


















We use our five senses to observe everything around us—touch, taste, smell, hearing, and vision. Although all of these five senses are crucial, there is a sense which creates the biggest impact on perception. It is the main topic of this book and, undoubtedly, it is vision.
When looking at a scene, we understand and interpret the details within a meaningful context. This seems easy but it is a very complex process which is really hard to model. What makes vision easy for human eyes and hard for devices? The answer is hidden in the difference between human and machine perception. Many researchers are trying to go even further.
One of the most important milestones on the journey is the invention of the camera. Even though a camera is a good tool to save vision-based memories of scenes, it can lead to much more than just saving scenes. Just as with the invention of the camera, man has always tried to build devices to make life better. As the current trend is to develop intelligent devices, being aware of the environment around us is surely a crucial step in this. It is more or less the same for us; vision makes the biggest difference to the game. Thanks to technology, it is possible to mimic the human visual system and implement it on various types of devices. In the process we are able to build vision-enabled devices.
Images and timed series of images can be called video, in other words the computed representations of the real world. Any vision-enabled device recreates real scenes via images. Because extracting interpretations and hidden knowledge from images via devices is complex, computers are generally used for this purpose. The term, computer vision, comes from the modern approach of enabling machines to understand the real world in a human-like way. Since computer vision is necessary to automate daily tasks with devices or machines, it is growing quickly, and lots of frameworks, tools and libraries have already been developed.
Open Source Computer Vision Library (OpenCV) changed the game in computer vision and lots of people contributed to it to make it even better. Now it is a mature library which provides state-of-the-art design blocks which are handled in subsequent sections of this book. Because it is an easy-to-use library, you don't need to know the complex calculations under-the-hood to achieve vision tasks. This simplicity makes sophisticated tasks easy, but even so you should know how to approach problems and how to use design tools in harmony.
To be able to solve any kind of complex problem such as a computer vision problem, it is crucial to divide it into simple and realizable substeps by understanding the purpose of each step. This chapter aims to show you how to approach any computer vision problem and how to model the problem by using a generic model template.
A practical computer vision architecture, explained in this book, consists of the combination of an Arduino system and an OpenCV system, as shown in the following diagram:
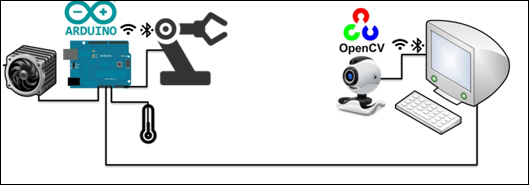
Arduino is solely responsible for collecting the sensory information—such as temperature, or humidity—from the environment and sending this information to the vision controller OpenCV system. The communication between the vision controller system and the Arduino system can be both wired or wireless as Arduino can handle both easily. After the vision system processes the data from Arduino and the webcam, it comes to a detection (or recognition) conclusion. For example, it can even recognize your face. The next step is acting on this conclusion by sending commands to the Arduino system and taking the appropriate actions. These actions might be driving a fan to make the environment cooler, moving a robotic arm to pass your coffee, and so on!
Note
A vision controller can be a desktop computer, laptop, mobile phone or even a microcomputer such as Raspberry Pi, or Beaglebone! OpenCV works on all of these platforms, so the principles are valid for all of these platforms. Microcomputers are also able to do some of the work otherwise done by Arduino.
Any computer vision system consists of well-defined design blocks ordered by data acquisition, preprocessing, image processing, post filtering, recognition (or detection) and actuation. This book will handle all of these steps in detail with a practical approach. We can draw a generic diagram of a computer vision system by mapping the steps to the related implementation platforms. In the following diagram, you can find a generic process view of a computer vision system:
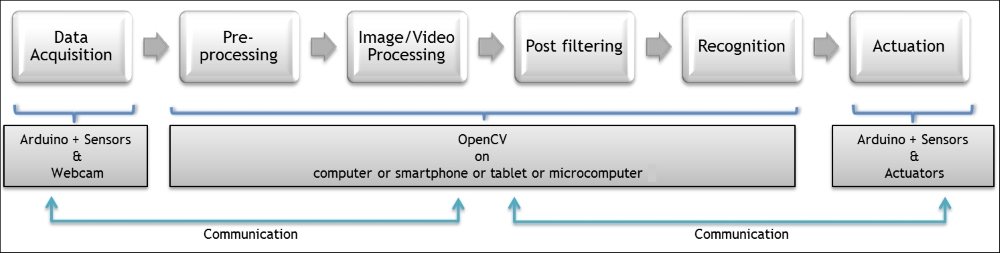
As can be seen, the first step is data acquisition, which normally collects the sensory information from the environment. Within the perspective of the vision controller, there are two main data sources—the camera, and the Arduino system.
