


















Dr. Richard Hipp, the architect and primary author of SQLite, explains how it all began in his interview with The Guardian published in June 2007:
"I started on May 29 2000. It's just over seven years old," he says. He was working on a project which used a database server, but from time to time the database went offline. "Then my program would give an error message saying that the database isn't working, and I got the blame for this. So I said, this is not a demanding application for the database, why don't I just talk directly to the disk, and build an SQL database engine that way? That was how it started."
Before we begin our journey exploring SQLite in the context of Android, we would like to inform you of some prerequisites. The following are very basic requirements and will require little effort from you:
You need to ensure that the environment for building Android applications is in place. When we say "environment," we refer to the combination of JDK and Eclipse, our IDE choice, ADT plugins, and Android SDK tools. In case these are not in place, the ADT bundle, which consists of IDE, ADT plugins, Android SDK tools, and platform tools, can be downloaded from http://developer.android.com/sdk/index.html. The steps mentioned in the link are pretty self-explanatory. For JDK, you can visit Oracle's website to download the latest version and set it up at http://www.oracle.com/technetwork/java/javase/downloads/index.html.
You need to have a basic knowledge of Android components and have run more than "Hello World" programs on an Android emulator. If not, a very apt guide is present on the Android developer site to set up an emulator. We would suggest you become familiar with basic Android components: Intent, Service, Content Providers, and Broadcast Receiver. The Android developer site has good repositories of samples along with documentation. Some of these are as follows:
With these things in place, we can now start our foray into SQLite.
In this chapter, we will cover the following:
Why SQLite?
The SQLite architecture
A quick review of database fundamentals
SQLite in Android
SQLite is an embedded SQL database engine. It is used by prominent names such as Adobe in Adobe Integrated Runtime (AIR); Airbus, in their flight software; Python ships with SQLite; PHP; and many more. In the mobile domain, SQLite is a very popular choice across various platforms because of its lightweight nature. Apple uses it in the iPhone and Google in the Android operating system.
It is used as an application file format, a database for electronic gadgets, a database for websites, and as an enterprise RDBMS. What makes SQLite such an interesting choice for these and many other companies? Let's take a closer look at the features of SQLite that make it so popular:
Zero-configuration: SQLite is designed in such a manner that it requires no configuration file. It requires no installation steps or initial setup; it has no server process running and no recovery steps to take even if it crashes. There is no server and it is directly embedded in our application. Furthermore, no administrator is required to create or maintain a DB instance, or set permissions for users. In short, this is a true DBA-less database.
No-copyright: SQLite, instead of a license, comes with a blessing. The source code of SQLite is in the public domain; you are free to modify, distribute, and even sell the code. Even the contributors are asked to sign an affidavit to protect from any copyrights warfare that may occur in future.
Cross-platform: Database files from one system can be moved to a system running a different architecture without any hassle. This is possible because the database file format is binary and all the machines use the same format. In the following chapters, we will be pulling out a database from an Android emulator to Windows.
Compact: An SQLite database is a single ordinary disk file; it comes without a server and is designed to be lightweight and simple. These attributes lead to a very lightweight database engine. SQLite Version 3.7.8 has a footprint of less than 350 KiB (kibibyte) compared to its other SQL database engines, which are much larger.
Fool proof: The code base is well commented, easy to understand, and modular. The test cases and test scripts in SQLite have approximately 1084 times more code than the source code of SQLite library and they claim 100 percent branch test coverage. This level of testing reaffirms the faith instilled in SQLite by developers.
Note
Interested readers can read more about branch test coverage from Wikipedia at http://en.wikipedia.org/wiki/Code_coverage.
The core, SQL compiler, backend, and database form the SQLite architecture:

At the top of the SQLite library stack, according to documentation, much of the public interface to the SQLite library is implemented by the wen.c, legacy.c, and vdbeapi.c source files. This is the point of communication for other programs and scripts.
Tokenizer breaks the SQL string passed from the interface into tokens and hands the tokens over to the parser, one by one. Tokenizer is hand-coded in C. The parser for SQLite is generated by the Lemon parser generator. It is faster than YACC and Bison and, at the same time, is thread safe and prevents memory leaks. The parser builds a parse tree from the tokens passed by the tokenizer and passes the tree to the code generator. The generator produces virtual machine code from the input and passes it to the virtual machine as executables. More information about the Lemon parser generator can be found at http://en.wikipedia.org/wiki/Lemon_Parser_Generator.
