


















 Download code from GitHub
Download code from GitHub
Chapter 1: Understanding the AI/ML landscape
In this opening chapter, we'll give you a little appreciation and context to the why behind AI and machine learning (ML). The only data we have comes from the past, and using that will help us predict the future. We'll take a look at the massive amount of data that is coming into the world today and try to get a sense of the scale of what we have to work with.
The main goal of any type of software or algorithm is to solve business and real-world problems, so we'll also take a look at how the applications take shape. If we use a food analogy, data would be the ingredients, the algorithm would be the chef, and the meal created would be the model. You'll learn about the most commonly used types of models within the broader landscape and how to know what to use.
There are a huge number of tools that you could use as a data scientist, and so we will also touch on how you can use solutions such as those provided by Anaconda to be able to do the actual work you want to and be able to take action as your models grow stale (which they will). By the end of this chapter, you'll have an understanding of the value and landscape of AI and be able to jumpstart any project that you want to build.
AI is the most exciting technology of our age and, throughout this first chapter, these topics will give you the solid foundation that we'll build upon through the rest of the book. These are all key concepts that will be commonplace in your day-to-day journey, and which you'll find to be invaluable in accomplishing what you need to.
In this chapter, we're going to cover the following main topics:
- Understanding the current state of AI and ML
- Understanding the massive generation of new data
- How to create business value with AI
- Understanding the main types of ML models
- Dealing with out-of-date models
- Installing packages with Anaconda
Introducing Artificial Intelligence (AI)
AI is moving fast. It has now become so commonplace that it's become an expectation that systems are intelligent. For example, not too long ago, the technology to compete against a human mind in chess was a groundbreaking piece of AI to be marveled at. Now we don't even give it a second thought. Millions of tactical and strategic calculations a second is now just a simple game that can be found on any computer or played on hundreds of websites.
That seemingly was intelligence… that was artificial. Simple right? With spam blockers, recommendation engines, and the best delivery route, the goalposts keep shifting so much that now, all of what was once thought of as AI is simply now regarded as everyday tools.
What was once considered AI is now just thought of as simply software. It seems that AI just means problems that are still unsolved. As those become normal, day-to-day operations, they can fade away from what we generally think of as AI. This is known as the Larry Tesler Theorem, which states "Artificial intelligence is whatever hasn't been done yet."
For example, if you asked someone what AI is, they would probably talk about autonomous driving, drone delivery, and robots that can perform very complex actions. All of these examples are very much in the realm of unsolved problems, and as (or if) they become solved, they may no longer be thought of as AI as the newer, harder problems take their place.
Before we dive any further, let's make sure we are aligned on a few terms that will be a focal point for the rest of the book.
Defining AI
It's important to call out the fact that there is no universal label as to what AI is, but for the purpose of this book, we will use the following definition:
Defining a data scientist
Along with the definition of AI, defining what a data scientist is can also lead you to many different descriptions. Know that as with AI, the field of data science can be a very broad category. Josh Wills tweeted that a data scientist is the following:
While there may be some truth to that, we'll use the following definition instead:
If you are reading this, then you probably fall into that category. There are many tools that a data scientist needs to be able to utilize to work toward the end goal, and we'll learn about many of those in this book.
Now that we've set a base level of understanding of what AI is, let's take a look at where the state of the world is regarding AI, and also learn about where ML fits into the picture.
Understanding the current state of AI and ML
The past is the only place where we can gather data to make predictions about the future. This is one of the core value propositions of AI and ML, and this is true for the field itself. I'll spare you from too much of the history lesson, but know that the techniques and approaches used today aren't new. In fact, neural networks have been around for over 60 years! Knowing this, keep in mind on your data science journey that a white paper or approach that you deem as old or out of date might just not have reached the right point for technology or data to catch up to it.
These systems allow for much greater scalability, distribution, and speed than if we had humans perform those same tasks. We will dive more into specific problem types later in the chapter.
Currently, one of the most well-known approaches to creating AI is neural networks, in which data scientists drew inspiration from how the human brain works. Neural networks were only a genuinely viable path when two things happened:
- We made the connection in 2012 that, just like our brain, we could get vastly better results if we created multiple layers.
- GPUs became fast enough to be able to train models in a reasonable timeframe.
This huge leap in AI techniques would not have been possible if we had not come back to the ideas of the past with fresh eyes and newer hardware.
Before more advanced GPUs were used, it simply took too long to train a model, and so this wasn't practical. Think about an assembly line making a car. If that moved along at one meter a day, that would be an effective end result, but it would take an extremely long time to produce a car (Henry Ford's 1914 assembly line moved at two meters a minute). Similar to 4k (and 8k) TVs being particularly useless until streaming or Blu-ray formats allowed us to have content that could even be shown in 4k, sometimes, other supporting technology needs to improve before the applications can be fully realized.
The massive increase in computational power in the last decade has unlocked the ability for the tensor computations to really shine and has taken us a long way from the Cornell report on The Perceptron (https://bit.ly/perceptron-cornell), the first paper to mention the ideas that would become the neural networks we use today. GPU power has increased at a rate such that the massive number of training runs can be done in hours, not years.
Tensors themselves are a common occurrence in physics and other forms of engineering and are an example of how data science has a heavy influence from other fields and has an especially strong relationship with mathematics. Now they are a staple tool in training deep learning models using neural networks.
Tensors
A tensor is simply a data structure that is commonly used in neural networks, but is a mathematical term. It can refer to matrices, vectors, and any n-dimensional arrays, but is mostly used to describe the latter when it comes to neural networks. It is where TensorFlow, the popular Google library, gets its name.
