


















 Download code from GitHub
Download code from GitHub
Data is one of the most important assets of any organization. The scale at which data is being collected and used in organizations is growing beyond imagination. The speed at which data is being ingested, the variety of the data types in use, and the amount of data that is being processed and stored are breaking all-time records every moment. It is very common these days, even in small-scale organizations, that data is growing from gigabytes to terabytes to petabytes. For the same reason, the processing needs are also growing that ask for capability to process data at rest as well as data on the move.
Take any organization; its success depends on the decisions made by its leaders and for making sound decisions, you need the backing of good data and the information generated by processing the data. This poses a big challenge on how to process the data in a timely and cost-effective manner so that right decisions can be made. Data processing techniques have evolved since the early days of computers. Countless data processing products and frameworks came into the market and disappeared over these years. Most of these data processing products and frameworks were not general purpose in nature. Most of the organizations relied on their own bespoke applications for their data processing needs, in a silo way, or in conjunction with specific products.
Large-scale Internet applications, popularly known as Internet of Things (IoT) applications, heralded the common need to have open frameworks to process huge amounts of data ingested at great speed dealing with various types of data. Large-scale web sites, media streaming applications, and the huge batch processing needs of organizations made the need even more relevant. The open source community is also growing considerably along with the growth of the Internet, delivering production quality software supported by reputed software companies. A huge number of companies started using open source software and started deploying them in their production environments.
In a technological perspective, the data processing needs were facing huge challenges. The amount of data started overflowing from single machines to clusters of huge numbers of machines. The processing power of the single CPU plateaued and modern computers started combining them together to get more processing power, known as multi-core computers. The applications were not designed and developed to make use of all the processors in a multi-core computer and wasted lots of the processing power available in a typical modern computer.
Note
Throughout this book, the terms node, host, and machine refer to a computer that is running in a standalone mode or in a cluster.
In this context, what are the qualities an ideal data processing framework should possess?
It should be capable of processing the blocks of data distributed across a cluster of computers
It should be able to process the data in a parallel fashion so that a huge data processing job can be divided into multiple tasks processed in parallel so that the processing time can be reduced considerably
It should be capable of using the processing power of all the cores or processors in a computer
It should be capable of using all the available computers in a cluster
It should be capable of running on commodity hardware
There are two open source data processing frameworks that are worth mentioning that satisfy all these requirements. The first is being Apache Hadoop and the second one is Apache Spark.
We will cover the following topics in this chapter:
Apache Hadoop
Apache Spark
Spark 2.0 installation
Apache Hadoop is an open source software framework designed from ground-up to do distributed data storage on a cluster of computers and to do distributed data processing of the data that is spread across the cluster of computers. This framework comes with a distributed filesystem for the data storage, namely, Hadoop Distributed File System (HDFS), and a data processing framework, namely, MapReduce. The creation of HDFS is inspired from the Google research paper, The Google File System and MapReduce is based on the Google research paper, MapReduce: Simplified Data Processing on Large Clusters.
Hadoop was adopted by organizations in a really big way by implementing huge Hadoop clusters for data processing. It saw tremendous growth from Hadoop MapReduce version 1 (MRv1) to Hadoop MapReduce version 2 (MRv2). From a pure data processing perspective, MRv1 consisted of HDFS and MapReduce as the core components. Many applications, generally called SQL-on-Hadoop applications, such as Hive and Pig, were stacked on top of the MapReduce framework. It is very common to see that even though these types of applications are separate Apache projects, as a suite, many such projects provide great value.
The Yet Another Resource Negotiator (YARN) project came to the fore with computing frameworks other than MapReduce type to run on the Hadoop ecosystem. With the introduction of YARN sitting on top of HDFS, and below MapReduce in a component architecture layering perspective, the users could write their own applications that can run on YARN and HDFS to make use of the distributed data storage and data processing capabilities of the Hadoop ecosystem. In other words, the newly overhauled MapReduce version 2 (MRv2) became one of the application frameworks sitting on top of HDFS and YARN.
Figure 1 gives a brief idea about these components and how they are stacked together:

Figure 1
MapReduce is a generic data processing model. The data processing goes through two steps, namely, map step and reduce step. In the first step, the input data is divided into a number of smaller parts so that each one of them can be processed independently. Once the map step is completed, its output is consolidated and the final result is generated in the reduce step. In a typical word count example, the creation of key-value pairs with each word as the key and the value 1 is the map step. The sorting of these pairs on the key, summing the values of the pairs with the same key falls into an intermediate combine step. Producing the pairs containing unique words and their occurrence count is the reduce step.
From an application programming perspective, the basic ingredients for an over-simplified MapReduce application are as follows:
Input location
Output location
Map function implemented for the data processing need from the appropriate interfaces and classes from the
MapReducelibraryReduce function implemented for the data processing need from the appropriate interfaces and classes from the
MapReducelibrary
The MapReduce job is submitted for running in Hadoop and once the job is completed, the output can be taken from the output location specified.
