


















 Download code from GitHub
Download code from GitHub
Introducing Deep Learning with Amazon SageMaker
Deep learning (DL) is a fairly new but actively developing area of machine learning (ML). Over the past 15 years, DL has moved from research labs to our homes (such as smart homes and smart speakers) and cars (that is, self-driving capabilities), phones (for example, photo enhancement software), and applications you use every day (such as recommendation systems in your favorite video platform).
DL models are achieving and, at times, exceeding human accuracy on tasks such as computer vision (object detection and segmentation, image classification tasks, and image generation) and language tasks (translation, entity extraction, and text sentiment analysis). Beyond these areas, DL is also actively applied to complex domains such as healthcare, information security, robotics, and automation.
We should expect that DL applications in these domains will only grow over time. With current results and future promises also come challenges when implementing DL models. But before talking about the challenges, let’s quickly refresh ourselves on what DL is.
In this chapter, we will do the following:
- We’ll get a quick refresher on DL and its challenges
- We’ll provide an overview of Amazon SageMaker and its value proposition for DL projects
- We’ll provide an overview of the foundational SageMaker components – that is, managed training and hosting stacks
- We’ll provide an overview of other key AWS services
These will be covered in the following topics:
- Exploring DL with Amazon SageMaker
- Choosing Amazon SageMaker for DL workloads
- Exploring SageMaker’s managed training stack
- Using SageMaker’s managed hosting stack
- Integration with AWS services
Technical requirements
There are several hands-on code samples in this chapter. To follow along with them, you will need the following:
- An AWS account and IAM user with permission to manage Amazon SageMaker resources.
- A computer or cloud host with Python3 and SageMaker SDK installed (https://pypi.org/project/sagemaker/).
- Have the AWS CLI installed (see https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html) and configured to use IAM user (see the instructions at https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-quickstart.html).
- To use certain SageMaker instance types for training purposes, you will likely need to request a service limit increase in your AWS account. For more information, go to https://docs.aws.amazon.com/general/latest/gr/aws_service_limits.html.
All of the code in this chapter can be downloaded from https://github.com/PacktPublishing/Accelerate-Deep-Learning-Workloads-with-Amazon-SageMaker.
Exploring DL with Amazon SageMaker
DL is a subset of the ML field, which uses a specific type of architecture: layers of learnable parameters connected to each other. In this architecture, each layer is “learning” a representation from a training dataset. Each new training data sample slightly tweaks the learnable parameters across all the layers of the model to minimize the loss function. The number of stacked layers constitutes the “depth” of the model. At inference time (that is, when we use our model to infer output from the input signal), each layer receives input from the previous layer’s output, calculates its representation based on the input, and sends it to the next layer.

Figure 1.1 – Fully connected DL network
Simple DL models can consist of just a few fully connected layers, while state-of-the-art (SOTA) models have hundreds of layers with millions and billions of learnable parameters. And the model size continues to grow. For example, let’s take a look at the evolution of the GPT family of models for various NLP tasks. The GPT-1 model was released in 2018 and had 110 million parameters; the GPT-2 model released in 2019 had 1,500 million parameters; the latest version, GPT-3, was released in 2020 and has 175 billion parameters!
As the number of parameters grows, DL practitioners deal with several engineering problems:
- How do we fit models into instance memory at training time? If it’s not possible, then how do we split the model between the memory of multiple GPU devices and/or compute nodes?
- How can we organize communication between multiple nodes at training time so that the overall model can aggregate learnings from individual nodes?
Layer internals are also becoming more complex and require more computing power. DL models also typically require vast amounts of data in specific formats.
So, to be able to successfully train and use SOTA DL models, ML engineers need to solve the following tasks (beyond implementing the SOTA model, of course):
- Gain access to a large number of specialized compute resources during training and inference
- Set up and maintain a software stack (for example, GPU libraries, DL frameworks, and acceleration libraries)
- Implement, manage, and optimize distributed training jobs
- Implement, deploy, and monitor inference pipelines
- Organize time- and cost-efficient experiments when tuning model performance
- Pre-process, label, and access large datasets (GBs and TBs of data)
As you can see, these tasks are not necessarily related to solving any specific business problem. However, you need to get all these components right to ensure that a particular business case can be solved using DL models with the highest possible accuracy in time and within expected budgets.
