


















 Download code from GitHub
Download code from GitHub
Angular’s Architecture and Concepts
Angular is a popular Single-Page Application (SPA) framework for building web applications. It is often preferred in enterprise application development because it is an opinionated, batteries-included framework that supports type-checking with TypeScript and concepts like Dependency Injection (DI) that allow for engineering scalable solutions by large teams. In contrast, React is a flexible and unopinionated library rather than a complete framework, requiring developers to pick their flavor from the community to build fully featured applications.
React is undoubtedly the more popular choice of the two. The numbers don’t lie. React’s easier learning curve and deceptively small and simple starting point have attracted the attention of many developers. The many “Angular vs React” articles you have undoubtedly encountered online add to the confusion. These articles are usually too shallow, often contain misleading information about Angular, and lack insights into the very bright future of Angular.
This chapter aims to give you a deeper understanding of why Angular exists, the variety of patterns and paradigms you can leverage to solve complex problems, and, later in the book, the pitfalls to avoid as you scale your solution. It’s important to take your time to read through this material because every journey begins with a choice. The real story of your choice today can only be written several years into a project when it’s too late and expensive to switch technologies.
This chapter covers the following topics:
- Two Angulars
- A brief history of web frameworks
- Angular and the philosophies behind it
- Component architecture
- Reactive programming
- Modular architecture
- Standalone architecture
- Angular Router
- State management
- React.js architecture
- The future of Angular
Chapter 2, Forms, Observables, Signals, and Subjects, covers Angular fundamental concepts and building blocks. Chapter 3, Architecting an Enterprise App, covers technical, architectural, and tooling concerns for delivering large applications. With Chapter 4, Creating a Router-First Line-of-Business App, we dive into creating scalable Angular applications ready for the enterprise.
Each chapter introduces new concepts and progressively builds on best practices while covering optimal working methods with popular open-source tools. Along the way, tips and information boxes provide additional background and history, numbered steps, and bullet points that describe actions you need to take.
The code samples provided in this book have been developed using Angular 17. Since the second edition, significant changes occurred in the JavaScript and Angular ecosystems. The transition to Angular’s Ivy engine meant some third-party tools stopped working. ESLint has superseded TSLint. Karma and Jasmine have become outdated and superseded by Jest or the more modern Vitest. Significant headway was made in replacing commonjs modules with ES modules (ESM). The totality of these changes meant that much of the second edition’s supporting tools were beyond repair. As a lesson learned, the example projects now utilize minimal tooling to allow for the best possible DevEx with the least possible amount of npm packages installed. The core samples of the book, which intentionally avoided third-party libraries, were initially written for Angular 5 and have survived the test of time. This book adopts the Angular Evergreen motto and encourages incremental, proactive, and timely upgrades of your dependencies to maintain the health of your project and your team.
This book is supported by the companion site https://AngularForEnterprise.com. Visit the site for the latest news and updates.
The world of JavaScript, TypeScript, and Angular is constantly changing. To maintain consistency for my readers, I published a collection of open-source projects that support the content of the book:

Figure 1.1: Code developed in support of this book
The diagram above shows you the moving parts that make up the technical content supporting this book. Each component is detailed in the coming chapters. The code samples contain chapter-by-chapter snapshots and the final state of the code. The most up-to-date versions of the sample code for the book are on GitHub at the repositories linked below:
- For Chapters 2 and 9, LocalCast Weather: https://github.com/duluca/local-weather-app
- For Chapters 4 to 10, Lemon Mart: https://github.com/duluca/lemon-mart
- For Chapter 5, Lemon Mart Server: https://github.com/duluca/lemon-mart-server
You may read more about updating Angular in the supplemental reading, Keeping Angular and Tools Evergreen, available at https://angularforenterprise.com/evergreen.
Now that you’re oriented with the book’s structure and supporting content, and before we dive into a prolonged history of the web, let’s first disambiguate the two major architectures of Angular and the underlying themes that motivated a dramatic rewrite of the framework in 2016.
Two Angulars
In its original incarnation, Angular.js, aka 1.x, pioneered the SPA era, a technique that tricks the browser into thinking that a single index.html houses an interactive application containing many pages. Angular.js also popularized the concept of two-way binding in web development, which automatically updates the view to match the state of the ViewModel. To implement such a feature, Angular.js used Change Detection to keep track of Document Object Model (DOM) elements of the browser and the ViewModel state of the application.
Change Detection depends on a sophisticated rendering loop to detect user interactions and other events to determine if the application needs to react to changes. Whenever a rendering loop is involved, like in games, performance can be measured as a frame rate expressed in Frames per Second (FPS). A slow change detection process results in a low FPS count, translating into a choppy User Experience (UX). With the demand for more interactive and complicated web applications, it became clear that the internal architecture of Angular.js couldn’t be improved to maintain a consistent FPS output. However, UX and performance are only one side of the experience story. As an application grows more complicated better tooling is needed to support a great Developer Experience (DevEx) – sometimes called DevX or DX – which is key to developer wellbeing.
The Angular 2 rewrite, now simply referred to as Angular, aimed to solve both sides of the problem. Before frameworks and libraries like React, Angular, and Vue, we suffered from unmanaged complexity and JavaScript-framework-of-the-week syndrome. These frameworks succeeded with promises to fix all problems, bring about universally reusable web components, and make it easier to learn, develop, and scale web applications- at least for a while, some being better than others during different periods. The same problems that plagued early SPA are returning as the demand for ever more complicated web experiences increases, and the tooling to resolve these problems grows ever complex. To master Angular or any other modern framework, it is critical to learn about the past, present, and future of web development. The adolescent history of the web has taught us a couple of essential lessons. First, change is inevitable, and second, the developer’s happiness is a precious commodity that can make or break entire companies.
As you can see, Angular’s development has been deeply impacted by performance, UX, and DevEx concerns. But this wasn’t a unique problem that only impacted Angular. Let’s roll back the clock further and look at the last quarter century or so of web development history so that you can contextualize modern frameworks like Angular, React, and Vue.
A brief history of web frameworks
It is essential to understand why we use frameworks such as Angular, React, or Vue in the first place to get an appreciation of the value they bring. As the web evolves, you may find that, in some cases, the framework is no longer necessary and should be discarded, and in others, critical to your business and must be retained. Web frameworks rose as JavaScript became more popular and capable in the browser. In 2004, the Asynchronous JavaScript and XML (AJAX) technique became very popular in creating websites that did not have to rely on full-page refreshes to create dynamic experiences, utilizing standardized web technologies like HTML, JavaScript/ECMAScript, and CSS. Browser vendors are supposed to implement these technologies as defined by the World Wide Web Consortium (W3C).
Internet Explorer (IE) was the browser that most internet users relied on at the time. Microsoft used its market dominance to push proprietary technologies and APIs to secure IE’s edge as the go-to browser. Things started to get interesting when Mozilla’s Firefox challenged IE’s dominance, followed by Google’s Chrome browser. As both browsers successfully gained significant market share, the web development landscape became a mess. New browser versions appeared at breakneck speed. Competing corporate and technical interests led to the diverging implementation of web standards.
This fracturing created an unsustainable environment for developers to deliver consistent experiences on the web. Differing qualities, versions, and names of implementations of various standards created an enormous challenge: successfully writing code that could manipulate the DOM of a browser consistently. Even the slightest difference in the APIs and capabilities of a browser would be enough to break a website.
The jQuery era
In 2006, jQuery was developed to smooth out the differences between APIs and browser capabilities. So instead of repeatedly writing code to check browser versions, you could use jQuery, and you were good to go. It hid away all the complexities of vendor-specific implementations and gracefully filled the gaps when there were missing features. For almost a decade, jQuery became the web development framework. It was unimaginable to write an interactive website without using jQuery.
However, to create vibrant user experiences, jQuery alone was not enough. Native web applications ran all their code in the browser, which required fast computers to run the dynamically interpreted JavaScript and render web pages using complicated object graphs. In the 2000s, many users ran outdated browsers on relatively slow computers, so the user experience wasn’t great.
Combined with AJAX, jQuery enabled any web developer to create interactive and dynamic websites that could run on any browser without running expensive server hardware and software. To have a solid understanding of the architectural nuances of code that runs on the client and server side, consider a traditional three-tier software architecture. Each tier is described in three primary layers, as shown in the following diagram:

Figure 1.2: Three-tiered software architecture
The presentation layer contains User Interface (UI) related code. This is primarily code that runs on the client, referred to as a thick client. However, the presentation logic can instead reside on the server. In these cases, the client becomes a thin client. The business layer contains business logic and normally resides on the server side. An undisciplined implementation can result in business logic spreading across all three layers. This means a bug or a change in the logic needs to be implemented in many locations. In reality, no individual can locate every occurrence of this logic and can only partially repair code. This, of course, results in the creation of more exotic bugs. The persistence layer contains code related to data storage.
To write easy-to-maintain and bug-free code, our overall design goal is to aim for low coupling and high cohesion between the components of our architecture. Low coupling means that pieces of code across these layers shouldn’t depend on each other and should be independently replaceable. High cohesion means that pieces of code related to each other, like code regarding a particular domain of business logic, should remain together. For example, when building an app to manage a restaurant, the code for the reservation system should be together and not spread across other systems like inventory tracking or user management.
With jQuery and AJAX, writing thick clients for the web became possible, making it easier than ever to write unmaintainable code. Modern web apps have way more moving parts than a basic three-tiered application. The diagram that follows shows additional layers that fit around the presentation, business, and persistence layers:

Figure 1.3: Modern Web Architecture
You can observe the essential components of modern web development in the expanded architecture diagram, which includes an API layer that usually transforms and transfers data between the presentation and business layers. Beyond code within the operating environment, the tools and best practices layer defines and enforces patterns used to develop the software. Finally, the testing layer defines a barrage of automated tests to ensure the correctness of code, which is crucial in today’s iterative and fast-moving development cycles.
While there was a big appetite to democratize web development with thick clients primarily consuming client-side computing resources, the tooling wasn’t ready to enforce proper architectural practices and deliver maintainable software. This meant businesses kept investing in server-side rendering technologies.
The server-side MVC era
In the late 2000s, many businesses still relied on server-side rendered web pages. The server dynamically created all the HTML, CSS, and data needed to render a page. The browser acted as a glorified viewer that would display the result. The following is a diagram that shows an example architectural overview of a server-side rendered web application in the ASP.NET MVC stack:

Figure 1.4: Server-side rendered MVC architecture
Model-View-Controller (MVC) is a typical pattern of code that has data manipulation logic in models, business logic in controllers, and presentation logic in views. In the case of ASP.NET MVC, the controller and model are coded using C#, and views are created using a templated version of HTML, JavaScript, and C#. The result is that the browser receives HTML, JavaScript, and needed data, and through jQuery and AJAX magic, web pages look to be interactive. Server-side rendering and MVC patterns are still popular and in use today. There are justified niche uses, such as Facebook.com. Facebook serves billions of devices that range from the very slow to the very fast. Without server-side rendering, it would be impossible for Facebook to guarantee consistent UX across its user base.
The combination of server-side rendering and MVC is an intricate pattern to execute; there are a lot of opportunities for presentation and business logic to become co-mingled. To ensure the low coupling of components, every member of the engineering team must be very experienced. Teams with a high concentration of senior developers are hard to come by, which would be an understatement.
Further complicating matters is that C# (or any other server-side language) cannot run natively in the browser. So developers who work on server-side rendered applications must be equally skilled at using frontend and backend technologies. It is easy for inexperienced developers to unintentionally co-mingle presentation and business logic in such implementations. When this happens, the inevitable UI modernization of an otherwise well-functioning system becomes impossible. In other words, to replace the sink in your kitchen with a new one, you must renovate your entire kitchen. Due to insufficient architecture, organizations spend millions of dollars writing and rewriting the same applications every decade.
Rich client era
In the 2000s, it was possible to build rich web applications decoupled from their server APIs using Java Applets, Flash, or Silverlight. However, these technologies relied on browser plugins that needed a separate installation. Most often, these plugins were outdated, created critical security vulnerabilities, and consumed too much power on mobile computers. Following the iPhone revolution in 2008, it was clear such plugins wouldn’t run on mobile phones, despite the best attempts by the Android OS. Besides, Apple CEO Steve Jobs’ disdain for such inelegant solutions marked the beginning of the end for the support of such technologies in the browser.
In the early 2010s, frameworks like Backbone and AngularJS started showing up, demonstrating how to build rich web applications with a native feel and speed and do so in a seemingly cost-effective way. The following diagram shows a Model-View-ViewModel (MVVM) client with a Representational State Transfer (REST) API. When we decouple the client from the server via an API, we can architecturally enforce the implementation of presentation and business logic separately. Theoretically, this RESTful web services pattern would allow us to replace the kitchen sink as often as possible without remodeling the entire kitchen.

