Let's use the humidity data and the first plot that we created. It looks like the humidity values are discrete, which is why you can see discrete peaks in the data. In this section, we'll analyze the differences between unbinned and binned histograms.
Let's begin by implementing the following steps:
- Choosing a different type of binning can make the distribution more continuous; use the following code:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15)
You'll get the following output. Graph 1:
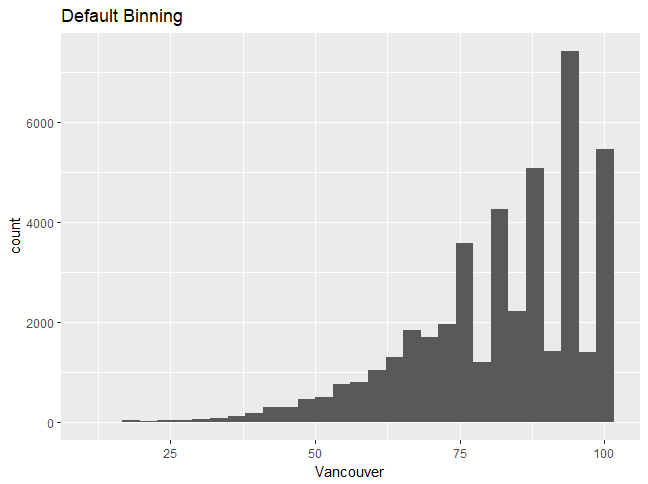
Graph 2:
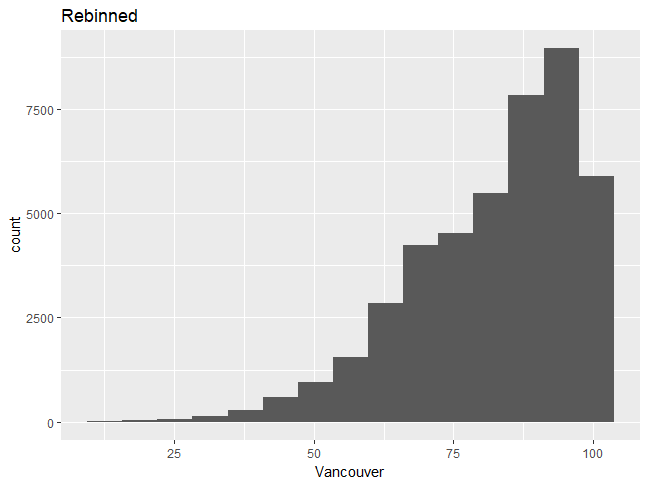
Choosing a different type of binning can make the distribution more continuous, and one can then better understand the distribution shape. We will now build upon the graph, changing some features and adding more layers.
- Change the fill color to white by using the following command:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15,fill="white",color=1)
- Add a title to the histogram by using the following command:
+ggtitle("Humidity for Vancouver city")
- Change the x-axis label and label sizes, as follows:
+xlab("Humidity")+theme(axis.text.x=element_text(size = 12),axis.text.y=element_text(size=12))
You should see the following output:
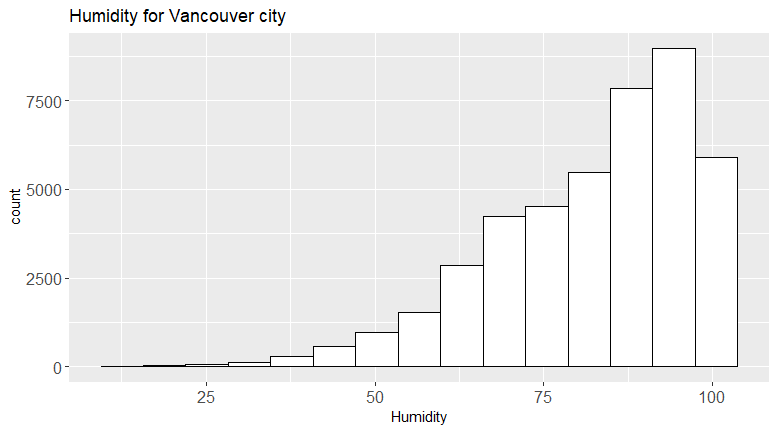
The full command should look as follows:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15,fill="white",color=1)+ggtitle("Humidity for Vancouver city")+xlab("Humidity")+theme(axis.text.x=element_text(size= 12),axis.text.y=element_text(size=12))
We can see that the second plot is a visual improvement, due to the following factors:
- There is a title
- The font sizes are visible
- The histogram looks more professional in white
To see what else can be changed, type ?theme.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















