


















ASP.NET Core—the redesign of ASP.NET from Microsoft—is the server-side web application development framework which helps you to build web applications effectively. This runs on top of the .NET Core platform, which enables your application to be run on a wide variety of platforms, including Linux and macOS. This opens up heaps of opportunities and it is exciting to be a .NET developer in these times.
By the end of this chapter, you will be able to:
- Explain the fundamental concepts about web applications—HTTP, client side, and server side
- Explain the three programming models of ASP.NET MVC
- Get to grips with the philosophy of ASP.NET MVC
- Create your first ASP.NET Core Web Application project and project structure
Before discussing the ASP.NET Core and its features, let us understand the fundamentals of web application development.
Note
Remember this principle: If you want to be an expert at something, you need to be very good at the fundamentals.
All web applications, irrespective of whether they are built using ASP.NET MVC (MVC stands for Model-View-Controller), which is actually inspired by the success of Ruby on Rails, or any other new shiny technology, work on the HTTP protocol. Some applications use HTTPS (a secure version of HTTP), where data is encrypted before passing through the wire. But HTTPS still uses HTTP.
Symmetric encryption is the conventional method to ensure the integrity of the data transferred. It makes use of only one secret key, called a symmetric key, for both encryption and decryption. Both the sender and receiver possess this key. The sender uses it for encryption, while the receiver uses it for decryption. Caesar's Cipher is a good example of symmetric encryption.
Asymmetric encryption makes use of two cryptographic keys. These keys are known as public and private keys. The information to be sent is encrypted by the public key. The private key is used to decrypt the information received. The same algorithm is behind both of these processes. The RSA algorithm is a popular algorithm used in asymmetric encryption.
Encryption ensures the integrity of the data transferred by making use of cryptographic keys. These keys are known only by the sender and the receiver of the data being transferred. This means that the data won't be tampered by anyone else. This prevents man-in-the-middle attacks.
A protocol is nothing but a set of rules that govern communication. The HTTP protocol is a stateless protocol that follows the request-response pattern.
HTTP stands for HyperText Transfer Protocol and is an application protocol which is designed for distributed hypermedia systems. HyperText in HyperText Transfer Protocol refers to the structured text that uses hyperlinks for traversing between the documents. Standards for HTTP were developed by the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C). The current version of HTTP is HTTP/2 and was standardized in 2015. It is supported by the majority of web browsers, such as Microsoft Edge, Google Chrome, and Mozilla Firefox.
- Is binary, instead of textual
- Is fully multiplexed, instead of ordered and blocking
- Uses one connection for parallelism
- Uses header compression to reduce overhead
- Allows servers to push responses proactively into client caches
Before talking about the request-response pattern, let's discuss a couple of terms: client and server. A server is a computing resource that receives the requests from the clients and serves them. A server, typically, is a high-powered machine with huge memory to process many requests. A client is a computing resource that sends a request and receives the response. A client could typically be any application that sends the requests.
Coming back to the request-response pattern, when you request a resource from a server, the server responds to you with the requested resource. A resource could be anything—a web page, text file, image, or another data format.

You fire a request. The server responds with the resource. This is called a request-response pattern.
When you request for the same resource again, the server responds to you with the requested resource again without having any knowledge of the fact that the same was requested and served earlier. The HTTP protocol inherently does not have any knowledge of the state of any of the previous requests received and served. There are several mechanisms available that maintain the state, but the HTTP protocol does not maintain the state by itself. We will explain the mechanisms to maintain the state later.
Here are the few advantages of using HTTP protocol:
- HTTP is a text-based protocol that runs on top of TCP/IP
- HTTP is firewall-friendly
- HTTP is easier to debug since it is text based
- All browsers know about HTTP. Thus, it is extremely portable on any device or any platform
- It standardizes the application-level protocol into a proper request–response cycle
With the help of a simple practical example, let's work with the statelessness and the request-response pattern. Here are the steps:
- Type this URL: https://en.wikipedia.org/wiki/ASP.NET_Core. This is a Wikipedia web page about ASP.NET Core.