Figure 1.5: Rich-client decoupled MVVM architecture
The MVVM architecture above shows a near doubling of boxes compared to the server-side MVC architecture. Does this mean we need to write twice as much code? Yes and no. Yes, we need to write more code to maintain a disciplined architecture; however, over time, we’ll write a lot less code because of the overall maintainability of the solution. The architecture surrounding the presentation logic indeed becomes a lot more complicated. The client and server must implement their presentation/API, business, and persistence layers.
Unfortunately, many early development efforts leveraging frameworks like Backbone and AngularJS collapsed under their weight because they failed to implement the client-side architecture properly.
These early development efforts also suffered from ill-designed RESTful Web APIs. Most APIs didn’t version their URIs, making it very difficult to introduce new functionality while supporting existing clients. Further, APIs often returned complicated data models exposing their internal relational data models to web apps. This design flaw creates a tight coupling between seemingly unrelated components/views written in HTML and models created in SQL. If you don’t implement additional layers of code to translate or map the structure of data, then you create an unintentional and uncontrolled coupling between layers. Over time, dealing with such coupling becomes very expensive very quickly, in most cases necessitating significant rewrites.
Today, we use the API layer to flatten the data model before sending it to the client to avoid such problems. Newer technologies like GraphQL go further by exposing a well-defined data model and letting the consumer query for the exact data it needs. Using GraphQL, the number of HTTP requests and the amount of data transferred over the wire is optimal without the developers having to create many specialized APIs.
Backbone and AngularJS proved that creating web applications that run natively in the browser was viable. All SPA frameworks at the time relied on jQuery for DOM manipulation. Meanwhile, web standards continued to evolve, and evergreen browsers supporting new standards became commonplace. However, change is constant, and the evolution of web technologies made it unsustainable to gracefully evolve this first generation of SPA frameworks, as I hinted in the Two Angulars section.
The next generation of web frameworks needed to solve many problems; they needed to enforce good architecture, be designed to evolve with web standards and be stable and scalable to enterprise needs without collapsing. Also, these new frameworks needed to gain acceptance from developers, who were burned out with too many rapid changes in the ecosystem. Remember, unhappy developers do not create successful businesses. Achieving these goals required a clean break from the past, so Angular and React emerged as platforms to address the problems of the past in different ways. As you’ll discover in the following sections, Angular offers the best tools and architecture for building scalable enterprise-grade applications.
Angular and the philosophies behind it
Angular is an open-source project maintained by Google and a community of developers. The new Angular platform vastly differs from the legacy framework you may have used. In collaboration with Microsoft, Google made TypeScript the default language for Angular. TypeScript is a superset of JavaScript that enables developers to target legacy browsers, such as Internet Explorer 11, while allowing them to write modern JavaScript code that works in evergreen browsers such as Chrome, Firefox, and Edge. The legacy version of Angular in the 1.x range, called AngularJS, was a monolithic JavaScript SPA framework. The modern version, Angular 2+, is a platform capable of targeting browsers, hybrid-mobile frameworks, desktop applications, and server-side rendered views.
In the prior generation, upgrading to new versions of AngularJS was risky and costly because even minor updates introduced new coding patterns and experimental features. Each update introduced deprecations or refactored API surfaces, requiring rewriting of large portions of code. Also, updates were delivered in uncertain intervals, making it impossible for a team to plan resources to upgrade to a new version. The release methodology eventually led to an unpredictable, ever-evolving framework with seemingly no guiding hand to carry code bases forward. If you used AngularJS, you were likely stuck on a particular version because the specific architecture of your code base made it very difficult to move to a new version. In 2018, the Angular team released the last major update to AngularJS with version 1.7. This release marked the beginning of the end for the legacy framework, with end-of-life coming in January 2022.
Deterministic releases
Angular improves upon AngularJS in every way imaginable. The platform follows semver, as defined at https://semver.org/, where minor version increments denote new feature additions and potential deprecation notices for the following major version, but no breaking changes. Furthermore, the Angular team at Google has committed to a deterministic release schedule with major versions released every 6 months. After this 6-month development window, starting with Angular 4, all major releases receive LTS with bug fixes and security patches for an additional 12 months. From release to end-of-life, each major version receives updates for 18 months. Refer to the following chart for the tentative release and support schedule for Angular:

Figure 1.6: Actively supported versions
What does this mean for you? You can be confident that your Angular code is supported and backward compatible for approximately 24 months, even if you make no changes to it. For example, if you wrote an Angular app in version 17 in November 2023, and you didn’t use any deprecated functionality, your code will be runtime compatible with Angular 18 and supported through May 2025. To upgrade your Angular 17 code to Angular 19, you must ensure that you’re not using any deprecated APIs that receive a deprecation notice in Angular 18.
In practice, most deprecations are minor and are straightforward to refactor. Unless you work with low-level APIs for highly specialized user experiences, the time and effort it takes to update your code base should be minimal. However, this is a promise made by Google and not a contract. The Angular team has a significant incentive to ensure backward compatibility because Google runs around 1,000+ Angular apps with a single version of Angular active at any one time throughout the organization. So, by the time you read this, all of Google’s 1,000+ apps will be running on the latest version of Angular.
First-class upgrades
You may think Google has infinite resources to update thousands of apps regularly. Like any organization, Google, too, has limited resources. It would be too expensive to assign a dedicated team to maintain every app. So the Angular team must ensure compatibility through automated tests and make it as painless as possible to move through major releases in the future. In Angular 6 ng update was introduced, making the update process a first-class experience.
The Angular team continually improves its release process with automated CLI tools to make upgrading deprecated functionality a mostly automated, reasonable endeavor. Air France and KLM demonstrated this strategy’s benefits, reducing their upgrade times from 30 days in Angular 2 to 1 day in Angular 7.
A predictable and well-supported upgrade process is excellent news for developers and organizations. Instead of being perpetually stuck on a legacy version of Angular, you can plan and allocate the necessary resources to keep moving your application to the future without costly rewrites. As I wrote in a 2017 blog post, The Best New Feature of Angular 4, at https://bit.ly/NgBestFeature, the message is clear:
For developers and managers: Angular is here to stay, so you should be investing your time, attention, and money in learning it – even if you’re currently in love with some other framework.
For decision makers (CIOs, CTOs, and so on): Plan to begin your transition to Angular in the next 6 months. It’ll be an investment you’ll be able to explain to business-minded people, and your investment will pay dividends for many years to come, long after the initial LTS window expires, with graceful upgrade paths to Angular vNext and beyond.
So why do Google (Angular) and Microsoft (TypeScript and Visual Studio Code) give away such technologies for free? There are multiple reasons:
- A sophisticated framework that makes it easy to develop web apps demonstrates technical prowess, which retains and attracts developer talent.
- An open-source framework enables the proving and debugging of new ideas and tools with millions of developers at scale.
- Allowing developers to create great web experiences drives more business for Google and Microsoft.
I don’t see any nefarious intent here and welcome open, mature, and high-quality tools that, if necessary, I can tinker with and bend to my own will. Not having to pay for a support contract for a proprietary piece of tech is a welcome bonus.
Beware - looking for Angular help on the web may be tricky. You’ll need to disambiguate between AngularJS or Angular, which may be referred to as Angular2, but also be aware that some advice given about versions 13 or below may not apply to 14+ because of the rendering engine change to Ivy. I always recommend reading the official documentation when learning. Documentation for Angular is at https://angular.dev. This should not be confused with angularjs.org, which is about the legacy AngularJS framework or the retired angular.io site.
For the latest updates on the upcoming Angular releases, view the official release schedule at https://angular.dev/reference/releases.
Maintainability
Your time is valuable, and your happiness is paramount, so you must carefully choose the technologies to invest your time in. With this in mind, we must answer why Angular is the tool you should learn over React, Vue, or others. Angular is a great framework to start learning. The framework and the tooling help you get off the ground quickly and continue being successful, with a vibrant community and high-quality UI libraries you can use to deliver exceptional web applications. React and Vue are great libraries with their strengths and weaknesses. Every tool has its place and purpose.
In some cases, React is the right choice for a project, while Vue is the right one in others. Becoming somewhat proficient in other web frameworks can only help further your understanding of Angular and make you a better developer overall. SPAs such as Backbone and AngularJS grabbed my full attention in 2012 when I realized the importance of decoupling frontend and backend concerns. Server-side rendered templates are nearly impossible to maintain and are the root cause of many expensive rewrites of software systems. If you care about creating maintainable software, you must abide by the prime directive: keep the business logic behind the API decoupled from the presentation logic implemented in the UI.
Angular neatly fits the Pareto principle or the 80-20 rule. It has become a mature and evolving platform, allowing you to achieve 80% of tasks with 20% of the effort. As mentioned in the previous section, every major release is supported for 18 months, creating a continuum of learning, staying up to date, and deprecating old features. From the perspective of a full-stack developer, this continuum is invaluable since your skills and training will remain relevant and fresh for many years to come.
The philosophy behind Angular is to err on the side of configuration over convention. Although convention-based frameworks may seem elegant from the outside, they make it difficult for newcomers to pick up the framework. Configuration-based frameworks aim to expose their inner workings through explicit configuration and hooks, where you can attach your custom behavior to the framework. In essence, where AngularJS had tons of magic, which can be confusing, unpredictable, and challenging to debug, Angular tries to be non-magical.
Configuration over convention results in verbose coding. Verbosity is a good thing. Terse code is the enemy of maintainability, only benefiting the original author. As Andy Hunt and David Thomas put it in The Pragmatic Programmer:
Remember that you (and others after you) will be reading the code many hundreds of times, but only writing it a few times.
Further, Andy Hunt’s Law of Design dictates:
If you can’t rip every piece out easily, then the design sucks.
Verbose, decoupled, cohesive, and encapsulated code is the key to future-proofing your code. Through its various mechanisms, Angular enables the proper execution of these concepts. It eliminates many custom conventions invented in AngularJS, such as ng-click, and introduces a more natural language that builds on the existing HTML elements and properties. As a result, ng-click becomes (click), extending HTML rather than replacing it.
Next, we’ll review Angular’s evergreen mindset and the reactive programming paradigm, the latest extensions of Angular’s initial philosophy.
Angular Evergreen
When you’re learning Angular, you’re not learning one specific version of Angular but a platform that is continually evolving. Since the first drafts, I designed this book to deemphasize the specific version of Angular you’re using. The Angular team champions this idea. Over the years, I have had many conversations with the Angular team and thought leaders within the community and listened to many presentations. As a result, you can depend on Angular as a mature web development platform. Angular frequently receives updates with great attention to backward compatibility. Furthermore, any code made incompatible by a new version is brought forward with help from automated tools or explicit guidance on updating your code by locating the Angular Update Guide on https://angular.dev/update, so you’re never left guessing or scouring the internet for answers. The Angular team is committed to ensuring you – the developer – have the best web development experience possible.
To bring this idea front and center with developers, several colleagues and I have developed and published a Visual Studio Code extension called Angular Evergreen, as shown in the following image:

Figure 1.7: Angular Evergreen VS Code extension
This extension detects your current version of Angular and compares it to the latest and next releases of Angular. Releases labeled next are meant for early adopters and testing your code’s compatibility with an upcoming version of Angular. Do not use next-labeled releases for production deployments.
Find more information, feature requests, and bug reports on the Angular Evergreen extension at https://AngularEvergreen.com.
One of the critical components of Angular that allows the platform to remain evergreen is TypeScript. TypeScript allows new features to be implemented efficiently while supporting older browsers, so your code can reach the widest audience possible.
TypeScript
Angular is coded using TypeScript. Anders Hejlsberg of Microsoft created TypeScript to address several major issues with applying JavaScript at a large enterprise scale.
Anders Hejlsberg is the creator of Turbo Pascal and C# and Delphi’s chief architect. Anders designed C# to be a developer-friendly language built upon the familiar syntax of C and C++. As a result, C# became the language behind Microsoft’s popular .NET Framework. TypeScript shares a similar pedigree with Turbo Pascal and C# and their ideals, which made them a great success.
JavaScript is a dynamically interpreted language where the browser parses and understands the code you write at runtime. Statically typed languages like Java or C# have an additional compilation step where the compiler can catch programming and logic errors during compile time. Detecting and fixing bugs at compile time versus runtime is much cheaper. TypeScript brings the benefits of statically typed languages to JavaScript by introducing types and generics. However, TypeScript is not a compiler in the traditional sense. It is a transpiler. A compiler builds code into machine language with C/C++ or Intermediary Language (IL) with Java or C#. A transpiler, however, transforms the code from one dialect to another. So, when TypeScript code is built, compiled, or transpiled, the result is pure JavaScript.
JavaScript’s official name is ECMAScript. The language’s feature set and syntax are maintained by the ECMA Technical Committee 39, or TC39 for short.
Transpilation has another significant benefit. The same tooling that converts TypeScript to JavaScript can be used to rewrite JavaScript with a new syntax to an older version that older browsers can parse and execute. Between 1999 and 2009, the JavaScript language didn’t see any new features. ECMAScript abandoned version 4 due to various technical and political reasons. Browser vendors have struggled to implement new JavaScript features within their browsers, starting with the introduction of ES5 and then ES2015 (also known as ES6).
As a result, user adoption of these new features has remained low. However, these new features meant developers could write code more productively. This created a gap known as the JavaScript Feature Gap, as demonstrated by the graphic that follows:

Figure 1.8: The JavaScript Feature Gap
The JavaScript Feature Gap is sliding, as TC39 has committed to updating JavaScript every year. As a result, TypeScript represents JavaScript’s past, present, and future. You can use future features of JavaScript today and still be able to target browsers of the past to maximize the audience you can reach. In 2023, this gap is smaller than ever, with ES2022 being a mature language with wide support from every major browser.
Now, let’s go over Angular’s underlying architecture.
Component architecture
Angular follows the MV* pattern, a hybrid of the MVC and MVVM patterns. Previously, we went over the MVC pattern. At a high level, the architecture of both patterns is relatively similar, as shown in the diagram that follows:

Figure 1.9: MV* architecture
The new concept here is the ViewModel, which represents the glue code that connects your view to your model or service. In Angular, this glue is known as binding. Whereas MVC frameworks like Backbone or React must call a render method to process their HTML templates, in Angular, this process is seamless and transparent for the developer. Binding is what differentiates an MVC application from an MVVM one.
The most basic unit of an Angular app is a component. A component combines a JavaScript class, written in TypeScript, and an Angular template, written in HTML, CSS, and TypeScript, as one element. The class and the template fit together like a jigsaw puzzle through bindings so that they can communicate with each other, as shown in the diagram that follows:

Figure 1.10: Anatomy of a component
Classes are an Object-Oriented Programming (OOP) construct. If you invest the time to dig deeper into the OOP paradigm, you will vastly improve your understanding of how Angular works. The OOP paradigm allows for the Dependency Injection (DI) of dependent services in your components, so you can make HTTP calls or trigger a toast message to be displayed to the user without pulling that logic into your component or duplicating your code. DI makes it very easy for developers to use many interdependent services without worrying about the order of the instantiation, initialization, or destruction of such objects from memory.
Angular templates allow similar code reuse via directives, pipes, user controls, and other components. These are pieces of code that encapsulate highly interactive end-user code. This kind of interactivity code is often complicated and convoluted and must be kept isolated from business logic or presentation logic to keep your code maintainable.
Angular 17 introduces a new control flow syntax (in preview), which replaces directives like *ngIf with @if, *ngFor with @for, and *ngSwitch with @switch and introduces @empty, @defer, contextual variables, and conditional statements. The new syntax makes templates easier to read and avoids importing legacy directives to every component in a standalone project. This book will exclusively use the control flow syntax.
You can run npx ng generate @angular/core:control-flow to convert your existing template to the new syntax.
Angular apps can be created in two different ways:
- An NgModule project
- A standalone project
As of Angular 17, the default way is to bootstrap your app as a standalone project. This approach has many benefits, as further explained in The Angular Router section below. There is a lot of new terminology to learn, but modules as a concept aren’t going away. It’s just that they’re no longer required.
Whether your app starts with bootstrapApplication or bootstrapModule, at the root level of your application, Angular components, services, directives, pipes, and user controls are provided to the bootstrapApplication function or organized under modules. The root level configuration renders your first component, injects any services, and prepares any dependencies it may require. In a standalone app, you can lazily load individual components.
You may also introduce feature modules to lazy load groups of services and components. All these features help the initial app load up very quickly, improving First Contentful Paint times because the framework doesn’t have to download and load all web application components in the browser simultaneously. For instance, sending code for the admin dashboard to a user without admin privileges is useless.
Being able to create standalone components allows us to ditch contrived modules. Previously, you were forced to place shared components in a shared module, leading to inefficiencies in reducing app size because developers wouldn’t necessarily want to create a module per shared component. For example, the LocalCast Weather app is a simple app that doesn’t benefit from the concept of a module, but the LemonMart app naturally reflects a modular architecture by implementing separate business functions in different modules. More on this later in the chapter in the Modular architecture section.
Standalone components shouldn’t be confused with Angular elements, an implementation of the web standard, custom elements, also known as Web Components. Implementing components in this manner would require the Angular framework to be reduced to only a few KB in size, as opposed to the current framework of around 150 KB. If this is successful, you will be able to use an Angular component you develop in any web application. Exciting stuff but also a tall order. You can read more about Angular elements at https://angular.dev/guide/elements.
Angular heavily uses the RxJS library, which introduces reactive development patterns to Angular instead of more traditional imperative development patterns.
Reactive programming
Angular supports multiple styles of programming. The plurality of coding styles within Angular is one of the reasons it is approachable to programmers with varying backgrounds. Whether you come from an object-oriented programming background or are a staunch believer in functional programming, you can build viable apps using Angular. In Chapter 2, Forms, Observables, Signals, and Subjects, you’ll begin leveraging reactive programming concepts in building the LocalCast Weather app.
As a programmer, you are most likely used to imperative programming. Imperative programming is when you, as the programmer, write sequential code describing everything that must be done in the order that you’ve defined them and the state of your application, depending on just the right variables to be set to function correctly. You write loops, conditionals, and call functions; you fire off events and expect them to be handled. Imperative and sequential logic is how you’re used to coding.
Reactive programming is a subset of functional programming. In functional programming, you can’t rely on variables you’ve set previously. Every function you write must stand on its own, receive its own set of inputs, and return a result without being influenced by the state of an outer function or class. Functional programming supports Test Driven Development (TDD) very well because every function is a unit that can be tested in isolation. As such, every function you write becomes composable. So you can mix, match, and combine any function you write with any other and construct a series of calls that yield the result you expect.
Reactive programming adds a twist to functional programming. You no longer deal with pure logic but an asynchronous data stream that you transform and mold into any shape you need with a composable set of functions. So when you subscribe to an event in a reactive stream, you’re shifting your coding paradigm from reactive programming to imperative programming.
Later in the book, when implementing the LocalCast Weather app, you’ll leverage subscribe in action in the CurrentWeatherComponent and CitySearchComponent.
Consider the following example, aptly put by Mike Pearson in his presentation Thinking Reactively: Most Difficult, of providing instructions to get hot water from the faucet to help understand the differences between imperative and reactive programming:
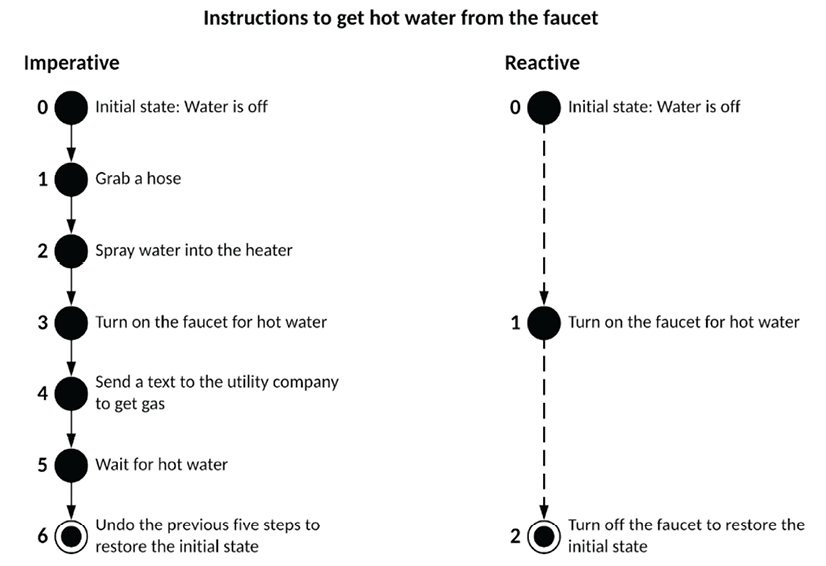
Figure 1.11: Imperative vs Reactive methodology
As you can see, with imperative programming, you must define every step of the code execution. There are six steps in total. Every step depends on the previous step, which means you must consider the state of the environment to ensure a successful operation. In such an environment, it is easy to forget a step and very difficult to test the correctness of every individual step. In functional reactive programming, you work with asynchronous data streams resulting in a stateless workflow that is easy to compose with other actions. There are two steps in total, but step 2 doesn’t require any new logic. It simply disconnects the code in step 1.
RxJS is the library that allows you to implement your code in the reactive paradigm.
Angular 16 introduced signals, in a developer preview, as a new paradigm to enable fine-grained reactivity within Angular. In Chapter 2, Forms, Observables, Signals, and Subjects, you will implement signals in your Angular application. Refer to the Future of Angular section later in the chapter for more information.
RxJS
RxJS stands for Reactive Extensions, a modular library that enables reactive programming. It is an asynchronous programming paradigm that allows data stream manipulation through transformation, filtering, and control functions. You can think of reactive programming as an evolution of event-based programming.
Reactive data streams
In event-driven programming, you would define an event handler and attach it to an event source. In more concrete terms, if you had a Save button, which exposes an onClick event, you would implement a confirmSave function that, when triggered, would show a popup to ask the user ‘Are you sure?’. Look at the following diagram for a visualization of this process:
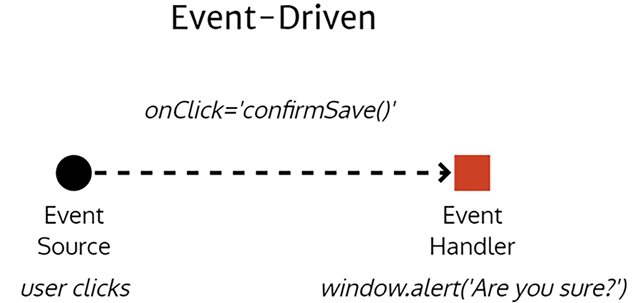
Figure 1.12: Event-driven implementation
In short, you would have an event firing once per user action. If the user clicks on the Save button many times, this pattern will gladly render as many popups as there are clicks, which doesn’t make much sense.
The publish-subscribe (pub/sub) pattern is a different type of event-driven programming. In this case, we can write multiple handlers to all simultaneously act on a given event’s result. Let’s say that your app just received some updated data. The publisher goes through its list of subscribers and passes the updated data to each.
Refer to the following diagram on how the updated data event triggers multiple functions:
- An
updateCachefunction updates your local cache with new data - A
fetchDetailsfunction retrieves further details about the data from the server - A
showToastMessagefunction informs the user that the app just received new data
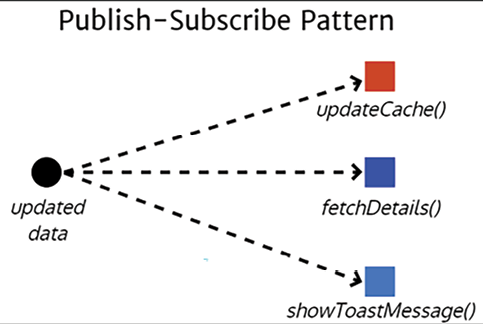
Figure 1.13: Pub/sub pattern implementation
All these events can happen asynchronously; however, the fetchDetails and showToastMessage functions will receive more data than they need, and it can get convoluted to try to compose these events in different ways to modify application behavior.
In reactive programming, everything is treated as a stream. A stream will contain events that happen over time, which can contain some or no data. The following diagram visualizes a scenario where your app is listening for mouse clicks from the user. Uncontrolled streams of user clicks are meaningless. You exert some control over this stream by applying the throttle function, so you only get updates every 250 milliseconds (ms). If you subscribe to this new event stream, every 250 ms, you will receive a list of click events. You may try to extract some data from each click event, but in this case, you’re only interested in the number of click events that happened. Using the map function, we can shape the raw event data into the sum of all clicks.
Further down the stream, we may only be interested in listening for events with two or more clicks, so we can use the filter function to act only on what is essentially a double-click event. Every time our filter event fires, it means that the user intended to double-click, and you can act on that information by popping up an alert.
The true power of streams comes from the fact that you can choose to act on the event at any time as it passes through various control, transformation, and filter functions. You can choose to display click data on an HTML list using @for and Angular’s async pipe so that the user can monitor the types of click data being captured every 250 ms.
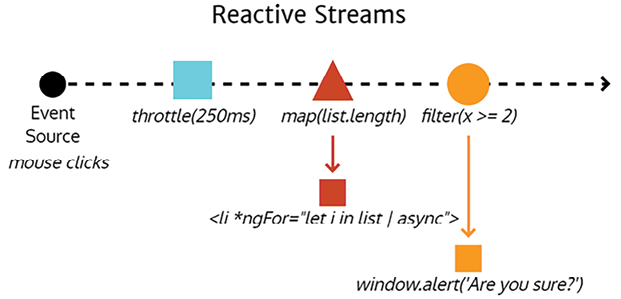
Figure 1.14: A reactive data stream implementation
Now let’s consider some more advanced Angular architectural patterns.
Modular architecture
As mentioned earlier in the Component architecture section, if you create an NgModule project, Angular components, services, and dependencies are organized into modules. Angular apps are bootstrapped via their root module, as shown in the diagram that follows:

Figure 1.15: Angular Bootstrap process showing major architectural elements
The root module can import other modules, declare components, and provide services. As your application grows, you must create sub-modules containing their components and services. Organizing your application in this manner allows you to implement lazy loading, allowing you to control which parts of your application get delivered to the browser and when. As you add more features to your application, you import modules from other libraries, like Angular Material or NgRx. You implement the router to enable rich navigational experiences between your components, allowing your routing configuration to orchestrate the creation of components.
Chapter 4, Creating a Router-First Line-of-Business App, introduces router-first architecture, where I encourage you to start developing your application by creating all your routes ahead of time.
In Angular, services are provided as singletons to a module by default. You’ll quickly get used to this behavior. However, you must remember that if you provide the same service across multiple modules, each module has its own instance of the provided service. In the case of an authentication service, where we wish to have only one instance across our entire application, you must be careful to provide that instance of the authentication service only at the root module level. Any service, component, or module provided at the root level of your application becomes available in the feature module.
Standalone architecture
If you create a standalone project, your dependencies will be provided at the root level bootstrapApplication function. First-party and third-party libraries are updated to expose provider functions instead of modules. These provider functions are inherently tree-shakable, meaning the framework can remove them from the final package if unused. The provider functions can be customized using “with” functions, where a function named withFeature() can enable a certain feature.
In standalone projects and while using standalone components in general, we must explicitly import the features they use that are not included in the providers. This means pipes, directives (including fundamental directives like *ngIf -- unless you’re using @if, of course), and child components must be provided. This can feel more verbose and restrictive than an NgModule project, but the long-term benefits outweigh the short-term pain. The better information we can provide to the framework about our projects, the better the framework can optimize our code and improve performance.
You can migrate existing NgModule projects to a standalone project using the following command:
$ npx ng g @angular/core:standalone
Beware - this is not a foolproof or entirely automated process. Read about it more at https://angular.dev/reference/migrations/standalone.
The router is the next most powerful technology you must master in Angular.
Angular Router
The Angular Router, shipped in the @angular/router package, is a central and critical part of building SPAs that act and behave like regular websites that are easy to navigate, using browser controls or the zoom or micro zoom controls.
The Angular Router has advanced features such as lazy loading, router outlets, auxiliary routes, smart active link tracking, and the ability to be expressed as an href, which enables a highly flexible Router-first app architecture leveraging stateless data-driven components, using RxJS BehaviorSubject or a signal.
A class (a component or a service in Angular) is stateless if it doesn’t rely on instance variables in executing any of its behavior (via functions or property getters/setters). A class is data-driven when it’s used to manage access to data. A stateless data-driven component can hold references to data objects and allow access to them (including mutations via functions) but would not store any bookkeeping or state information in a variable.
Large teams can work against a single code base, with each team responsible for a module’s development, without stepping on each other’s toes while enabling easy continuous integration. With its billions of lines of code, Google works against a single code base for a very good reason: integration after the fact is very expensive.
Small teams can remix their UI layouts on the fly to quickly respond to changes without having to rearchitect their code. It is easy to underestimate the time wasted due to late-game changes in layout or navigation. Such changes are easier for larger teams to absorb but costly for small teams.
Consider the following diagram; first off, depending on the bootstrap configuration, the app will either be a standalone or NgModule project. Regardless, you’ll define a rootRouter at the root of your application; components a, master, and detail; services; pipes; directives; and other modules will be provided. All these components will be parsed and eagerly loaded by the browser when a user first navigates to your application.