Deep learning is a technique in the field of AI and, more specifically, ML, but aren't they the same thing? The answer is no. Understanding the difference will help you focus on particular subsets and ensure that you have a clear picture of what is out there. Let's take a more in-depth look next.
Knowing the difference between AI and ML
Machine Learning (ML) is simply a machine being able to infer things based on input data without having to be specifically told what things are. It learns and deduces patterns and tries its best to fit new data into that pattern. ML is, in fact, a subset of the larger AI field, and since both terms are so widely used, it's valuable to get some brief examples of different types of AI and how the subsets fit into the broader term.
Let's look at a simple Venn diagram that shows the relationship between AI, ML, and deep learning. You'll see that AI is the broader concept, with ML and deep learning being specific subsets:
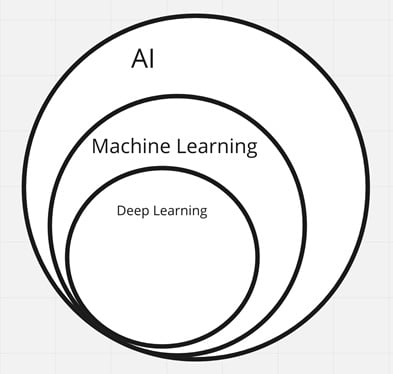
Figure 1.1 – Hierarchy of AI, ML, and deep learning
An example of AI that isn't ML is an expert system. This is a rule-based system that is designed for a very specific case, and in some ways can come down to if-else statements. It is following a hand-coded system behind the scenes, but that can be very powerful. A traffic light that switches to green if there is more than x number of cars in the North/South lane, but fewer than y cars in the East/West lane, would be an example.
These expert systems have been around for a long time, and the chess game was an example of that. The famous Deep Thought from Carnegie Mellon searched about 500 million possible outcomes per move to hunt down the best one. It was enough to put even the best chess players on the ropes. It later gave way to Deep Blue, which started to look like something closer to ML as it used a Bayesian structure to achieve its world conquest.
That's not AI! You might say. In an odd twist… IBM agrees with you, at least in the late 90s, as they actually claimed that it wasn't AI. This was likely due to the term having negative connotations associated with it. However, this mentality has changed in modern times. Many of the early promises of AI have come to fruition, solving many issues we knew we wanted to solve, and creating whole new sectors such as chatbots.
AI can be complex image detection, such as for self-driving, and voice recognition systems, such as Amazon's Alexa, but it can also be a system made up of relatively simple instructions. Think about how many simple tasks you carry out based on incredibly simple patterns. I'm hungry, I should eat. Those clothes are red, those are white, so they belong in different bins. Pretty simple right? The fact is that AI is a massive term that can include much more than what it's given credit for.
Much of what AI has become in the last 10 years is due to the high amount of data that it has access to. In the next section, we'll take a look in a little more detail at what that looks like.
Understanding the massive generation of new data
Put simply, data is the fuel that powers all things in AI. The amount of data is staggering. In 2018, it was calculated that 90% of the world's data was created in the last 2 years. There is no reason to think that stat might hold no matter when you read this. But who cares? On its own, data means nothing without being able to use it.
Fracking, a new technique to open up new pockets of oil, has opened up access to previously unreachable areas. Without that, those energy reserves would have sat there doing nothing. This is exactly what AI does with data. It lets us tap into this previously useless holding of information in order to unlock its value.
Data is just a recording of a specific state of the world or an event at a specific time. The ability and costs to do this have followed the famous Moore's law, making it cheaper and quicker to store and retrieve a huge amount. Just look at the price of hard drives throughout the years, going from $3.5 million per GB in 1964, to about .02 cents today in 2021.
Moore's Law
From the famed CEO of Intel, Moore's law states that the number of transistors that can fit on a chip will double every 2 years. This is many times misquoted as 18 months, but that is actually a separate prediction from a fellow Intel employee, David House, based on power consumption. This could also have been a self-fulfilling prophecy, as that was the goal, and not just happenstance.
It turned out that this law applies to many things outside of just compute speed. The cost of many goods (especially tech) follows this. In automotive, TV cost/resolution, and many other fields, you will find a similar curve.
If you heard that your used Coke cans would be worth $10 once a new recycling factory was built, would you throw them in the garbage? That is similar to what all companies are hearing about their data. Even though they might be making use of it today, they are still collecting and storing everything they can in the hope that someday, it can be used. Storage is also cheap, and getting cheaper. Due to both of these, it is seen as a much better move to save this data as it could be much more valuable than the cost of storing it.
What data do you have that could be valuable? Consider HR hiring reports, the exact time of each customer purchase, or keywords in searches – each piece of data on its own might not give you much insight, but combined with the power ML gives you to find patterns, that data could have incredible value. Even if you don't see what could be done now, the message to companies is Just hang on to it, maybe there is a use for it. Because of this, companies have become data pack rats.
One movement that has led to a huge increase in data is the massive increase in the number of IoT devices. IoT stands for Internet of Things, and it is the concept that every day, normal devices are connected to the same internet that you get your email, YouTube, and Facebook from. Light switches, vacuums, and even fridges can be connected and send data which is collected by the manufacturer in order to improve their functionality (hopefully).
These seeming pinpricks of data combined to create 13.6 Zettabytes in 2019, and it's not slowing down. By 2025, there will be 79.4 Zettabytes! You will be hard-pressed to find new devices that aren't IoT-ready as companies are always looking to add that new feature to the latest offering. From a physical perspective, if each gigabyte in a zettabyte was a brick, the Great Wall of China could be made 258 times over with the 3,873,000,000 bricks you'd have. That's a lot of data to take care of and process!
New technologies and even software architecture patterns have been developed to handle all this data. Event-based architecture is a way to handle data that turns the traditional database model inside out. Instead of storing everything in a database, it has a stream of events, and anything that needs that data can reach into the stream and grab what they need. There is so much data that they don't even bother putting it in one place!