The virtual machine, also known as Virtual Database Engine (VDBE), is the heart of SQLite. It is responsible for fetching and changing values in the database. It executes the program generated by the code generator to manipulate database files. Each SQL statement is first converted into virtual machine language for VDBE. Each instruction of VDBE contains an opcode and up to three additional operands.
B-trees, along with Pager and the OS Interface, form the backend of the SQLite architecture. B-trees are used to organize the data. The pager on the other hand assists B-tree by caching, modifying, and rolling back data. B-tree, when required, requests particular pages from the cache; this request is processed by the pager in an efficient and reliable manner. The OS Interface, as the name suggests, provides an abstraction layer to port to different operating systems. It hides the unnecessary details of communicating with different operating systems from SQLite calls and handles them on behalf of SQLite.
These are the internals of SQLite and an application developer in Android need not worry about the internals of Android because the SQLite Android libraries have effectively used the concept of abstraction and all the complexities are hidden. One just needs to master the APIs provided, and that will cater to all the possible use cases of SQLite in an Android application.
A database, in simple words, is an organized way to store data in a continual fashion. Data is saved in tables. A table consists of columns with different datatypes. Every row in a table corresponds to a data record. You may think of a table as an Excel spreadsheet. From the perspective of object-oriented programming, every table in a database usually describes an object (represented by a class). Each table column illustrates a class attribute. Every record in a table represents a particular instance of that object.
Let's look at a quick example. Let's assume you have a Shop database with a table called Inventory. This table might be used to store the information about all the products in the shops. The Inventory table might contain these columns: Product name (string), Product Id (number), Cost (number), In stock (0/1), and Numbers available (number). You could then add a record to the database for a product named Shoe:
|
ID |
Product name |
Product Id |
Cost |
In stock |
Numbers available |
|---|---|---|---|---|---|
|
1 |
Carpet |
340023 |
2310 |
1 |
4 |
|
2 |
Shoe |
231257 |
235 |
1 |
2 |
Data in the database is supposed to be checked and influenced. The data within a table can be as follows:
You may search for particular data within a database by utilizing what is known as a query. A query (using the SELECT command) can involve one table, or a number of tables. To generate a query, you must determine the tables, data columns, and values of the data of interest using SQL commands. Each SQL command is concluded with a semicolon (;).
An SQLite statement is written in SQL, which is issued to a database to retrieve data or to create, insert, update, or delete data in the database.
All SQLite statements start with any of the keywords: SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, and so on, and all the statements end with a semicolon (;). For instance:
CREATE TABLE table_name (column_name INTEGER);
The CREATE TABLE command is used to create a new table in an SQLite database. A CREATE TABLE command describes the following attributes of the new table that is being created:
The database in which the new table is created. Tables may be generated in the main database, the temp database, or in any database attached.
The name of each column in the table.
The declared type of each column in the table.
A default value or expression for each column in the table.
A default relation sequence to be used with each column.
Preferably, a
PRIMARY KEYfor the table. This will support both single-column and composite (multiple-column) primary keys.A set of SQL constraints for each table. Constraints such as
UNIQUE,NOT NULL,CHECK, andFOREIGN KEYare supported.In some cases, the table will be a
WITHOUT ROWIDtable.
The following is a simple SQLite statement to create a table:
String databaseTable = "CREATE TABLE "
+ TABLE_CONTACTS +"("
+ KEY_ID
+ " INTEGER PRIMARY KEY,"
+ KEY_NAME + " TEXT,"
+ KEY_NUMBER + " INTEGER"
+ ")";Here, CREATE TABLE is the command to create a table with the name TABLE_CONTACTS. KEY_ID, KEY_NAME and KEY_NUMBER are the column IDs. SQLite requires a unique ID to be provided for each column. INTEGER and TEXT are the datatypes associated with the corresponding columns. SQLite requires the type of data to be stored in a column to be defined at the time of creation of the table. PRIMARY KEY is the data column constraint (rules enforced on data columns in the table).