The camera is the ultimate sensor to mimic the human vision system and it is directly connected to the vision controller in our scheme. By using OpenCV's data acquisition capabilities, the vision controller reads the vision data from the camera. This data is either an image snapshot or a video created from the timed series of image frames. The camera can be of various types and categories.
In the most basic categorization, a camera can give out analog or digital data. All of the cameras used in the examples in this book are digital because the processing environment and processing operation itself are also digital. Each element of the picture is referred to as a pixel. In digital imaging, a pixel, pel, or picture element is a physical point in a raster image or the smallest addressable element in an all-points-addressable display device; so it is the smallest controllable element of a picture represented on the screen. You can find more information on this at http://en.wikipedia.org/wiki/Pixel.
Cameras can also be classified by their color sensing capabilities. RGB cameras are able to sense both main color components and a huge amount of combinations of these colors. Grayscale cameras are able to detect the scene only in terms of shades of gray. Hence, rather than color information, these cameras provide shape information. Lastly, binary cameras sense the scene only in black or white. By the way, a pixel in a binary camera can have only two values—black and white.
Another classification for cameras is their communication interface. Some examples are a USB camera, IP camera, wireless camera, and so on. The communication interface of the camera also directly affects the usability and capability of that camera. At home generally we have web cameras with USB interfaces. When using USB web cameras, generally you don't need external power sources or the external stuff that makes using the camera harder, so it is really easy to use a USB webcam for image processing tasks. Cameras also have properties such as resolution but we'll handle camera properties in forthcoming chapters.
Regular USB cameras, most often deployed as webcams, offer a 2D image. In addition to 2D camera systems, we now have 3D camera systems which can detect the depth of each element in the scene. The best known example of 3D camera systems is probably Kinect, which is shown here:

OpenCV supports various types of cameras, and it is possible to read the vision information from all these cameras by using simple interfaces, as this issue is handled by examples in the forthcoming chapters. Please keep in mind that image acquisition is the fundamental step of the vision process and we have lots of options.
Generally, we need information in addition to that from the camera to analyze the environment around us. Some of this information is related to our other four senses. Moreover, sometimes we need additional information beyond human capabilities. We can capture this information by using the Arduino sensors.
Imagine that you want to build a face-recognizing automatic door lock project. The system will probably be triggered by a door knock or a bell. You need a sound sensor to react when the door is knocked or the bell is rung. All of this information can be easily collected by Arduino. Let's add a fingerprint sensor to make it doubly safe! In this way, you can combine the data from the Arduino and the camera to reach a conclusion about the scene by running the vision system.
In conclusion, both the camera and the Arduino system (with sensors) can be used by the vision controller to capture the environment in detail!
Preprocessing means getting something ready for processing. It can include various types of substeps but the principle is always the same. We will now explain preprocessing and why it is important in a vision system.
Firstly, let's make something clear. This step aims to make the collected vision data ready for processing. Preprocessing is required in computer vision systems since raw data is generally noisy. In the image data we get from the camera, we have lots of unneeded regions and sometimes we have a blurry image because of vibration, movement, and so on. In any case, it is better to filter the image to make it more useful for our system. For example, if you want to detect a big red ball in the image, you can just remove small dots, or you can even remove those parts which are not red. All of these kinds of filtering operations will make our life easy.
Generally, filtering is also done in data acquisition by the cameras, but every camera has different preprocessing capabilities and some of them even have vibration isolation. But, when built-in capabilities increase, cost is increased in parallel. So we'll handle how to do the filtering inside of our design via OpenCV. By the way, it is possible to design robust vision systems even with cheap equipment such as a webcam.
The same is valid for the sensor data. We always get noisy data in real life cases so noise should be filtered to get the actual information from the sensor. Some of these noises come from the environment and some of them come from the internal structure of the sensor. In any case, data should be made ready for processing; this book will give practical ways to achieve that end.
It should be understood that the complexity of image data is generally much greater than with any regular sensor such as a temperature sensor or a humidity sensor. The dimensions of the data which represents the information are also different. RGB images include three color components per pixel; red, green and blue. To represent a scene with a resolution of 640x480, a RGB camera needs 640x480x3 = 921600 bytes. Multiplication by three comes from the dimension of each pixel. Each pixel holds 3 bytes of data in total, 1 byte for each color. To represent the temperature of a room, we generally need 4 bytes of data. This also explains why we need highly capable devices to work on images. Moreover, the complexity of image filters is different from simple sensor filters.