But more data isn't always the answer. There are many times that more data is the enemy. Datasets that have a large amount of incorrectly labeled data can make for a much more poorly trained model. This, of course, makes intuitive sense. Trying to teach a person or a computer something while giving them examples that aren't valid isn't going to get the output that you are looking for.
Let's look at a simple example of explaining to your child what a tiger is. You point out two large orange cats with black stripes and tell them Look, that's what a tiger looks like. You then point to an all-black cat and then say And look! There is another one, incorrectly telling your child that this other animal is also a tiger. You have now created a dataset that contains false positives, and could make it challenging for your child to learn what an actual tiger is. False positives might be an issue with the 3-value dataset, whereas false negatives might be an issue if they have just seen one.
Important Note
This is for example purposes only. Any model trained on just one data point is almost guaranteed to not provide very accurate end results. There is a field of study known as one-shot learning that attempts to work with just one data point, but this is generally found in vision problems.
You might also have an issue where the data being fed in doesn't resemble the live production data. Training data being as close as possible to test data is critical, so if, in our training example from before, you pointed out a swimming tiger from 300 ft away, your child might find it very challenging to identify one when they see one walking from 10 ft away in the zoo. More doesn't always equal better.
Having data is critical to the success of AI, but the true driving force behind its adoption is what it can do for the world of business, such as Netflix recommending shows you will like, Google letting advertisers get their business in front of the right people, and Amazon showing you other products to fill your cart. This all allows businesses to scale like no other technique or approach out there and helps them continue to dominate in their space.
Evaluating how AI delivers business value
What do Facebook (now Meta), Apple, Amazon, Netflix, and Google have in common? Well, other than being companies that make up the popular FAANG acronym, they have a heavy focus on ML. Each one relies on this technology to not just make small percentage gains in areas, but many times, it is this tech that is at the heart of what they do. And as a key point, the only reason they keep AI and ML at the heart of what they do is because of the value it creates. Always focus on delivering business value and solving problems when you look to apply AI.
Google owes much of its growth to its hugely successful ad algorithms. Responsive search ads (or RSA) have a simple goal of trying to optimize ads to achieve the best outcome. RSA does this by pulling the levers it has, such as the headlines and body copy, to get the best outcome, which is clicks. Its bidding algorithm always has a dynamic pricing model for certain keywords based on a massive number of factors such as location, gender, age group, search profiles, and many others. Alphabet's (Google's parent company) revenue in 2020 was $182.5 billion, with a b. In no other way can you create such a massive generation of cash with so few people other than software and ML.
Some of these minor adjustments are changing the price by a penny, moving a user age group to target by a year, and changing the actual ad that is shown based on the context of the web page. Google's algorithms then measure whether it was successful. Can you imagine if a developer had to code up each individual change to a pricing model after making such small changes? Even if they did do that, there would be a much lower chance that the actual adjustments being made would be the ones actually impacting the desired end value.
We can consider another example in the form of how a system can determine what shows we might like by looking at Netflix. Netflix is able to suggest what we might want to watch next by using a recommendation system that uses your past viewing history to make predictions about future viewing habits. A recommendation system is simply something that predicts with different degrees of accuracy how likely you are to like a piece of content. We make use of this technique every time we pull up our Amazon home page, get an email from Netflix that there is a new show that we might like, or doomscroll through Twitter.
There is a massive business value to each of these, as getting more eyeballs on screens helps sell more ads and products, improves click-through rates (the number of people who actually click on an ad), and increases other metrics that, at the end of the day, make that platform more valuable than if you simply got a list of the top 10 most sold items. You have your own personal robot behind the scenes trying to help you out. Feels nice, doesn't it?
Netflix does this by creating latent features for each movie and show without having to use the old style of asking users questions such as: How much do you like comedies? Action movies? Sports movies? Think about how many people didn't fill these out, and thus Netflix didn't have the retention rate of people who did.
This prediction system so valuable that Netflix offered a million-dollar prize to anyone who could improve it by 10%. This tells us two things:
- That there is a huge business value in improving the AI system
- That there is a dire shortage of people that Netflix could find to work on this problem
A latent feature is a synthetic tag generated from a weighted combination of other attributes. Did you ever describe a movie to a friend as epic? That was our mind putting together attributes of a movie, the sum total of which created the epic label. This allows for more freedom and essentially infinite ways to combine what already exists to create a system that can determine (with incredible accuracy) what someone will like and buy. This also allows a reduced number of features to be considered.
Amazon has made real-world moves based on this, shipping items to local distribution centers before people buy things in order to increase delivery speed. This allows yet another competitive advantage that increases their ability to capture and retain customers. Maybe tomorrow you'll have a drone waiting outside your house for a few minutes waiting on you to click buy now on that new phone you've been eyeing for a week.
Every example here should show you not only how AI can solve problems at scale, but also that AI and ML are not just technical fields. If you really want to make an impact, you need to make sure you keep the business problems you are trying to solve at the forefront of your mind.
These are just a few of the numerous business problems that you may want to solve, but what techniques would you even start with when looking at them for the first time? In the next section, we will dive into just that.
Understanding the main types of ML models
Here we are going to take a look at some of the vast number of techniques and approaches that can be used to solve your problems. Similar to how a hacker may know a handful of techniques in their field (contrary to what Hollywood has you believe), a data scientist might know only one branch or area of the following really well. So don't be discouraged. The key is being able to know what tool to use based on the problem you have.
To put this in context, let's take a Star Wars example. Say you are put in charge of defense on the moon of Endor. You have data on the prior attacks of those pesky Ewoks. The Emperor is getting a little restless, so you decide to put ML to use to try and figure out what's going on and put a stop to it.