- From the preceding URL, the browser fires a request to the Wikipedia server.
- The web server at Wikipedia serves you the ASP.NET Core web page.
- Your browser receives that web page and presents it.
- Now, request the same page again by typing the same URL again (https://en.wikipedia.org/wiki/ASP.NET_Core) and pressing Enter.
- The browser again fires the request to the Wikipedia server.
- Wikipedia serves you the same ASP.NET Core web page without being aware of the fact that the same resource was requested previously.
- Here's a screenshot from the Wikipedia page showing requests and responses:

It is necessary to understand the client side and server side of web applications and what can be done on either side. With respect to web applications, your client is the browser and your server could be the web server/application server.
The client side is whatever that happens in your browser. It is the place where your JavaScript code runs and your HTML elements reside.
The server side is whatever happens at the server at the other end of your computer. The request that you fire from your browser has to travel through the wire (probably across the network) to execute some server-side code and return the appropriate response. Your browser is oblivious to the server-side technology or the language your server-side code is written in. The server side is also the place where your C# code resides.
Let us discuss some of the facts to make things clearer:
- Fact 1: All browsers can only understand HTML, CSS (Cascading Style Sheets), and JavaScript, irrespective of the browser vendor:
- You might be using Microsoft Edge, Firefox, Chrome, or any other browser. Still, the fact is that your browser can understand only HTML, CSS, and JavaScript. It cannot understand C#, Java, or Ruby. This is the reason why you can access the web applications built using any technology by the same browser:

- Fact 2: The purpose of any web development framework is to convert your server-side code to HTML, CSS, and JavaScript:
- This is related to the previous point. As browsers can only understand HTML, CSS, and JavaScript, all the web development technologies should convert your server-side code to HTML, CSS, and JavaScript so that your browser can understand. This is the primary purpose of any web development framework. This is true whether you build your web applications using ASP.NET MVC, ASP.NET Web Forms, Ruby on Rails, or J2EE. Each web development framework may have a unique concept/implementation regarding how to generate the HTML, CSS, and JavaScript, and may handle features such as security performance differently. But still, each framework has to produce the HTML, because that's what your browsers understand.
Basically, there are two common styles when programming HTTP: Remote Procedure Calls and REST. Let's look at each here:
- Remote Procedure Calls: In the RPC style, we usually treat HTTP as a transport medium and do not focus on HTTP itself. We are simply piggybacking on HTTP. Our service provides some set of operations that are callable directly. In other words, from our client, we call methods as if we are calling normal methods and passing parameters. Usually, RPC is applied via SOAP (Simple Object Access Protocol), which is another XML protocol that runs on top of HTTP. RPC was popular before 2008, and these days the RESTful approach is more popular, since RPC style introduces more coupling between client and server.
- REST: REST stands for Representational State Transfer. In REST, we use URLs to represent our resources, such as
https://api.example.com/books/. This URL is basically an identifier for a book collection. And for example, the following could be an identifier for the book with ID 1:https://api.example.com/books/1.
Then, we use HTTP verbs to interact with these resources. HTTP verbs and HTTP methods are synonyms. The available methods in HTTP are GET, HEAD, POST, PUT, DELETE, TRACE, OPTIONS, CONNECT, and PATCH. So, when we make an HTTP request with GET, we are basically asking the web server to return that resource representation. And that representation can change, even for each request.
The server can return XML for one request and JSON for another, depending on what a client accepts, which is specified by the Accept header.
Why do we need REST? It is all about standardization. Suppose that we access a resource by using the GET verb; we inherently know that we are not altering anything in the server. Similarly, when we send a request via PUT, we inherently know that the requests are idempotent, meaning duplicate requests won't change anything to the same resource. Once we have this standard established, our application behaves like a browser. Just like a browser does not need documentation of an API while walking through the pages, our applications will not need documentation, but only adhere to the standards.