But it doesn't mean that we cannot use complex filters in a simple way. If we know the purpose of the filter and the meanings of filter parameters, we can use them easily. This book aims to make you aware of the filtering process and how to apply advanced filtering techniques in an easy way.
So, filtering is for extracting the real information from the data and it is an integral step in the computer vision process. Many computer vision projects fail in the development phase because of the missing layer of filtering. Even the best recognition algorithms fail with noisy and inaccurate data. So, please be aware of the importance of data filtering and preprocessing.
The most inspiring part of a computer vision project is probably the automated interpretation of the scene. To extract meanings from an image, we apply various types of image processing techniques. Sometimes we need more information than we can take from a single image. In this case, relationships between image frames become important. If such inter-frame information is extracted, it is called video processing. Some video processing applications also include the processing of audio signals. Because all the principles are same, video processing is not so much different from image processing.
To understand the importance of this chapter it is logical to look at real life applications. Imagine that you want to build a vision-enabled line-follower robot. There will be a camera on top of the middle of the robot and the robot will follow a black line on a white floor. To achieve this task you should detect the line and find out if the line is on the left side or the right side. If the line is on the left side of the image, you should go left to take it in to the middle. Similarly, if the line is on the right side of the image, you should go right. Within a margin, if a line is in the middle of the image, you should go forward. You can also detect the orientation of the line to plan your robot's movements in a smarter way.
In this example, you should apply image processing techniques to detect the line in the image. You will see that the book proposes a good, small set of techniques which show you the directions that you should follow to solve your problem. And, by applying these techniques, it is possible to get some candidate regions in the images which can be counted as a line. To interpret the line candidates efficiently, you should make feature extraction for the regions in the image. By comparing the features (properties) of the line candidates system you can separate real lines from noises, such as shadows.
Feature extraction is a pattern recognition and classification term that means extracting a small set of information which represents a bigger set of information. By processing images, we extract the so-called features such as length, position, area of an image region, and so on. Later on, we will use these features to detect and recognise any kinds of objects.
There are some major approaches to extract useful small sets of information from the image. Segmentation is a term for such an operation.
Image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as superpixels). The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.
Note
More information can be found at http://en.wikipedia.org/wiki/Image_segmentation.
In our example, line candidates are segments in the image.
Blob analysis is a good method that labels the segments in the image. It is a useful method to find the closed loops in the image. Closed loops generally correspond to objects in the image. Blob analysis is also an image processing technique and will be handled later. It is important to get the idea of the feature extraction now.
The information which was extracted from the image will be used in the next step of the computer vision system. Because this processing step will summarize the image, it is very important to do this correctly to make the whole vision system work. Again, you don't need to know the complex calculations under the hood. Instead, you should know where and how to use image processing techniques to get valuable small information sets from the scene. That is exactly what this book deals with in the forthcoming chapters.
After extracting some useful information from the image, sometimes a higher layer of filtering is required. The removal of unnecessary segments by considering their properties is one such higher level of filtering. Normally, it is very easy if you know the requirements of the related project.
Because this step is very simple, sometimes we can think of it as part of image processing. It also makes senses because the aim of image processing is to provide a small set of clear information to the recognition or detection element.
OpenCV has good mechanisms for post-processing and we'll handle them in a brief, practical way by basing the concepts on real life examples. Understanding the purpose itself is much more important.
The main purpose of the vision system is to reach a conclusion by interpreting the scheme via images or the image arrays. The way to the conclusion is recognition or detection.
Detection can be counted as a basic form of recognition. The aim is to detect an object or event. There are two types of conclusion. An object or an event either exists or it doesn't. Because of this binary nature of conclusion it is a special classification process with two classes. The first class is existence and the second class is non-existence. "To be or not to be, that is the question."
Recognition is a more complex term which is also called classification and tells the identification process of one or more pre-specified or learned objects or object classes. Face recognition is a good example of such an operation. A vision system should identify you by recognizing your face. This is generally a complex classification process with multiple classes. In this case, each face is a class, so it is a complex problem. But, thanks to OpenCV, we have lots of easy-to-use mechanisms for recognition, even for complex problems.
Sometimes, complex algorithms take a lot of time to finish. Similarly, in some cases, very fast behavior is needed, especially for real-time performance requirements. In such cases, we can also use simple but effective decision algorithms. As Leonardo da Vinci says, "Simplicity is the ultimate sophistication". This book also will tell you about how to build robust recognition systems by using simple design blocks.
