


















 Download code from GitHub
Download code from GitHub
Understanding Sensitive Information
Before we start learning about the concept of cyber anonymity, it’s important to understand the level of sensitivity of information. In today’s world, information is power. If you look at the wealthiest companies in the world, all of them are related to information. Typically, we think illegal activities, including dealing drugs, selling weapons, and smuggling, generate lots of money and power, or “create kingdoms.” But the reality is, information has power exceeding all of these underground activities.
The world’s top wealthiest companies and individuals have gained this status by managing information. Typically, data is in the raw form of facts and statistics. This can be used for reference or analysis. Once properly analyzed, data becomes information. Information is generally processed data that gives us meaningful context that can be used for decision-making. That’s why information has become power as information is processed, structured, and organized data that enables powerful decision-making.
As an example, let’s take an advertising campaign that utilizes TV or social media advertisements. With TV broadcasting, it will broadcast to millions of people, but the target customer engagement would be a very low percentage. If social media is used, we could select the precisely interested or prospective users to advertise to. So, the impact will be very high. This is more powerful than we think. If you select the exact audience that you want the advertisement to reach, selecting attributes such as age group, gender, and geography, it will be more effective. Not only this, but nowadays, social media even has data about users’ genuine likes and dislikes. If we use social media, the advertisement will be delivered to prospective users. This is also known as direct marketing.
This chapter will cover the following main topics:
- The categorization of information
- Different forms of sensitive information
- Raw data can create sensitive information
- Privacy in cyberspace
- Cyber anonymity
The categorization of information
Information can be further classified and categorized depending on the sensitivity. As an example, in today’s world, mobile phones have also become information repositories. Everyone’s mobile phone has a large amount of information that they have stored intentionally or unintentionally. Nowadays, information can be in different forms, not just text or numbers. It can be in the form of documents, images, videos, and so on. Some information is stored by users on their mobile phones intentionally. Users of mobile phones are aware that this information is stored. But there is also another set of information stored in phones without users’ knowledge.
People often confuse personal and sensitive information. Collecting, storing, using, or disclosing sensitive information is protected under different lawsuits around the world. A famous one is GDPR, passed by the European Union in 2016 and enforced in May 2018. These legal concerns are very strict on sensitive information. The reason behind this is disclosing sensitive information can have an irreversible effect on someone’s life. Let’s look at the difference between personal information and sensitive information:
- Personal information: Personal information refers to any information about an individual or a person that makes them distinguishable or identifiable. Under the law, even if the information given is not accurate, it is still considered personal information.
Personal information includes an individual’s name, address, contact information, date of birth, email address, and bank information.
- Sensitive information: Unlike personal information, sensitive information has a direct impact on the individual if disclosed. Sensitive information is a subcategory of personal information in a broader sense. Sensitive information may have a direct impact on or harm an individual if it is not handled properly.
Sensitive information includes an individual’s criminal record, health records, biometric information, sexual orientation, or membership in a trade union. If disclosed, the result may be discrimination, harassment, or monetary loss for the person to whom the sensitive information pertains.
If you look at the aforementioned information, what we need to understand is most Personally Identifiable Information (PII) is not confidential to our close relations and friends. Also, nowadays, our close circles have expanded to the global level with social media. Most social media users overexpose their own or other people’s personal information, either intentionally or unintentionally.
Different forms of sensitive information
Most users aren’t aware that when they access a web application or a website, it can collect some of their information. They just think that they are only accessing information from the web browser, but the reality is web applications can collect a lot more information than users think. To understand this, we can simply access https://www.deviceinfo.me (as shown in Figure 1.1). This website shows you how much information is collected from your device just by accessing a website. If you access this website with your mobile phone, it will display lots of information, including your mobile phone’s type/model, operating system, browser version, IP address, hostname, number of cores, memory, interfaces, and latitude and longitude. This shows that web applications and websites can collect almost all the information about a device.