HTTP defines methods (sometimes referred to as verbs) to indicate the desired actions to be performed on the identified resources. It is a part of HTTP specification. Even though all the requests of the HTTP protocol follow the request-response pattern, the way the requests are sent can vary from one to the next. The HTTP method defines how the request is being sent to the server.
The available methods in HTTP are GET, HEAD, POST, PUT, DELETE, TRACE, OPTIONS, CONNECT, and PATCH. In most of the web applications, the GET and POST methods are widely used. In this section, we will discuss these methods. Later, we will discuss other HTTP methods on a need-to-know basis.
GET is a method of the HTTP protocol which is used to get a resource from the server. Requests which use the GET method should only retrieve the data and should not have any side effect. This means that if you fire the same GET request again and again, you should get the same data, and there should not be any change in the state of the server as a result of this GET request.
In the GET method, the parameters are sent as part of the request URL and will therefore be visible to the end user. The advantage of this approach is that the user can bookmark the URL and visit the page again whenever they want. An example is https://yourwebsite.com/?tech=mvc6&db=sql.
We are passing a couple of parameters in the preceding GET request. tech is the first parameter, with the value mvc6, and db is the second parameter, with the value sql. Assume your website takes the preceding parameters with values and searches in your database to retrieve the blog posts that talk about mvc6 and sql before presenting those blog posts to the user:

The disadvantage of the GET method is that, as the data is passed in clear text in the URL as parameters, it cannot be used to send sensitive information. Moreover, most browsers have limitations on the number of characters in the URL, so, when using GET requests, we cannot send large amounts of data.
The POST request is generally used to update or create resources at the server, as well as when you want to send some data to be processed by the server. Especially in the context of REST, it is more accurate to consider POST as a process rather than Create.
Data is passed in the body of the request. This has the following implications:
- You can send relatively sensitive information to the server, as the data is embedded in the body of the request and it will not be visible to the end user in the URL. However, note that your data is never truly secure unless you use HTTPS. Even if you send the data within the request body, without HTTPS, it is very easy for someone in the middle to eavesdrop on your data.
- As the data is not sent through the request URL, it does not take up space in the URL, and it therefore has no issues with the URL length limitations:

As we have covered the fundamentals, we can now proceed to discuss ASP.NET.
Before we discuss the HTTP methods, let's review three aspects of HTTP verbs:
- Idempotency: Idempotency is an important concept in HTTP calls. In idempotent requests, you can change the server-side state (however, only once). That is, if you make multiple idempotent requests to the server, the net effect will be as if you have done one request.
- Safety: Safe requests simply do not cause any side effects. They are only used to retrieve data. By side effects, we refer to any persistent changes in memory or database or any other external system. Registering a user is a side effect. Making a money transfer is a side effect. But viewing user information is not a side effect.
- Cacheablity: Server or client or proxies can cache the responses for the requests.
The following table lists the important HTTP methods and their aspects:
Method | Description | Idempotent | Safe | Cacheable |
| Reads a resource. | Yes | Yes | Yes |
| Creates a resource or triggers a process. | No | No | No |
| Puts something onto a resource ID. Overrides if something exits. Not to be confused with an update. | Yes | No | No |
| Updates a part of a resource. | No | No | No |
| Removes a resource. | Yes | No | No |
In the preceding table, we can see that the GET method is the only safe method. And that's why, for example, search engines like Google only use GET methods to scan our side. Adhering to this standard makes sure nothing is changed during a search engine scan.
Some of the other notable methods are as follows:
CONNECT: This is used for HTTP tunneling for security reasons. It's not common in typical web applications and services.TRACE: It is used for debugging purposes. It's not common in typical web applications and services.OPTIONS: By using theOPTIONSverb, we can query which methods are supported by the web server for that resource.
Here's some part of the response after the OPTIONS method is invoked:
HTTP/1.1 200 OK Allow: OPTIONS, GET, HEAD, POST
Scenario
Your company wants you to monitor the network traffic of their website. Here, we use https://www.google.com/ as a reference.
Aim
To check the request-response pattern for https://www.google.com/.
Steps for completion
- Open your favorite browser.
- Hit F12 to open developer tools.
- Then, click on the Network tab.