Using SageMaker
Amazon SageMaker is an AWS service that promises to simplify the lives of ML practitioners by removing “undifferentiated heavy lifting” (such as the tasks mentioned previously) and lets you focus on actually solving business problems instead. It integrates various functional capabilities to build, train, and deploy ML models. SageMaker was first introduced in late 2017 and has since expanded greatly, adding more than 200 features in 2020 alone according to AWS’s Re:invent 2020 keynotes.
Amazon SageMaker caters to a broad audience and set of use cases, including the following (this is a non-exclusive list):
- Developers without much ML background
- Enterprise data science teams
- Leading research organizations who are looking to run cutting-edge research
SageMaker is a managed service as it abstracts the management of underlying compute resources and software components via APIs. AWS customers use these APIs to create training jobs, manage model artifacts, and deploy models for inference on Amazon SageMaker. AWS is responsible for the high availability of SageMaker resources and provides respective Service-Level Agreements (SLAs). Amazon SageMaker has a “pay as you go” model, with customers paying only for the resources they consume.
In this book, we will explore SageMaker capabilities that are relevant for DL models and workloads, and we will build end-to-end solutions for popular DL use cases, such as Natural Language Processing (NLP) and Computer Vision (CV).
We will focus on the following Amazon SageMaker capabilities:
- Model development phase:
- Data preparation using SageMaker GroundTruth
- Data pre- and post-processing using SageMaker Processing
- Integration with data storage solutions – Amazon S3, Amazon EFS, and Amazon FSx for Lustre
- Developing models using SageMaker Studio IDE and Notebooks
- Training phase:
- Inference:
- Managed hosting platform for batch and real-time inference
- Model monitoring at inference time
- Compute instances for DL serving
As we progress through the book, we will also learn how to use the SageMaker API and SDKs to programmatically manage our resources. Additionally, we will discuss optimization strategies and SageMaker capabilities to reduce cost and time-to-market.
This book focuses on DL capabilities, so we will set several SageMaker features and capabilities aside. You can explore Amazon SageMaker further by reading the SageMaker documentation (https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html) and practical blog posts (https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/sagemaker/).
In the next section, we’ll find out exactly how SageMaker can help us with DL workloads.
Choosing Amazon SageMaker for DL workloads
As discussed earlier, DL workloads present several engineering challenges due to their need to access high quantities of specialized resources (primarily GPU devices and high-throughput storage solutions). However, managing a software stack can also present a challenge as new versions of ML and DL frameworks are released frequently. Due to high associated costs, it’s also imperative to organize your training and inference efficiently to avoid waste.
Let’s review how SageMaker can address these challenges.
Managed compute and storage infrastructure
SageMaker provides a fully managed compute infrastructure for your training and inference workloads. SageMaker Training and Inference clusters can scale to tens and up to hundreds of individual instances within minutes. This can be particularly useful in scenarios where you need to access a large compute cluster with short notice and for a limited period (for example, you need to train a complex DL model on a large dataset once every couple of months). As with other AWS services, SageMaker resources provide advanced auto-scaling features for inference endpoints so that customers can match demand without resource overprovisioning.
You can also choose from a growing number of available compute instances based on the requirements of specific DL models and types of workload. For instance, in many scenarios, you would need to use a GPU-based instance to train your DL model, while it may be possible to use cheaper CPU instances at inference time without this having an impact on end user performance. SageMaker gives you the flexibility to choose the most optimal instances for particular DL models and tasks.
In case of failure, AWS will automatically replace faulty instances without any customer intervention.
These SageMaker features greatly benefit customers as SageMaker simplifies capacity planning and operational management of your ML infrastructure.
Managed DL software stacks
To build, train, and deploy DL models, you need to use various frameworks and software components to perform specialized computations and communication between devices and nodes in distributed clusters. Creating and maintaining software stacks across various development environments can be labor-intensive.
To address these needs, as part of the SageMaker ecosystem, AWS provides multiple pre-built open source Docker containers for popular DL frameworks such as PyTorch, TensorFlow, MXNet, and others. These containers are built and tested by AWS and optimized for specific tasks (for instance, different containers for training and inference) and compute platforms (CPU or GPU-based containers, different versions of CUDA toolkits, and others).