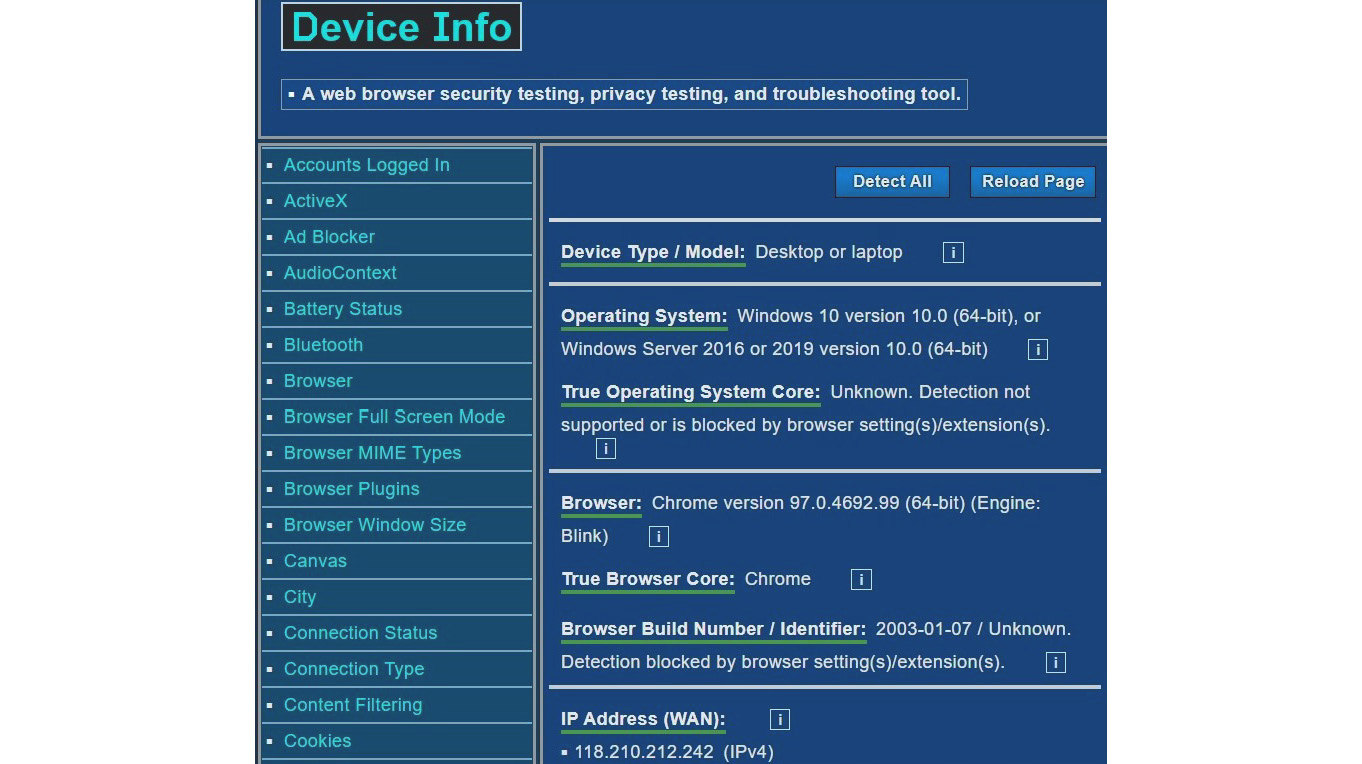
Figure 1.1 – Information derived about your device
This is a classic example of the data that a simple web application can collect, just by getting a device to access the application, without installing any agent or running a script.
When you look at the data that we have on our devices, mobile phones, or desktops, it can be sorted into a few categories. But not every case will contain PII.
Any form of information that could lead to any type of loss, such as financial, if accessed by a third party can be considered sensitive information.
Sensitive information can take different forms.
Mostly, people think that sensitive information is banking account information, including credit card numbers and social media account information. But a private picture or video clip can be even more sensitive than the preceding listed examples of sensitive information.
If you lose your credit card, the maximum damage that can occur is the credit limit of the stolen credit card is reached. But if someone accesses a private picture or video clip of yours, it can create more damage that might not be reversible.
Sometimes, we disclose sensitive information unintentionally. Let’s look at the following photo:

Figure 1.2 – Photo of a car, carrying sensitive information
This photo was taken by someone trying to sell their car. As a precaution, the seller has even masked the numberplate to reduce the information this photo discloses. Even if you inspect this photo closely, you might not find any interesting information. But although the seller has masked part of the vehicle identification number, there is still a lot of information given away with this photo without their knowledge. This information is known as metadata. Metadata can be defined as data about data.
We usually look at the content of a file, but metadata discloses even more information than we are aware of.
Let’s look at the metadata of the preceding photo. Let’s access http://metapicz.com/, upload the image, and see what we can find. This site can acquire meta information on an image. It extracts information including the camera make, model, exposure, and aperture of the device.

Figure 1.3 – Derived information from a picture
The preceding screenshot shows the make of the device that captured the photo of the car, as well as the model and exposure. Exposure refers to the amount of light that comes in while you are pressing the capture button of a camera. Aperture refers to the opening of the lens of the camera to allow light through and focal length is the distance between the lens and the image sensor. So, if someone analyzes an image, they can get a massive amount of information, even about the lighting conditions of the environment during the time of capturing this image.
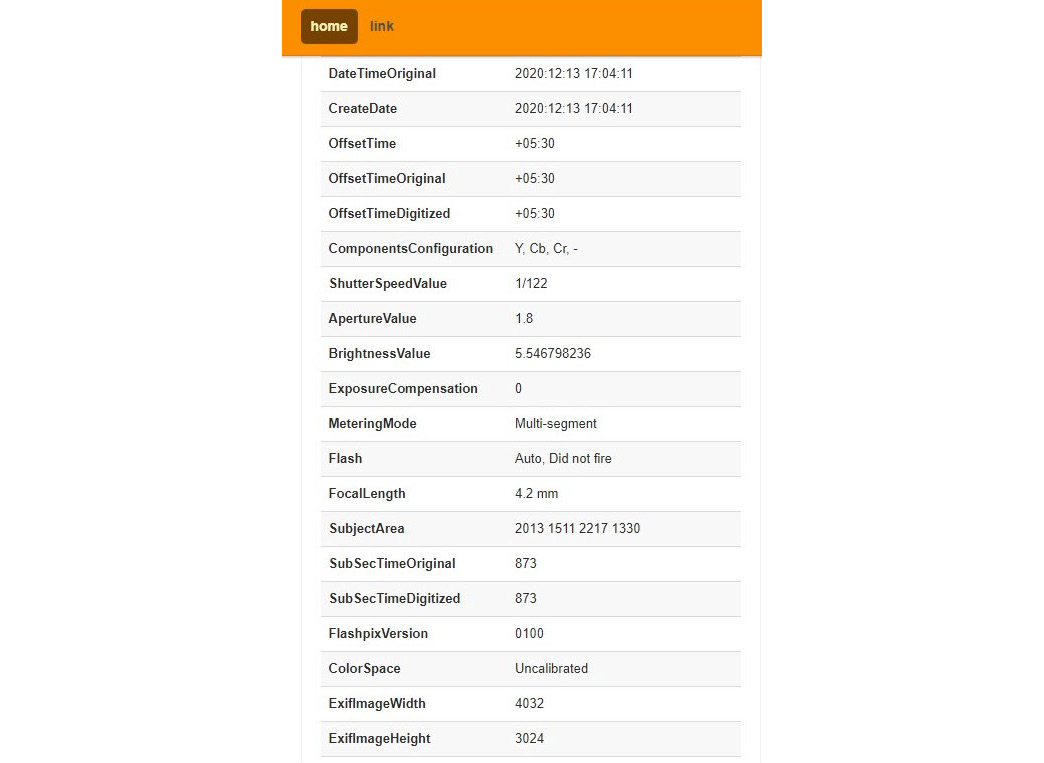
Figure 1.4 – More information from the image metadata
The preceding screenshot shows information related to the time the photo was taken, such as the created date and offset. Typically, offset refers to the time zone. According to this screenshot, the offset is +05.30, which refers to GMT +5:30, which is Asia/Colombo time, specifically, Kolkata. By analyzing this, we now know the region in which the photo was taken.