- Next, go to https://www.google.com/.
- Study the header body for request and response.
You should see something similar to what is shown in the following screenshot:

ASP.NET is a server-side web application development framework, developed by Microsoft, allowing developers to build web applications, websites, and web services.
It is currently fully open source in this URL and is still maintained by Microsoft: https://github.com/aspnet
Basically, ASP.NET has three main programming models: ASP.NET Web Forms, ASP.NET MVC, and ASP.NET Web Pages. They form part of the ASP.NET Framework in this manner:
- ASP.NET for .NET Framework: This has the following sub sections:
- Web Forms: This is known for rapid application development. This tries to mimic desktop behavior.
- MVC: This applies the Model-View-Controller pattern.
- Web API: This is an MVC-style web service.
- Single-Page Application: Here, the server gives the initial HTML request, but further rendering happens entirely within the browser.
- ASP.NET Core: It is the new ASP.NET Platform that runs in a cross-platform manner. Subsections are:
- Web API: This is primarily used for developing web services.
- Web Application: This is used for MVC Applications. It can be used for developing web services too. Web API and MVC have become an almost unified thing.
- Web Application (Razor Pages): Razor Pages is a feature of ASP.NET Core MVC that makes coding page-focused scenarios easier and more productive.
Note
A recent trend for developers is the use of Single-Page Application frameworks on top of web services like Web APIs. However, MVC and Single-Page Application frameworks also play nicely together. In the future, we expect Microsoft to put more effort on .NET Core instead of .NET Framework. .NET Framework is already mature. Perhaps it will be put into maintenance mode but nothing is certain yet.
Even though the end result of all of the preceding programming models is to produce dynamic web pages effectively, the methodologies that they follow differ from each other. Let us discuss ASP.NET MVC.
ASP.NET MVC is the implementation of the MVC pattern in ASP.NET. The disadvantages of ASP.NET Web Forms which tried to mimic Windows development in the web environment, such as limited control over the generation of HTML, coupling with business code and UI code, hard-to-grasp, and complex page life cycle, are resolved in ASP.NET MVC. As most of the modern applications are controlled by client-side JavaScript libraries/frameworks, such as jQuery, KnockoutJS, AngularJS, and ReactJS, having complete control over the generated HTML is of paramount importance. As for Knockout, Angular, and React, these single-page libraries actually generate the HTML directly within the browser via their own template engines. In other words, the rendering is done in the browser rather than the server. This frees up server resources and it allows the web application to behave just like a disconnected application, as in mobile apps.
Let us talk a bit about the Model-View-Controller pattern and how it benefits the web application development.
This is a software architectural pattern which helps in defining the responsibility for each of the components and how they fit together in achieving the overall goal. This pattern is primarily used in building user interfaces and is applicable in many areas, including developing desktop applications and web applications. But I am going to explain the MVC pattern from the context of web development.
Primarily, the MVC pattern has three components:
- Model: This component represents your domain data. Note that this is not your database. This model component can talk to your database, but the model only represents your domain data. For example, if you are building an e-commerce web application, the model component may contain classes such as
Product,Supplier, andInventory. - View: This component is responsible for what to present to the user. Usually, this component would contain your HTML and CSS files. This may also include the layout information governing how your web application looks to the end user.
- Controller: As the name implies, the controller is responsible for interacting with different components. It receives the request (through the routing module), talks to the model, and sends the appropriate view to the user.