This two-step process of dividing a MapReduce data processing job to map and reduce tasks was highly effective and turned out to be a perfect fit for many batch data processing use cases. There is a lot of Input/Output (I/O) operations with the disk happening under the hood during the whole process. Even in the intermediate steps of the MapReduce job, if the internal data structures are filled with data or when the tasks are completed beyond a certain percentage, writing to the disk happens. Because of this, the subsequent steps in the MapReduce jobs have to read from the disk.
Then the other biggest challenge comes when there are multiple MapReduce jobs to be completed in a chained fashion. In other words, if a big data processing work is to be accomplished by two MapReduce jobs in such a way that the output of the first MapReduce job is the input of the second MapReduce job. In this situation, whatever may be the size of the output of the first MapReduce job, it has to be written to the disk before the second MapReduce could use it as its input. So in this simple case, there is a definite and unnecessary write operation.
In many of the batch data processing use cases, these I/O operations are not a big issue. If the results are highly reliable, for many batch data processing use cases, latency is tolerated. But the biggest challenge comes when doing real-time data processing. The huge amount of I/O operations involved in MapReduce jobs makes it unsuitable for real-time data processing with the lowest possible latency.
Spark is a Java Virtual Machine (JVM) based distributed data processing engine that scales, and it is fast compared to many other data processing frameworks. Spark was originated at the University of California Berkeley and later became one of the top projects in Apache. The research paper, Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, talks about the philosophy behind the design of Spark. The research paper states:
"To test the hypothesis that simple specialized frameworks provide value, we identified one class of jobs that were found to perform poorly on Hadoop by machine learning researchers at our lab: iterative jobs, where a dataset is reused across a number of iterations. We built a specialized framework called Spark optimized for these workloads."
The biggest claim from Spark regarding speed is that it is able to "Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk". Spark could make this claim because it does the processing in the main memory of the worker nodes and prevents the unnecessary I/O operations with the disks. The other advantage Spark offers is the ability to chain the tasks even at an application programming level without writing onto the disks at all or minimizing the number of writes to the disks.
How did Spark become so efficient in data processing as compared to MapReduce? It comes with a very advanced Directed Acyclic Graph (DAG) data processing engine. What it means is that for every Spark job, a DAG of tasks is created to be executed by the engine. The DAG in mathematical parlance consists of a set of vertices and directed edges connecting them. The tasks are executed as per the DAG layout. In the MapReduce case, the DAG consists of only two vertices, with one vertex for the map task and the other one for the reduce task. The edge is directed from the map vertex to the reduce vertex. The in-memory data processing combined with its DAG-based data processing engine makes Spark very efficient. In Spark's case, the DAG of tasks can be as complicated as it can. Thankfully, Spark comes with utilities that can give excellent visualization of the DAG of any Spark job that is running. In a word count example, Spark's Scala code will look something like the following code snippet . The details of this programming aspects will be covered in the coming chapters:
val textFile = sc.textFile("README.md")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word =>
(word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()
The web application that comes with Spark is capable of monitoring the workers and applications. The DAG of the preceding Spark job generated on the fly will look like Figure 2, as shown here:
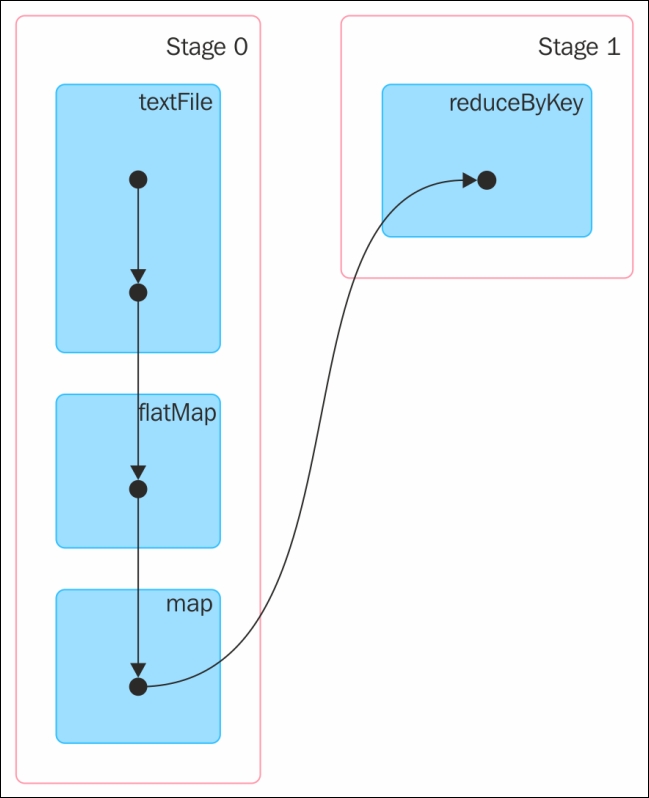
Figure 2
The Spark programming paradigm is very powerful and exposes a uniform programming model supporting the application development in multiple programming languages. Spark supports programming in Scala, Java, Python, and R even though there is no functional parity across all the programming languages supported. Apart from writing Spark applications in these programming languages, Spark has an interactive shell with Read, Evaluate, Print, and Loop (REPL) capabilities for the programming languages Scala, Python, and R. At this moment, there is no REPL support for Java in Spark. The Spark REPL is a very versatile tool that can be used to try and test Spark application code in an interactive fashion. The Spark REPL enables easy prototyping, debugging, and much more.