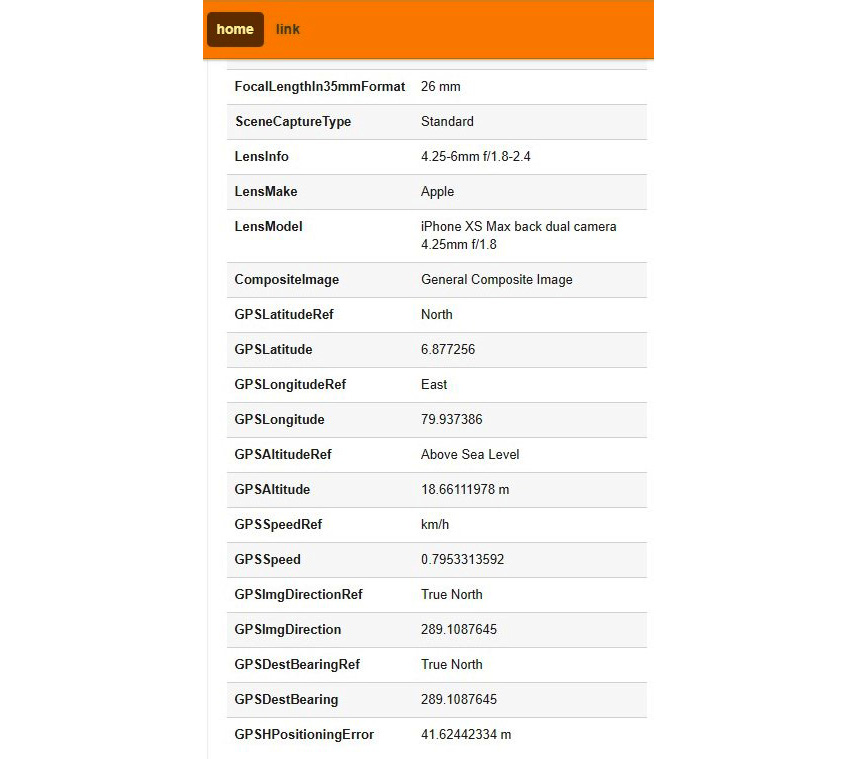
Figure 1.5 – Lens and GPS information derived from the image
Personally identifiable data or information is anything that discloses information about you, including your name, address, telephone number, or social media identity, photos with contents that identify you, and even metadata. Also, your email address or IP can be treated as PII. We should be able to control our privacy and decide when, how, and to what extent our PII is revealed.
This is also known as data privacy. There are many initiatives and acts around the globe that relate to data privacy, but data privacy can be violated at various levels. Most of the devices we use today compromise our privacy even without us being aware. We will take Android as an example. Whenever you use an Android phone, it collects a lot of information about you as we usually connect our Gmail account to get the full functionality of the Android device. Once you have connected your Gmail account to the Android device, it will start collecting your information.
If you want to see what information about you Google is collecting, access https://myactivity.google.com/ and log in using your Google account that is connected to your device. You will be amazed to see how much information Google collects, including your web and app activity, your location history, and your YouTube watch history, that is, all the videos you watch and search for on YouTube.
If you go to the location history and click the Manage Activity link, you will see how much data your device has uploaded to Google.

Figure 1.6 – Activity recorded in Google
If you select any of the dates, it will show you all your movements, including the method of commute, very accurate information about your walk, and even photos that you took taken during the journey using your device’s camera.

Figure 1.7 – Detailed information captured by Google
Even if you disable data connectivity on your Android device while traveling, the device will still collect all this information and upload it to Google whenever you connect your device to the internet later. This doesn’t just occur on the Android operating system; all devices do this – even your iPhone or Windows device.
If you want to check what information is being stored on your Windows device, press the Windows key + I to access Windows Settings | Privacy | Diagnostics & feedback | Open Diagnostic Data Viewer.