SQLite supports more attributes that can be used for creating a table, for instance, let us create a create table statement that inputs a default value for empty columns. Notice that for KEY_NAME, we are providing a default value as xyz and for the KEY_NUMBER column, we are providing a default value of 100:
String databaseTable =
"CREATE TABLE "
+ TABLE_CONTACTS + "("
+ KEY_ID + " INTEGER PRIMARY KEY,"
+ KEY_NAME + " TEXT DEFAULT xyz,"
+ KEY_NUMBER + " INTEGER DEFAULT 100" + ")";Here, when a row is inserted in the database, these columns will be preinitialized with the default values as defined in the CREATE SQL statement.
There are more keywords, but we don't want you to get bored with a huge list. We will be covering other keywords in the subsequent chapters.
SQLite follows a unique set of rules and guidelines called syntax.
An important point to be noted is that SQLite is case-insensitive, but there are some commands that are case-sensitive, for example, GLOB and glob have different meaning in SQLite. Let us look at the SQLite DELETE statement's syntax for instance. Although we have used capital letters, replacing them with lowercase letters will also work fine:
DELETE FROM table WHERE {condition};SQLite uses a dynamic and weakly typed SQL syntax, whereas most of the SQL databases use static, rigid typing. If we look at other languages, Java is a statically typed language and Python is a dynamically typed language. So what do we mean when we say dynamic or static? Let us look at an example:
a=5 a="android"
In statically typed languages, this will throw an exception, whereas in a dynamically typed language it will work. In SQLite, the datatype of a value is not associated with its container, but with the value itself. This is not a cause of concern when dealing with statically typed systems, where a value is determined by a container. This is because SQLite is backwards compatible with the more common static type systems. Hence, the SQL statements that we use for static systems can be used seamlessly here.
In SQLite, we have storage classes that are more general than datatypes. Internally, SQLite stores data in five storage classes that can also be referred to as primitive datatypes:
INTEGER: This supports a range of signed integers from 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. SQLite handles this automatically based on the value. At the time of processing in the memory, they are converted to the most general 8-byte signed integer form.REAL: This is a floating point value, and SQLite uses this as an 8-byte IEEE floating point number to store such values.TEXT: SQLite supports various character encodings, such as UTF-8, UTF-16BE, or UTF-16LE. This value is a text string.BLOB: This type stores a large array of binary data, exactly how it was provided as input.
SQLite itself does not validate if the types written to the columns are actually of the defined type, for example, you can write an integer into a string column and vice versa. We can even have a single column with different storage classes:
id col_t ------ ------ 1 23 2 NULL 3 test
SQLite does not have a separate storage class for Boolean and uses the Integer class for this purpose. Integer 0 represents the false state whereas 1 represents a true state. This means that there is an indirect support for Boolean and we can create Boolean type columns only. The catch is, it won't contain the familiar TRUE/FALSE values.
As we saw for the Boolean datatype, there is no storage class for the Date and Time datatypes in SQLite. SQLite has five built-in date and time functions to help us with it; we can use date and time as integer, text, or real values. Moreover, the values are interchangeable, depending on the need of the application. For example, to compute the current date, use the following code:
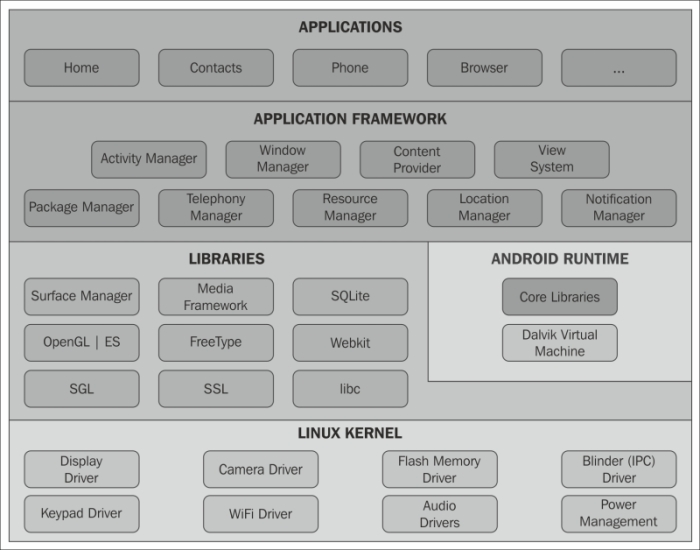
SELECT date('now');The Android software stack consists of core Linux kernel, Android runtime, Android libraries that support the Android framework, and finally Android applications that run on top of everything. The Android runtime uses Dalvik virtual machine (DVM) to execute the dex code. In newer versions of Android, that is, from KitKat (4.4), Android has enabled an experimental feature known as ART, which will eventually replace DVM. It is based on Ahead of Time (AOT), whereas DVM is based on Just in Time (JIT). In the following diagram, we can see that SQLite provides native database support and is part of the libraries that support the application framework along with libraries such as SSL, OpenGL ES, WebKit, and so on. These libraries, written in C/C++, run over the Linux kernel and, along with the Android runtime, forms the backbone of the application framework, as shown in the following diagram:
Before we start exploring SQLite in Android, let's take a look at the other persistent storage alternatives in Android:
Shared preference: Data is stored in a shared preference in the key-value form. The file itself is an XML file containing the key-value pairs. The file is present in the internal storage of an application, and access to it can be public or private as needed. Android provides APIs to write and read shared preferences. It is advised to use this in case we have to save a small collection of such data. A general example would be saving the last read position in a PDF, or saving a user's preference to show a rating box.