In addition to the core data processing engine, Spark comes with a powerful stack of domain specific libraries that use the core Spark libraries and provide various functionalities useful for various big data processing needs. The following table lists the supported libraries:
|
Library |
Use |
Supported Languages |
|
Spark SQL |
Enables the use of SQL statements or DataFrame API inside Spark applications |
Scala, Java, Python, and R |
|
Spark Streaming |
Enables processing of live data streams |
Scala, Java, and Python |
|
Spark MLlib |
Enables development of machine learning applications |
Scala, Java, Python, and R |
|
Spark GraphX |
Enables graph processing and supports a growing library of graph algorithms |
Scala |
Spark can be deployed on a variety of platforms. Spark runs on the operating systems (OS) Windows and UNIX (such as Linux and Mac OS). Spark can be deployed in a standalone mode on a single node having a supported OS. Spark can also be deployed in cluster node on Hadoop YARN as well as Apache Mesos. Spark can be deployed in the Amazon EC2 cloud as well. Spark can access data from a wide variety of data stores, and some of the most popular ones include HDFS, Apache Cassandra, Hbase, Hive, and so on. Apart from the previously listed data stores, if there is a driver or connector program available, Spark can access data from pretty much any data source.
Tip
All the examples used in this book are developed, tested, and run on a Mac OS X Version 10.9.5 computer. The same instructions are applicable for all the other platforms except Windows. In Windows, corresponding to all the UNIX commands, there is a file with a .cmd extension and it has to be used. For example, for spark-shell in UNIX, there is a spark-shell.cmd in Windows. The program behavior and results should be the same across all the supported OS.
In any distributed application, it is common to have a driver program that controls the execution and there will be one or more worker nodes. The driver program allocates the tasks to the appropriate workers. This is the same even if Spark is running in standalone mode. In the case of a Spark application, its SparkContext object is the driver program and it communicates with the appropriate cluster manager to run the tasks. The Spark master, which is part of the Spark core library, the Mesos master, and the Hadoop YARN Resource Manager, are some of the cluster managers that Spark supports. In the case of a Hadoop YARN deployment of Spark, the Spark driver program runs inside the Hadoop YARN application master process or the Spark driver program runs as a client to the Hadoop YARN. Figure 3 describes the standalone deployment of Spark:
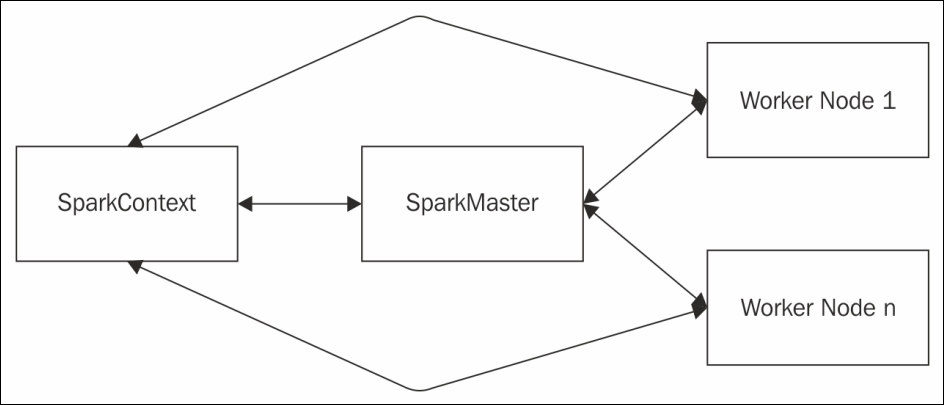
Figure 3
In the Mesos deployment mode of Spark, the cluster manager will be the Mesos Master. Figure 4 describes the Mesos deployment of Spark:
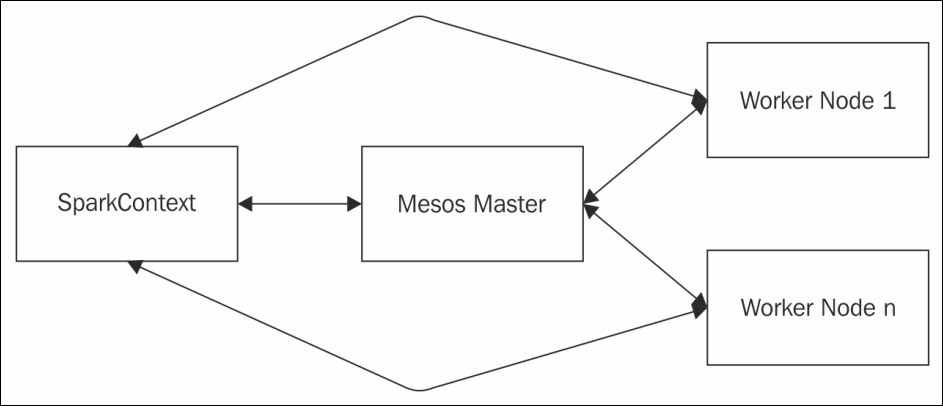
Figure 4
In the Hadoop YARN deployment mode of Spark, the cluster manager will be the Hadoop Resource Manager and its address will be picked up from the Hadoop configuration. In other words, when submitting the Spark jobs, there is no need to give an explicit master URL and it will pick up the details of the cluster manager from the Hadoop configuration. Figure 5 describes the Hadoop YARN deployment of Spark:
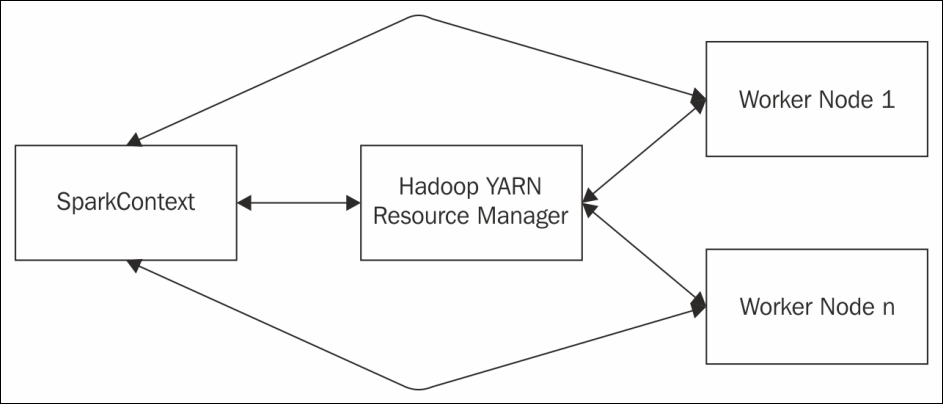
Figure 5
Spark runs in the cloud too. In the case of the deployment of Spark on Amazon EC2, apart from accessing the data from the regular supported data sources, Spark can also access data from Amazon S3, which is the online data storage service from Amazon.
Spark supports application development in Scala, Java, Python, and R. In this book, Scala, Python, and R, are used. Here is the reason behind the choice of the languages for the examples in this book. The Spark interactive shell, or REPL, allows the user to execute programs on the fly just like entering OS commands on a terminal prompt and it is available only for the languages Scala, Python and R. REPL is the best way to try out Spark code before putting them together in a file and running them as applications. REPL helps even the experienced programmer to try and test the code and thus facilitates fast prototyping. So, especially for beginners, using REPL is the best way to get started with Spark.