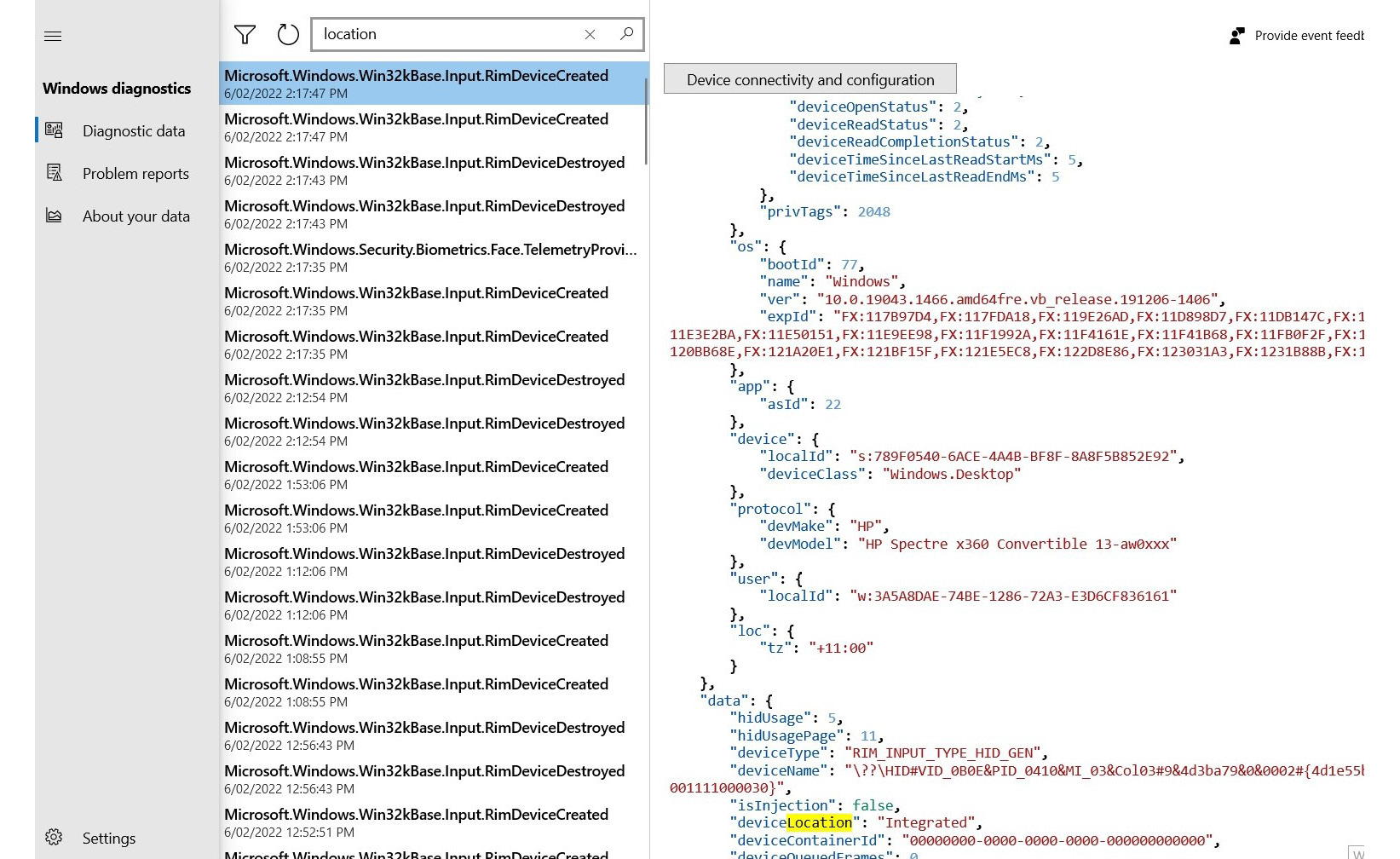
Figure 1.8 – Telemetric data shared with Microsoft by your device
This shows what your device is sharing with Microsoft. Not only operating systems but also applications collect our information. You may have noticed that many applications that you install on your device request access to your location, photos, and other sources of information, even if the app doesn’t need to use this information. As an example, if you install a flashlight app and it requests access to your location, that is suspicious.
The reality is most operating systems, applications, devices, and even manual systems collect this information. Sometimes, disclosing personal information can be dangerous. There was an incident reported in India recently related to this. A Business Process Outsourced (BPO) company that provides services to overseas companies from India was advertising a vacancy. Many people came for the interview. At the security post, there was an open register on which each candidate had to fill in information, including their name, address, telephone number, and email address. (This is common in many Asian countries.) There was a woman who attended the interview that got a call for a second interview at a different location in the evening. It was a bit suspicious, but the BPO company operates 24x7, so this wasn’t too odd of a scenario as during the first interview, they informed candidates that the job would be on a shift basis. The woman went for the second interview but never came back. Later investigations found that the call for the second interview was fake; her information was collected by someone who came to the same interview and as everyone was filling in an open registry, they were able to access all previous records. This shows how dangerous disclosing personal information can be. But still, I have seen many locations where retail stores do it especially during the 2020 pandemic, as they wanted to trace positive cases of COVID-19 and inform people who had come into contact with those infected people.
Raw data can create sensitive information
There are different ways we disseminate our data knowingly or unknowingly, including participating in different types of surveys. Sometimes, researchers who conduct surveys may not use the data for the intended purpose. Often, data collected as part of open or public surveys is used for different purposes. If a researcher is collecting data, it’s important that they disclose the purpose of the data collection, and the data collected cannot and should not be used for any other purpose than that.
The main advantage of having raw data for an attacker is that this raw data can be processed to get PII or sensitive information, which can be used for direct and indirect attacks.
In the previous section, we discussed what PII and sensitive information are. Let’s take an example. When you call a bank or service provider, typically, they ask a few questions to verify your identity. The questions they ask are really basic; as we discussed earlier, this might even be information you’ve shared with your close circle. These questions can include your full name, address, contact number, and email address. (In fact, I still remember the full names of most of my schoolmates as the first thing that is done in the morning at schools in my country is marking the register. Teachers usually read names aloud one by one, and if the student is present, they have to shout, “Present!” Because of this, I still remember most of my classmates’ full names and initials, even though we have long names in our culture!)