The following image speaks of the MVC pattern:
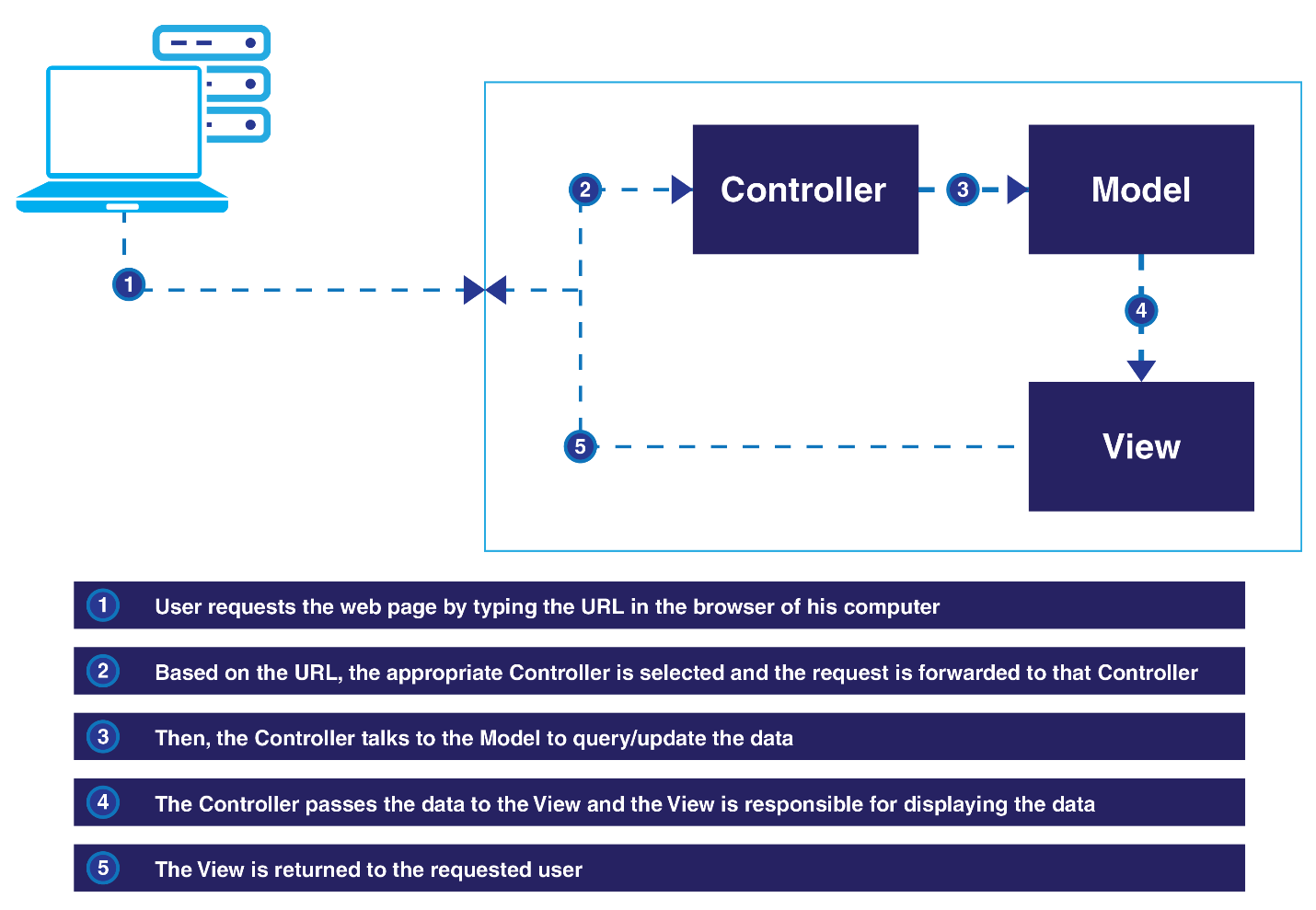
This separation of responsibilities brings great flexibility to the web application development, allowing each area to be managed separately and independently.
The Code for ASP.NET Core is as follows:
public class ValuesController : Controller
{
// GET api/<controller>
public IEnumerable<string> Get()
{
return new string[] { "value1", "value2" };
}
}Basically, each controller is represented by a class derived from the Controller class, although we can also write controllers without deriving from Controller. Each public method of the controller represents actions.
In this case, if we define a GET method (accessed via www.yoursite.com/controller without writing GET), it returns a string array as a response. How these strings are returned depends on the content negotiation.
Whenever you add a file or folder in your file system (inside the ASP.NET Core project folder), the changes will automatically be reflected in your application.