Internal/external storage: This terminology can be a little misleading; Android defines two storage spaces to save files. On some devices, you might have an external storage device in form of an SD card, whereas on others, you will find that the system has partitioned its memory into two parts, to be labeled as internal and external. Paths to the external as well as internal storage can be fetched by using Android APIs. Internal storage, by default, is limited and accessible only to the application, whereas the external storage may or may not be available in case it is mounted.
Since API level 1, Android ships with SQLite. At the time of writing this book, the current version of SQLite was 3.8.4.1. According to the documentation, the version of SQLite is 3.4.0, but different Android versions are known to ship with different versions of SQLite. We can easily verify this via the use of a tool called SQLite3 present in the platform-tools folder inside the Android SDK installation folder and Android Emulator:
adb shell SQLite3 --version SQLite 3.7.11: API 16 - 19 SQLite 3.7.4: API 11 - 15 SQLite 3.6.22: API 8 - 10 SQLite 3.5.9: API 3 - 7
We need not worry about the different versions of SQLite and should stick to 3.5.9 for compatibility, or we can go by the saying that API 14 is the new minSdkVersion and switch it with 3.7.4. Until and unless you have something very specific to a particular version, it will hardly matter.
The
android.database package contains all the necessary classes for working with databases. The
android.database.SQLite package contains the SQLite-specific classes.
Android provides various APIs to enable us to create, access, modify, and delete a database. The complete list can be quite overwhelming; for the sake of brevity, we will cover the most important and used ones.
The SQLiteOpenHelper class is the first and most essential class of Android to work with SQLite databases; it is present in the android.database.SQLite namespace. SQLiteOpenHelper is a helper class that is designed for extension and to implement the tasks and actions you deem important when creating, opening, and using a database. This helper class is provided by the Android framework to work with the SQLite database and helps in managing the database creation and version management. The modus operandi would be to extend the class and implement tasks and actions as required by our application. SQLiteOpenHelper has constructors defined as follows:
SQLiteOpenHelper(Context context, String name, SQLiteDatabase.CursorFactory factory, int version) SQLiteOpenHelper(Context context, String name, SQLiteDatabase.CursorFactory factory, int version, DatabaseErrorHandler errorHandler)
The application context permits access to all the shared resources and assets for the application. The name parameter consists of the database filename in the Android storage. SQLiteDatabase.CursorFactory is a factory class that creates cursor objects that act as the output set for all the queries you apply against SQLite under Android. The application-specific version number for the database will be the version parameter (or more particularly, its schema).
The constructor of SQLiteOpenHelper is used to create a helper object to create, open, or manage a database. The
context is the application context that allows access to all the shared resources and assets. The name parameter either contains the name of a database or null for an in-memory database. The SQLiteDatabase.CursorFactory factory creates a cursor object that acts as the result set for all the queries. The version parameter defines the version number of the database and is used to upgrade/downgrade the database. The errorHandler parameter in the second constructor is used when SQLite reports database corruption.
SQLiteOpenHelper will trigger its onUpgrade() method if our database version number is not at default 1. Important methods of the SQLiteOpenHelper class are as follows:
synchronized void close()synchronized SQLiteDatabase getReadableDatabase()synchronized SQLiteDatabase getWritableDatabase()abstract void onCreate(SQLiteDatabase db)void onOpen(SQLiteDatabase db)abstract void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion)
The synchronized close() method closes any open database object. The synchronized keyword prevents thread and memory consistency errors.