Why do service providers ask these sorts of questions? Because by collecting a series of information such as this, they can identify that they are communicating with the correct person. This is the principle behind claims-based authentication in federation trusts. Claims, rather than credentials, will be shared between the identity provider and service provider. Claims are typically attributes, and they are treated as raw data.
Another interesting fact is, once someone has collected raw data, they can easily find personal and sensitive information too. For these types of searches, attackers use different tools. One such tool is Social Searcher (https://www.social-searcher.com/).
If you want to find more information on someone, so long as you know their first name and last name, you also can start searching for them on social media. The Social Searcher web app is connected to multiple social media APIs and provides information related to the searched name and its respective social media accounts. There are many internet resources and tools like this that can be found in many open source distributions, including Kali, Parrot OS, Security Onion, and Predator. Later chapters will discuss different tools and techniques in detail to understand what type of integration these tools have with collecting information and how can we prevent creating sensitive information.
Privacy in cyberspace
Every country has its own jurisdiction system and laws. Typically, respective laws are applicable within the country. Even within federal governments, sometimes different states will have different laws and acts. The reason is if any incident takes place, the law enforcement bodies of respective areas or state stake the required actions.
Cyberspace works completely differently, though, as in most incidents, the perpetrator connects remotely over the internet with the target. Most of the time, the attacker is located in a different state or country than the target. The internet is an unregulated space and no one has direct ownership. Every time we access the internet, we need to remember that we are connected to an unregulated space and we need to look after our own security as the internet cannot be completely governed due to its architecture and very nature.
Whenever we are connected to cyberspace using any type of device, we are risking breaches of our privacy. In reality, we compromise our privacy in different layers. When we connect to the internet, we use different kinds of devices. It can be a mobile device, laptop, desktop, and so on. The first layer is the device that we connect to the internet as it stores lots of information. Then, we have the application that we use to access and surf the internet, typically a browser. The browser also keeps lots of information. Then, the device must be connected to the internet using some sort of media; this can be a wired or wireless connection. Whatever connection we use, there is a possibility that the network is collecting information on us. This is known as network capturing.
The next layer is the devices to which the network is connected. This includes Wi-Fi routers, switches, and firewalls that are connected to the network, and they also collect information. The network connection is then connected to the Internet Service Provider (ISP), which collects different kinds of information about the connection. If you are accessing a particular website, the host web server collects information about the connection. This information includes the timestamp, your public IP address, the type of browser being used, and the operating system.
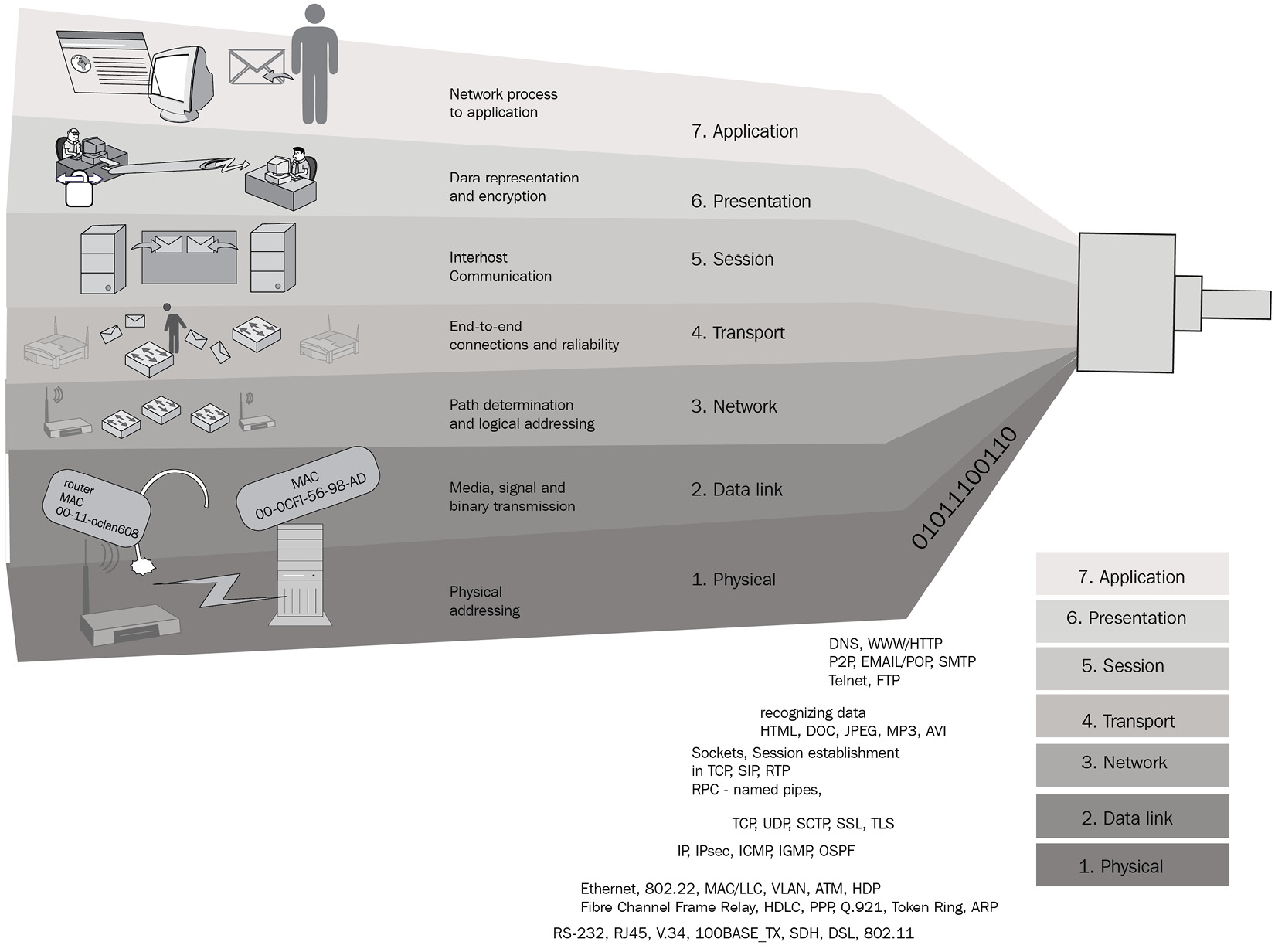
Figure 1.9 – Different layers where different types of information pass through
When you look at these layers, even if an attacker is not involved, there are multiple layers where information is being collected about your connection. As we discussed earlier, this includes personal and sensitive information about you.