ML is very broad, so let's start with the four main categories: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. This distinction comes down to simply how much help the model gets when it's being trained and the desired outcome of the model. The dataset that the model is training on is, appropriately, called the training set. Let's take a look at each of these ML categories in a little more detail.
Supervised learning
Supervised learning is used when you have labeled training data that you feed in. A famous and early example is spam detection. Another would be predicting the price of a car. These are both examples where you know the right answer. The key is that the data is labeled with the main feature you care about and can use that to train your model.
Back to the Endor moon, you have the following data. It shows reports with the weather, time of day, whether shipments are coming in, the number of guards, and other data that may be useful, along with a simple Boolean label of attack: True/False:

Figure 1.2 – Attack data from the moon of Endor
This is a great use case for supervised learning (in this case, should you be worried?). We'll look at this scenario in more detail in Chapter 7, Choosing the Best AI Algorithm.
Algorithms that fall under the supervised learning category are as follows:
- Logistic Regression
- Linear Regression
- Support Vector Machines
- K-Nearest Neighbor (a density-based approach)
- Neural Networks
- Random Forest
- Gradient Boosting
Next, we will cover unsupervised learning.
Unsupervised learning
Unsupervised learning is used when you do not have labeled training data that you feed in. A common scenario is when you have a group of entities and need to cluster them into groups. Some examples where this is used are advertising campaigns based on specific sub-sets of customers, or movies that might share common characteristics.
In the following diagram, you can see different customers from a hypothetical company, and there seem to be three separate groups they naturally fall into:
.
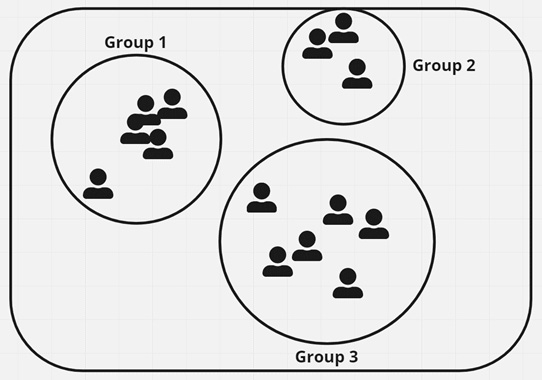
Figure 1.3 – Example of classification problem with three customer groups
This diagram might represent some customers of a new movie recommendation engine you are trying to build, and each group should get a separate genre sent to them for their viewing pleasure.
There is another related approach that takes the same idea of grouping, but instead of trying to see what people or entities fit into a group, you are trying to find the entities that don't fall into one of the main groups. These outliers don't fit into the pattern of the others, and searching for them is known as anomaly detection.
Anomaly detection is also a form of unsupervised learning. You can't have a labeled list of things that are normal and not normal, because how would you know? There isn't a sure way to go through and label all the different ways that something could look inconsistent, as that would be very time-consuming and borderline impossible. This type of problem is also known as outlier detection due to the goal being the detection of those entities that are different from the others.
This can be vital when looking at identity fraud to understand whether an action or response falls out of place of a normal baseline. If you have ever gotten a text or email from your credit card company asking whether it was you that made a purchase, that is anomaly detection at work! There is no way for them to code up every possible scenario that could happen outside the normal, and this again shows the power of ML.
Looking back at our earlier scenario on the moon of Endor, you know that there is some suspicious key card access that has happened. You look at all the data but can't make much of it. You know there isn't a way to figure out which logins in the past were valid, so you can't label the data and thus you determine that this falls into the unsupervised bucket of algorithms.
The following diagram shows what a dataset might look like for the key card events that could be a good candidate for an unsupervised problem, specifically anomaly detection. As you can see, there are no labels on any of the data points.
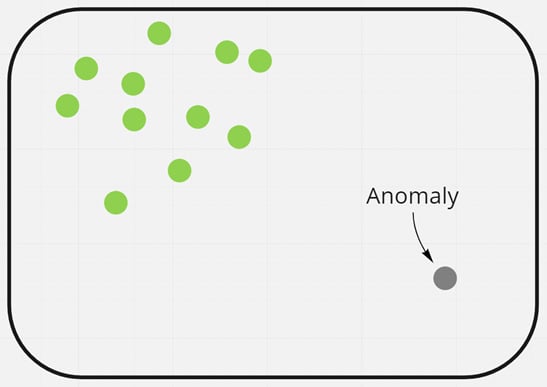
Figure 1.4 – Example of an anomaly problem with one anomaly
One of the data points (the top right) clearly has some characteristics that make it stand out from the rest of the group. The keystrokes take much longer, and the heat sensor reading at the time is much higher. This is a simplistic representation, but you can see how something seems out of place to the eye. That's the essence of what an anomaly is.
With the preceding example, do you think that the event on the bottom right should be investigated, or does it seem normal? It might be worthwhile looking into who accessed the system at that time.
Algorithms that fall under the unsupervised learning category are as follows:
- K-means (a clustering-based approach)
- Isolation forest
- Principal Component Analysis (PCA)
- Neural networks
We've just covered supervised and unsupervised, but there is another type that is somewhat of a mix and subset of the two. Let's take a quick look at what semi-supervised models look like.
Semi-supervised learning
Semi-supervised learning is the process by which you attempt to create a model from data that is both labeled and unlabeled to try and have the best of both the supervised and unsupervised techniques. It attempts to learn from both types of data and is very useful when you don't have the luxury of everything being labeled. Many times, you use the unsupervised approach to find higher-level patterns, and the supervised step to fine-tune exactly what those patterns represent.
In the following example, you'll see where you might have taken part in this process yourself without realizing it.