The next two methods, getReadableDatabase() and getWriteableDatabase(), are the methods in which the database is actually created or opened. Both return the same SQLiteDatabase object; the difference lies in the fact that getReadableDatabase() will return a readable database in case it cannot return a writable database, whereas getWriteableDatabase() returns a writable database object. The getWriteableDatabase() method will throw an SQLiteException if a database cannot be opened for writing. In case of getReadableDatabase(), if a database cannot be opened, it will throw the same exception.
We can use the isReadOnly() method of the SQLiteDatabase class on the database object to know the state of the database. It returns true for read-only databases.
Calling either methods will invoke the onCreate() method if the database doesn't exist yet. Otherwise, it will invoke the onOpen() or onUpgrade() methods, depending on the version number. The
onOpen() method should check the isReadOnly() method before updating the database. Once opened, the database is cached to improve performance. Finally, we need to call the close() method to close the database object.
The onCreate(), onOpen(), and onUpgrade() methods are designed for the subclass to implement the intended behavior. The onCreate() method is called when the database is created for the first time. This is the place where we create our tables by using SQLite statements, which we saw earlier in the example. The onOpen() method is triggered when the database has been configured and after the database schema has been created, upgraded, or downgraded as necessary. Read/write status should be checked here with the help of the isReadOnly() method.
The onUpgrade() method is called when the database needs to be upgraded depending on the version number supplied to it. By default, the database version is 1, and as we increment the database version numbers and release new versions, the upgrade will be performed.
A simple example illustrating the use of the SQLiteOpenHelper class is present in the code bundle for this chapter; we would be using it for explanation:
class SQLiteHelperClass
{
...
...
public static final int VERSION_NUMBER = 1;
sqlHelper =
new SQLiteOpenHelper(context, "ContactDatabase", null,
VERSION_NUMBER)
{
@Override
public void onUpgrade(SQLiteDatabase db,
int oldVersion, int newVersion)
{
//drop table on upgrade
db.execSQL("DROP TABLE IF EXISTS "
+ TABLE_CONTACTS);
// Create tables again
onCreate(db);
}
@Override
public void onCreate(SQLiteDatabase db)
{
// creating table during onCreate
String createContactsTable =
"CREATE TABLE "
+ TABLE_CONTACTS + "("
+ KEY_ID + " INTEGER PRIMARY KEY,"
+ KEY_NAME + " TEXT,"
+ KEY_NUMBER + " INTEGER" + ")";
try {
db.execSQL(createContactsTable);
} catch(SQLException e) {
e.printStackTrace();
}
}
@Override
public synchronized void close()
{
super.close();
Log.d("TAG", "Database closed");
}
@Override
public void onOpen(SQLiteDatabase db)
{
super.onOpen(db);
Log.d("TAG", "Database opened");
}
};
...
...
//open the database in read-only mode
SQLiteDatabase db = SQLiteOpenHelper.getWritableDatabase();
...
...
//open the database in read/write mode
SQLiteDatabase db = SQLiteOpenHelper.getWritableDatabase();Note
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Now that you are familiar with the helper class that kick-starts the use of SQLite databases within Android, it's time to look at the core SQLiteDatabase class. SQLiteDatabase is the base class required to work with an SQLite database in Android and provides methods to open, query, update, and close the database.
More than 50 methods are available for the SQLiteDatabase class, each with its own nuances and use cases. Rather than an exhaustive list, we'll cover the most important subsets of methods and allow you to explore some of the overloaded methods at your leisure. At any time, you can refer to the full online Android documentation for the SQLiteDatabase class at http://developer.android.com/reference/android/database/sqlite/SQLiteDatabase.html.
Some methods of the SQLiteDatabase class are shown in the following list:
public long insert (String table, String nullColumnHack, ContentValues values)public Cursor query (String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy)public Cursor rawQuery(String sql, String[] selectionArgs)public int delete (String table, String whereClause, String[] whereArgs)public int update (String table, ContentValues values, String whereClause, String[] whereArgs)
Let us see these SQLiteDatabase classes in action with an example. We will insert a name and number in our table. Then we will use the raw query to fetch data back from the table. After this, we will go through the delete() and update() methods, both of which will take id as a parameter to identify which row of data in our database table we intend to delete or update:
public void insertToSimpleDataBase()
{
SQLiteDatabase db = sqlHelper.getWritableDatabase();
ContentValues cv = new ContentValues();
cv.put(KEY_NAME, "John");
cv.put(KEY_NUMBER, "0000000000");
// Inserting values in different columns of the table using
// Content Values
db.insert(TABLE_CONTACTS, null, cv);
cv = new ContentValues();
cv.put(KEY_NAME, "Tom");
cv.put(KEY_NUMBER, "5555555");
// Inserting values in different columns of the table using
// Content Values
db.insert(TABLE_CONTACTS, null, cv);
}
...