This gives an understanding of the different layers between the web application and the device. Importantly, if any of the layers are compromised by attackers, it will become more crucial as then attackers have control and access to these layers. They can even intercept communications and acquire credentials if the protocols of the communication used are weak.
When you perform any activity on the internet, or within the network using an application, data goes through these layers when communicating with other entities. As an example, when you draft an email using an email client such as Microsoft Outlook, data is created in the application layer and all the other layers are responsible for different tasks:
- Layer 7 – application: This layer is where the users are directly interacting with the device using an application such as a browser.
- Layer 6 – presentation: This layer is preparing source and destination devices to communicate with each other. Encryption and decryption take place in this layer.
- Layer 5 – session: This layer helps to establish, manage, and terminate the connection between the source and destination devices. Communication channels are referred to as sessions.
- Layer 4 – transport: Transporting data from the source to the destination takes place in this layer. If the dataset is large, then data will be broken into pieces in this layer.
- Layer 3 – network: This layer is responsible for mapping the best paths for data traversal between devices and delivering messages through nodes or routers.
- Layer 2 – data link: This layer is responsible for switching connected devices.
- Layer 1 – physical: This layer represents the physical connectivity, including cables and other mediums responsible for sending data as frames.
When thinking of privacy, you need to concentrate on all the layers, including the device, application, network, communication, and web servers. For example, if you are using a shared device and save passwords on the web browser, your private information can be stolen easily, as there are many free tools out there to make life more easy.
If you access https://www.nirsoft.net/utils/web_browser_password.html, you can download web browser password viewers, which can retrieve stored passwords easily.
The same site also provides you with a range of free tools that can be used with the Graphical User Interface (GUI) or scripts (command-line tools) to automate the process.
Cyber anonymity
We have discussed how our privacy can be compromised and different levels of privacy.
Cyber anonymity is the state of being unknown. With cyber anonymity, the activities performed in cyberspace will remain, but the state will be unknown. As an example, if an attacker performs an attack anonymously, the attack will still be effective but the attacker’s identity will be unknown. Being completely anonymous is a complex process as there are multiple layers of collecting information, as explained earlier.
If we look at the same set of layers that we discussed, to be anonymous in cyberspace, we need to concentrate on each layer. The main idea here is for the attacker to eliminate all traces of themselves as if even a single amount of information is left, they can be identified. That’s how many anonymous groups have been traced, in some cases after many years of research.
There was one case related to the world-famous Silk Road, an anonymous marketplace on the dark web mostly selling drugs to over 100,000 buyers around the world. Later, the Federal Bureau of Investigation (FBI) seized the site. With the site, the United States government seized over 1 billion US dollars' worth of Bitcoin connected to Silk Road. Even though the main actors behind Silk Road were arrested, the administrators of the site started Silk Road 2, but that was also seized by the US government. However, the site was completely anonymous for a few years until the FBI traced and shut it down. According to the media, the infamous Dread Pirate Roberts, the pseudonym of Ross Ulbricht, the founder of Silk Road, was taken down because of a misconfigured server. This server was used to maintain the cyber anonymity of Silk Road, but due to a single misconfiguration, it uncovered the real IPs of some requests instead of them being anonymous. As a result, the FBI was able to track down the communication and traced the perpetrator using the IP.
This is a classic example to illustrate how even though efforts were made to remain anonymous on all layers, a small mistake revealed their whereabouts. This is why it is stated that cyber anonymity is a complicated process that involves various technologies. Also, it requires concentrating on all the layers to be completely anonymous. There are many common technologies, including Virtual Private Networks (VPNs), proxy servers, censorship circumvention tools, and chain proxies, that help with maintaining cyber anonymity, which will be discussed in upcoming chapters.
Typically, all operating systems, applications, and appliances are designed to keep different types of information in the form of logs to maintain accountability and to be able to help with troubleshooting. This information can be volatile or static. Volatile information will be available until the next reboot or shutdown of the system in memory. Forensic and memory-capturing tools can be used to dump volatile data, which can then be analyzed to find out specific information.
Static data can be found in temporary files, registries, log files, and other locations, depending on the operating system or application. Some information that is available is created by the user activity and some is created as a part of the system process.