Have you ever been on Facebook, and it asked you to tag your friends in pictures? That was a semi-supervised approach at work. An unsupervised model groups people's faces together that it thinks are the same person, and then the user will be the one to label those groups as Michael, Donald, Don, and so on. In this way, you have part of the problem as an unsupervised learning problem with the clustering of people into groups, and part as a supervised problem with labeling these groups.
Due to this being a combination of supervised and unsupervised, you can, in theory, pull from any of the algorithm families on the respective groups.
Let's now move on to the last type of AI approach on our list.
Reinforcement learning
The fourth major type of ML, after supervised, unsupervised, and semi-supervised is reinforcement learning. Reinforcement learning (RL) is the process by which a system, called an agent, gradually learns to accomplish some tasks via a reward function by interacting with an environment.
A reward function is a way to determine how desired an outcome is, and the reinforcement learning model attempts to optimize what it's doing to achieve the highest reward value. Take an example of a rat in a maze. In this example, the rat is the agent, the environment is the maze, and the reward function is how strong the smell of cheese is (and ultimately eating it).
Every time it turns the right way, the smell of cheese gets a bit stronger. It then tries to figure out how to navigate in such a way that the smell continues to increase, until it is given the biggest reward at the end, which is a nice slice of mozzarella. Reinforcement is a popular choice in robotics, self-driving, and anything else where you have a clear end goal, but don't have a traditional training dataset as a starting point.
Reward functions can work in the opposite way as well. Take a newborn child, for example. Parents are programmed to minimize the amount of crying that their little girl does, and so they learn what to do or not do. Did you just set her down and she started crying? Pick her up. Crying started in the middle of the night? Try feeding her, then changing her diaper. To our mind, those sound like very simple things, but it's the RL that we all have hard-wired into us that dictates what we do and optimizes us to be good parents. In this case, the parents are the agents observing the environment and taking action, and how much the baby cries is the reward function. Minimize crying, optimize smiling. Being parents all of a sudden sounds pretty straightforward.
Before they were acquired by Google, DeepMind showed how RL can be used to learn to play many Atari games with no prior knowledge of how they work, and with the only input being the pixels on the screen: https://arxiv.org/abs/1312.5602.
This article does a great job of defining what RL is and the one key difference between it and other approaches to AI: https://www.synopsys.com/ai/what-is-reinforcement-learning.html.
In RL, training data is obtained via the direct interaction of the agent with the environment. Training data is the learning agent's experience, not a separate collection of data that has to be fed to the algorithm. This significantly reduces the burden on the supervisor in charge of the training process.
Sometimes, training data is fed into an RL system such as AlphaGo, but that training data is simply used to run simulations using what it knows to be the optimal outcome based on the reward function. Much of the research into self-driving adopts the same approach.
Evaluating the problem type
With all these different types of approaches, it is good to have a simple recap of how to know which path to take when you start to look at a problem. In the following diagram, we'll find a simple flowchart to determine which approach might be correct:
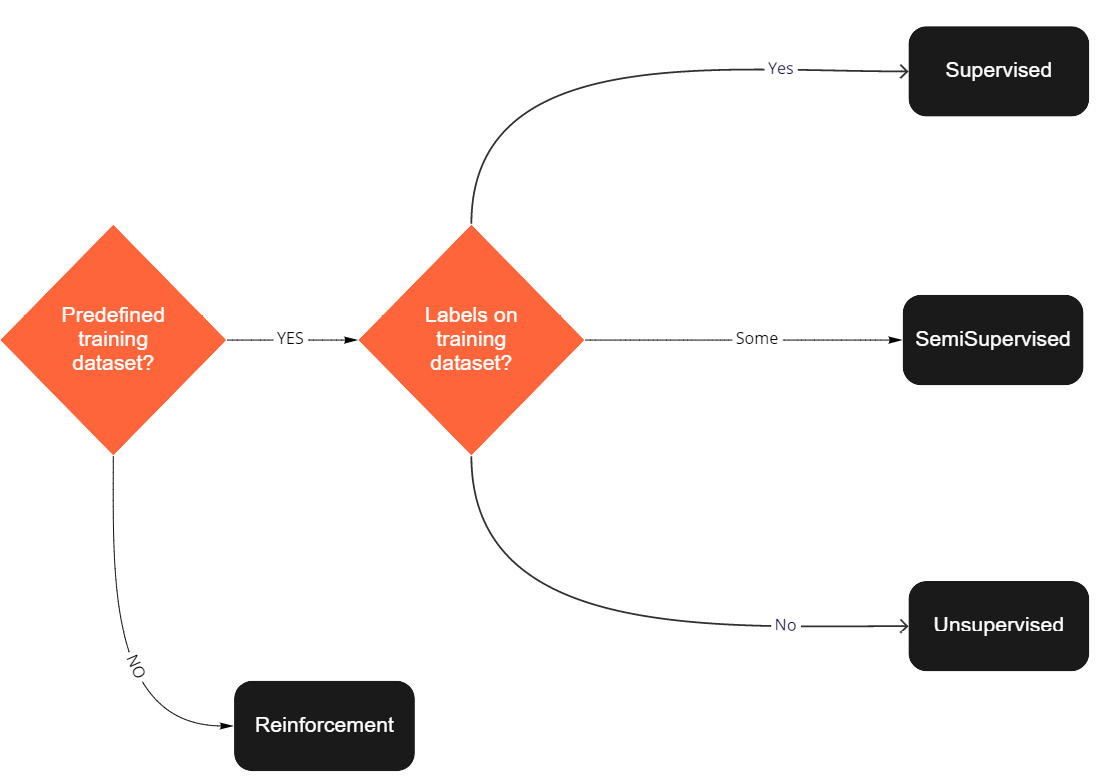
Figure 1.5 – Decision tree for ML problem types
As you can see, there are two key questions that you need to ask yourself that will lead to the most appropriate approach:
- Do I have a training dataset?