As a pre-requisite to Spark installation and to do Spark programming in Python and R, both Python and R are to be installed prior to the installation of Spark.
Visit https://www.python.org for downloading and installing Python for your computer. Once the installation is complete, make sure that the required binaries are in the OS search path and the Python interactive shell is coming up properly. The shell should display some content similar to the following:
$ python
Python 3.5.0 (v3.5.0:374f501f4567, Sep 12 2015, 11:00:19)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
For charting and plotting, the matplotlib library is being used.
Note
Python version 3.5.0 is used as a version of choice for Python. Even though Spark supports programming in Python version 2.7, as a forward looking practice, the latest and most stable version of Python available is used. Moreover, most of the important libraries are getting ported to Python version 3.x as well.
Visit http://matplotlib.org for downloading and installing the library. To make sure that the library is installed properly and that charts and plots are getting displayed properly, visit the http://matplotlib.org/examples/index.html page to pick up some example code and see that your computer has all the required resources and components for charting and plotting. While trying to run some of these charting and plotting samples, in the context of the import of the libraries in Python code, there is a possibility that it may complain about the missing locale. In that case, set the following environment variables in the appropriate user profile to get rid of the error messages:
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
Visit https://www.r-project.org for downloading and installing R for your computer. Once the installation is complete, make sure that the required binaries are in the OS search path and the R interactive shell is coming up properly. The shell should display some content similar to the following:
$ r
R version 3.2.2 (2015-08-14) -- "Fire Safety"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin13.4.0 (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
[Previously saved workspace restored]
>
Spark installation can be done in many different ways. The most important pre-requisite for Spark installation is that the Java 1.8 JDK is installed in the system and the JAVA_HOME environment variable is set to point to the Java 1.8 JDK installation directory. Visit http://spark.apache.org/downloads.html for understanding, choosing, and downloading the right type of installation for your computer. Spark version 2.0.0 is the version of choice for following the examples given in this book. Anyone who is interested in building and using Spark from the source code should visit: http://spark.apache.org/docs/latest/building-spark.html for the instructions. By default, when you build Spark from the source code, it will not build the R libraries for Spark. For that, the SparkR libraries have to be built and the appropriate profile has to be included while building Spark from source code. The following command shows how to include the profile required to build the SparkR libraries:
$ mvn -DskipTests -Psparkr clean package
Once the Spark installation is complete, define the following environment variables in the appropriate user profile:
export SPARK_HOME=<the Spark installation directory>
export PATH=$SPARK_HOME/bin:$PATH
If there are multiple versions of Python executables in the system, then it is better to explicitly specify the Python executable to be used by Spark in the following environment variable setting:
export PYSPARK_PYTHON=/usr/bin/python
In the $SPARK_HOME/bin/pyspark script, there is a block of code that determines the Python executable to be used by Spark:
# Determine the Python executable to use if PYSPARK_PYTHON or PYSPARK_DRIVER_PYTHON isn't set:
if hash python2.7 2>/dev/null; then
# Attempt to use Python 2.7, if installed:
DEFAULT_PYTHON="python2.7"
else
DEFAULT_PYTHON="python"
fi
So, it is always better to explicitly set the Python executable for Spark, even if there is only one version of Python available in the system. This is a safeguard to prevent unexpected behavior when an additional version of Python is installed in the future.