Again, you should be aware of the aim of recognition or classification. This awareness will show you the path which you should follow to succeed.
Every vision system has a purpose. There are some scenarios such as; "if you detect this event (or object), do this action". At the end of the long but enjoyable decision process of a vision system, the next step would surely be to perform an action by considering the conclusion. This is because of the "existence purpose" of the system. Everything up to now has been done to enable us to take the right action.
Let's remember our line follower robot example. The robot detects the line and the position of the line in its view. It also decides on the direction to follow. Would it be meaningful if the robot knew the direction in which it should go but was unable to move? This example also shows the importance of the action at the end.
The physical action managed by the vision controller should affect real life in a physical manner. Good examples are driving motors to move on, heating an environment, unlocking a door, triggering a device, and so on. To do this leads us to the Arduino. It has a huge amount of community support, lots of libraries on many devices and it is really easy to use. Maybe for industrial design, you can go beyond Arduino but it is a fact that Arduino is a very good proof-of-concept platform for physical interaction with the world. Arduino is an embedded system which makes the hard engineering stuff simple and easy. So we should love it!
The most inspiring thing about using embedded systems to produce different physical interactions is that many of them are the same in terms of software development. Square wave signals are used for different purposes in embedded systems. You will learn about them in detail in later chapters but consider that square waves can be used for a kind of dimming functionality. When you produce a square wave with fifty percent duty ratio; it means that there will be a pulse with logic high in a limited time t and with a logic low in a limited time t. The software will apply the same dimming principle even on completely different devices. If you apply this fairly high frequency square wave to a motor, it will turn at half of its speed capability. Similarly, if you apply the same square wave to an LED, it will shine at half of its shining capability. Even with completely different physical devices, we have the same behavior with the same software. So, we should see the inspiring nature of the instruments which we use to touch the world and if we have an idea of how to connect them to our system then everything will be okay.
In this book we present a hardware-independent software approach to interact with the world. So, even though the physical examples are hardware-dependent, you will be able to apply the same principles to any embedded system. There are also state-of-the art tips to interact with the world using Arduino in an artistic way.
In the approach we have presented, the vision process is divided into well-defined, easy-to-realize sub-blocks. Because every block has a major role in the performance of the overall system, each of them should be developed efficiently under some simple principles which will make the vision system rock solid.
When approaching any kind of vision problem, firstly the big picture should be seen and the problem should be divided into meaningful and internally independent sub-pieces as we proposed. This approach will make you see important details and isolated solutions to small problems. This is the most important first step to building futuristic vision-enabled systems. The next step is just connecting the pieces and enjoying your art!
The approach which is presented in this chapter is applicable to any kind of vision system. But you should get more and more practice in real life situations to ground the approach solidly. Let's do some brainstorming on such a real-life example—a hand gesture-controlled door unlock system.
There should be a camera at the entrance, by the door, which is able to see any guest's movements. To make it more applicable let's trigger the motion detection system by pressing the bell. Visitors will press the bell and show a right hand gesture to the camera, and the vision controller will unlock the door automatically. If the hand gesture is wrong, the door won't open.
The first step is data acquisition and, because we want to see hand gestures, we can use a simple 30FPS webcam with a 1024x768 resolution.
We can convert the image to binary and we can apply a filter to remove small objects in the image. The hand will be presented in a binary way. Filtering is done.
Now we should perform feature extraction to find the possible position of the hand in the image. The convex hull method or blob analysis can be used for such a problem and we will handle these algorithms later on. At the end, we will have an image with features of hand candidates, as shown in this screenshot:

We need a hand detector as the next step. We can use the number of fingers by applying a skeleton analysis to the hand and by comparing the positions of the fingers; we can classify the hand gesture.
If it is the right hand gesture, we can send the information to the Arduino door unlock controller and it will unlock the door for a limited time to welcome the authorized visitor!
You can apply all these principals to any problem to get familiar with it. Do not focus on the algorithmic details now. Just try to divide the problem into pieces and try to decide what properties you can use to solve the problem.
As long as you get used to the approach, this book will show you how to realize each step and how you can find the right algorithm to achieve it. So, go on and try to repeat the approach for a garage door open/close system which will recognize your car's number plate!
We now know how to approach vision projects and how to divide them into isolated pieces which make the realization of the projects much easier. We also have some idea about how the complex tasks of vision systems can be achieved in a systematic way.
We also talked about the reason and importance of each sub-step in the approach. We are now aware of the key points in the approach and have a solid knowledge of how we can define a solution frame for any computer vision problem.
Now, it is time to get your hands dirty!