We bundle our static files into one file because for each static file, a browser will make a separate request to the server to retrieve it. If you have 100 CSS and JavaScript files, this means there will be 100 separate requests to retrieve those files. Obviously, reducing the number of requests will certainly improve the performance of your application. Thus, bundling is effectively decreasing the number of requests.
Note
HTTP/2 uses only 1 persistent connection for all files and requests. Thus, bundling is less useful in HTTP/2. However, it's still recommended since HTTP/1.x is here to stay for a long time. The development and deployment of an ASP.NET Core application on a Linux machine will be explained in a later chapter.
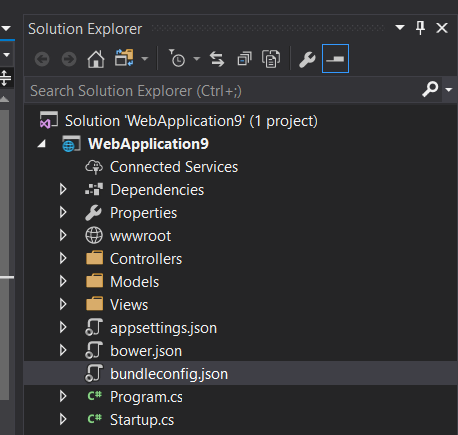
These are the important folders and files in a file-based project:
Here's the project structure of ASP.NET Core:
Note
Despite the fact that current ASP.NET Core templates are using Bower, Bower itself is obsolete now. Instead, npm or yarn is recommended. Just like NuGet, the JavaScript world needed package managers as there are hundreds of thousands of libraries and they have complex dependencies on each other. These package managers allow you to automate the installation and upgrades of these libraries by writing single commands from the command line.
Follow this steps to create your first project:
- Open up Visual Studio 2017. Navigate to
File|New Project|Web. You'll be presented with this screen:
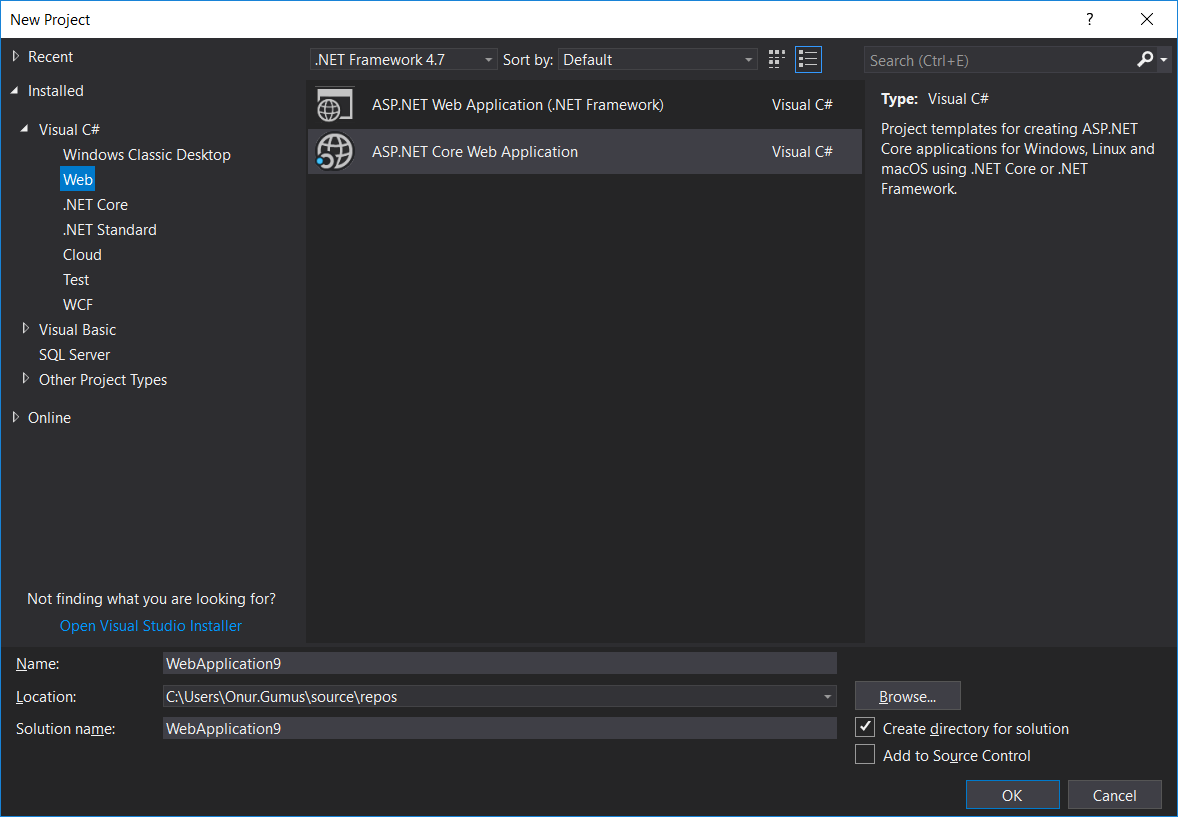
- Select
ASP.NET Core Web Application. Optionally, give a name to your project, or accept the default. Then, click onOK. - Make sure you select
.NET Core 2.0. If it doesn't show up, download .NET Core SDK from https://www.microsoft.com/net/download/ core and restart Visual Studio. Then selectWeb Applicationand click onOK. - Right-click on your project and click on