Once all the preceding steps are completed successfully, make sure that all the Spark shells for the languages Scala, Python, and R are working properly. Run the following commands on the OS terminal prompt and make sure that there are no errors and that content similar to the following is getting displayed. The following set of commands is used to bring up the Scala REPL of Spark:
$ cd $SPARK_HOME
$ ./bin/spark-shellUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/06/28 20:53:48 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/06/28 20:53:49 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.1.6:4040
Spark context available as 'sc' (master = local[*], app id = local-1467143629623).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_66)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala>exit
In the preceding display, verify that the JDK version, Scala version, and Spark version are correct as per the settings in the computer in which Spark is installed. The most important point to verify is that no error messages are displayed.
The following set of commands is used to bring up the Python REPL of Spark:
$ cd $SPARK_HOME
$ ./bin/pyspark
Python 3.5.0 (v3.5.0:374f501f4567, Sep 12 2015, 11:00:19)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/06/28 20:58:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Python version 3.5.0 (v3.5.0:374f501f4567, Sep 12 2015 11:00:19)
SparkSession available as 'spark'.
>>>exit()
In the preceding display, verify that the Python version, and Spark version are correct as per the settings in the computer in which Spark is installed. The most important point to verify is that no error messages are displayed.
The following set of commands are used to bring up the R REPL of Spark:
$ cd $SPARK_HOME
$ ./bin/sparkR
R version 3.2.2 (2015-08-14) -- "Fire Safety"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin13.4.0 (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
[Previously saved workspace restored]
Launching java with spark-submit command /Users/RajT/source-code/spark-source/spark-2.0/bin/spark-submit "sparkr-shell" /var/folders/nf/trtmyt9534z03kq8p8zgbnxh0000gn/T//RtmphPJkkF/backend_port59418b49bb6
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/06/28 21:00:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Spark context is available as sc, SQL context is available as sqlContext
During startup - Warning messages:
1: 'SparkR::sparkR.init' is deprecated.
Use 'sparkR.session' instead.
See help("Deprecated")
2: 'SparkR::sparkRSQL.init' is deprecated.
Use 'sparkR.session' instead.
See help("Deprecated")
>q()
In the preceding display, verify that the R version and Spark version are correct as per the settings in the computer in which Spark is installed. The most important point to verify is that no error messages are displayed.
If all the REPL for Scala, Python, and R are working fine, it is almost certain that the Spark installation is good. As a final test, run some of the example programs that came with Spark and make sure that they are giving proper results close to the results shown below the commands and not throwing any error messages in the console. When these example programs are run, apart from the output shown below the commands, there will be lot of other messages displayed in the console. They are omitted to focus on the results:
$ cd $SPARK_HOME
$ ./bin/run-example SparkPi
Pi is roughly 3.1484
$ ./bin/spark-submit examples/src/main/python/pi.py
Pi is roughly 3.138680
$ ./bin/spark-submit examples/src/main/r/dataframe.R
root
|-- name: string (nullable = true)
|-- age: double (nullable = true)
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
name
1 Justin
Most of the code that is going to be discussed in this book can be tried and tested in the appropriate REPL. But the proper Spark application development is not possible without some basic build tools. As a bare minimum requirement, for developing and building Spark applications in Scala, the Scala build tool (sbt) is a must. Visit http://www.scala-sbt.org for downloading and installing sbt.
Maven is the preferred build tool for building Java applications. This book is not talking about Spark application development in Java, but it is good to have Maven also installed in the system. Maven will come in handy if Spark is to be built from source. Visit https://maven.apache.org for downloading and installing Maven.
There are many Integrated Development Environments (IDEs) available for Scala as well as Java. It is a personal choice, and the developer can choose the tool of his/her choice for the language in which he/she is developing Spark applications.
Spark REPL for Scala is a good start to get into the prototyping and testing of some small snippets of code. But when there is a need to develop, build, and package Spark applications in Scala, it is good to have sbt-based Scala projects and develop them using a supported IDE, including but not limited to Eclipse or IntelliJ IDEA. Visit the appropriate website for downloading and installing the preferred IDE for Scala.
