


















 Download code from GitHub
Download code from GitHub
Introducing Amazon Web Services
Welcome to the journey of becoming an Amazon Web Services (AWS) solutions architect. A path full of challenges, but also a path full of knowledge awaits you. To begin, I'd like to start by defining the role of a solutions architect in the software-engineering context. Architecture has a lot to do with technology, but it also has a lot to do with everything else; it is a discipline responsible for the nonfunctional requirements, and a model to design the Quality of Service (QoS) of the information systems.
Architecture is about finding the right balance and the midpoint of every circumstance. It is about understanding the environment in which problems are created, involving the people, the processes, the organizational culture, the business capabilities, and any external drivers that can influence the success of a project.
We will learn that part of our role as solutions architects is to evaluate several trade-offs, manage the essential complexity of things, their technical evolution, and the inherent entropy of complex systems.
The following topics will be covered in this chapter:
- Understanding cloud computing
- Cloud design patterns and principles
- Shared security model
- Identity and access management
Technical requirements
Solution scripts are available in the book's repositories at the following URLs, if you get stuck with the examples:
Minimizing complexity
A widely used strategy to solve difficult problems is to use functional decomposition, that is, breaking a complex system or process into manageable parts; a pattern for this is the multilayered architecture, also known as the n-tier architecture, by which we decompose big systems into logical layers focused only on one responsibility, leveraging characteristics such as scalability, flexibility, reusability, and many other benefits. The three-layer architecture is a popular pattern used to decompose monolithic applications and design distributed systems by isolating their functions into three different services:
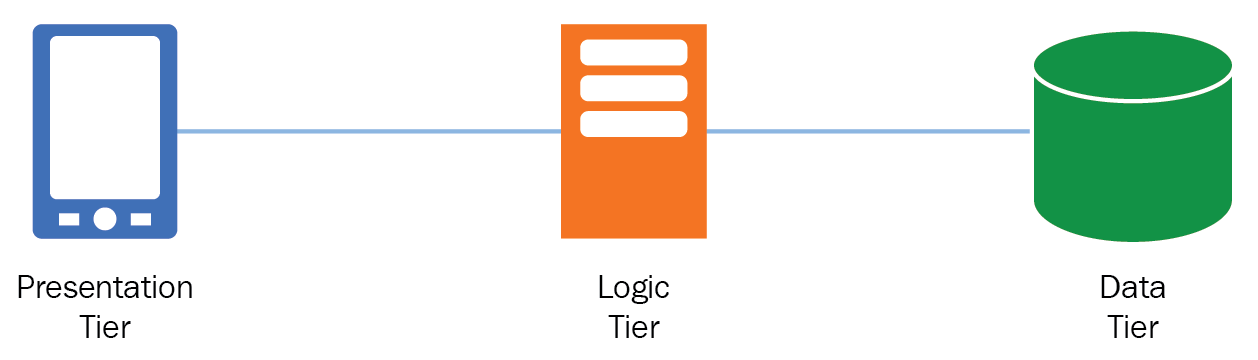
- Presentation Tier: This represents the component responsible for the user interface, in which user actions and events are generated via a web page, a mobile application, and so on.
- Logic Tier: This is the middleware, the middle tier where the business logic is found. This tier can be implemented via web servers or application servers; here, every presentation tier event gets translated into service methods and business functions.
- Data Tier: Persistence means will interact with the logic tier to maintain user state and behavior; this is the central repository of data for the application. Examples of this are database management systems (DBMS) or distributed memory-caching systems.
Conway's law
This sentence shows the relevance of the way people organize to develop systems, and how this impacts every design decision we make. We will get into depth in the later chapters discussing microservices architectures, about how we can decouple and remove the barriers that prevent systems from evolving. Bear in mind that this book will show you a new way of systems thinking, and with AWS you have the tools to solve any kind of problem and create very sophisticated solutions.

Cloud computing
Cloud computing is a service model based on large pools of resources exposed through web interfaces, with the objective being to provide shareable, elastic, and secure services on demand with low cost and high flexibility:
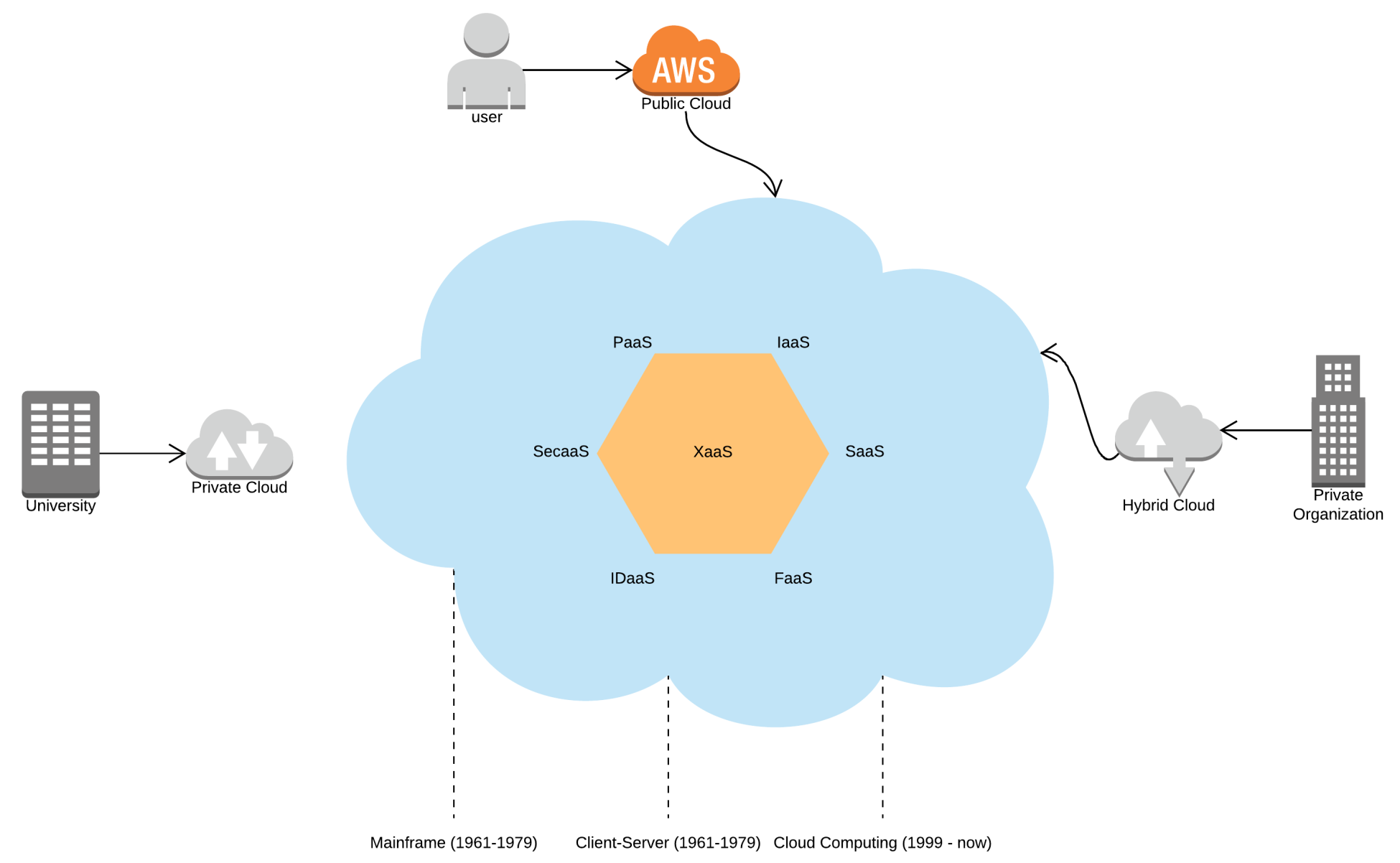
Architecting for AWS
Designing cloud-based architectures, carries a different approach than traditional solutions, because physical hardware and infrastructure are now treated as software. This brings many benefits, such as reusability, high cohesion, a uniform service interface, and flexible operations.
It's easy to make use of on-demand resources when they are needed to modify its attributes in a matter of minutes. We can also provision complex structures declaratively and adapt services to the demand patterns of our users. In this chapter, we will be discussing the design principles that will make the best use of AWS.
Cloud design principles
These principles confirm the fundamental pillars on which well-architected and well-designed systems must be made:
- Enable scalability:
- Antipattern: Manual operation to aggregate capacity reactively and not proactively. Passive detection of failures and service limits can result in downtimes for applications and is prone to human errors due to limited reaction timespans:
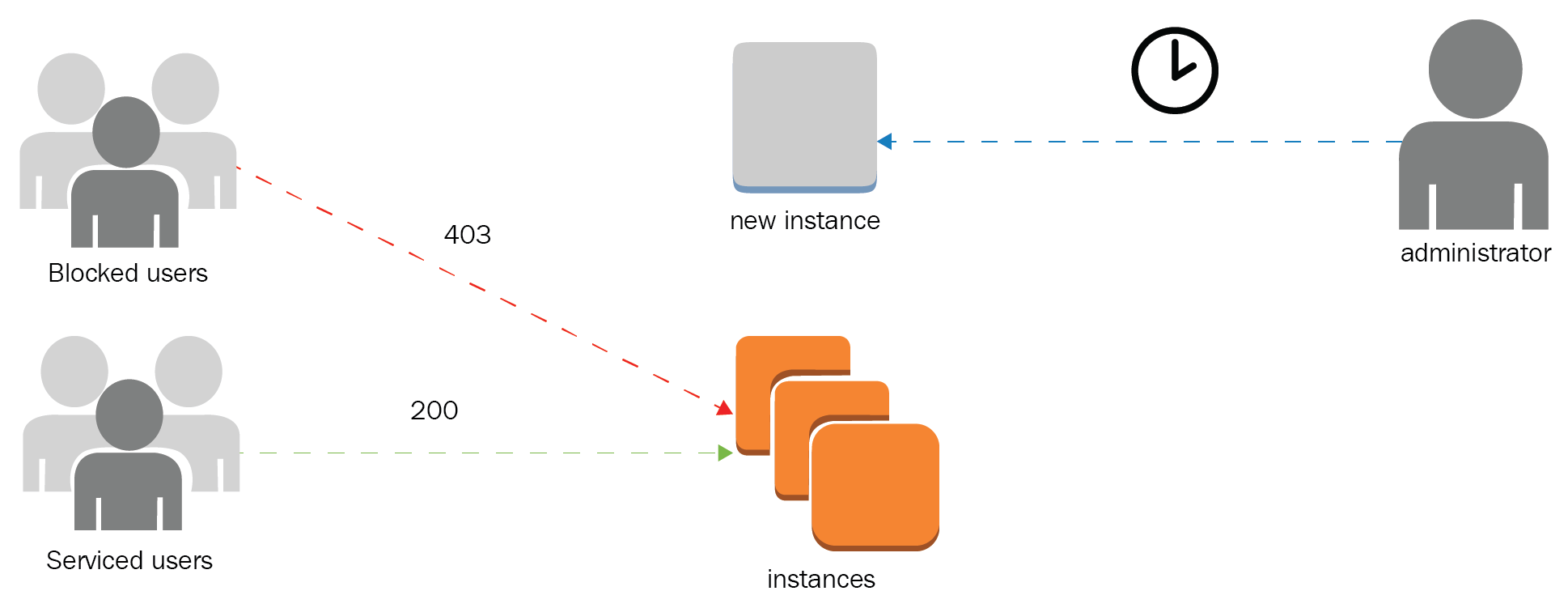
From the diagram, we can see that instances take time to be fully usable, and the process is human-dependent.
-
- Best practice: The elastic nature of AWS services makes it possible to manage changes in demand and adapt to the consumer patterns with the possibility to reach global audiences. When a resource is not elastic, it is possible to use Auto Scaling or serverless approaches:

Auto Scaling automatically spins up instances to compensate for demand.
- Automate your environment:
- Antipattern: Ignoring configuration changes and the lack of a configuration management database (CMDB) can result in erratic behavior, visibility loss, and have a high impact on critical production systems. The absence of robust monitoring solutions results in fragile systems and slow responses to change requests compromising security and the system's stability:

AWS Config records every change in the resources and provides a unique source of truth for configuration changes.
-
- Best practice: Relying on automation, from scripts to specialized monitoring services, will help us to gain reliability and make every cloud operation secure and consistent. The early detection of failures and deviation from normal parameters will support in the process of fixing bugs and avoiding issues to become risks. It is possible to establish a monitoring strategy that accounts for every layer of our systems. Artificial intelligence can be used for analyzing the stream of changes in real time and reacting to these events as they occur, facilitating agile operations in the cloud:

Config can be used to durably store configuration changes for later inspection, react in real time with push notifications, and visualize real-time operations dashboards.
- Use disposable resources:
- Antipattern: Running instances with low utilization or over capacity can result in higher costs. The poor understanding of every service feature and capability can result in higher expenses, lower performance, and administration overhead. Maybe you are not using the right tool for the job. Immutable infrastructure is a determinant aspect of using disposable resources, so you can create and replace components in a declarative way:

Tagging will help you gain control, and provide means to orchestrate change management. The previous diagram shows how tagging can help to discover compute resources to stop and start only in office hours for different regions.
-
- Best practice: Using reserved instances promotes a fast Return on Investment (ROI). Running instances only when they are needed or using services such as Auto Scaling and AWS Lambda will strengthen usage only when needed, thus optimizing costs and operations. Practices such as Infrastructure as Code (IaC) give us the ability to create full-scale environments and perform production-level testing. When tests are over, you can tear down the testing environment:

Auto Scaling lets the customer specify the scaling needs without incurring additional costs.
- Loosely couple your components:
- Antipattern: Tightly coupled systems avoid scalability and create a high degree of dependencies at the component and service levels. Systems become more rigid, less portable, and it is very complicated to introduce changes and improvements. Coupling not only happens at the software or infrastructure levels, but also with service providers by using proprietary solutions or services that create dependencies with a brand forcing us to consume their products with the inherent restrictions of the maker:

Software changes constantly, and we need to keep ourselves updated to avoid the erosion of the operating systems and technology stacks.
-
- Best practice: Using indirection levels will avoid direct communications and less state sharing between components, thus keeping low coupling and high cohesion. Extracting configuration data and exposing it as services will permit evolution, flexibility, and adaptability to changes in the future.
It is possible to replace a component with another if the interface has not changed significantly. It is fundamental to use standards-based technologies and protocols that bring interoperability such as HTTP and RESTful web services:
A good strategy to decouple is to use managed services.
- Design services, not servers:
- Antipattern: Investing time and effort in the management of storage, caching, balancing, analysis, streaming, and so on, is time-consuming and deviates us from the main purpose of the business: the creation of valuable solutions for our customers. We need to focus on product development and not on infrastructure and operations. Large-scale in-house solutions are complicated, and they require a high level of expertise and budget for research and fine-tuning:
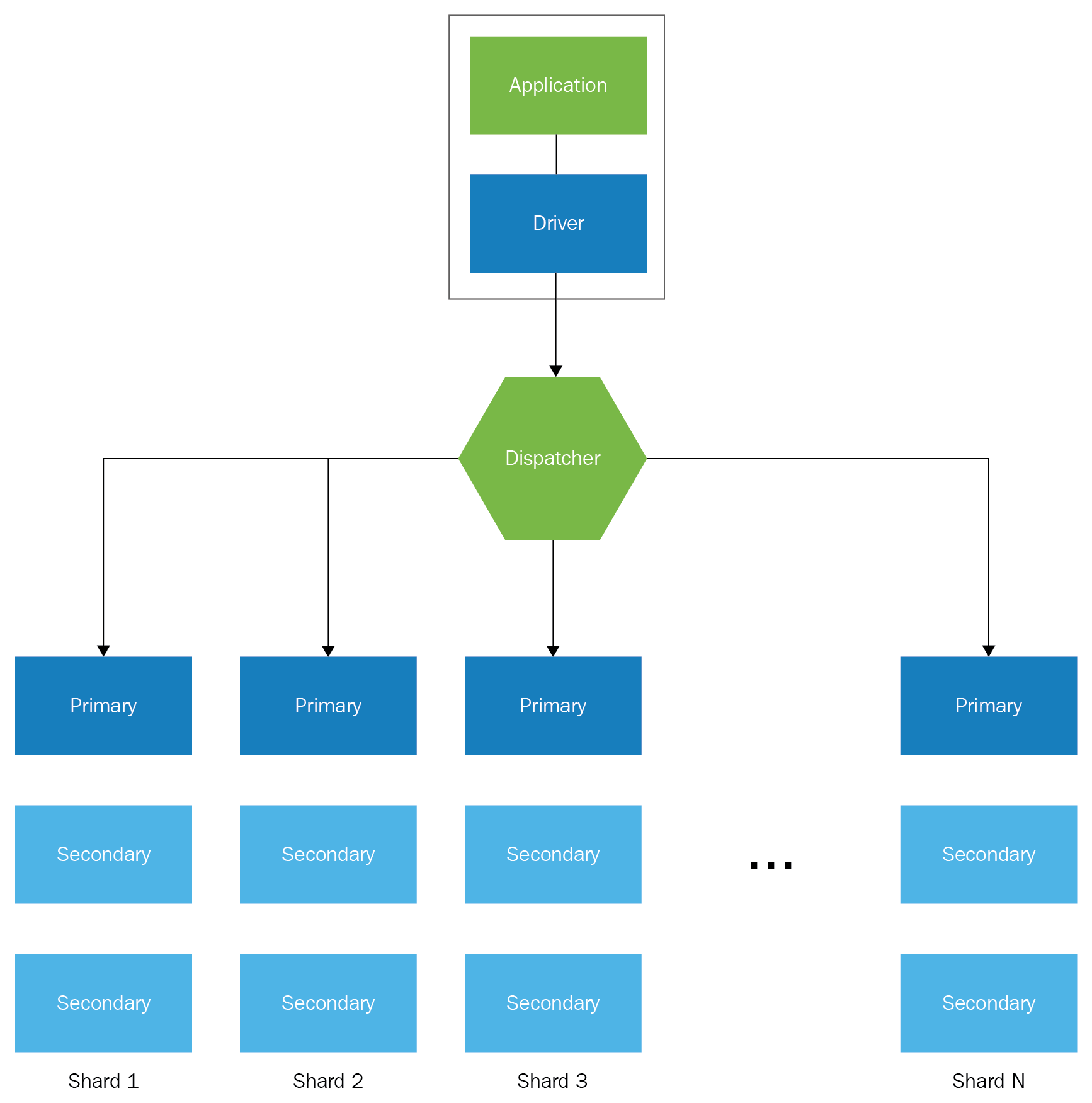
-
- Best practice: Cloud-based services abstract the problem of the operation of this specialized services on a large-scale and offload the operations management to a third party. Many AWS services are backed by Service Level Agreements (SLAs), and these SLAs are passed down to our customers. In the end, this improves the brand's reputation and our security posture; also, this will enable organizations to reach higher levels of compliance:
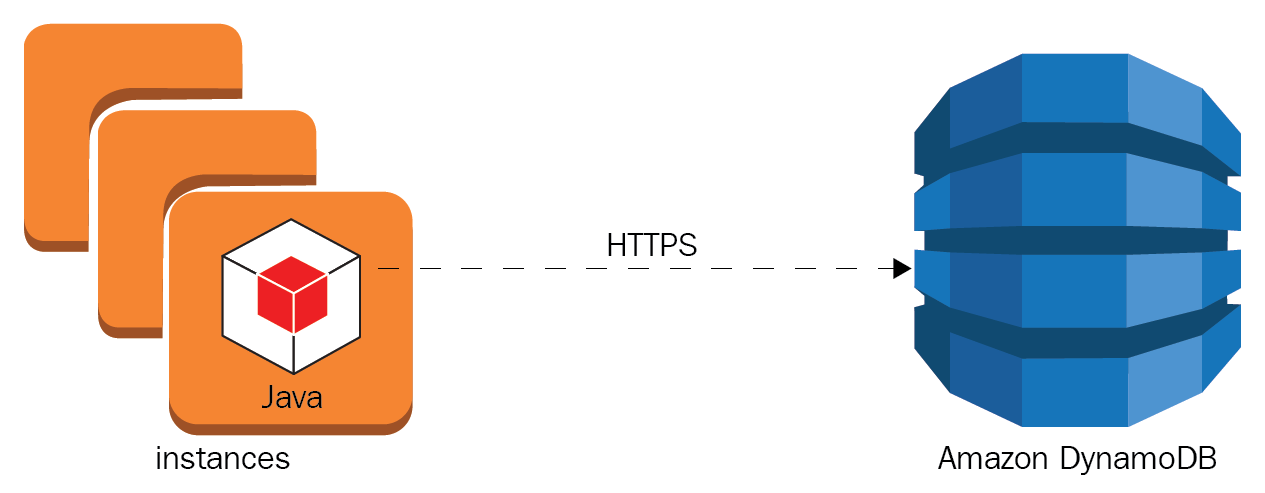
- Choose the right database solutions:
- Antipattern: Taking a relational database management system (RDBMS) as a silver bullet and using the same approach to solve any kind of problem, from temporal storage to Big Data. Not taking into account the usage patterns of our data, not having a governance data model, and an incorrect classification can leave data exposed to third parties. Working in silos will result in increased costs associated with the extract, transform, and load (ETL) pipelines from dispersed data avoiding valuable knowledge:
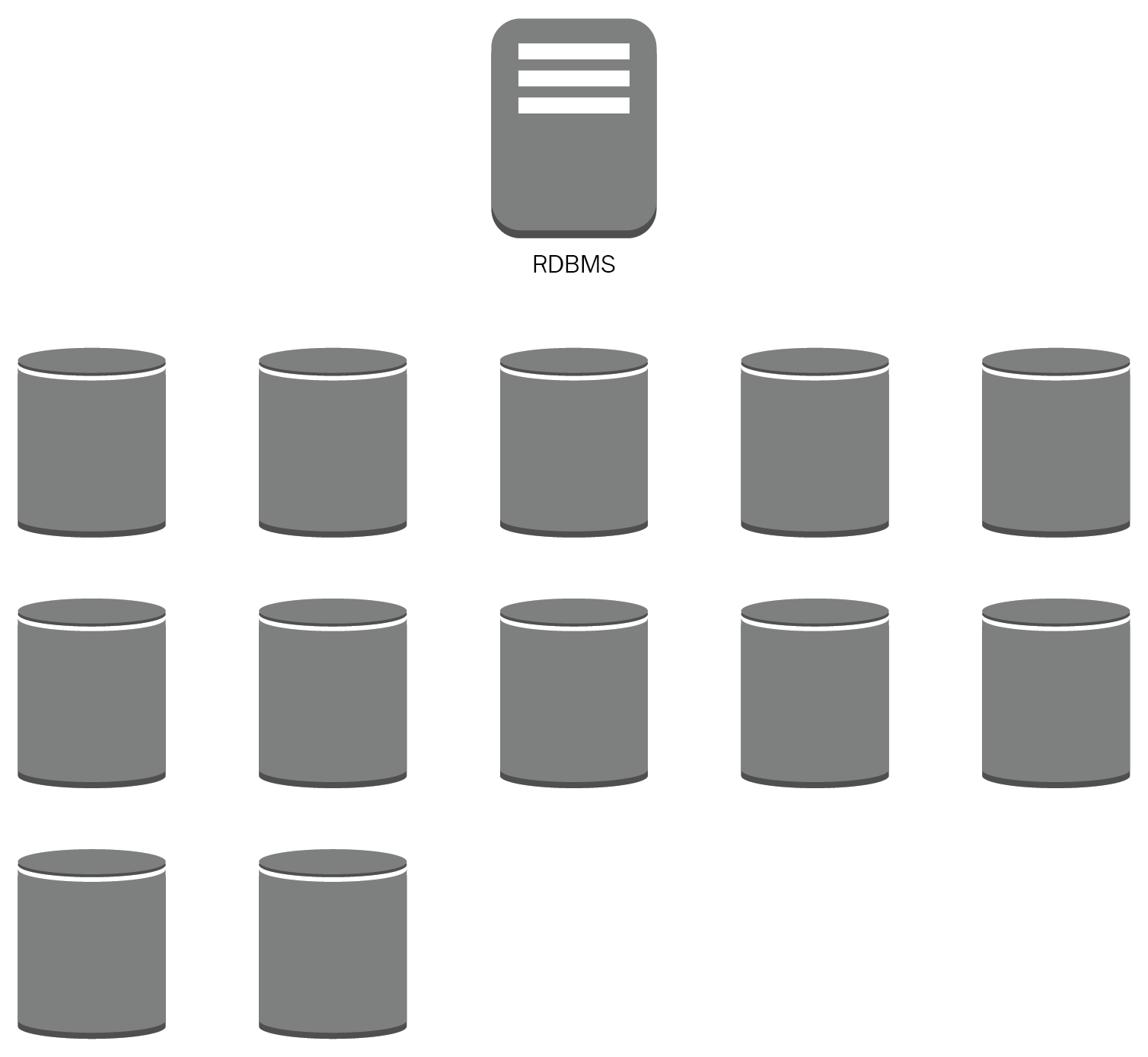
Big Data and analytics workloads will require a lot of effort and capacity from an RDBMS datastore.
-
- Best practice: Classify information according to its level of sensibility and risk, to establish controls that allow clear security objectives, such as confidentiality, integrity, and availability (CIA). Designing solutions with specific-purpose services and ad hoc use cases such as caching and distributed search engines and non-relational databases. All of these will contribute to the flexibility and adaptability of the business. Understanding data temperature will improve the efficiency of storage and recovery solutions while optimizing costs. Working with managed databases will make it possible to analyze data at petabyte scale, process huge quantities of information in parallel, and create data-processing pipelines for batch and real-time patterns:

- Avoid single points of failure:
- Antipattern: A chain is as strong as its weakest link. Monolithic applications, a low throughput network card, and web servers without enough RAM memory can bring a whole system down. Non-scalable resources can represent single points of failure or even a database license that prevents the use of more CPU cores. Points of failure can also be related to people by performing unsupervised activities and processes without the proper documentation; also the lack of agility could represent a constraint in critical production operations:
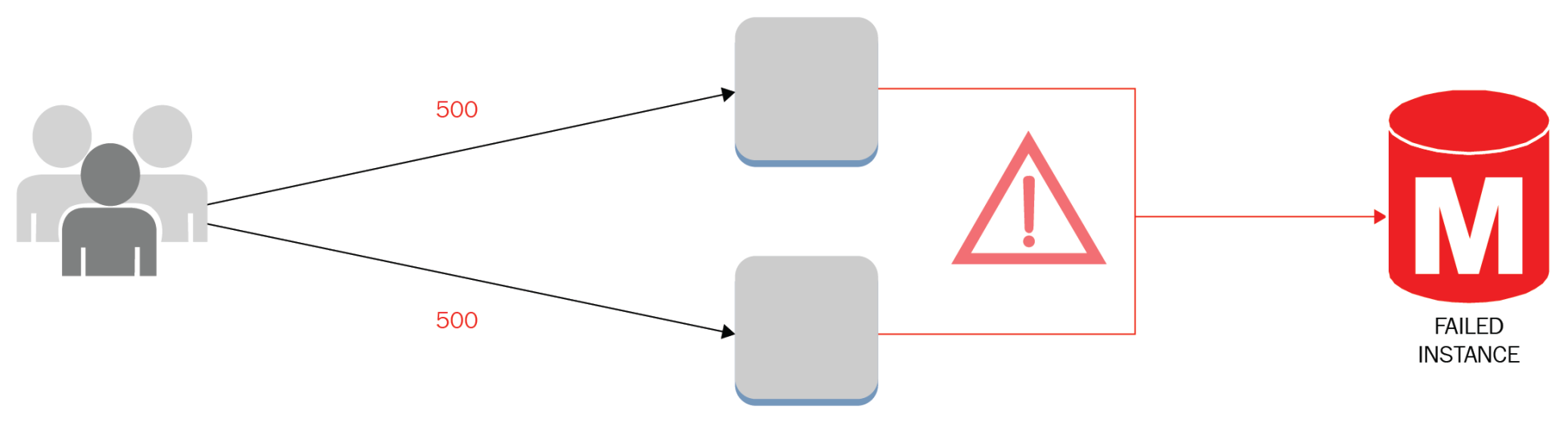
-
- Best practice: Active-passive architectures avoid complete service outages, and redundant components enable business continuity by performing switchover and failover when necessary. The data and control planes must take this N+1 design paradigm, avoiding bottlenecks and single component failures that compromise the full operation. Managed services offer up to 99.95% availability regionally, offloading responsibilities from the customer. Experienced AWS solutions architects can design sophisticated solutions with SLAs of up to five nines:

- Optimize for cost:
- Antipattern: Using big servers for simple compute functions, such as authentication or email relay, could lead to elevated costs in the long term and keeping instances running 24/7 when traffic is intermittent. Adding bigger instances to improve performance without a performance objective and proper tuning won't solve the problem. Even poorly designed storage solutions will cost more than expected. Billing can go out of control if expenses are not monitored in detail.
It is common to provision resources for testing purposes or to leave instances idle, forgetting to remove them. Sometimes, instances need to communicate with resources or services in another geographic region increasing complexity and costs due to inter-region transfer rates:
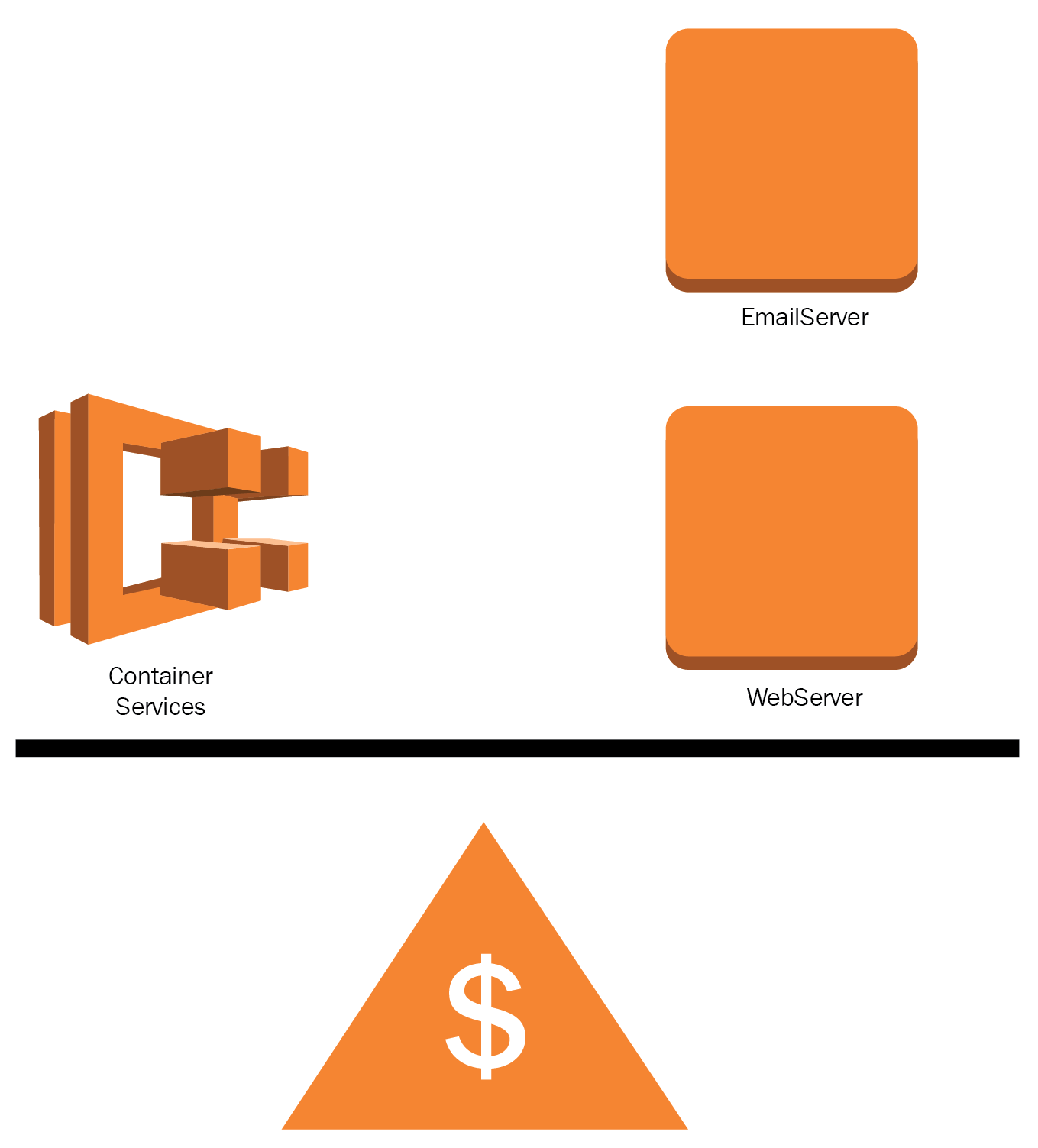
-
- Best practice: Replacing traditional servers with containers or serverless solutions. Consider using Docker to maximize the instance resources and AWS Lambda; use recurring compute resources only when needed. Reserving compute capacity can decrease your costs significantly, by up to 95%. Leverage managed services features that can store transient data such as sessions, messages, streams, system metrics, and logs:

- Use caching:
- Antipattern: Repeatedly accessing the same group of data or storing this data in a medium not optimized for reading workloads, applications dealing with the physical distance between the client, and the service endpoint. The user receives a pretty bad experience when the network is not available.
Increasing costs due to redundant read requests and cross-region transfer rates, also not having a life cycle for storage and no metrics that can warn about the usage patterns of data:
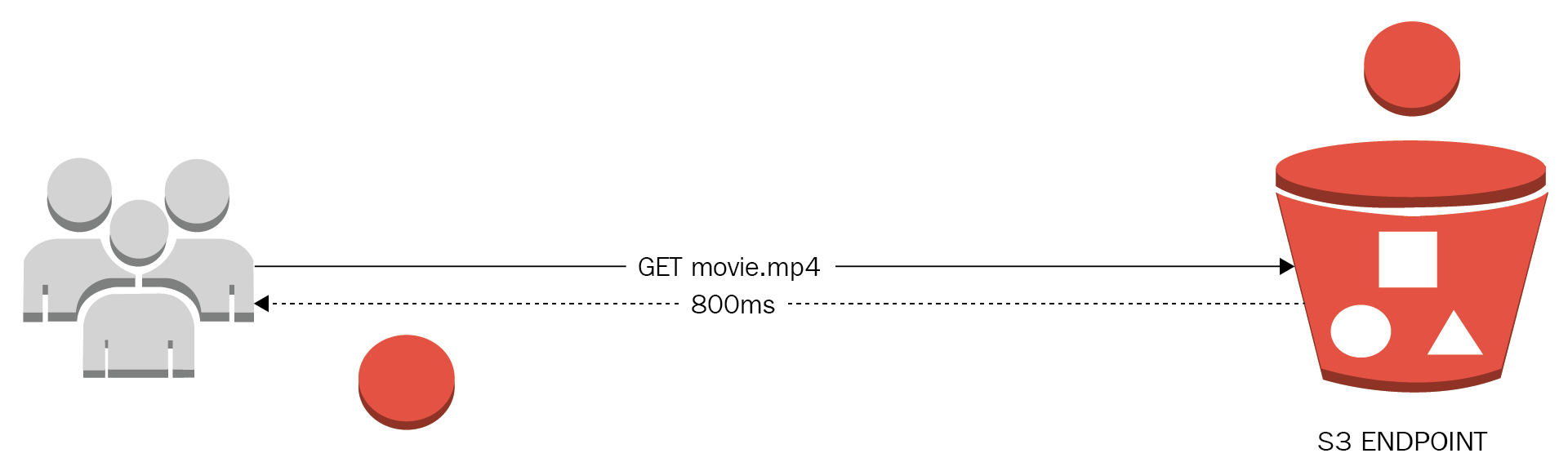
-
- Best practice: Identify the most used queries and objects to optimize this information by transferring a copy of this data to the closest location to your end users. By using memory storage technologies it is possible to achieve microsecond latencies and the ability to retrieve huge amounts of data. It is necessary to use caching strategies in multiple levels, even storing commonly accessed data directly on the client, for example mobile applications using search catalogs.
Caching services can lower your costs and offload backend stress by moving this data closer to the consumer. It is even possible to offer degraded experiences without the total service disruption in the case of a backend failure:

- Secure your infrastructure everywhere:
- Antipattern: Trusting in the operating system's firewalls and being naive about the idea that every workload in the cloud is 100% secure out of the box. Waiting until a security breach is made to take corrective measures maybe thinking that only Fortune 500 companies are victims of Distributed Denial of Service (DDoS) attacks. Implementing HTTPS but no security at-rest compromise greatly the organization assets and become an easy prey of ransomware attacks.
Using the root account and the lack of logs management structures will take visibility and auditability away. Not having an InfoSec department or ignoring security best practices can lead to a complete loss of credibility and of our clients:

-
- Best practice: Security must be an holistic labor. It must be implemented at every layer using a systemic approach. Security needs to be automated to be able to react immediately when a breach or unusual activity is found; this way, it is possible to remediate as detected. In AWS, it is possible to segregate network traffic and use managed services that help us to protect valuable assets with complete visibility of operations and management.
At-rest data can be safeguarded by using encryption semantics using cryptographic keys generated on demand delegating the management and usage of these keys to users designated for these jobs. Data in transit must be protected by standard transmission protocols such as IPSec and TLS:
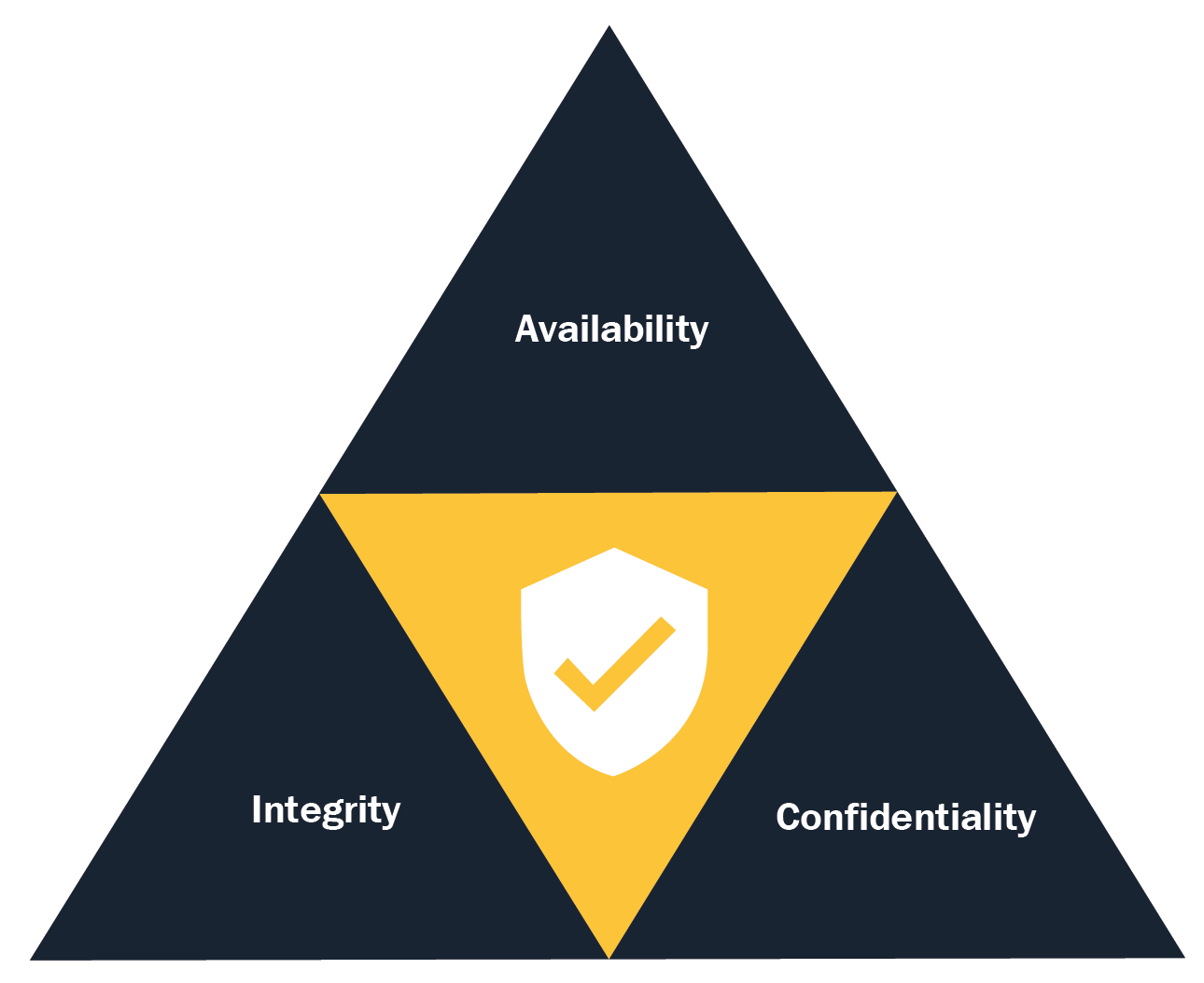
Cloud design patterns – CDP
Cloud design patterns are a collection of solutions for solving common problems using AWS technologies. It is a library of recurrent problems that solutions architects deal with frequently when implementing and designing for the cloud. This is curated by the Ninja of Three (NoT) team.
These patterns will be used throughout this book as a reference, so you can get acquainted with them and understand their rationale and implementation in detail.
AWS Cloud Adoption Framework – AWS CAF
The Cloud Adoption Framework offers six perspectives to help business and organizations to create an actionable plan for the change management associated with their cloud strategies. It is a way to align businesses and technology to produce successful results:

The six perspectives are grouped as follows:
- CAF business perspectives:
- Business perspective: Aligns business and IT into a single model
- People perspective: Personnel management to improve their cloud competencies
- Governance perspective: Follows best practices to improve enterprise management and performance
- CAF technical perspectives:
- Platform perspective: Includes the strategic design, the principles, patterns, and tools to help you with the architecture transition process
- Security perspective: Focuses on compliance and risk management to define security controls
- Operations perspective: This perspective helps to identify the processes and stakeholders relevant to execute change management and business continuity
AWS Well-Architected Framework – AWS WAF
The AWS Well-Architected Framework takes a structured approach to design, implement, and adopt cloud technologies, and it works around five perspectives so you can look at a problem from different angles. These areas of interest are sometimes neglected because of time constraints and misalignment with compliance frameworks. This book relies strongly on the pillars that are listed here:
- Operational excellence
- Security
- Reliability
- Performance efficiency
- Cost optimization