Build. This will restore the dependencies.
It is now time to create your first ASP.NET Core application.
Fire up Visual Studio and follow these steps:
- Create a project by selecting
File|New Projectin Visual Studio. The first option is for creating an earlier version of the ASP.NET web application. The second option is for creating the ASP.NET Core application using the .NET Core framework. NET Core supports only the core functionalities. The advantage of using the .NET core library is that it can be deployed on any platform. SelectASP.NET Core Web Application:
Note
Routing and controllers work together to render the correct view.
We'll use the name Lesson2 here to avoid reinventing the wheel in Chapter 2, Controllers.
- Select the
Emptytemplate from the list of ASP.NET Core templates. The second option is for creating the Web API application (for building the HTTP-based services) and the third option is for creating a web application containing some basic functionalities which you can run out of the box, without you ever needing to write anything:
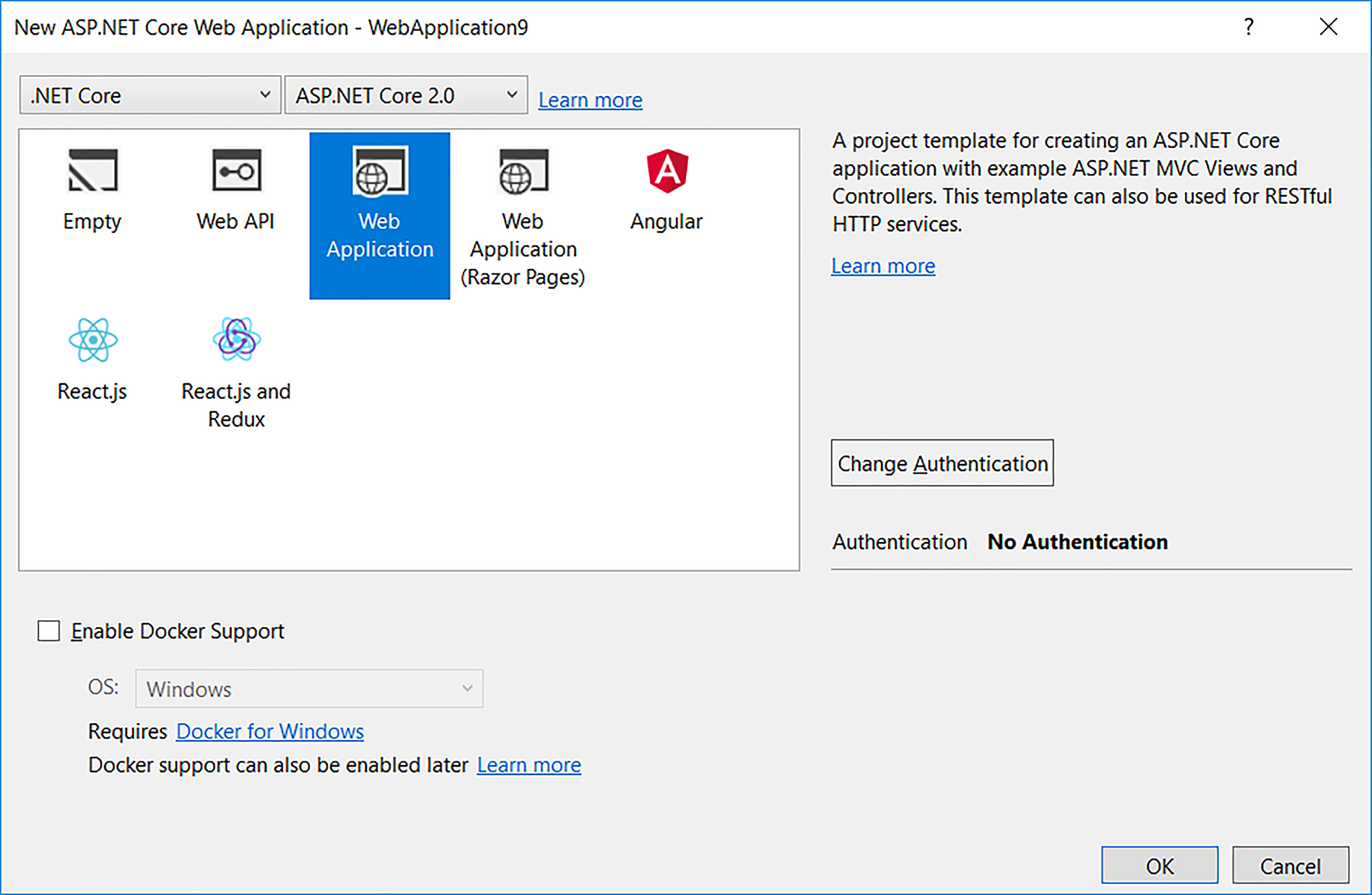
- Once you click on
OKin the window, as shown in the preceding screenshot (after selecting theEmptytemplate option), a solution will be created, as shown in the following screenshot:
- When you run the application (by pressing F5) without any changes, you'll get the simple
Hello World!text on your screen, as shown in the following screenshot:

We have not done any coding in this newly created application. So, have you thought about how it displays the text Hello World!?
The answer lies in the Startup.cs file, which contains a class by the name of Startup.
Note
When an exception occurs, we want to display the callstack for better diagnosis, for instance. However, doing so in a production environment would be a security risk. Hence, we have development-specific code.