Notebook style application development tools are very common these days among data analysts and researchers. This is akin to a lab notebook. In a typical lab notebook, there will be instructions, detailed descriptions, and steps to follow to conduct an experiment. Then the experiments are conducted. Once the experiments are completed, there will be results captured in the notebook. If all these constructs are combined together and fit into the context of a software program and modeled in a lab notebook format, there will be documentation, code, input, and the output generated by running the code. This will give a very good effect, especially if the programs generate a lot of charts and plots.
Tip
For those who are not familiar with notebook style application development IDEs, there is a very nice article entitled Interactive Notebooks: Sharing the Code that can be read from http://www.nature.com/news/interactive-notebooks-sharing-the-code-1.16261. As an optional software development IDE for Python, the IPython notebook is described in the following section. After the installation, get yourself familiar with the tool before getting into serious development with it.
In the case of Spark application development in Python, IPython provides an excellent notebook-style development tool, which is a Python language kernel for Jupyter. Spark can be integrated with IPython, so that when the Spark REPL for Python is invoked, it will start the IPython notebook. Then, create a notebook and start writing code in the notebook just like the way commands are given in the Spark REPL for Python. Visit http://ipython.org to download and install the IPython notebook. Once the installation is complete, invoke the IPython notebook interface and make sure that some example Python code is running fine. Invoke commands from the directory from where the notebooks are stored or where the notebooks are to be stored. Here, the IPython notebook is started from a temporary directory. When the following commands are invoked, it will open up the web interface and from there create a new notebook by clicking the New drop-down box and picking up the appropriate Python version.
The following screenshot shows how to combine a markdown style documentation, a Python program, and the generated output together in an IPython notebook:
$ cd /Users/RajT/temp
$ ipython notebook
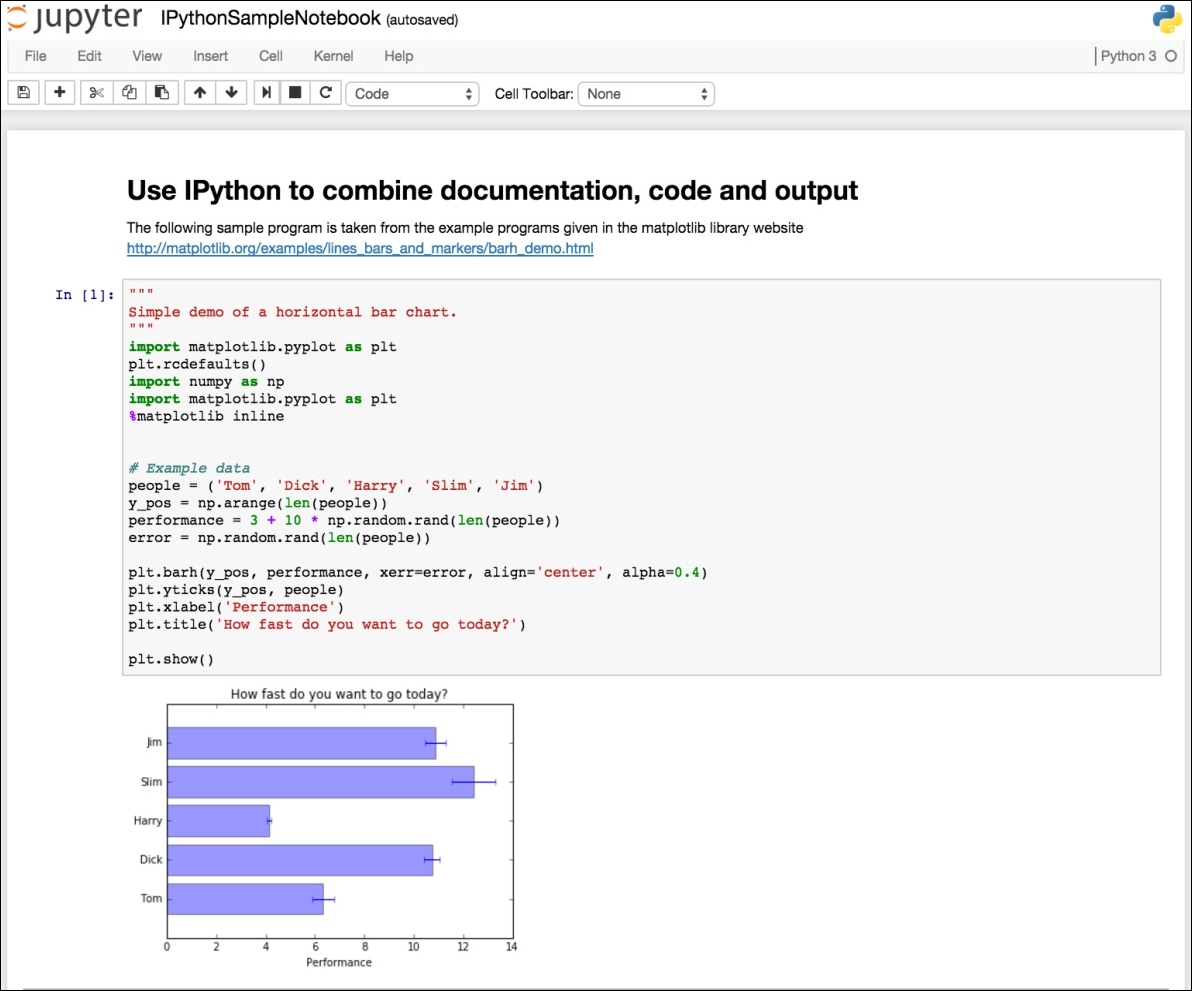
Figure 6
Figure 6 shows how the IPython notebook can be used to write simple Python programs. The IPython notebook can be configured as a shell of choice for Spark, and when the Spark REPL for Python is invoked, it will start up the IPython notebook and Spark application development can be done using IPython notebook. To achieve that, define the following environment variables in the appropriate user profile:
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
Now, instead of invoking the IPython notebook from the command prompt, invoke the Spark REPL for Python. Just like what has been done before, create a new IPython notebook and start writing Spark code in Python:
$ cd /Users/RajT/temp
$ pyspark
Take a look at the following screenshot:
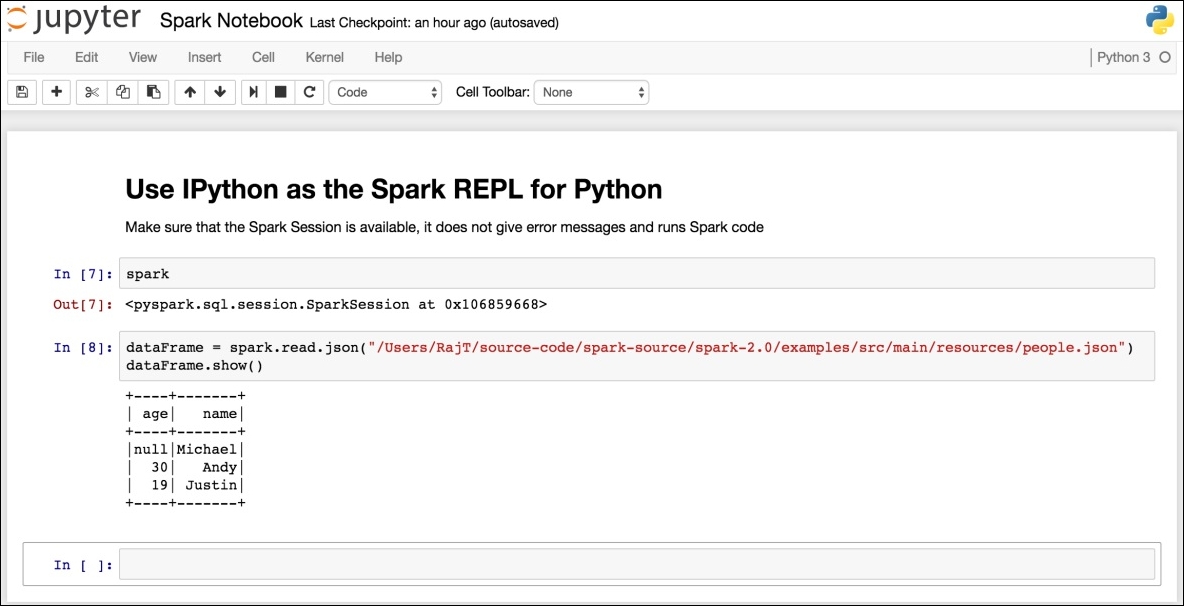
Figure 7
Among the R user community, the preferred IDE for R is the RStudio. RStudio can be used to develop Spark applications in R as well. Visit https://www.rstudio.com to download and install RStudio. Once the installation is complete, before running any Spark R code, it is mandatory to include the SparkR libraries and set some variables to make sure that the Spark R programs are running smoothly from RStudio. The following code snippet does that:
SPARK_HOME_DIR <- "/Users/RajT/source-code/spark-source/spark-2.0"
Sys.setenv(SPARK_HOME=SPARK_HOME_DIR)
.libPaths(c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib"), .libPaths()))
library(SparkR)
spark <- sparkR.session(master="local[*]")
In the preceding R code, change the SPARK_HOME_DIR variable definition to point to the directory where Spark is installed. Figure 8 shows a sample run of the Spark R code from RStudio:
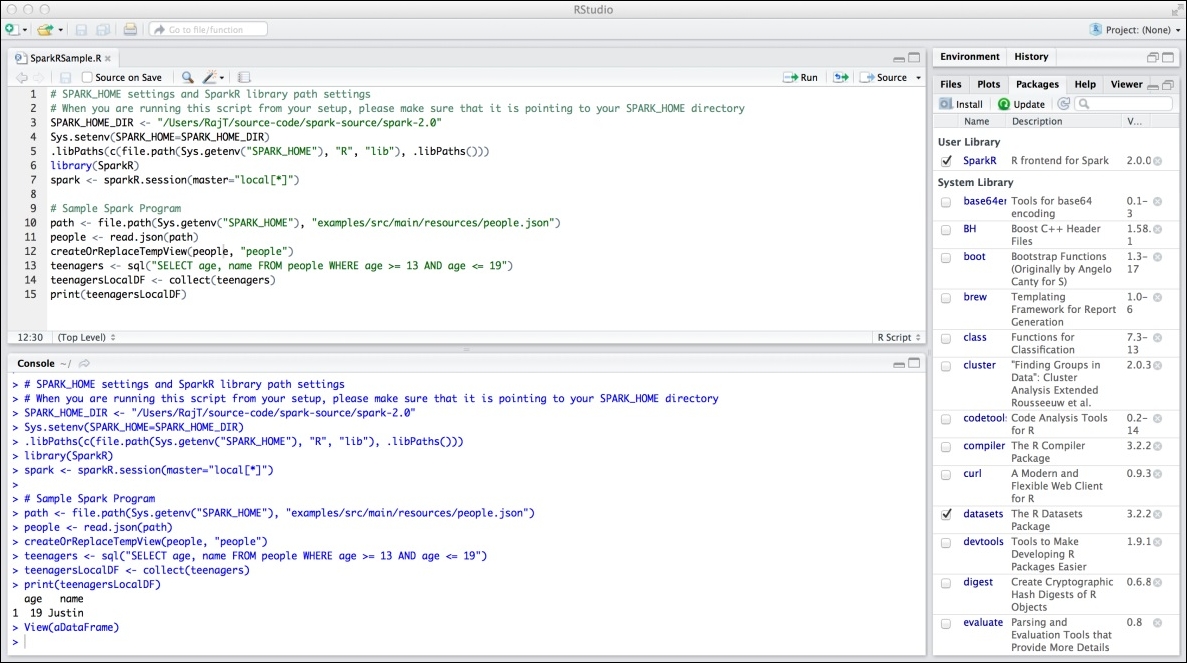
Figure 8
Once all the required software is installed, configured, and working as per the details given previously, the stage is set for Spark application development in Scala, Python, and R.
Apache Zeppelin is another promising project that is getting incubated right now. It is a web-based notebook similar to Jupyter but supporting multiple languages, shells, and technologies through its interpreter strategy enabling Spark application development inherently. Right now it is in its infant stage, but it has a lot of potential to become one of the best notebook-based application development platforms. Zeppelin has very powerful built-in charting and plotting capabilities using the data generated by the programs written in the notebook.
Zeppelin is built with high extensibility having the ability to plug in many types of interpreters using its Interpreter Framework. End users, just like any other notebook-based system, enter various commands in the notebook interface. These commands are to be processed by some interpreter to generate the output. Unlike many other notebook-style systems, Zeppelin supports a good number of interpreters or backends out of the box such as Spark, Spark SQL, Shell, Markdown, and many more. In terms of the frontend, again it is a pluggable architecture, namely, the Helium Framework. The data generated by the backend is displayed by the frontend components such as Angular