If you need to maintain complete anonymity, this information is useful as you need to minimize or prevent the footprints created in different layers. To overcome this challenge, the most used technique is using live boot systems. Most Linux systems provide the flexibility of running a live operating system, using CDs/DVDs, live boot USB drives, or virtual systems directly connected to an ISO file. Some operating systems that have the live boot option available are as follows:
- Kali Linux live boot – penetration testing environment
- Parrot Security or Parrot OS live boot – security testing
- Gentoo – based on FreeBSD
- Predator OS
- Knoppix – based on Debian
- PCLinuxOS – based on Mandrake
- Ubuntu – based on Debian
- Kubuntu – KDE Ubuntu version
- Xubuntu – light Ubuntu version that uses an Xfce desktop environment
- Damn Small Linux – Debian (Knoppix remaster)
- Puppy Linux – Barry Kauler wrote almost everything from scratch
- Ultimate Boot CD (UBCD) – diagnostics CD
- openSUSE Live – based on the Jurix distribution
- SystemRescue CD – Linux system on a bootable CD-ROM for repairing your system and your data after a crash
- Feather Linux – Knoppix remaster (based on Debian)
- FreeBSD – derived from BSD
- Fedora – another community-driven Linux distribution
- Linux Mint – an elegant remix based on Ubuntu
- Hiren’s BootCD PE (Preinstallation Environment) – Windows 10-based live CD with a range of free tools
Once you boot from live boot systems, it reduces or prevents creating logs and temporary files on the actual operating system straight away. Once the live boot system is shut down or rebooted, volatile data and static data are created because your activities are completely removed; when you boot next time, it will be a brand-new operating system. If you require, you always have the option to permanently install most of these operating systems.
Whenever you access the internet, DNS information will be cached in the local system until you manually remove it, the Time to Live (TTL) value is reached, or you run an automated tool. When you access any website, the local DNS resolver resolves it and keeps it in the cache until the TTL value becomes 0. When configuring DNS on the domain service provider’s portal or DNS server, usually, the TTL values are added.
As an example, by using the nslookup command, we can check the TTL value.
Let’s use nslookup on microsoft.com:
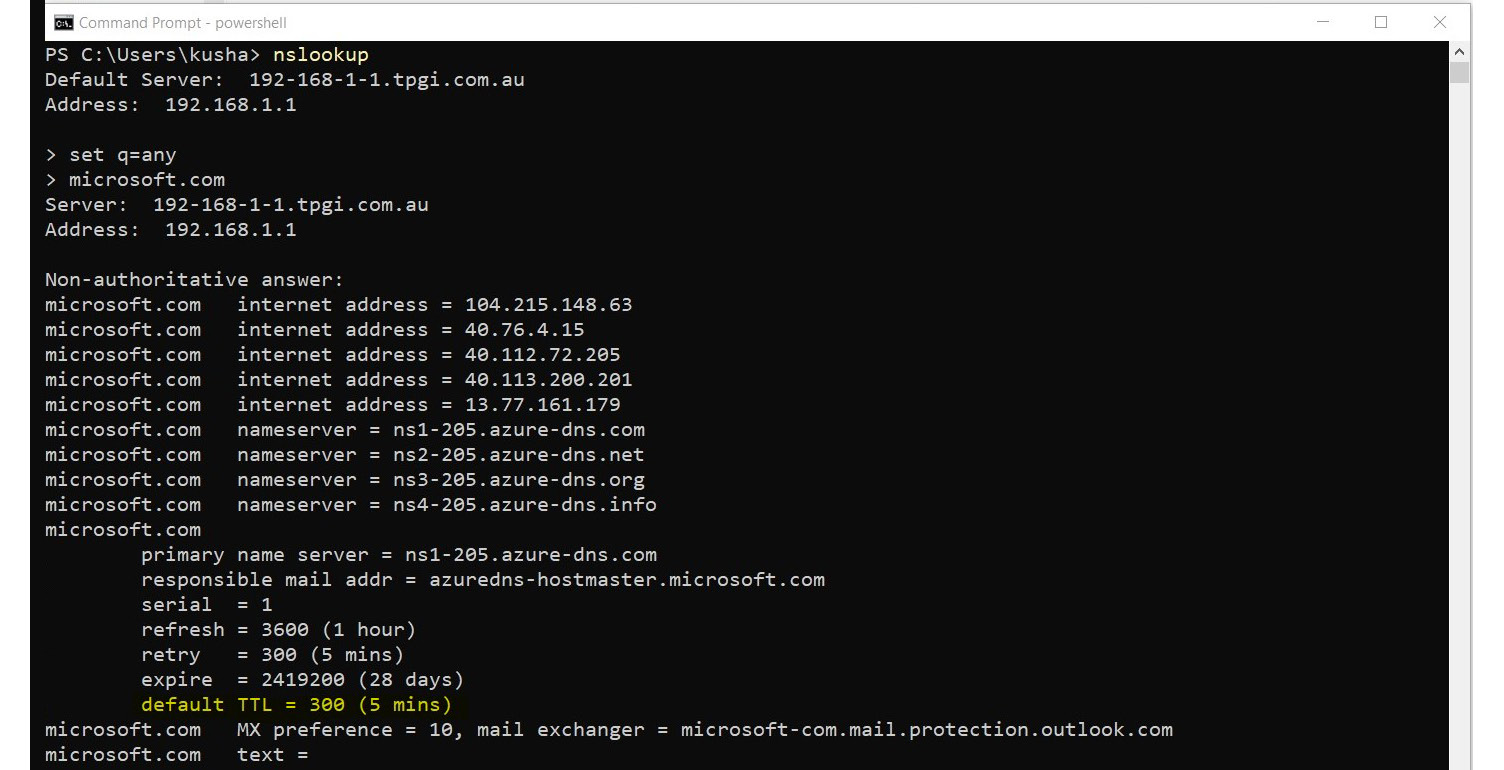
Figure 1.10 – DNS information retrieval with nslookup
This shows the TTL value of microsoft.com is 300 seconds/5 minutes.