Since Docker containers provide interoperability and encapsulation, developers can utilize pre-built SageMaker containers to build and debug their workloads locally before deploying them to a cloud cluster to shorten the development cycle. You also have the flexibility to extend or modify SageMaker containers based on specific requirements.
Advanced operational capabilities
While Amazon SageMaker utilizes several popular open source solutions for DL, it also provides several unique capabilities to address certain challenges when operationalizing your ML workloads, such as the following:
- SageMaker Debugger
- SageMaker Model Monitor
- SageMaker’s DataParallel/ModelParallel distributed training libraries
Let’s move on next to look at integration with other AWS services.
Integration with other AWS services
Amazon SageMaker is well integrated with other AWS services so that developers can build scalable, performant, and secure workloads.
In the next section, we’ll see how Amazon SageMaker’s managed training stack can be leveraged to run DL models.
Exploring SageMaker’s managed training stack
Amazon SageMaker provides a set of capabilities and integration points with other AWS services to configure, run, and monitor ML training jobs. With SageMaker managed training, developers can do the following:
- Choose from a variety of built-in algorithms and containers, as well as BYO models
- Choose from a wide range of compute instances, depending on the model requirements
- Debug and profile their training process in near-real-time using SageMaker Debugger
- Run bias detection and model explainability jobs
- Run incremental training jobs, resume from checkpoints, and use spot instances
Spot instances
Amazon EC2 Spot Instances provides customers with access to unused compute capacity at a lower price point (up to 90%). Spot instances will be released when someone else claims them, which results in workload interruption.
- Run model tuning jobs to search for optimal combinations of model hyperparameters
- Organize training jobs in a searchable catalog of experiments
Amazon SageMaker provides the following capabilities out of the box:
- Provisioning, bootstrapping, and tearing down training nodes
- Capturing training job logs and metrics
In this section, we will go over all the stages of a SageMaker training job and the components involved. Please refer to the following diagram for a visual narrative that provides a step-by-step guide on creating, managing, and monitoring your first SageMaker training job. We will address the advanced features of SageMaker’s managed training stack in Part 2 of this book:
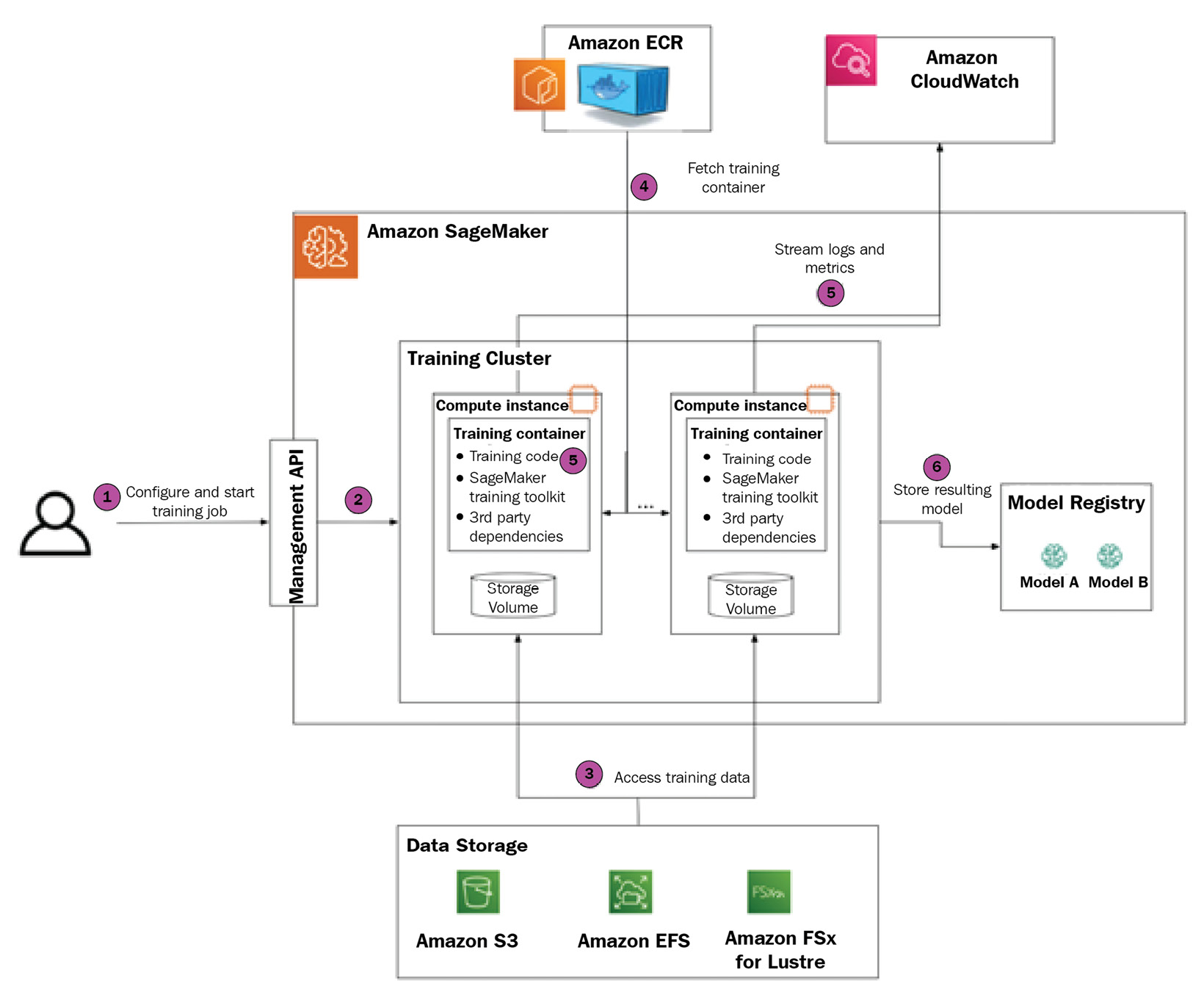
Figure 1.2 – Amazon SageMaker training stack
Let’s walk through each step in turn.
We will also provide code snippets to illustrate how to perform a SageMaker training job configuration using the SageMaker Python SDK (https://sagemaker.readthedocs.io/en/stable/).
Step 1 – configuring and creating a training job
You can instantiate a SageMaker training job via an API call.