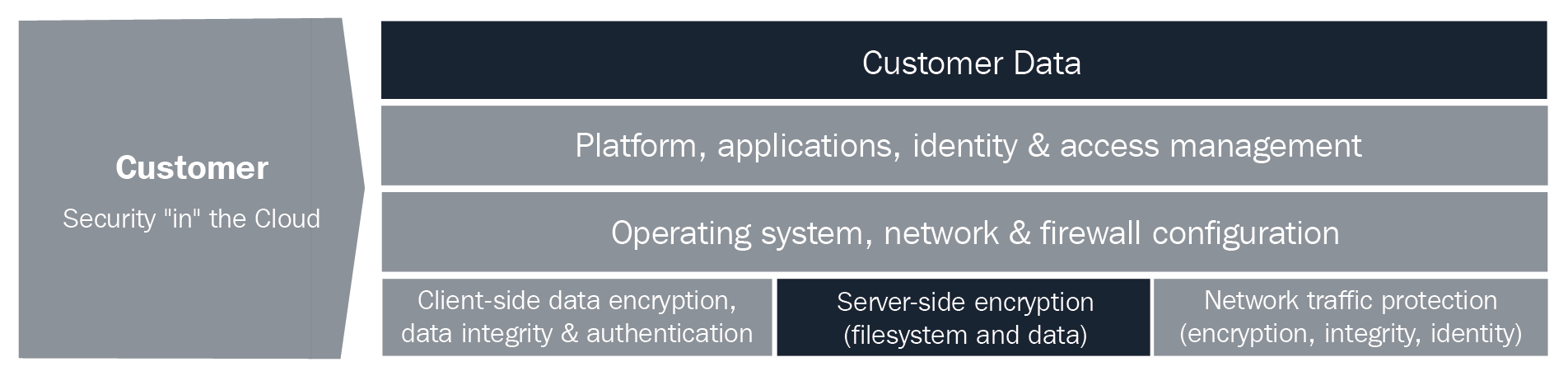
Shared security model
This model is the way AWS frees the customer from the responsibility of establishing controls at the infrastructure, platform, and services levels by implementing them through their services. In this sense, the customer must provide full control of implementation in some cases, or work in a hybrid model where the customer provides their own solutions by complementing existing ones in the cloud:
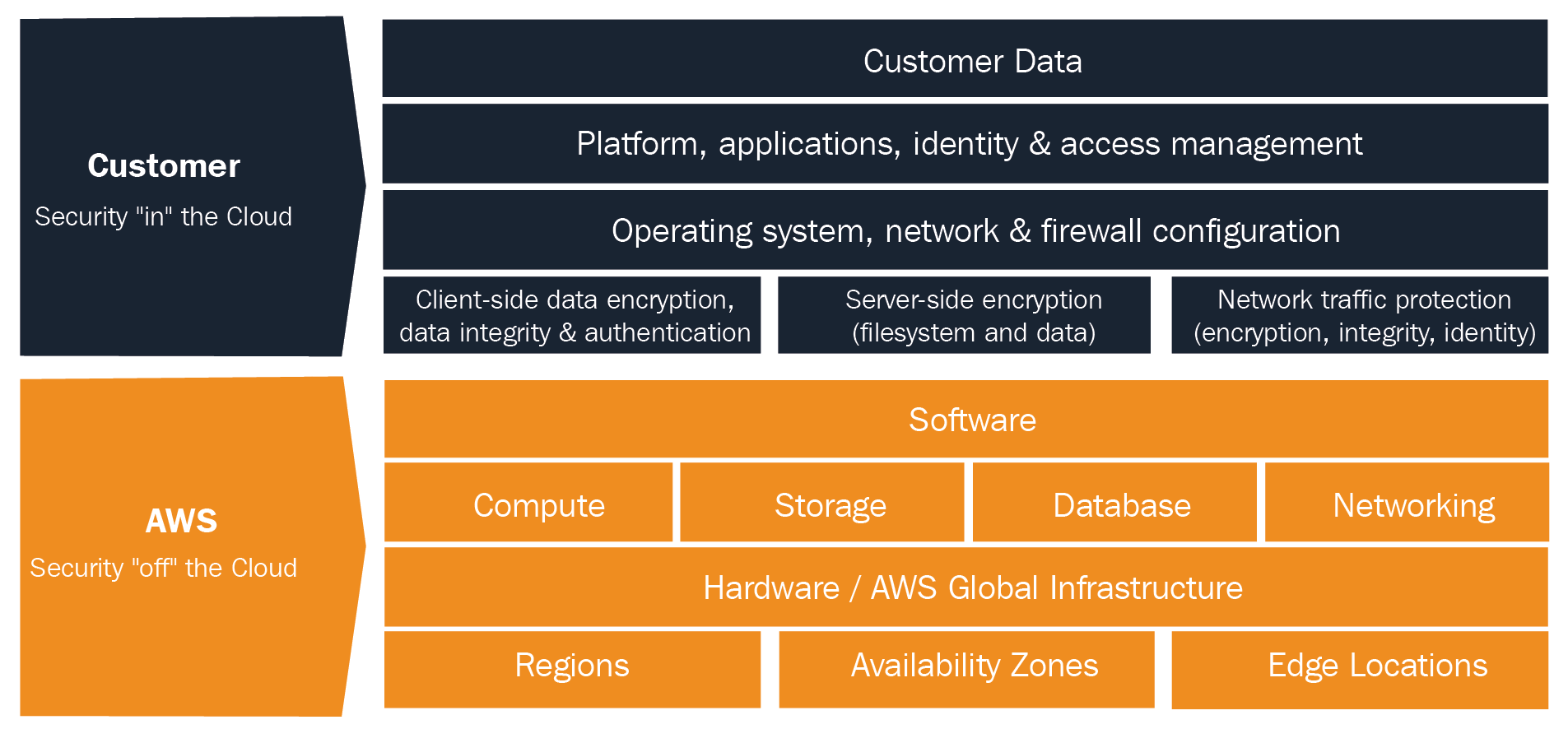
The previous diagram shows that AWS is responsible for the security of the cloud; this involves software and hardware infrastructure and core services. The customer is responsible for everything in the cloud and the data they are the owner of.
To clarify this model, we will use a simple web server example and explain for every step which controls are in place for the customer and for AWS:
To create our web server, we will create an instance.
In the EC2 console choose Launch Instance:
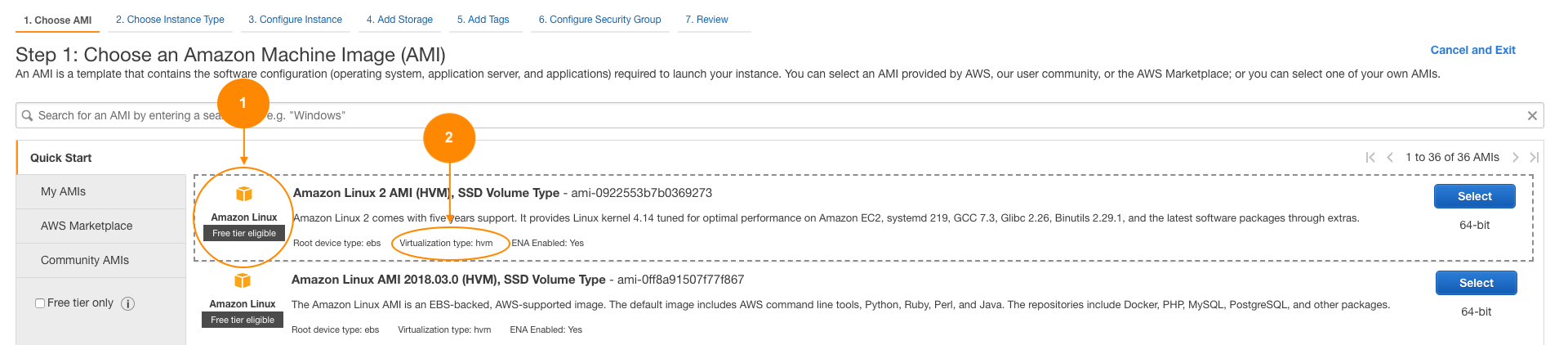
Following are the details of the instance:
|
AWS/customer |
|
The previous example is an example of an inherited control (virtualization type) and a shared control (virtual image).

The next screen is for the configuration of the network attributes and the tenancy mode:
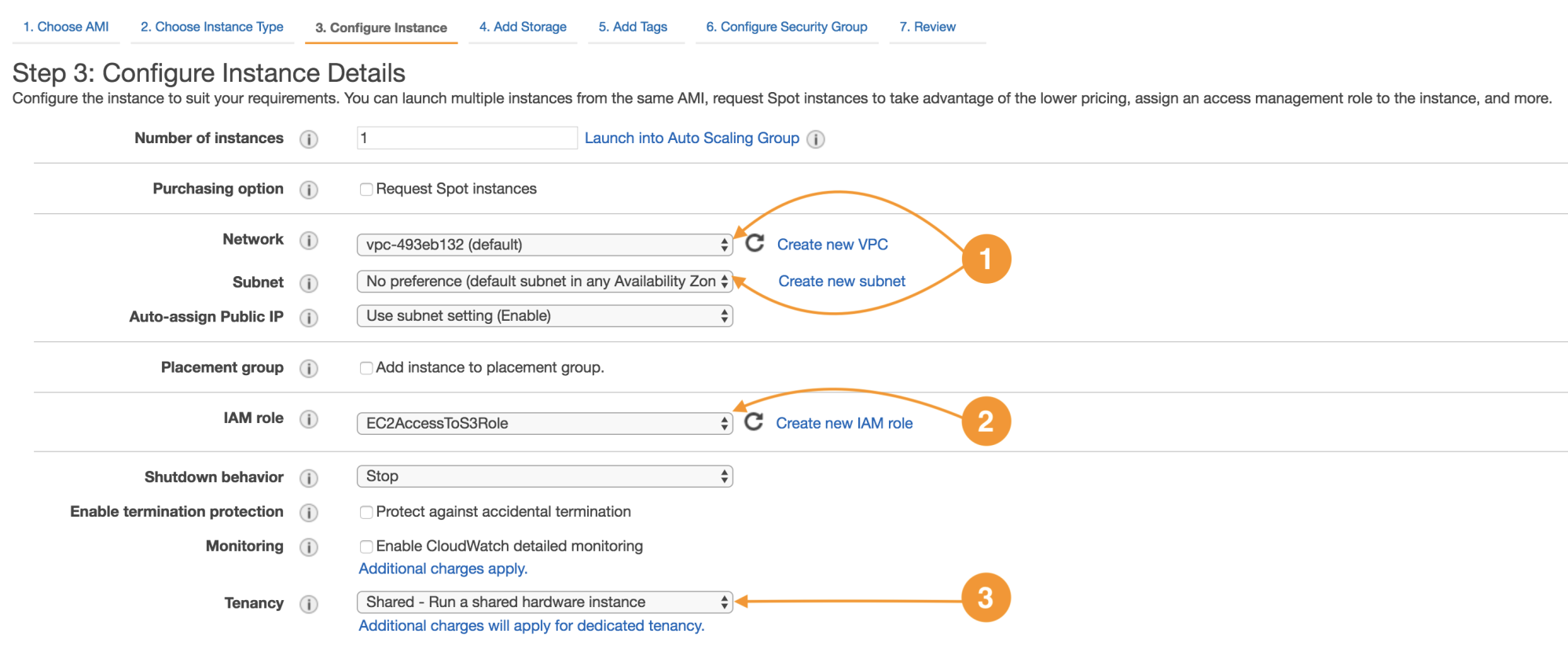
The following are the details of instance configuration:
|
AWS
|
Every instance runs in a virtual private cloud (Network) (1); the network is an infrastructure-protected service, and the customer inherits this protection, which enables workload isolation to the account level. |
|
Customer
|
Is possible to segregate the network by means of public and private subnetting, route tables function as a traffic control mechanism between networks, service endpoints, and on-premises networks. |
|
Customer
|
Identity and Access Management is the service dedicated to user management and account access. IAM Roles are meant to improve security from the customer perspective by establishing trust relationships between services and other parties. EC2AccessToS3Role (2) will allow an instance to invoke service actions on S3 securely to store and retrieve data. |
|
AWS/customer |
The Tenancy property (3) is a shared control by which AWS implements security at some layers and the customer will implement security in other layers. It is common to run your instance in shared hosts (multi-tenant), but it can be done on a dedicated host (single tenant); this will make your workloads compliant with FIPS-140 and PCI-DSS standards. |
The virtual private cloud (VPC) is an example of an inherited control, since AWS runs the network infrastructure; nevertheless, segmentation and subnet configuration is an example of a hybrid control, because the client is responsible for the full implementation by performing a correct configuration and resource distribution.
IAM operations are customer-related, and this represents a specific customer control. IAM roles and all the account access must be managed properly by the client.
Making use of dedicated resources is an example of shared controls. AWS will provide the dedicated infrastructure and the client provides all the management from the hypervisor upwards (operating system, applications).
The highlighted components represent the ones relevant for this example. Add a persistent EBS volume to our EC2 instance:

Security at rest for EBS with KMS cryptographic keys
|
AWS/customer |
EBS volumes can be ciphered on demand by using cryptographic keys provided by the Key Management Service (KMS); this way all data at rest will be kept confidential |
The EBS encryption attribute is an example of a shared control, because AWS will provide these facilities as part of EBS and KMS services, but the client must enable this configuration properties because by default, disks are not encrypted. The customer has the ability to use specific controls such as Linux Unified Key Setup (LUKS) to encrypt EBS volumes with third-party tools:
Create a security group to filter the network traffic:

Detail:
|
AWS/customer |
Security groups act as firewalls at the instance level, denying all inbound traffic and opening access only by customer-specified IPs, networks, ports, and protocols. It is a best practice to compartmentalize access by chaining multiple security groups restricting access on every layer. In this example, we create only one security group for the web server in which will be allowed HTTP traffic from any IP address (0.0.0.0/0) and restricted access via SSH only from a management machine—in this case, my IP. |
This is a hybrid control because the function of network traffic filtering is from AWS, but the full implementation is given by the customer through the service API:

Create a key pair to access the EC2 instance:
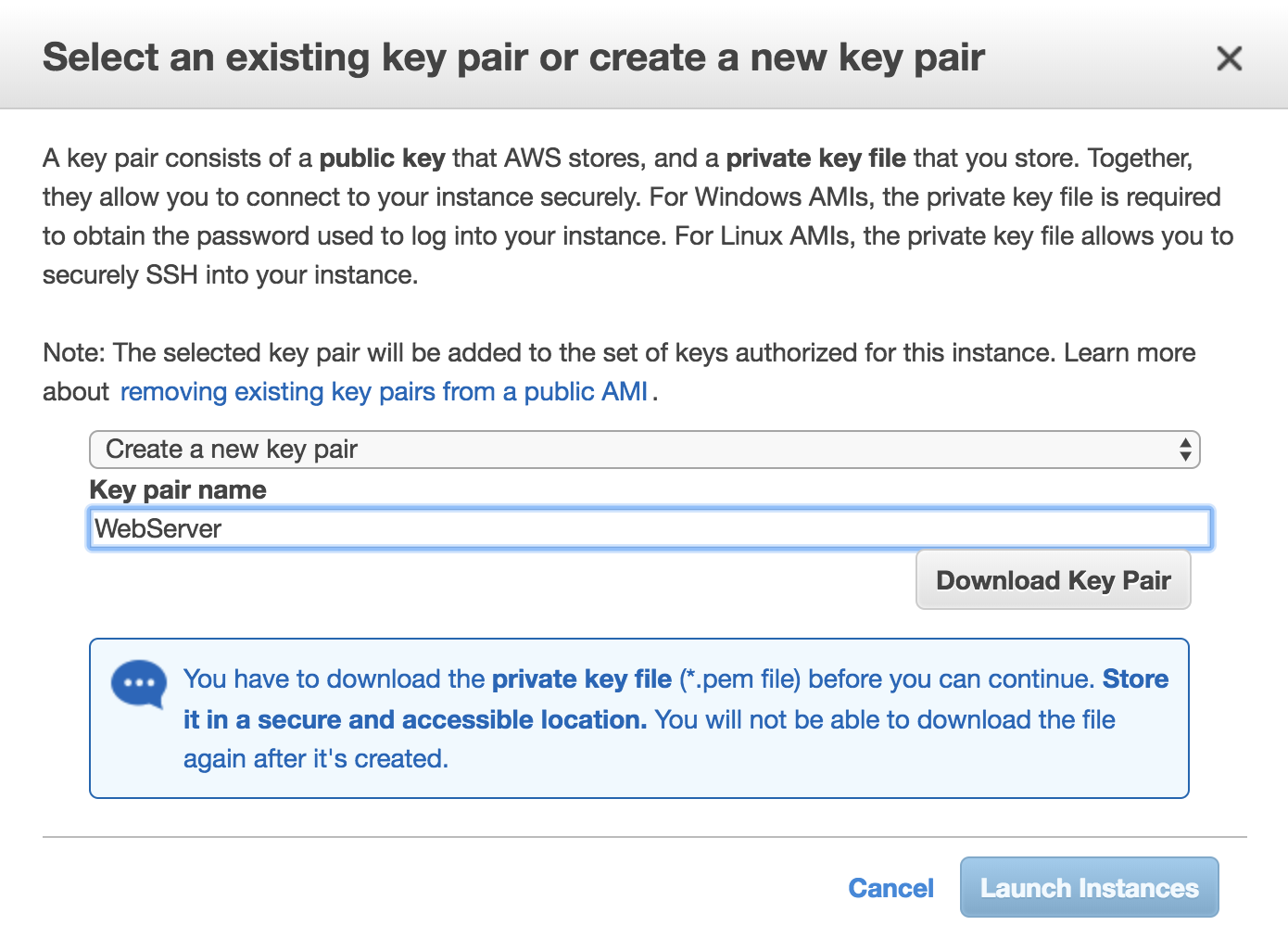
Detail:
|
AWS/Customer |
Every compute instance in EC2, whether Linux or Windows, is associated with a key pair, one public key and one private key. The public key is used to cipher the login information of a specific instance. The private key is guarded by the customer so they can provide their identity through SSH for Linux instances. Windows instances use the private key to decrypt the administrator's password. |
This is a shared control because the customer and AWS keep responsibility for the guarding of these keys and avoid third-party access that does not have the private key in their possession:

The last step has a dual responsibility:
- The customer must protect the platform on which the application will be running, their applications, and everything related to the identity and access management from the app of the middleware perspective.
- AWS is responsible for the storage and protection of the public key and the instance configuration.
Identity and Access Management
Let's discuss the core services to manage security in the AWS account scope. Identity and Access Management (IAM) and CloudTrail. IAM is the service responsible for all the user administration, and their credentials, access, and permissions with respect to the AWS service APIs. CloudTrail will give us visibility on how this accesses are used, since CloudTrail records all the account activity at the API level.
- To enable CloudTrail, you must access the AWS console, find CloudTrail in the services pane and then click on Create trail:

- The configuration is flexible enough to record events in one region only, or cross-region in the same account, and you can even record CloudTrail events with multiple accounts; it is recommended to choose All for Read/Write events:
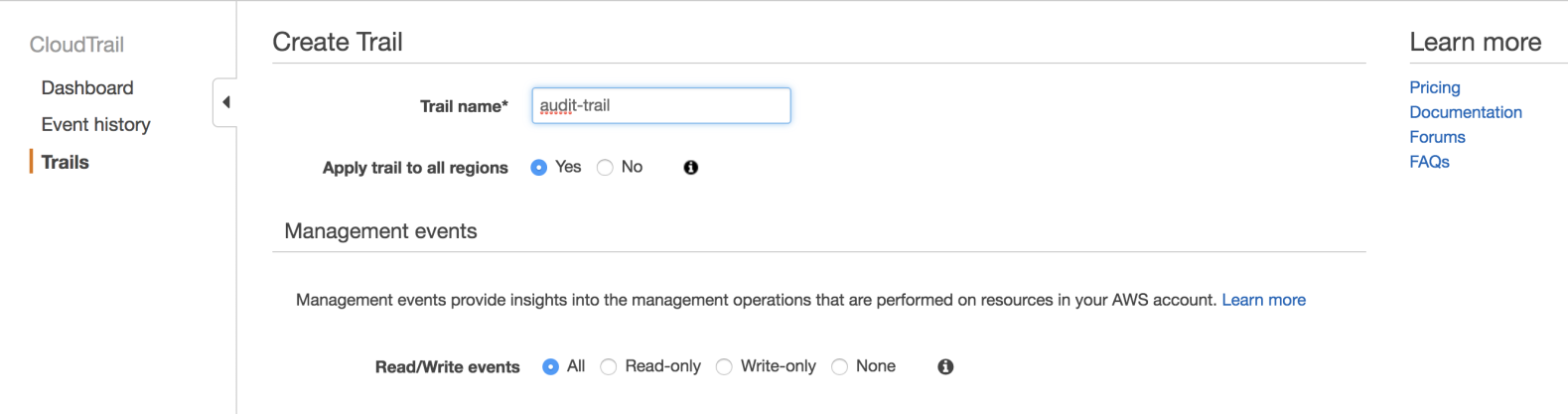
It is important to enable this service initially in newly created accounts and always keep it active because it also helps in troubleshooting when configuration problems occur, when there are production service outages, or to attribute actions to IAM users.
User creation
We will create an IAM user and this user can be used by a person for the purpose of everyday operations. But it can also be used by an application invoking service APIs.
- Let's navigate to the IAM service in the console, choose the left menu Users, and then Add user:
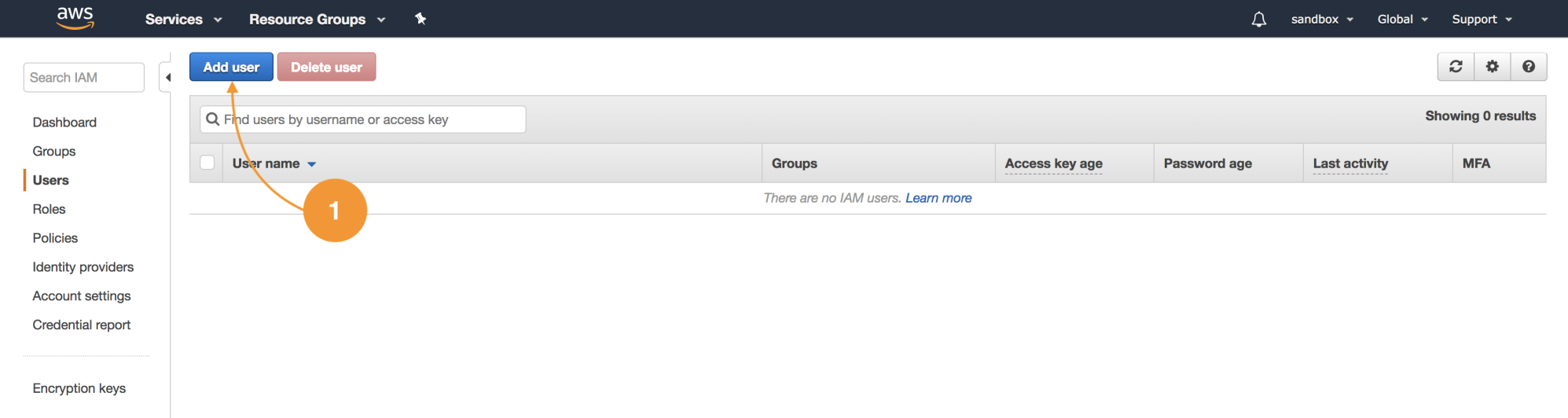
- The user we will create can only access the web console, and for this, we will create credentials that consist of a username and a password:

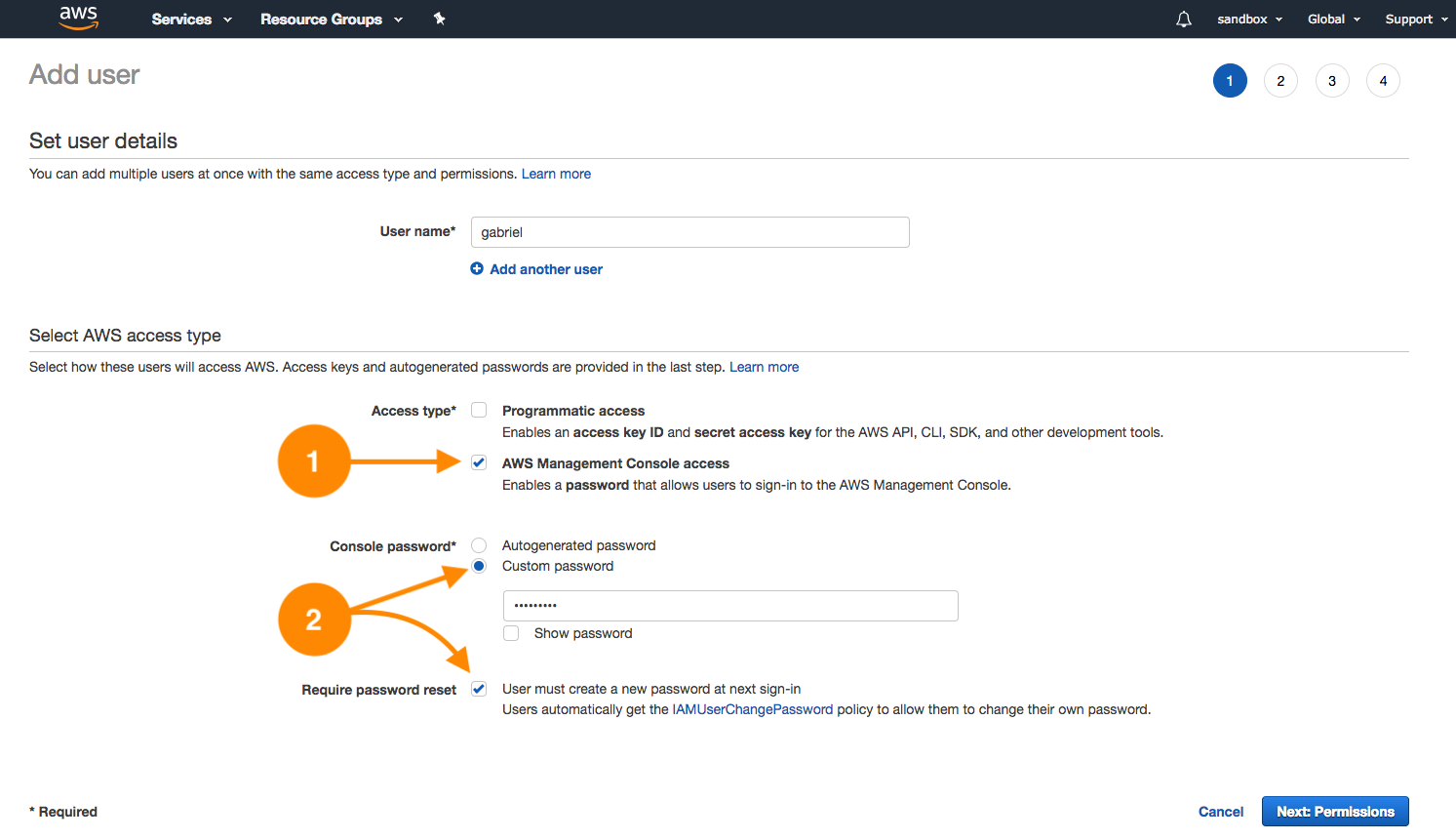
- In this case, check the AWS Management Console access (1) as shown in the next screenshot. You have the possibility to assign a custom password for the user or to generate one randomly. It is a good practice to enable password resetting on the next sign-in. This will automatically assign the policy IAMUserChangePassword (2) that will allow the user to change their own password as shown here:
- Choose Next: Permissions; on this screen, we will leave it as is. Select Create User to demonstrate the default user level that every new user has. The last screen shows us the login data, such as the URL. This URL is different than root access:
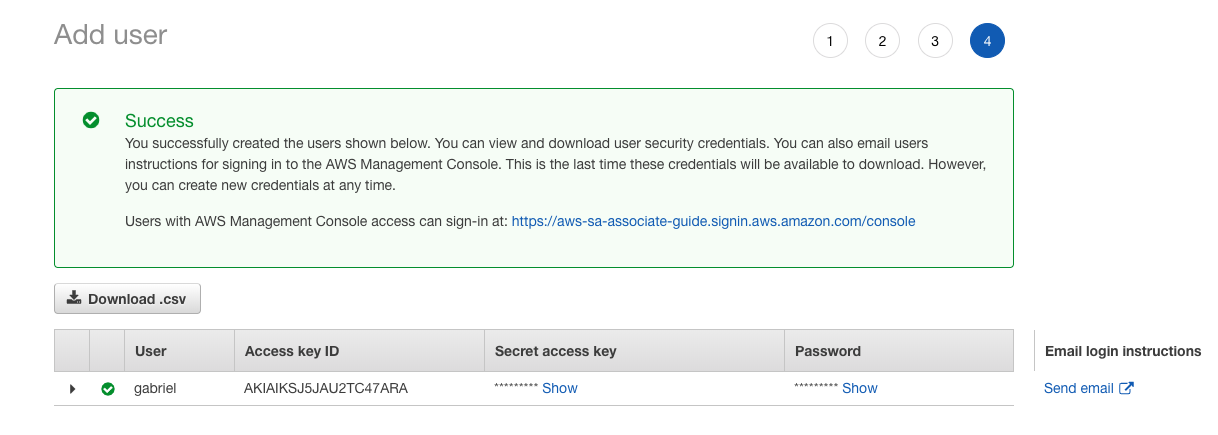
- Copy the URL, username, and password shown in the previous screenshot. The access URL can be customized; by default, it has the account number but it is up to the administrator to generate an alias by clicking Customize:
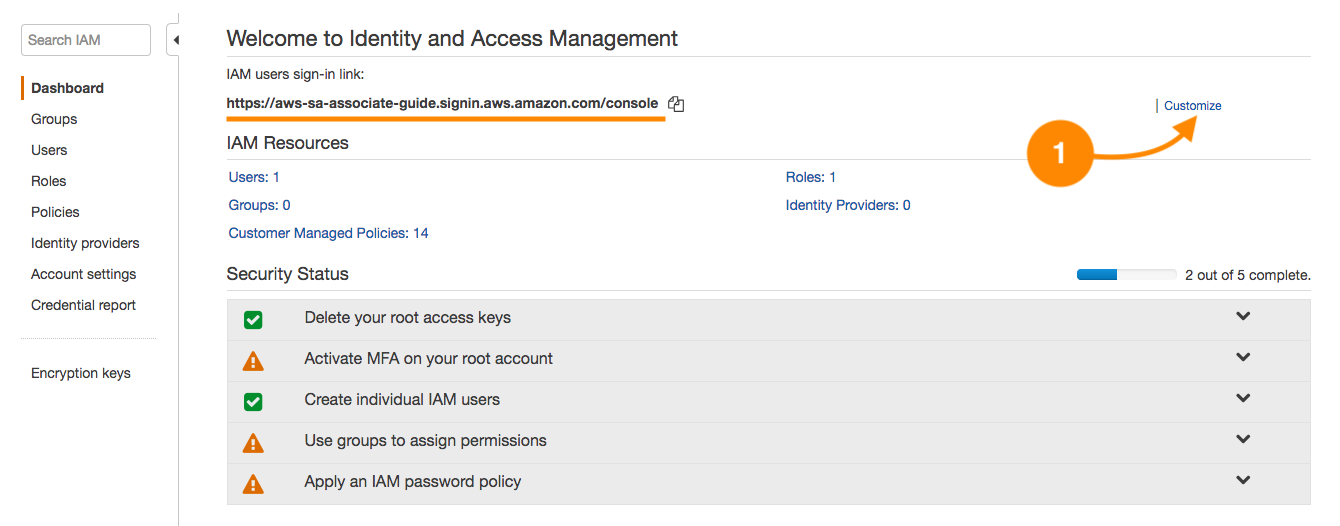
- Close your current session and use the new access URL. You will see a screen like the following:
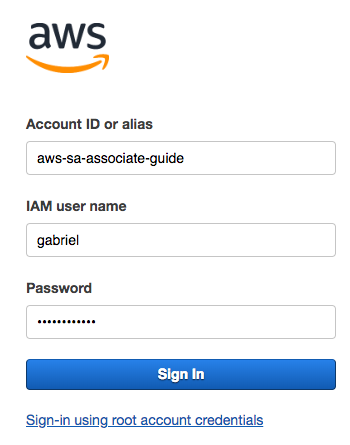
- Use your new IAM administrator username and password; once logged in, search for the EC2 services. You will get the following behavior:

- Let's validate the current access scope by trying to list the account buckets in S3:

This simple test shows up something fundamental about AWS security. Every IAM user, once created, has no permissions; only when permissions are assigned explicitly will the IAM user be able to use APIs, including the AWS console. Let's close this session and log in again; this time, with the root account to create a secure access structure.
Designing an access structure
We will work on the access structure using the following model:
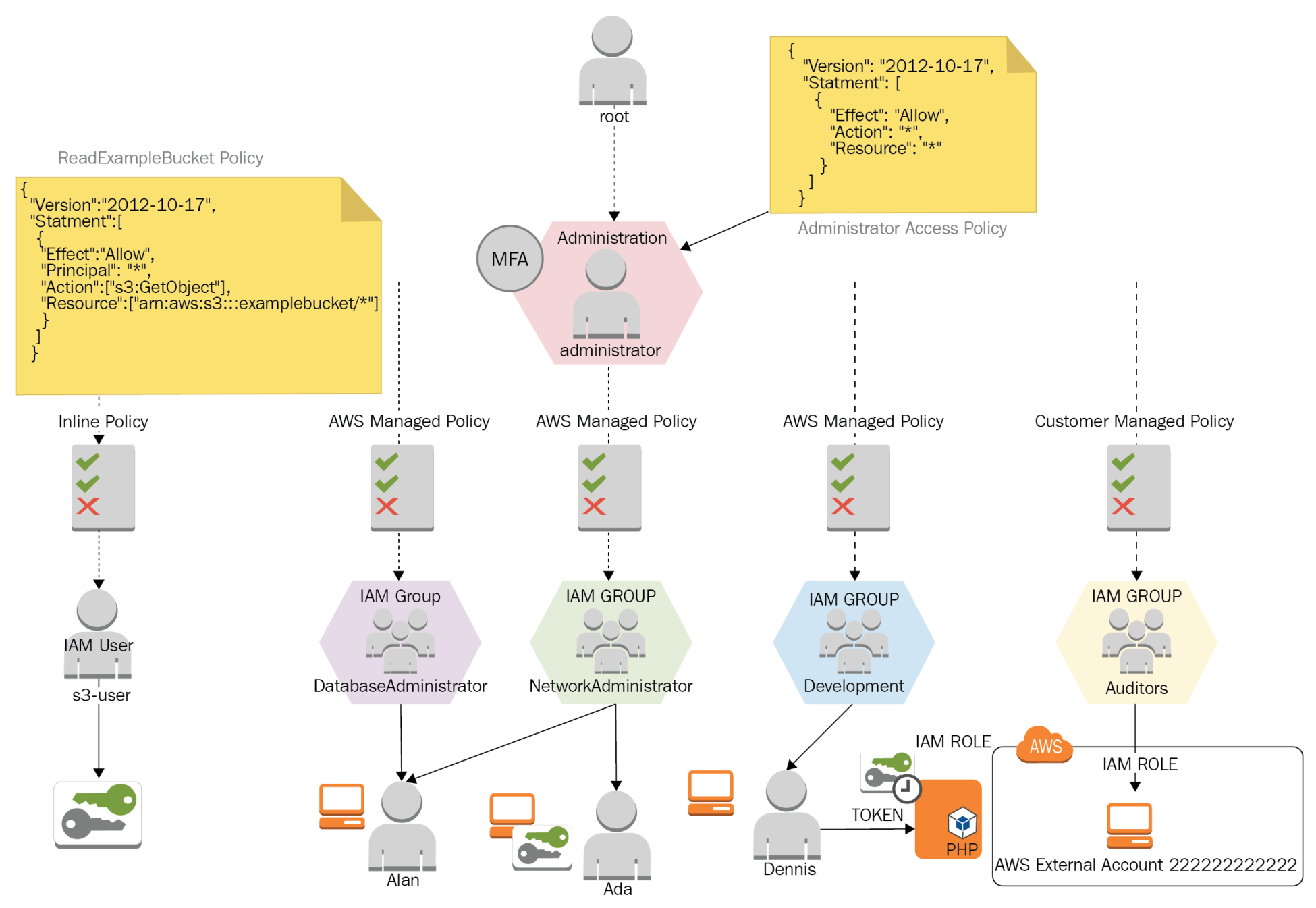
This diagram shows different use cases for IAM Users, IAM Groups, IAM Roles, and the IAM Policies for everyone.
Create an administration group
We will create IAM groups solely for administration purposes, and a unique user that has wide access to this account.
- Navigate to IAM | Groups and then choose the action Create New Group:

- Use the name Administration, and select Next Step. In this screen, we will add an IAM policy. IAM policies are JSON formatted documents that specify granuraly the permissions that an entity has (user, group, role).
- In the search bar of the step, write the word administrator to filter some of the options available for administration policies; the policy we need is called Administrator Access. This policy is an AWS-managed policy and is available for every AWS customer for their use when a full administration policy is required for a principle.
- Select Next Step. This will lead us to the review screen, where we can visually confirm that the administrator policy has been added. This policy has many AWS resources and has a unique Amazon Resource Name as follows:
arn:aws:iam::aws:policy/AdministratorAccess
- Add the group; in the group detail, we can observe that it doesn't have any users in it. Let's add our administrator user. This user must be used instead of the root account.
- Choose the left menu IAM users and create a new user with the name administrator; in this case, we will only choose AWS Management Console access, because, at this time, this user won't be using access keys, only the username and the password, to log into the console.
- In step 2 of the Add User screen, choose the administration group; this way, the user will inherit the AdministratorAccess IAM policy from the group Administration:

- Select Next: Review and Create User. It is now possible to download the comma-separated value (CSV) file with the access data for this user. Again, copy the access URL for this user and close the root session; from now on, we will be using only the administrator user created. The login screen must be similar to this:
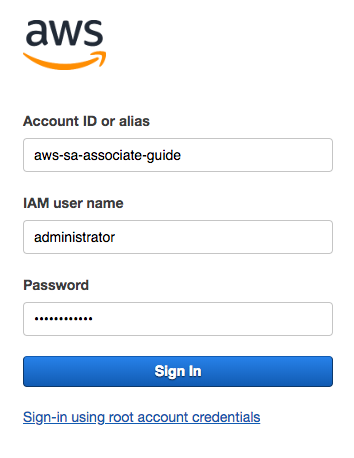
- Once the login data is entered, we will be required to change the temporary password, guaranteeing confidentiality. Now that we are logged in as an IAM user, we can confirm, because the top bar has changed to administrator@account as shown:

Business case
Ada is a network administrator; part of her activities consist of provisioning virtual networks (VPCs), subnets, configuring route tables, managing hosted zones for domains in Route 53, and managing logs of the network traffic.
Ada supports database and development areas in the provisioning of infrastructure and network resources, but she should not be able to create compute resources as EC2 instances and EBS volumes.
Alan is a DBA, and most of his tasks are performance monitoring, checking database logs, provisioning databases, and performing full database backups on S3. This user must be able to read network parameters for each database instance and troubleshoot issues in production databases.
Alan will work with the AWS console because most of the monitoring operations are made from a web environment and other DBAs just using a vendor-specific driver. We will create a database administrator group, because, this way, the administration is centralized. By doing this, we can control and maintain all the security aspects in one spot; this is a better approach than having to manage tens or hundreds of users independently.
Let's create four groups and three users with the following details:
|
Function |
IAM group name |
IAM policy |
IAM user |
|
IAM User |
DatabaseAdministrator |
DatabaseAdministrator |
Alan |
|
IAM User |
NetworkAdministrator |
NetworkAdministrator |
Ada |
|
IAM Service Role |
Development |
- |
Dennis |
|
IAM Cross Account |
Auditors |
SecurityAudit |
- |
Alan must support Ada's activities temporarily while she is out of the office for vacations, so we need to add Alan to the network administrator group. The set of permissions Alan will have are the union of both groups.
IAM groups allow a user to become a member of one or more groups, as groups exist at the same level. It's impossible to nest a group inside another group.
Dennis is the member of the development team and he must be able to create EC2 instances. He must also be able to create EC2 service roles that permit cross-service access. These IAM roles give the ability to impersonate the access to services and avoid the usage of explicit access keys when applications interact via CLI or programmatically to authenticate APIs. The application Dennis will deploy consists of a .NET application that uses the AWS SDK and accesses an S3 bucket to store and retrieve data. To achieve this, the IAM role S3AccessToEC2Role must be created via IAM. This instance role and profile will internally require temporal credentials via the security token service (STS):
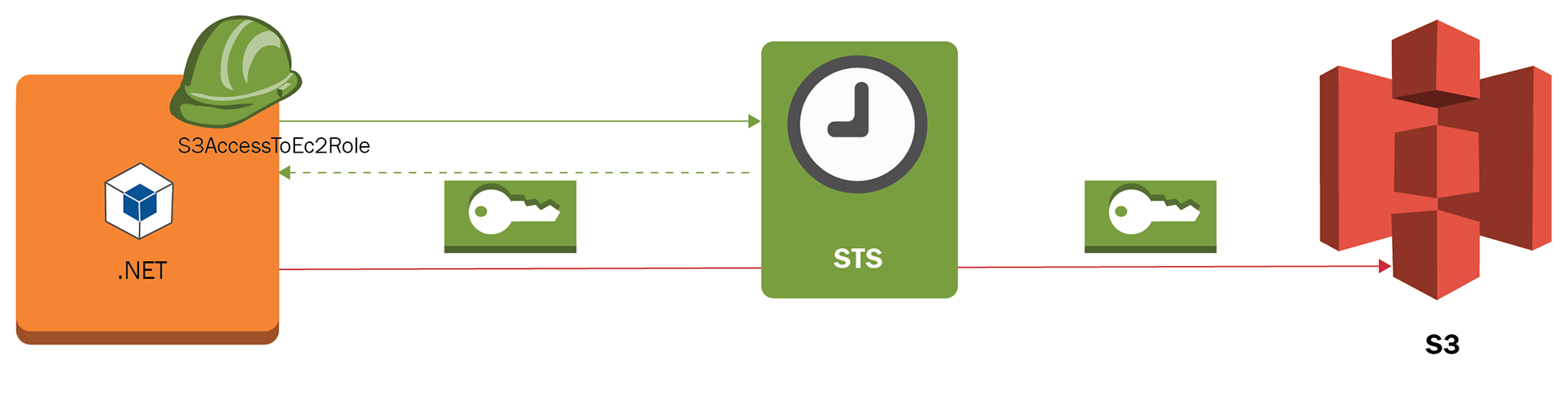
The practice of not using ACCESS_KEY and SECRET_ACCESS_KEY credentials will prevent other parties from using them if they are found in the filesystem or in the application configuration files.
Our user Dennis must be able to create instances and IAM roles for applications. Dennis will make use of an IAM policy inherited via the development group and will be given the permissions needed to create instance roles and pass IAM roles to services. Let's create this policy, so it can be attached to the development group.
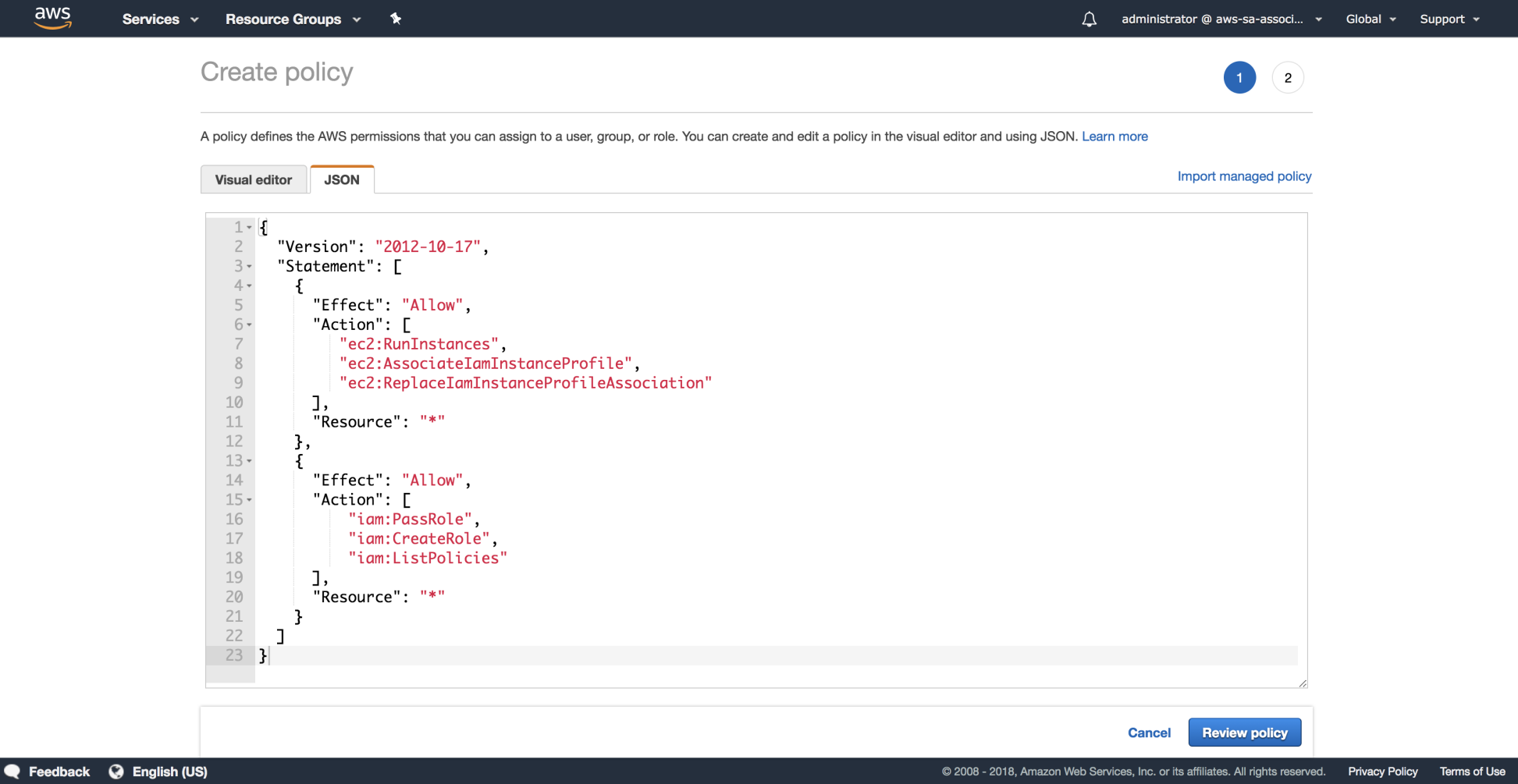
- Navigate to IAM | Policies | Create policy and choose the JSON tab and paste the document available under this file: https://github.com/gabanox/Certified-Solution-Architect-Associate-Guide/blob/master/chapter00/RoleCreatorPolicy.json:
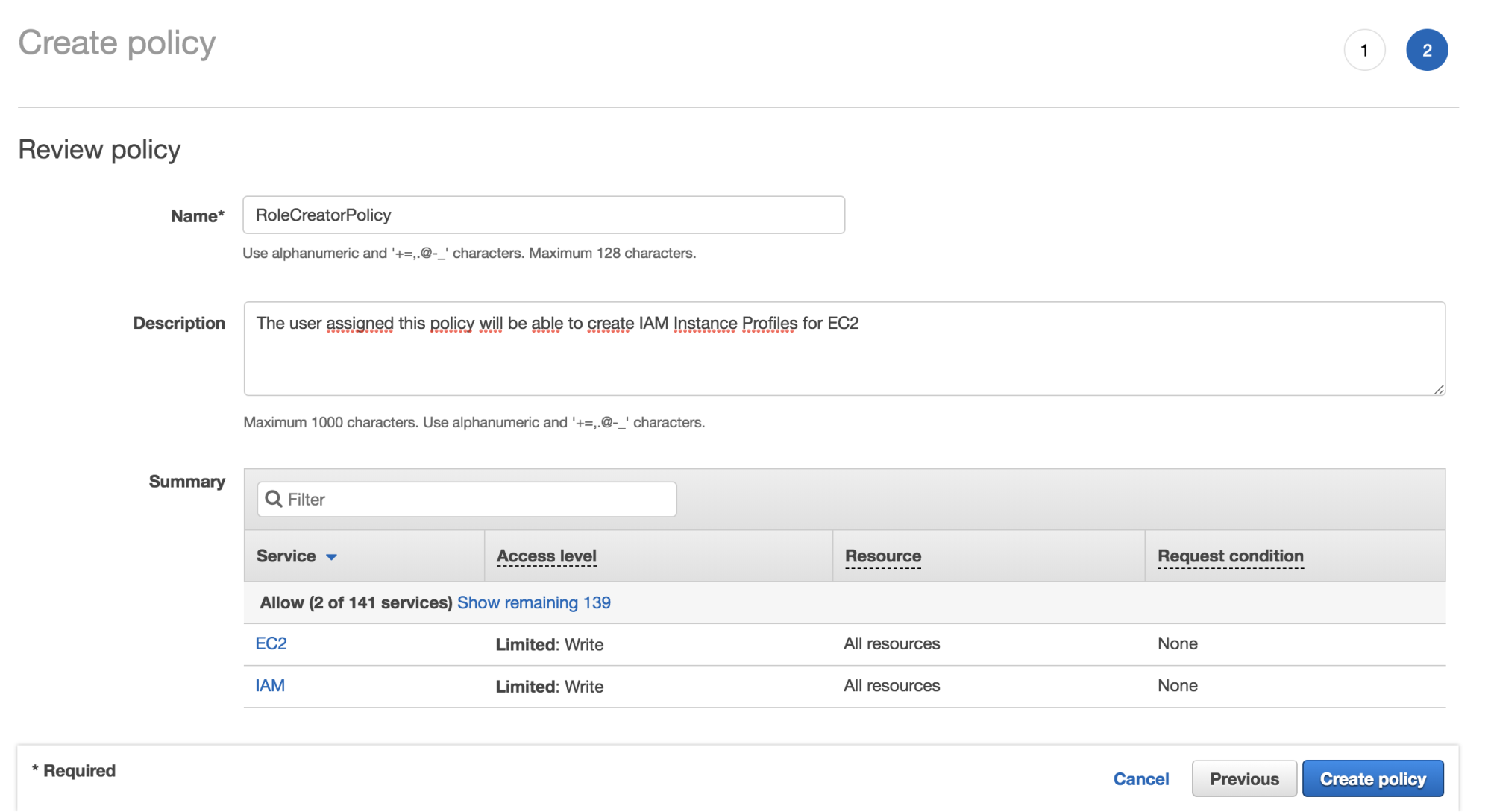
- We are required to specify a Name and Description for the new IAM policy:
- Once we have created our policy, let's associate it with the development group. On the IAM Policies listing, we have the option to filer by name (1); in this case, this policy was created globally in this account and can be reused. Choose Customer managed or use the search box to find it:
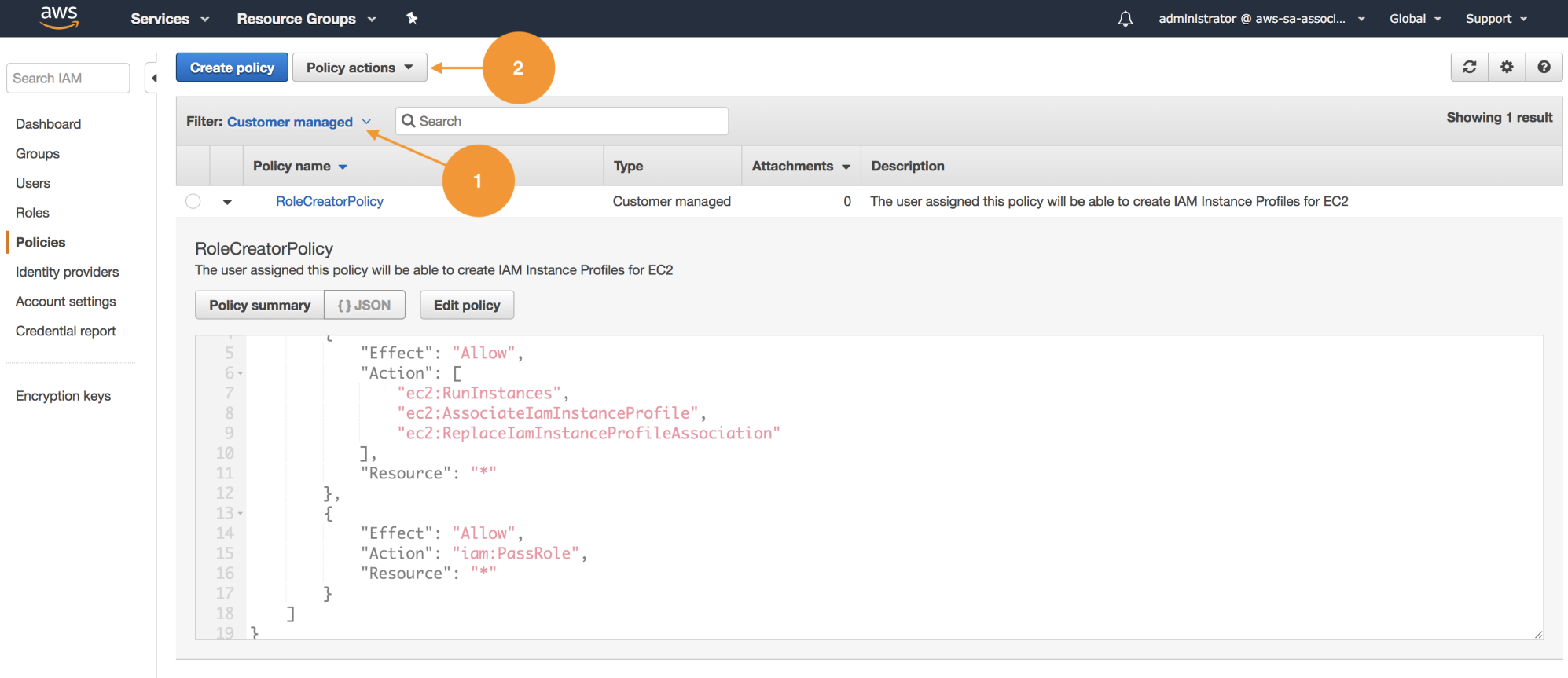
- Once we choose the policy, select Policy Actions and use the function attach (2), as shown in the preceding screenshot; this will redirect us to the detail, where we can use attached entities and associate them with the development group as shown:

- Again, let's use the policy filter choosing AWS managed until we find AmazonEC2FullAccess. Repeat the process to attach this policy to the development group. This way, Dennis will be able to create EC2 instances and associate the appropriate instance role:

- Close the current session and log in with Dennis' credentials. Let's navigate to the IAM section and proceed to create a new role. The service that will use this role is EC2:
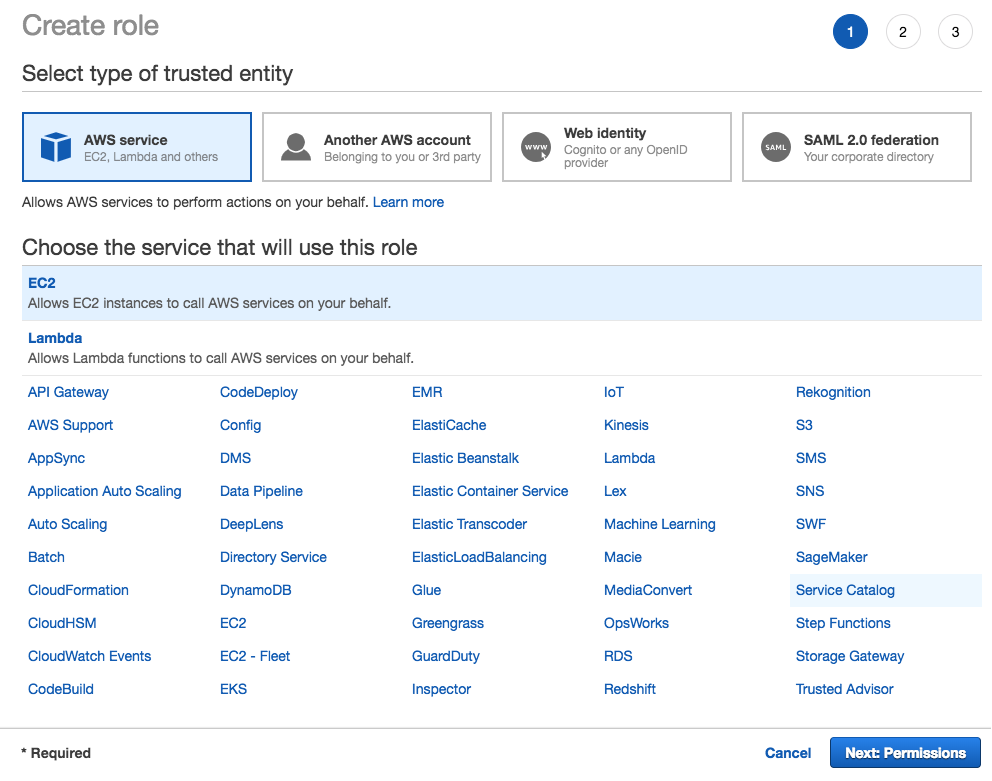
- Under permissions, search for s3 in the search box and add the policy AmazonS3FullAccess:

- Name the role EC2ToS3InstanceRole and click Create:

- Spin a new EC2 instance in step 3 of the EC2 wizard, under Configure Instance, and make sure to select EC2toS3InstanceRole:

At this point, if you have some problem creating this users structure, you can run the following script from the command line.
- First, make sure that you have access keys configured; if they aren't, use aws configure
- Download the following script and set execution permissions with chmod +x checkpoint.sh from your terminal: https://github.com/gabanox/Certified-Solution-Architect-Associate-Guide/blob/master/chapter00/checkpoint1.sh
Inline policies
As the administrator, navigate to the S3 service in the console, and create a bucket with a unique name. After that, upload a text file with any kind of content using the upload button.
Write down the bucket name, as you will use it later.
- We will create an IAM user with CLI-only access and a policy that only allows reading objects. Use the name s3-user as shown in the next screenshot, and in the fourth step of the Add user wizard, download the access credentials CSV file:
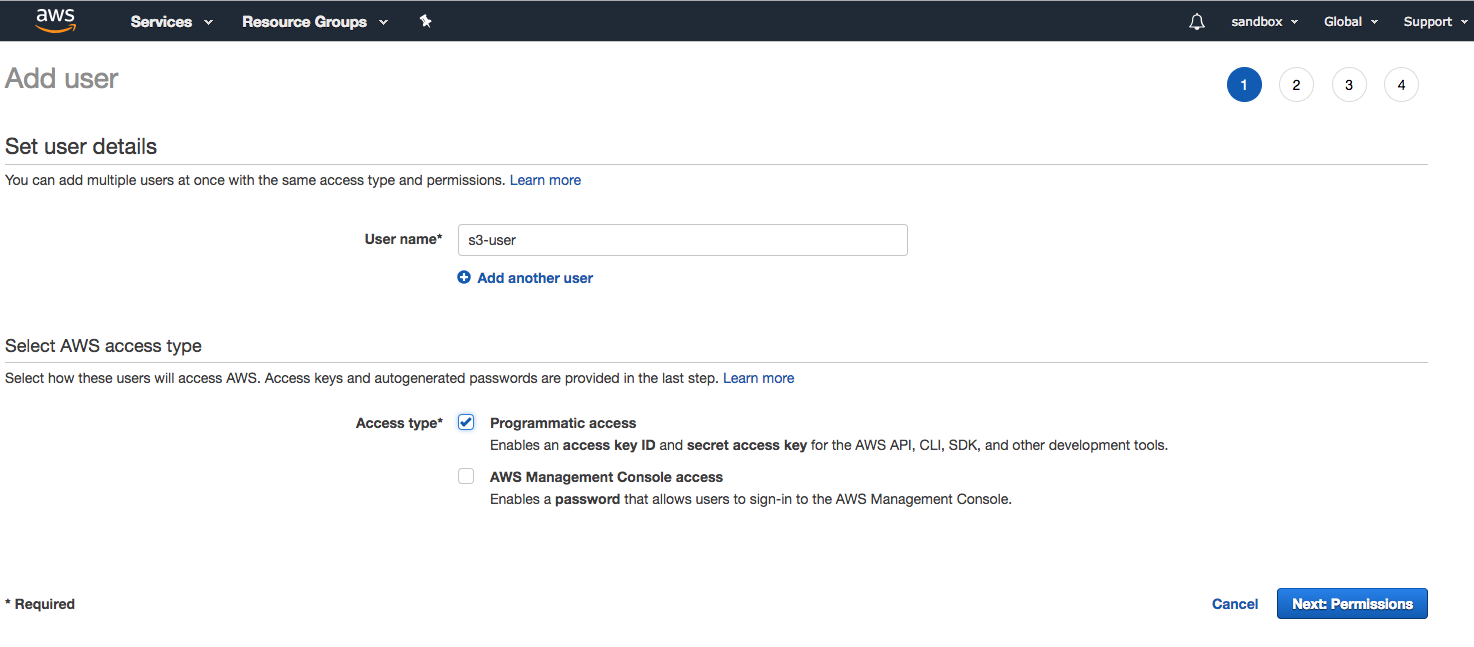
- Make sure Programmatic access is enabled; we will create this user without any kind of permissions at first. Once created, the user will be assigned an inline policy; these policies cannot be reused with other users because they are defined only once and attached directly to users and groups.
- Under the Users section in IAM, select the s3-user and Add inline policy as shown here:
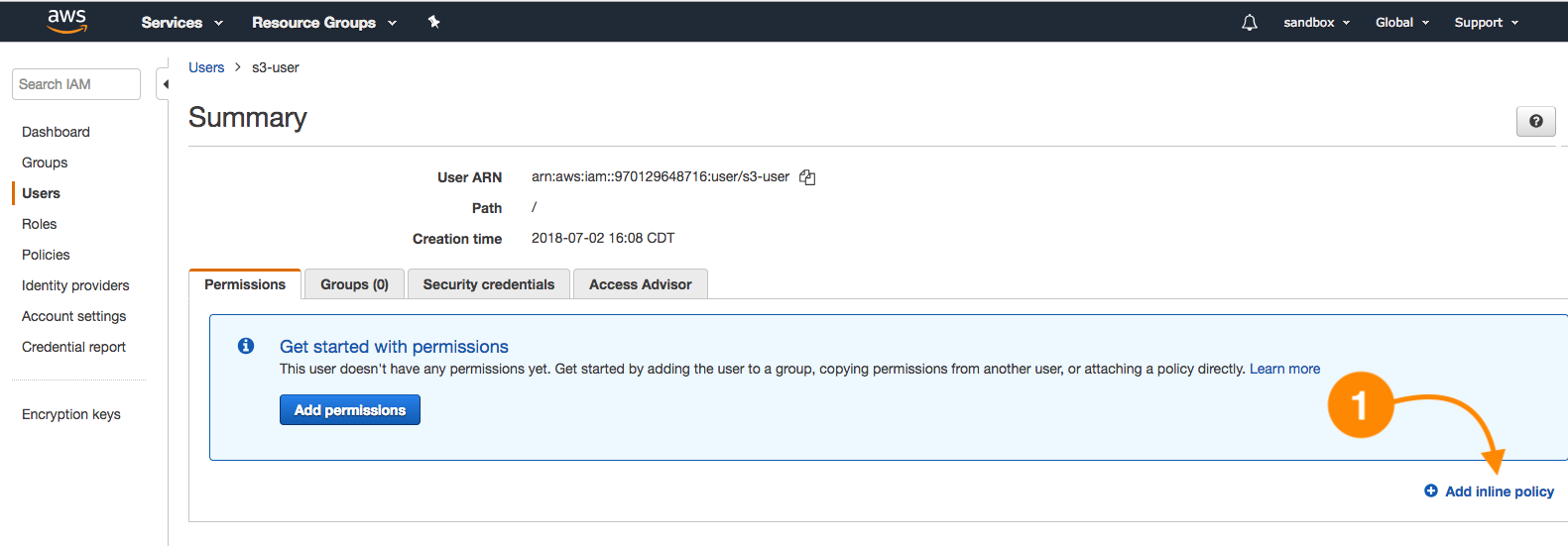
- Use the visual editor, in this case by choosing S3 as the service (1). Under Actions, select only GetObject (2), and for the resources section, select Specific and Add ARN (3), writing down the bucket name and the option Any:

- To configure the access credentials via CLI, open a terminal and paste the following command replacing the values for aws_access_key_id and _aws_secret_access_key with your own (the s3-user CSV file values):
aws configure set profile.s3-user.aws_access_key_id "AKIAXXXXXXXXXXXXXXXXX"
aws configure set profile.sqs-user.aws_secret_access_key "ZuEVD4DDyK1TsmNp/Pa6toR/Qf3FfUN0t/XXXXXX"
- The following command will allow the download operation (a read) to the local filesystem:
aws s3 cp s3://example-bucket-20180602/test-object.txt --profile s3-user .
The structure of this command is as follows:
aws s3 cp <LocalPath> <S3Uri> or <S3Uri> <LocalPath> or <S3Uri> <S3Uri> ...
This way, we are using the copy subcommand and validating that the S3 user has read-only access to objects.
IAM cross-account roles
An external auditors group requires read-only access to the account so they can inspect API activity on the account. These auditors are a company that has an AWS account, but to follow the less-privileged principle, we will use a role with an AWS Managed Policy called SecurityAudit, plus the AWSCloudTrailReadOnlyAccess. This way, there won't be a necessity to create an additional user in the audited account, but this account can define the level of permissions necessary to let external auditors perform their task.
This task requires an additional AWS account, so this is only demonstrative. Also, take into account that only IAM users are allowed to perform the AssumeRole action.
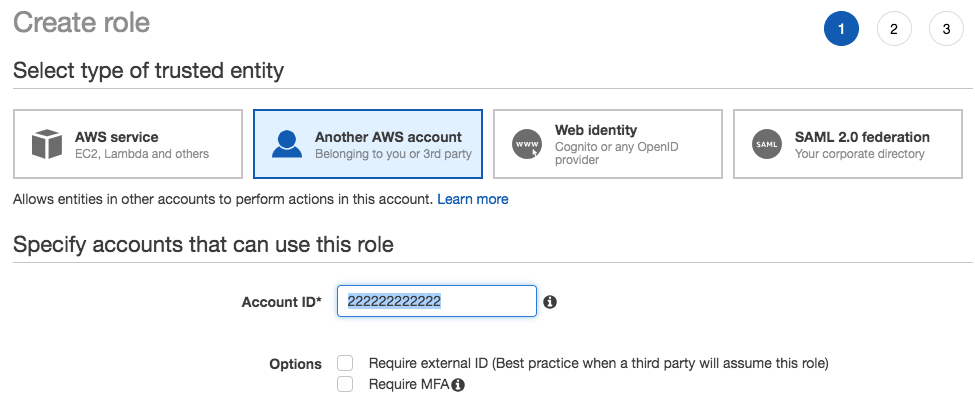
- As an administrator, navigate to IAM and create a role. On the type of trusted entity, choose Another AWS account. For this demo, I will use a hypothetical account number. The IAM role used in this scenario is called delegation:

We have two accounts, the Production Account (11111111111), which will have the cross-account role created, and the access policy for this external audit user, and the Sandbox Account (222222222222), the one that will assume the external role to access AWS APIs; in this case, Cloud trail.
- The next step is to create the cross-account role in the production account. The type of trusted entity is Another AWS account, and we will specify the trusted account number (sandbox):
External auditors will also have read-only access to Cloud trail:

- Select the role created to review the details; by default, it is configured to allow broad access using the root principal as the trusted entity.
- Edit this trust relationship as shown next, and specify our IAM user in this case administrator (it could be a member of the audit group):

Now, in the sandbox account, we need to configure the audit-role this account will assume. This can be done in the current user upper menu as follows:
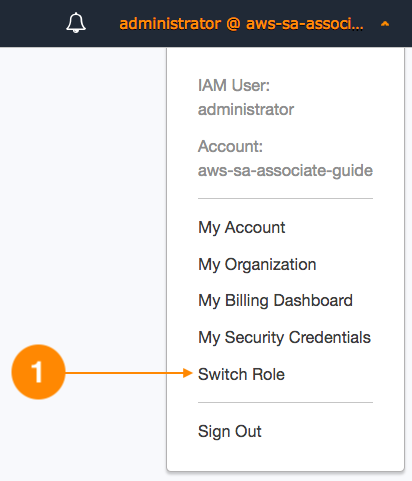
In the next screen, you will be prompted to specify the requested account (production), the name of the external role to assume, and a friendly name:

- Now, we can see our role-friendly name listed under Role History; once we assume this identity, our web console will display the production account data and the top menu will change to display the current assumed role:

- To end this lesson under Cloud trail, it is possible to see all the API events since logging was activated for the account:

As a complementary activity, it is recommended to enable Multi-Factor Authentication (MFA); you can provision this 2FA by downloading Google Authenticator from your mobile app store.
Summary
This chapter is the formal introduction to Amazon Web Services; you have learned about cloud design principles, patterns, frameworks, and best practices for AWS architecture. You will put security in practice by designing an access structure for a business case for several kinds of users, manage them via groups, and enable cross-account roles.
Further reading
- Understanding Cloud Design Patterns: http://en.clouddesignpattern.org/index.php/Main_Page
- The AWS Cloud Adoption Framework: https://aws.amazon.com/es/professional-services/CAF/
- AWS architecture well framework: https://aws.amazon.com/es/architecture/well-architected/
- Architecting for the Cloud (AWS Best Practices): https://d1.awsstatic.com/whitepapers/AWS_Cloud_Best_Practices.pdf
- AWS - Overview of Security Processes: https://d1.awsstatic.com/whitepapers/Security/AWS_Security_Whitepaper.pdf