...
public void getDataFromDatabase()
{
int count;
db = sqlHelper.getReadableDatabase();
// Use of normal query to fetch data
Cursor cr = db. query(TABLE_CONTACTS, null, null,
null, null, null, null);
if(cr != null) {
count = cr.getCount();
Log.d("DATABASE", "count is : " + count);
}
// Use of raw query to fetch data
cr = db.rawQuery("select * from " + TABLE_CONTACTS, null);
if(cr != null) {
count = cr.getCount();
Log.d("DATABASE", "count is : " + count);
}
}
...
...
public void delete(String name)
{
String whereClause = KEY_NAME + "=?";
String[] whereArgs = new String[]{name};
db = sqlHelper.getWritableDatabase();
int rowsDeleted = db.delete(TABLE_CONTACTS, whereClause, whereArgs);
}
...
...
public void update(String name)
{
String whereClause = KEY_NAME + "=?";
String[] whereArgs = new String[]{name};
ContentValues cv = new ContentValues();
cv.put(KEY_NAME, "Betty");
cv.put(KEY_NUMBER, "999000");
db = sqlHelper.getWritableDatabase();
int rowsUpdated = db.update(TABLE_CONTACTS, cv, whereClause, whereArgs);
}
ContentValues is essentially a set of key-value pairs, where the key represents the column for the table and the value is the value to be inserted in that column. So, in the case of values.put("COL_1", 1);, the column is COL_1 and the value being inserted for that column is 1.
The following is an example:
ContentValues cv = new ContentValues(); cv.put(COL_NAME, "john doe"); cv.put(COL_NUMBER, "12345000"); dataBase.insert(TABLE_CONTACTS, null, cv);
A query recovers a Cursor object. A Cursor object depicts the result of a query and fundamentally points to one row of the result of the query. With this method, Android can buffer the results of the query in a productive manner; as it doesn't need to load all of the data into memory.
To obtain the elements of the resulting query, you can use the getCount() method.
To navigate amid individual data rows, you can utilize the moveToFirst() and moveToNext() methods. The isAfterLast() method permits you to analyze whether the end of the output has arrived.
The Cursor object provides typed get*() methods, for example, the getLong(columnIndex) and getString(columnIndex) methods to gain entry to the column data for the ongoing position of the result. columnIndex is the number of the column you will be accessing.
The Cursor object also provides the getColumnIndexOrThrow(String) method that permits you to get the column index for a column name of the table.
To close the Cursor object, the close() method call will be used.
A database query returns a cursor. This interface provides random read-write access to the result set. It points to a row of the query result that enables Android to buffer the results effectively since now it is not required to load all the data in the memory.
The pointer of the returned cursor points to the 0th location, which is known as the first location of the cursor. We need to call the moveToFirst() method on the Cursor object; it takes the cursor pointer to the first location. Now we can access the data present in the first record.
Cursor implementations, if from multiple threads, should perform their own synchronization when using the cursor. A cursor needs to be closed to free the resource the object holds by calling the close() method.
Some other support methods we will encounter are as follows:
The
getCount()method: This returns the numbers of elements in the resulting query.The
get*()methods: These are used to access the column data for the current position of the result, for example,getLong(columnIndex)andgetString(columnIndex).The
moveToNext()method: This moves the cursor to the next row. If the cursor is already past the last entry in the result set, it will returnfalse.
We covered in this chapter the know-how of SQLite features and its internal architecture. We started with a discussion on what makes SQLite so popular by looking at its salient features, then we covered the underlying architecture of SQLite and went over database fundamentals such as syntax and datatypes, and finally moved on to SQLite in Android. We explored the Android APIs for using SQLite in Android.
In the next chapter, we will focus on carrying forward what we have learned in this chapter and apply it to build Android applications. We will focus on the UI elements and connecting UI to the database components.