SageMaker defines several mandatory configuration parameters that need to be supplied by you. They are listed as follows.
Choosing an algorithm to train
Amazon SageMaker supports several types of ML algorithms:
- Built-in algorithms are available out of the box for all SageMaker users. At the time of writing, 18 built-in algorithms cover a variety of use cases, including DL algorithms for computer vision and NLP tasks. The user is only responsible for providing algorithm hyperparameters.
- Custom algorithms are developed by the user. AWS is not responsible for training logic in this case. The training script will be executed inside a Docker container. Developers can choose to use AWS-authored Docker images with pre-installed software dependencies or can use BYO Docker images.
- Marketplace algorithms are developed by third-party vendors and available via the AWS Marketplace. Similar to built-in algorithms, they typically offer a fully managed experience where the user is responsible for providing algorithm hyperparameters. Unlike built-in algorithms, which are free to use, the user usually pays a fee for using marketplace algorithms.
Defining an IAM role
Amazon SageMaker relies on the Amazon IAM service and, specifically, IAM roles to define which AWS resources and services can be accessed from the training job. That’s why, whenever scheduling a SageMaker training job, you need to provide an IAM role, which will be then assigned to training nodes.
Defining a training cluster
Another set of required parameters defines the hardware configuration of the training cluster, which includes several compute instances, types of instances, and instance storage.
It’s recommended that you carefully choose your instance type based on specific requirements. At a minimum, ML engineers need to understand which compute device is used at training time. For example, in most cases for DL models, you will likely need to use a GPU-based instance, while many classical ML algorithms (such as linear regression or Random Forest) are CPU-bound.
ML engineers also need to consider how many instances to provision. When provisioning multiple nodes, you need to make sure that your algorithm and training script support distributed training.
Built-in algorithms usually provide recommended instance types and counts in their public documentation. They also define whether distributed training is supported or not. In the latter case, you should configure a single-node training cluster.
Defining training data
Amazon SageMaker supports several storage solutions for training data:
- Amazon S3: This is a low-cost, highly durable, and highly available object storage. This is considered a default choice for storing training datasets. Amazon S3 supports two types of input mode (also defined in training job configuration) for training datasets:
- Amazon EFS: This is an elastic filesystem service. If it’s used to persist training data, Amazon SageMaker will automatically mount the training instance to a shared filesystem.
- Amazon FSx for Luster: This is a high-performant shared filesystem optimized for the lowest latency and highest throughput.