- Does this training dataset have labels?
Note that RL still needs training data (as all AI algorithms do), but it's just in a very different shape from the others. RL will get its training data as the agent interacts with the environment. It's not a static set you have in the beginning that you need to generate and clean. Some RL applications, such as AlphaGo, do feed data in for the model to train, but this data is in the form of data needed to create good simulations and gain experience of playing. It's not hard data that it pulls directly from, rather the agent keeps learning as it goes.
One key difference between RL and the others is that the agent can directly impact the data and state of the environment. An algorithm playing an Atari game, a self-driving car, and a bowling machine will all be operating on a dynamic state that the algorithm impacts. A supervised learning algorithm, in contrast, will never change the data that was used in training.
In time, you will know these well enough that you won't need to ask these questions and can just jump to the correct approach, but it's good to use this simple chart as a quick guide to get started.
With this information, you now know the main types of ML problems that you will encounter and solve in the wild. Supervised learning is when you have data with labels, unsupervised learning is when you are trying to make sense of data without labels, and semi-supervised learning is when you use techniques that combine both. You also learned that RL is when you know the outcome you want to achieve and need an agent to figure out how best to accomplish this.
With all of these model types, there is one thing that they all have in common, which is that they might not perform as well over time as they did when you initially trained them. Let's explore what this looks like in more detail in the next section.
Dealing with out-of-date models
So, you've trained the perfect model and the data is flowing into the algorithm with great results. Sit back and just relax, right? Well, not quite. Just like you constantly need to adjust a menu at a restaurant to keep up with new customers' preferences, you will need to update your model to take in new data and adapt accordingly. Thankfully, you have quite a few tools at your disposal to do so.
In addition to the nature of the training data being used to classify types of AI model algorithms, how or when the training happensis also taken into consideration. Let's look at the two types of training methods in more detail: online versus batch.
Difference between online and batch learning
Online learning is the process where you have a live learning process that can take in new data as it comes in to adjust the algorithm. Think of learning how to play golf for the first time. At the beginning, you have watched just a bit of the PGA tour, and you know that you need to grab a club and swing away. You pick a club at random and start hacking. After a few sand traps and quadruple bogeys, you have a friend who gives you some pointers, and you realize that after adjusting, you have managed to cut your strokes down a lot by the last 9 holes. You've adjusted your game on the fly.
Making sure you didn't just take a static approach to what you were doing allows you to tweak your approach and incorporate the new info into what you were doing.
The other approach is batch learning. Batch learning is when you take a chunk of data and feed it into the training stage to spit out a static model. Going back to our earlier example in our quest to get our tour card, this would be like after playing your 18 holes, you went to take some lessons from a pro, and then went back out onto the course to test out your new approach.
This is where one of the key misconceptions arises with ML. AI models don't simply improve on their own as they take in and process data from the world. There are ways to do that, and many of the AI models deployed use the batch learning process.
Why not use online learning all the time? Well, is getting a friend to help you on the golf course better than taking the time to talk to a professional? There are pros and cons to each. Let's go over a few of these now:
- The first reason is the business scenario at hand. For example, if you are trying to make predictions on the outcome of a sporting event before it happens, it makes no sense to use online learning.
- Another is that setting up batch learning allows you to parse out and have more control over the exact data that is fed into your model. You can create a data pipeline that applies certain rules to the data flowing in, but you still won't be able to put the same care and analysis into the data as it goes into a batch process.
- The next reason is convenience. Sometimes, the data is far away from where your model inference is happening. Inference is when your model is actually processing the live data through the system, many times referred to simply as running or scoring the model. Maybe you are running your model on an edge device such as a phone or IoT device. In that case, there might not be a simple or efficient way to get mountains of data processed and into the right place to train.
- Training is also costly in terms of both time and money, and this relates back to the location of where this model is running. Many types of models need a beefy GPU, CPU, memory, or some other dedicated hardware that isn't in place. Separating your training from where your model runs lets you separate these phases and allows you to have specialized devices or architecture designed around the exact use case. For example, maybe training your model requires GPUs that you rent for $5,000 an hour, but once your model is trained, it can be used on a $50 machine.
- The last reason for not using online learning is simply that you don't want the deployed model to change. If you have a self-driving car, do you really want new data to be taken in, causing each of your cars to have a slightly different model? This would result in 100,000+ different models running at a time in the wild. Each one could almost be guaranteed to have slightly different innards than the original source of truth. The implications from a moral and safety perspective are massive, not to mention trying to QA what is going on and why. In this scenario, it's much better to have a golden standard that you can train, and then test. That way, when you roll out an update such as Tesla does (and no doubt others will have followed by the time you read this), that exact model has already been tested by running in the real world.
On the other hand, online learning does have a massive advantage in the areas where you have the ability and support to grab new data coming in. An example of when you might want to do this is predictive analytics, which is when you use historical data to predict things such as when a wind turbine might fail. Being able to train on live data could help you when the weather starts to change, and the operational mechanics of a physical system might operate differently. Fast forward weeks or months into the future, and you might have a much better result than a static model.
Online learning helps a great deal with model drift, which we will cover in the next section.
How models become stale: model drift
Drift is a major problem in the ML world. What is drift? Model drift is when the data you trained the model on doesn't represent the current state of the world in which the model is deployed. The Netflix algorithm trained on your preferences might be off after your sibling watches all the shows they like. A wind turbine operation was fed temperatures and conditions for the summer, but now winter storms have dramatically changed the climate it operates in.