ASP.NET Core runtime calls the ConfigureServices and Configure methods through the main method. For example, if you want to configure any service, you can add it here. Any custom configuration for your application can be added to this Configure method:
public void ConfigureServices(IServiceCollection services)
{
}
public void Configure(IApplicationBuilder app, IHostingEnvironment
env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.Run(async (context) =>
{
await context.Response.WriteAsync("Hello World!");
});
}There are only a couple of statements in the Configure method. Let us leave aside async, await, and context for the moment in the second statement, which we will discuss later. In essence, the second statement tells the runtime to return Hello World! for all the incoming requests, irrespective of the incoming URL.
When you type the URL http://localhost:50140/Hello in your browser, it will still return the same Hello World!
This is the reason we got the Hello World! when we ran the application.
As we have chosen the Empty template while creating the ASP.NET Core application, no component will have been installed. Even MVC won't be installed by default when you select the Empty template as we did.
In this chapter, you've learned the basics of web development, including what constitutes the server side and client side. HTTP is a key protocol in web development. We have even discussed the features of ASP.NET Core. We've looked at REST and RPC as two web programming styles.
We have also discussed the new project structure of the ASP.NET Core application and the changes when compared to the previous versions.
In the next chapter, we are going to discuss the controllers and their roles and functionalities. We'll also build a controller and associated action methods and see how they work.