JS. There are various options to display the data in tabular format, raw format as generated by the interpreters, charts, and plots. Because of the architectural separation of concerns such as the backend, the frontend, and the ability to plug in various components, it is a great way to choose heterogeneous components for the right job. At the same time, it integrates very well to provide a harmonious end-user-friendly data processing ecosystem. Even though there is pluggable architecture capability for various components in Zeppelin, the visualizations are limited. In other words, there are only a few charting and plotting options available out of the box in Zeppelin. Once the notebooks are working fine and producing the expected results, typically, the notebooks are shared with other people and for that, the notebooks are to be persisted. Zeppelin is different again here and it has a highly versatile notebook storage system. The notebooks can be persisted to the filesystem, Amazon S3, or Git, and other storage targets can be added if required.
Platform as a Service (PaaS) has been evolving over the last couple of years since the massive innovations happening around Cloud as an application development and deployment platform. For software developers, there are many PaaS platforms available delivered through Cloud, which obviates the need for them to have their own application development stack. Databricks has introduced a Cloud-based big data platform in which users can have access to a notebook-based Spark application development interface in conjunction with micro-cluster infrastructure to which the Spark applications can be submitted. There is a community edition as well, catering to the needs of a wider development community. The biggest advantage of this PaaS platform is that it is a browser-based interface and users can run their code against multiple versions of Spark and on different types of clusters.
For more information please refer to the following links:
Spark is a very powerful data processing platform supporting a uniform programming model. It supports application development in Scala, Java, Python, and R, providing a stack of highly interoperable libraries used for various types of data processing needs, and a plethora of third-party libraries that make use of the Spark ecosystem covering various other data processing use cases. This chapter gave a brief introduction to Spark and setting up the development environment for the Spark application development that is going to be covered in forthcoming chapters of the book.
The next chapter is going to discuss the Spark programming model, the basic abstractions and terminologies, Spark transformations, and Spark actions, in conjunction with real-world use cases.