Coming back to our golfing example, this would be like getting fantastic at a single course, but then the course owners decided to mix things up, moving all the bunkers to drift to where your favorite tee shot on hole 4 was. If you don't take into account this new drift, you'll find yourself eating sand instead of smugly walking up to your perfectly placed tee shot.
Let's take a look at this golf example to see how things can change from what you expect from one week to the next. In the first diagram, you see your normal golf shot, while in the second, you can see that same shot the following week, after that bunker location has changed:
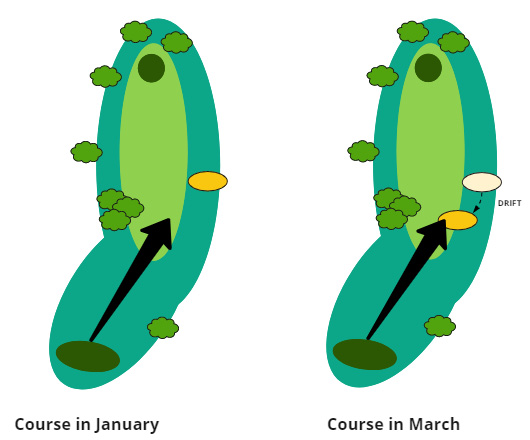
Figure 1.6 – Golf course showcasing the model drift of a bunker
As you can see in the second diagram, the course designer decided to move the bunker closer to the tee box. You could continue to hit your shot in the same position as before, but you would get much worse results after this change as you are now hitting straight into this sand trap. This is what you need to do with your models; make sure you are paying attention and realize that we live in a dynamic world that can evolve.
Model drift is an important concept to consider, and there are many tools that can help with this, which we'll look at further in Chapter 8, Dealing with Common Data Problems. But now let's look at how you would even install these tools in the first place.
Installing packages with Anaconda
Let's now move on to a little more practical knowledge of how to get going on your journey into data science and set you up for the rest of this book. We'll quickly cover how to download Anaconda and install the packages and software you'll need.
To put it simply: there are a lot of tools out there for you to use as a data scientist. A lot. Some of them are just de facto ones that you should use and not look back (such as Python currently), while some have a small number of true contenders (such as conda versus pip), and then it breaks wide open when you get into toolsets and packages due to the open source movement (which we will go into in much more detail in the next chapter).
Anaconda itself is a distribution or a curated collection of tools or items. One of the most common places you'll hear this term is in the phrase Linux distribution. All that means is that someone packaged up a group of components that they thought were helpful and let you consume it in one easy package. Think of a gift basket or a pre-made arrangement of summer flowers.
Next, let's learn more about Anaconda and its main benefits.
How to use Anaconda Individual Edition to download packages
Anaconda Individual Edition is a collection of tools and packages that make it incredibly simple to get everything set up on your local computer to start or continue your data science journey. It's the easy button for ML and AI. This is also referred to as the Anaconda distribution, as it's a curated set of tools that Anaconda distributes as a single group. This is the same terminology that Linux-based systems use, which is a collection of other things rolled together.
The following are the main components that you get when you install Anaconda Individual Edition:
- Python: Easily the most common language used for data science
- Conda: A package manager and virtual environment tool
- Navigator: A GUI tool that gives you the main functionality of Conda
- 250+ packages
It is highly encouraged and necessary to download Anaconda in order to follow along with this book. It's free for individual use and comes with the preceding components. Some of the packages included are NumPy for array mathematical operations and Bokeh for visual operations, among many others. It can be installed at https://www.anaconda.com/products/individual.
Anaconda Individual Edition for Commercial Use
On an important note, Individual Edition is intended for just that, individuals. If you are wanting to use it in a commercial setting, then you will need to check and find a license for that. Currently, it is called Commercial Edition, and this lets you use it in a setting where you are downloading large numbers of packages. Due to this potentially changing by the time you are reading this, it is advised that you go to the official website to find out more information: https://www.anaconda.com/products/commercial-edition.
Python is going to be the go-to language for data science, and for this reason is covered in this book. While there are a lot of other fantastic languages, Python excels in this domain due to its ease of use, the ability to be the glue among many other tools, and its huge number of amazing data science libraries in the form of packages.
Due to the huge number of packages out there, having a package manager is critical for being able to focus on the actual problem at hand and not fighting with system files. Building from the source could be a great way to spend a month of your time if you want to be cruel to yourself, but it is probably easier to let conda do the heavy lifting for you. Even having a few tools can quickly get you into a situation where you have to move a lot of files to the right place to get to what you need. Python comes out of the box with pip, which is completely fine to start with, but there is another solution that has a huge advantage over this, and which we'll go over now.
Anaconda has a fantastic solution to the evil of dependency hell. Its main product, conda, is a package and environment manager that massively eases the burden of having to figure out what goes with what. Due to how complex dependencies can be, you can find yourself in a situation where you just wanted to try out this great new library or tool, only to realize to your horror that what it needed was a different version of package x, which isn't compatible with the thing y, which your real project relies on and is now broken. This is dependency hell.
The biggest reason for using conda to manage packages over pip is that conda will resolve dependencies for you without you having to sort through which versions of tools you need in order for everything to work together.
Navigator is the GUI companion to conda. If you prefer a more visual style to find packages and manage environments, then this is your thing. You will get most of the main functions that are in its sister CLI.
Python virtual environments are another tool that I'd heavily advocate. There are many times that you might want a different version of the same tool depending on what project you are using. The most common is Python itself. There were some significant changes between Python 2 and 3, and due to this, some projects will require one version or the other. Conda solves this problem, too, by allowing you to create virtual environments to contain different packages. We'll cover how to do that in the next chapter.
There are other genres of tools out there that I'm less opinionated on, and in general, this book takes a lighter touch in terms of which to use, but with so many other choices with things, I'd use conda and worry about the other things later. Of the things that conda takes care of for you, the previously mentioned dependency management might be the most impactful. Let's now see how dependencies work and why it's best to let conda figure it out.