Before training can begin, you need to make sure that data is persisted in one of these solutions, and then provide the location of the datasets.
Please note that you can provide the locations of several datasets (for example, training, test, and evaluation sets) in your training job.
Picking your algorithm hyperparameters
While it’s not strictly mandatory, in most cases, you will need to define certain hyperparameters of the algorithm. Examples of such hyperparameters include the batch size, number of training epochs, and learning rate.
At training time, these hyperparameters will be passed to the training script as command-line arguments. In the case of custom algorithms, developers are responsible for parsing and setting hyperparameters in the training script.
Defining the training metrics
Metrics are another optional but important parameter. SageMaker provides out-of-the-box integration with Amazon CloudWatch to stream training logs and metrics. In the case of logs, SageMaker will automatically stream stdout and stderr from the training container to CloudWatch.
stdout and stderr
stdout and stderr are standard data streams in Linux and Unix-like OSs. Every time you run a Linux command, these data streams are established automatically. Normal command output is sent to stdout; any error messages are sent to stderr.
In the case of metrics, the user needs to define the regex pattern for each metric first. At training time, the SageMaker utility running on the training instance will monitor stdout and stderr for the regex pattern match, then extract the value of the metric and submit the metric name and value to CloudWatch. As a result, developers can monitor training processes in CloudWatch in near-real time.
Some common examples of training metrics include loss value and accuracy measures.
Configuring a SageMaker training job for image classification
In the following Python code sample, we will demonstrate how to configure a simple training job for a built-in image classification algorithm (https://docs.aws.amazon.com/sagemaker/latest/dg/image-classification.html):
- Begin with your initial imports:
import sagemaker from sagemaker import get_execution_role
- The
get_execution_role()method allows you to get the current IAM role. This role will be used to call the SageMaker APIs, whereassagemaker.Session()stores the context of the interaction with SageMaker and other AWS services such as S3:role = get_execution_role() sess = sagemaker.Session()
- The
.image_uris.retrieve()method allows you to identify the correct container with the built-in image classification algorithm. Note that if you choose to use custom containers, you will need to specify a URI for your specific training container:training_image = sagemaker.image_uris.retrieve('image-classification', sess.boto_region_name) - Define the number of instances in the training cluster. Since image classification supports distributed training, we can allocate more than one instance to the training cluster to speed up training:
num_instances = 2
- The image classification algorithm requires GPU-based instances, so we will choose to use a SageMaker P2 instance type:
instance_type = "ml.p2.xlarge"
- Next, we must define the location of training and validation datasets. Note that the image classification algorithm supports several data formats. In this case, we choose to use the JPG file format, which also requires
.lstfiles to list all the available images:data_channels = { 'train': f"s3://{sess.default_bucket()}/data/train", 'validation': f"s3://{sess.default_bucket()}/data/validation", 'train_lst': f"s3://{sess.default_bucket()}/data/train.lst", 'vadidation_lst': f"s3://{sess.default_bucket()}/data/validation.lst", } - Configure the training hyperparameters:
hyperparameters=dict( use_pretrained_model=1, image_shape='3,224,224', num_classes=10, num_training_samples=40000, # TODO: update it learning_rate=0.001, mini_batch_size= 8 )
- Configure the
Estimatorobject, which encapsulates training job configuration:image_classifier = sagemaker.estimator.Estimator( training_image, role, train_instance_count= num_instances, train_instance_type= instance_type, sagemaker_session=sess, hyperparameters=hyperparameters, )
- The
fit()method submits the training job to the SageMaker API. If there are no issues, you should observe a new training job instance in your AWS Console. You can do so by going to Amazon SageMaker | Training | Training Jobs:image_classifier.fit(inputs=data_channels, job_name="sample-train")
Next, we’ll provision the training cluster.
Step 2 – provisioning the SageMaker training cluster
Once you submit a request for the training job, SageMaker automatically does the following:
- Allocates the requested number of training nodes
- Allocates the Amazon EBS volumes and mounts them on the training nodes
- Assigns an IAM role to each node
- Bootstraps various utilities (such as Docker, SageMaker toolkit libraries, and so on)
- Defines the training configuration (hyperparameters, input data configuration, and so on) as an environment variable
Next up is the training data.