Figure 1.16: Angular architecture
If you were to implement a lazily loaded route, /b, you would need to create a feature module named b, which would have its childRouter; components /b/a and /b/b; services; pipes; directives; and other modules provided for it. During transpilation, Angular will package these components into a separate file or bundle, and this bundle will only be downloaded, parsed, and loaded if the user ever navigates to a path under /b.
In a standalone project, you can lazy load other standalone components represented by the triangles. You can organize components in a route configuration file. The /c/a and /c/b components will have access to providers at the root level. You may provide an environment injector for a specific component in the route config file. Practically speaking, this is only useful if you want to provide a service only ever used by that component or one with a specific scope, e.g., a state that’s only used by that component. In contrast to a NgModule app, you will have to declare the modules you’re using in each component granularly. However, unlike an NgModule app, root-level providers not used by any component are tree-shakable. The combination of these two properties results in a small app bundle, and given each module can be individually lazy loaded, the size of each bundle will be smaller as well, leading to better overall performance.
Let’s investigate lazy loading in more detail.
Lazy loading
The dashed line connecting /b/... to rootRouter demonstrates how lazy loading works. Lazy loading allows developers to achieve a sub-second First Meaningful Paint quickly. By deferring the loading of additional modules, we can keep the bundle size delivered to the browser to a minimum. The size of a module negatively impacts download and loading speeds because the more a browser has to do, the longer it takes for a user to see the app’s first screen. By defining lazily loaded modules, each module is packaged as separate files, which can be downloaded and loaded individually and on demand.
The Angular Router provides smart active link tracking, which results in a superior developer and user experience, making it very easy to implement highlighting features to indicate to the user the current tab or portion of the currently active app. Auxiliary routes maximize components’ reuse and help easily pull off complicated state transitions. With auxiliary routes, you can render multiple master and detail views using only a single outer template. You can also control how the route is displayed to the user in the browser’s URL bar and compose routes using routerLink in the template and Router.navigate in the component class, driving complicated scenarios.
In Chapter 4, Creating a Router-First Line-of-Business App, I cover implementing router basics, and advanced recipes are covered in Chapter 8, Recipes – Reusability, Forms, and Caching.
Beyond routing, state management is another crucial concept to master if you want to build sophisticated Angular applications.
State management
An EcmaScript class backs every component and service in Angular. When instantiated, a class becomes an object in memory. As you work with an object, if you store values in object properties, you’re introducing state to your Angular application. If unmanaged, the state becomes a significant liability to the success and maintainability of your application.
I’m a fan of stateless design both in the backend and frontend. From my perspective, state is evil, and you should pay careful attention to not introduce state into your code. Earlier, we discussed how services in Angular are singletons by default. This is a terrible opportunity to introduce state to your application. You must avoid storing information in your services. In Chapter 4, Creating a Router-First Line-of-Business App, I introduce you to readonly BehaviorSubject, which acts as a data anchor for your application. In this case, we store these anchors in services to share them across components to synchronize data. The data anchor is a reference to the data instead of a copy. The service doesn’t store any metadata or do any bookkeeping.
In Angular components, the class is a ViewModel acting as the glue code between your code and the template. Components are relatively short-lived compared to services, and it is okay to use object properties in this context.
However, beyond design, there are specific use cases for introducing robust mechanisms to maintain complicated data models in the state of your application. Progressive web applications (PWA) and mobile applications are cases where connectivity is not guaranteed. In these cases, being able to save and resume the entire state of your application is a must to provide a great UX for your end user.
The NgRx library for Angular leverages the Flux pattern to enable sophisticated state management for your applications. In Chapter 2, Forms, Observables, Signals, and Subjects, and Chapter 9, Recipes – Master/Detail, Data Tables, and NgRx, I provide alternative implementations for various features using NgRx to demonstrate the differences in implementation between more lightweight methods.
The Flux pattern
Flux is the application architecture created by Facebook to assist in building client-side web applications. The Flux pattern defines a series of components that manage a store that stores the state of your application, via dispatchers that trigger/handle actions and view functions that read values from the store. Using the Flux pattern, you keep the state of your application in a store where access to the store is only possible through well-defined and decoupled functions, resulting in architecture that scales well because, in isolation, decoupled functions are easy to reason with and write automated unit tests for.
Consider the diagram that follows to understand the flow of information between these components:

Figure 1.17: NgRx data flow
NgRx implements the Flux pattern in Angular using RxJS.
NgRx
The NgRx library brings Redux-like (a popular React.js library) reactive state management to Angular based on RxJS. State management with NgRx allows developers to write atomic, self-contained, and composable pieces of code, creating actions, reducers, and selectors. This kind of reactive programming allows side effects in state changes to be isolated and feels right at home with the general coding patterns of React.js. NgRx creates an abstraction layer over already complex and sophisticated tooling like RxJS.
There are excellent reasons to use NgRx, such as if you deal with 3+ input streams in your application. In such a scenario, the overhead of dealing with so many events makes it worthwhile to introduce a new coding paradigm to your project. However, most applications only have two input streams: REST APIs and user input. NgRx may make sense for offline-first Progressive Web Apps (PWAs), where you may have to persist and restore complicated state information (or niche enterprise apps with similar needs).
Here’s an architectural overview of NgRx:

Figure 1.18: NgRx architectural overview
Consider the very top of the diagram as an observable action stream, where actions can be dispatched and acted upon as denoted by the circles. Effects and components can dispatch an action. Reducers and effects can act upon these actions to either store values in the store or trigger an interaction with the server. Selectors are leveraged by components to read values from the store.
Given my positive attitude toward minimal tooling and a lack of definite necessity for NgRx beyond the niche audiences previously mentioned, I do not recommend NgRx as a default choice. RxJS/BehaviorSubject are powerful and capable enough to unlock sophisticated and scalable patterns to help you build great Angular applications, as is demonstrated in the chapters that lead up to Chapter 9, Recipes – Master/Detail, Data Tables, and NgRx.
You can read more about NgRx at https://ngrx.io.
NgRx component store
The NgRx component store, with the package name @ngrx/component-store, is a library that aims to simplify state management by targeting local/component states. It is an alternative to a reactive push-based subject-in-a-service approach. For scenarios where the state of a component is only changed by the component itself or a small collection of components, you can improve the testability, complexity, and performance of your code by using this library.
In contrast to global-state solutions like NgRx, the NgRx component store, with its limited scope, can automatically clear itself when its associated view is detached from the component tree. Unlike a singleton service, you can have multiple instances of a component store, enabling distinct states for different components. Additionally, the conceptual model for the component store is straightforward. One only needs to grasp the select, updater, and effect concepts, all operating within a confined scope. Hence, for those crafting a standalone Angular app or seeking component-specific storage, the NgRx component store provides a sustainable and easily testable approach.
You can find out more about the NgRx component store at https://ngrx.io/guide/component-store.
React.js architecture
In contrast to Angular, React.js implements the Flux pattern hollistically. Following is a router-centric view of a React application, where components/containers and providers are represented in a strict tree-like manner.