How to handle dependencies with conda
Dependency management can be complex, so let's use a hypothetical cooking example to see where the challenges could come in. You want to make lasagna and it needs the following ingredients:
- Cheddar aged 3-4 weeks
- 1% or 2% milk
- Ground beef
To start, you grab some 3-week aged cheddar. However, your milk will only mix right with cheddar that is exactly 4 weeks old. So, then you need to go back and switch out your cheddar. But then you see that the meat you want to use goes bad when using 2% milk (which makes no sense), and 1% needs a different age cheddar… but then you see that you also needed a coupon to make sure you kept it under budget. You didn't know about that, and it doesn't even make sense that the limitation was there! Confusing, right?! Exactly. Dependencies can be a nightmare to deal with, and you should be focusing on more important problems.
What if you just let your personal shopper go figure all this out? This is what a package manager does for you, making a list of each thing you need, and sorting it all out for you. All you need to do is say I want to make lasagna. Find a good dependency manager and use it. Conda is one of these good dependency managers, while pip is another one. Use it and focus on making delicious lasagna. Conda is preferred for reasons we'll go into just a bit later.
For a more real-world example, take a look at the main dependencies of scikit-learn 1.0.0, a very popular tool for scientific computing:
- Python (>= 3.7)
- NumPy (>= 1.14.6)
- SciPy (>= 1.1.0):
numpy>= 1.11.3, <2,libcxx>= 4.0.1python>= 3.7, <3.8libopenblas>= 0.2.20, <0.2.21
- Joblib (>= 0.11)
- threadpoolctl (>= 2.0.0)
- Matplotlib (>= 1.1):
dateutilpytz
As you can see, there are many dependencies that scikit-learn needs, and not only that, but some dependencies need to pull in others to do what they need, such as SciPy requiring NumPy.
One thing that can happen with needing different packages is that you could have different versions of certain packages being brought in. One way to help with this is to use different spaces for the specific things you need for a certain project. Anaconda has a solution for this called environments, and we'll take a look at these in the following section.
Creating separate work areas with Anaconda environments
Virtual environments are a way to create a closed system that you can freely tweak without the danger of impacting the host system. Think of them like a pop-up kitchen you go to that you can mess up, try crazy recipes in the blender, and then walk away from while someone else cleans up and your house is never touched.
Remember when I said Anaconda was preferred? This was because the virtual environments are baked in, and you can just use one tool for dependency management and package management.
Once you have it installed, you should create a virtual environment so that anything installed can have its own nice place to live and not interfere with any other installed libraries and packages. Virtual environments are a critical concept to get a handle on, so it's worth diving into a bit of detail here. After downloading Anaconda, pull up the Terminal in macOS, or run the Anaconda PowerShell script in Windows, and run the following command:
conda create -n myenv Python=3.8
This creates the myenv environment with Python 3.8. You can then activate this environment with the following command:
conda activate myenv
Activating the environment simply means hey, I want to jump in and run commands inside here. At that point, any package installed, upgraded, or downgraded won't impact your local machine or other libraries that might need to be installed.
Important Note
Earlier versions of conda had platform-specific commands, while newer versions allow this same one to work across all supported platforms. At the time of writing this book, this was OSX (Mac), Windows 10, and Linux.
The main difference with Python virtual environments is that conda is language-agnostic, so it provides much more flexibility with its ability to not be boxed in if your needs change and you need to make use of R or potentially any other language.
You aren't limited to the roughly 250 packages that come to you out of the box. It's simple to install additional packages as required. There are 7,500+ that can be installed from repo.anaconda.com, and thousands of others from conda-forge, the community channel for packages.
Now that you are in your virtual environment, run the following command to install numpy:
conda install numpy
NumPy is a library that helps you perform many mathematical operations on arrays. You don't have to know about it now, but we'll talk much more about it in Chapter 4, Working with Jupyter Notebooks and NumPy.
If you ever need help or would like to explore more, you can use the conda help command to show useful info about what you can do from the command line:
conda help
You can also go straight to the source and get tips and guides from Anaconda itself here: https://docs.anaconda.com/anaconda/user-guide/getting-started/.
If you are more the visual type, you also have the alternative, which is to use Navigator. While not as powerful as the command-line tool, Navigator makes the most commonly used commands available in perhaps a more familiar GUI interface.
We'll go more in-depth into conda, package management, virtual environments, and Navigator in later chapters.
Summary
As you can see, there is a lot to cover across the AI/ML world, and we have just scratched the surface of what lies beneath.
In this chapter, we covered a bit of the history of AI/ML in order to understand how we got to this point. We also saw how a huge amount of data is feeding the AI revolution with cheap storage and more sources creating it. Business value is also a main driving force pushing this tech forward, and we saw how some companies such as Netflix and Google are leveraging it to solve different problems. Moving on to out-of-date models, we learned what drift is, and how it can impact your ability to deliver consistent predictions on production data as the real-world changes. Finally, we got a bit more hands-on by installing packages with Anaconda's package manager, conda.
With this knowledge, you're now equipped to be able to distinguish between different models and problem types to use in certain scenarios, including supervised and unsupervised. You'll also be able to know whether the trade-offs for online versus batch learning are worth it and be able to determine which is right for you. Lastly, you should now be able to install Anaconda Individual Edition and use it to create an environment and download the packages that you will need for the rest of this book.
In our next chapter, you'll learn everything you need to know about the bedrock of AI: open source. You'll get hands-on experience with the most popular tools, NumPy and pandas, learn about the open source community and how to take part, and practice how to import anything you need using conda and the conda-forge community into your project in seconds.