If we access the Microsoft website, this DNS entry will be cached in the local cache.
We can check this by executing ipconfig /displaydns on Windows Command Prompt.
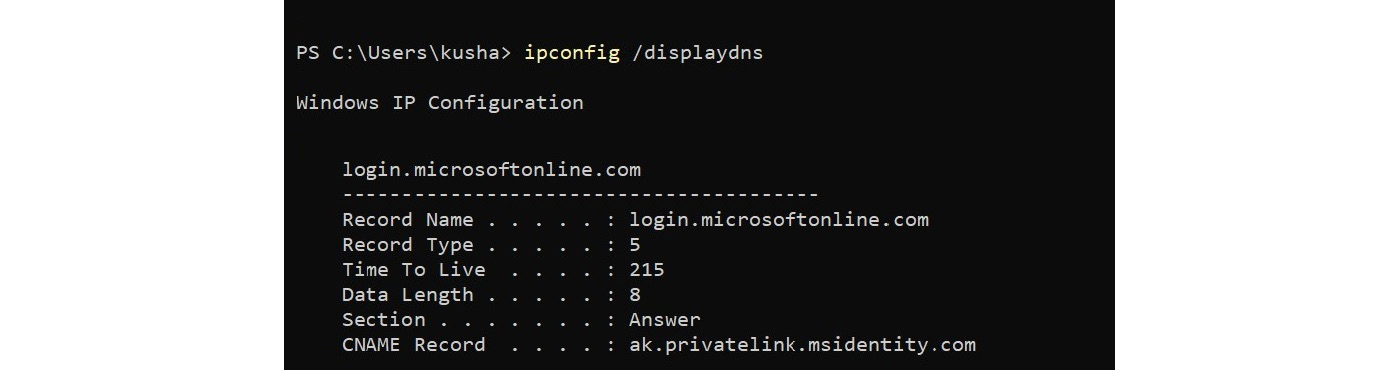
Figure 1.11 – Information retrieved by ipconfig/displaydns
If you are using PowerShell, you can use the Get-DnsClientCache cmdlet to get a similar result.
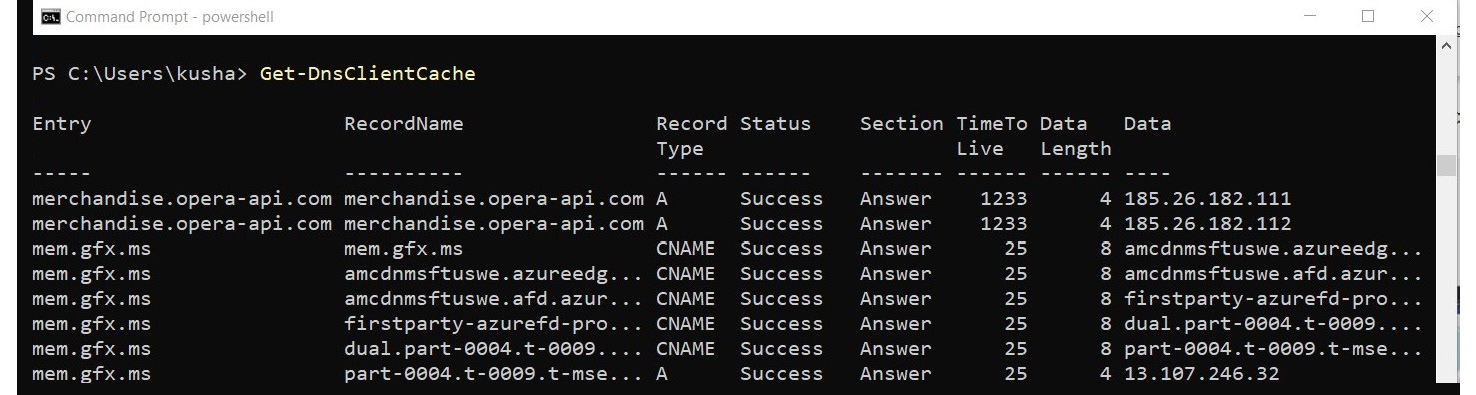
Figure 1.12 – Information retrieved by Get-DnsClientCache
This information is categorized as volatile information. However, until your next reboot or shutdown, these entries will be there if the TTL value has not reached 0.
If you execute the preceding command a few times, with some intervals, you will realize every time you run it, the TTL value of the result is always less than the previous TTL value. When the TTL value becomes 0, the entry will be automatically removed. This is how DNS has been designed, to provide optimum performance during the runtime and when you change the DNS entry. That’s the reason why when you change the DNS entry, it can take up to 48 hours to completely replicate the DNS as some clients might still have resolved IPs from DNS entries in their cache.
This is not just the case on the local cache; if you have DNS servers in the infrastructure, these DNS servers also cache the resolved DNS entries for later use.
Summary
This chapter focused on five core areas to provide a clear foundation for cyber anonymity. We learned how to identify sensitive information and categorize and classify it. We also learned about the ways that an attacker can retrieve sensitive information from raw data. We also discussed privacy concerns in cyberspace and areas to look at when it comes to cyber anonymity.
In the next chapter, you will learn the reasons why attackers are interested in breaching your privacy and how attackers use stolen data for their benefit.