Figure 1.19: React.js architectural overview
In the initial releases of React, one had to laboriously pass values up/down the inheritance tree of every component for even the most basic functionality to work. Later, react-redux was introduced, so each component can read/write values directly to the store without traversing the tree.
This basic overview should give you a sense of the significant architectural differences between Angular and React. However, keep in mind that just like Angular, React’s community, patterns, and practices are continually evolving and getting better over time.
If you dig simplicity, check out Vue. It. Is. Simple. In a good way: https://vuejs.org.
You can learn more about React at https://reactjs.org.
Future of Angular
One of the biggest benefits of Angular is that you can count on major releases every 6 months. However, with a regular cadence comes the pressure to release meaningful and splashy updates with every major release. We can probably blame Google for creating this pressure. If you’re not constantly producing, you’re out. This has an unfortunate side effect of new features being released in preview or an unfinished state. While an argument can be made that releasing upcoming features in preview allows for feedback to be collected from the developer community, no guarantees are made that performance regressions will not be introduced.
If your team is not consuming every bit of Angular news coming out regularly, you may miss these nuances and roll out code into production that negatively impacts your business, potentially impacting revenue. For example, some users have noticed performance regressions in Angular 16, and the Angular team knew about this and fixed it in Angular 17, but this posture puts businesses who’ve taken up the new version at risk.
The ambitious Angular Elements feature best exemplifies another aspect of this. Circa Angular 9, a big deal was made when announcing web component support for Angular. The promise was that you could create universally reusable components using your favorite framework. The team highlighted the great challenge of shipping a pared-down version of Angular along with the component – reducing the framework size from 150 KB to only a few KB. Instead of focusing on finalizing this feature, and despite making great incremental process, the team has found the task too daunting. So the team has moved on to different ideas to tackle this problem. But even those new ideas are being rushed and rolled out in a preview state, e.g., Angular signals adding to the pile of unfinished work in production software. In Angular 17, signals are partially out of preview and have the potential to transform how Angular apps are built in the future with the implementation of signal-based components. Signals do not easily leak memory compared to RxJS’s leaky subscription concept. Signals can also work with async/await calls, avoiding many unnatural uses of reactive coding with RxJS. The stable delivery of all these features is probably due in Angular 19.
Find out up-to-date information about upcoming and in-preview features at https://angular.dev/roadmap.
A large Angular application suffers from crippling performance issues just like Angular.js did, except the goalposts around the definition of large have moved significantly. The major trouble here is that it’s impossible to resolve these performance issues, at least not without significant engineering investment that leaves you digging under the hood of the Angular rendering engine.
Further, in 2023, by leveraging ES2022 features, it is possible to build reactive and interactive web applications using pure JavaScript. Angular signals expose these ES2022 features to enable fine-grained reactivity by replacing Zone.js with native JavaScript. This means that only the parts of the DOM that need to get updated are updated, significantly reducing render times. This is a topic I further explore in Chapter 3, Architecting an Enterprise App. Combining these changes results in a more optimized change detection cycle, resulting in smoother FPS.
Every release of Angular seeks to improve Time-to-Interactive (TTI) for modern browsers. In the past, this meant improving bundle sizes, introducing lazy loading of modules, and now individual components. Angular now supports Server-side Rendering (SSR) with non-destructive hydration. This means that a server can compute the DOM of a view and transfer it to the client, and the client can update the DOM displayed to the user without completely replacing it.
Angular is also moving away from Jasmine to Jest. Jasmine has always been a great unit-testing framework. However, making it work in a web application context always requires a lot of configuration and additional tools like Karma to execute the tests and get coverage reports. Jest includes all these features. The support is currently experimental, and it’s unclear whether Vitest will be a better option than Jest. Angular is moving away from webpack to esbuild, which is about 40x faster than webpack. Once again, it is only available as a (developer) preview.
As you can see, some of the most exciting things happening in Angular are in preview features. The ground truth is that teams are heads down, working on delivering features for their projects and trying their best to keep up with all the latest changes. It’s tough enough to keep updating dependencies continually; big changes in the mental model of the framework, combined with performance issues, risk losing the confidence of developers and businesses alike. Trust is hard to build and easy to lose.
The reality is the Angular team is doing great work, and the framework is making the necessary changes to evolve and meet ever-growing expectations. It bears repeating Google mandates that the 2,000+ Angular projects they have must all be on the same version of Angular. This means that every new update to Angular is well-tested, and there are no backward compatibility surprises.
Angular remains an exciting, agile, and capable framework. My motivation is to inform you of where the land mines are. I hope you are as excited as I am about the state of modern web development and the future possibilities it unlocks. Buckle up your seatbelt, Dorothy, ‘cause Kansas is going bye-bye.
Summary
In summary, web technologies have evolved to a point where it is possible to create rich, fast, and native web applications that can run well on the vast majority of desktop and mobile browsers deployed today. Angular has become a mature and stable platform, applying lessons learned from the past. It enables sophisticated development methodologies that enable developers to create maintainable, interactive, and fast applications using technologies like TypeScript, RxJS, and NgRx-enabled patterns from object-oriented programming, reactive programming, the Flux pattern, and standalone components, along with the NgRx component store.
Angular is meant to be consumed in an evergreen manner, so it is a great idea always to keep your Angular up to date. Visit https://AngularForEnterprise.com for the latest updates and news.
Angular is engineered to be reactive through and through; therefore, you must adjust your programming style to fit this pattern. With signals, Angular even gains fine-grained reactivity. However, presentation layer reactivity is not the same as reactive programming. When signal-based components arrive circa Angular 19, Angular will no longer require reactive programming to achieve a reactive presentation layer. In Chapter 9, Recipes – Master/Detail, Data Tables, and NgRx, I provide an example of a nearly observable and subscription-free application using signals and NgRx SignalStore to show what’s possible with Angular 17. Until then, the official documentation should be your bible, found at https://angular.dev.
In the next chapter, we will review the LocalCast Weather app as a standalone app; you will learn about capturing user input with reactive forms, keeping components decoupled, enabling data exchange between them using BehaviorSubject and how the NgRx component store and Angular signals differ from these concepts. In the following chapters, you will learn about advanced architectural patterns to create scalable applications and how your Angular frontend works within the context of a full-stack TypeScript application using minimal MEAN. The book wraps up by introducing you to DevOps and continuous integration techniques to publish your apps.
Further reading
- Design Patterns: Elements of Reusable Object-Oriented Software, Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, 1994, Addison Wesley, ISBN 0-201-63361-2.
- Human JavaScript, Henrik Joreteg, 2013, http://read.humanjavascript.com.
- What’s new in TypeScript x MS Build 2017, Anders Hejlsberg, 2017, https://www.youtube.com/watch?v=0sMZJ02rs2c.
- The Pragmatic Programmer, 20th Anniversary Edition, David Thomas and Andrew Hunt, 2019, Addison Wesley, ISBN 978-0135957059.
- Thinking Reactively: Most Difficult, Mike Pearson, 2019, https://www.youtube.com/watch?v=-4cwkHNguXE.
- Data Composition with RxJS, Deborah Kurata, 2019, https://www.youtube.com/watch?v=Z76QlSpYcck.
- Flux Pattern In-Depth Overview, Facebook, 2019, https://facebook.github.io/flux/docs/in-depth-overview.
- Developer experience: What is it and why should you care?, GitHub, 2023, https://github.blog/2023-06-08-developer-experience-what-is-it-and-why-should-you-care.
- Standalone Components, Google, 2023, https://angular.dev/reference/migrations/standalone.
- Built-in control flow, Google, 2023, https://angular.dev/guide/templates/control-flow.
Questions
Answer the following questions as best as possible to ensure you’ve understood the key concepts from this chapter without googling anything. Do you know if you got all the answers right? Visit https://angularforenterprise.com/self-assessment for more:
- What is the difference between a standalone and an NgModule project?
- What is the concept behind Angular Evergreen?
- Using the double-click example for reactive streams, implement the following steps using RxJS: listen to click events from an HTML target with the
fromEventfunction. Determine whether the mouse was double-clicked within a 250 ms timeframe using thethrottleTime,asyncScheduler,buffer, andfilteroperators. If a double-click is detected, display an alert in the browser. Hint: use https://stackblitz.com or implement your code and use https://rxjs.dev/ for help. - What is NgRx, and what role does it play in an Angular application?
- What is the difference between a module, a component, and a service in Angular?
Join our community on Discord
Join our community’s Discord space for discussions with the authors and other readers:
https://packt.link/AngularEnterpise3e