Step 3 – SageMaker accesses the training data
When your training cluster is ready, SageMaker establishes access to training data for compute instances. The exact mechanism to access training data depends on your storage solution:
- If data is stored in S3 and the input mode is File, then data will be downloaded to instance EBS volumes. Note that depending on the dataset’s size, it may take minutes to download the data.
- If the data is stored in S3 and the input mode is Pipe, then the data will be streamed from S3 at training time as needed.
- If the data is stored in S3 and the input mode is FastFile, then the training program will access the files as if they are stored on training nodes. However, under the hood, the files will be streamed from S3.
- If the data is stored in EFS or FSx for Luster, then the training nodes will be mounted on the filesystem.
The training continues with deploying the container.
Step 4 – SageMaker deploys the training container
SageMaker automatically pulls the training images from the ECR repository. Note that built-in algorithms abstract the underlying training images so that users don’t have to define the container image, just the algorithm to be used.
Step 5 – SageMaker starts and monitors the training job
To start the training job, SageMaker issues the following command on all training nodes:
docker run [TrainingImage] train
If the training cluster has instances with GPU devices, then nvidia-docker will be used.
Once the training script has started, SageMaker does the following:
- Captures
stdout/stderrand sends it to CloudWatch logs. - Runs a regex pattern match for metrics and sends the metric values to CloudWatch.
- Monitors for a
SIGTERMsignal from the SageMaker API (for example, if the user decides to stop the training job earlier). - Monitors if an early stopping condition occurs and issues
SIGTERMwhen this happens. - Monitors for the exit code of the training script. In the case of a non-zero exit code, SageMaker will mark the training job as “failed.”
Step 6 – SageMaker persists the training artifacts
Regardless of whether the training job fails or succeeds, SageMaker stores artifacts in the following locations:
- The
/opt/ml/outputdirectory, which can be used to persist any training artifacts after the job is completed. - The
/opt/ml/modeldirectory, the content of which will be compressed into.tarformat and stored in the SageMaker model registry.
Once you have your first model trained to solve a particular business problem, the next step is to use your model (in ML parlance, perform inference). In the next few sections, we will learn what capabilities SageMaker provides to run ML inference workloads for various use cases.
Using SageMaker’s managed hosting stack
Amazon SageMaker supports several types of managed hosting infrastructure:
- A persistent synchronous HTTPS endpoint for real-time inference
- An asynchronous endpoint for near-real-time inference
- A transient Batch Transform job that performs inference across the entire dataset
In the next section, we will discuss use cases regarding when to use what type of hosting infrastructure, and we’ll review real-time inference endpoints in detail.
Real-time inference endpoints
Real-time endpoints are built for use cases where you need to get inference results as soon as possible. SageMaker’s real-time endpoint is an HTTPS endpoint: model inputs are provided by the client via a POST request payload, and inference results are returned in the response body. The communication is synchronous.
There are many scenarios when real-time endpoints are applicable, such as the following:
- To provide movie recommendations when the user opens a streaming application, based on the user’s watch history, individual ratings, and what’s trending now
- To detect objects in a real-time video stream
- To generate a suggested next word as the user inputs text
SageMaker real-time endpoints provide customers with a range of capabilities to design and manage their inference workloads:
- Create a fully managed compute infrastructure with horizontal scaling (meaning that a single endpoint can use multiple compute instances to serve high traffic load without performance degradation)
- There is a wide spectrum of EC2 compute instance types to choose from based on model requirements including AWS’ custom chip Inferentia and SageMaker Elastic Inference
- Pre-built inference containers for popular DL frameworks
- Multi-model and multi-container endpoints
- Model production variants for A/B testing
- Multi-model inference pipelines
- Model monitoring for performance, accuracy, and bias
- SageMaker Neo and SageMaker Edge Manager to optimize and manage inference at edge devices
Since this is a managed capability, Amazon SageMaker is responsible for the following aspects of managing users’ real-time endpoints:
- Provisioning and scaling the underlying compute infrastructure based on customer-defined scaling policies
- Traffic shaping between model versions and containers in cases where multiple models are deployed on a single SageMaker endpoint.
- Streaming logs and metrics at the level of the compute instance and model.
Creating and using your SageMaker endpoint
Let’s walk through the process of configuring, provisioning, and using your first SageMaker real-time endpoint. This will help to build your understanding of its internal workings and the available configuration options. The following diagram provides a visual guide:
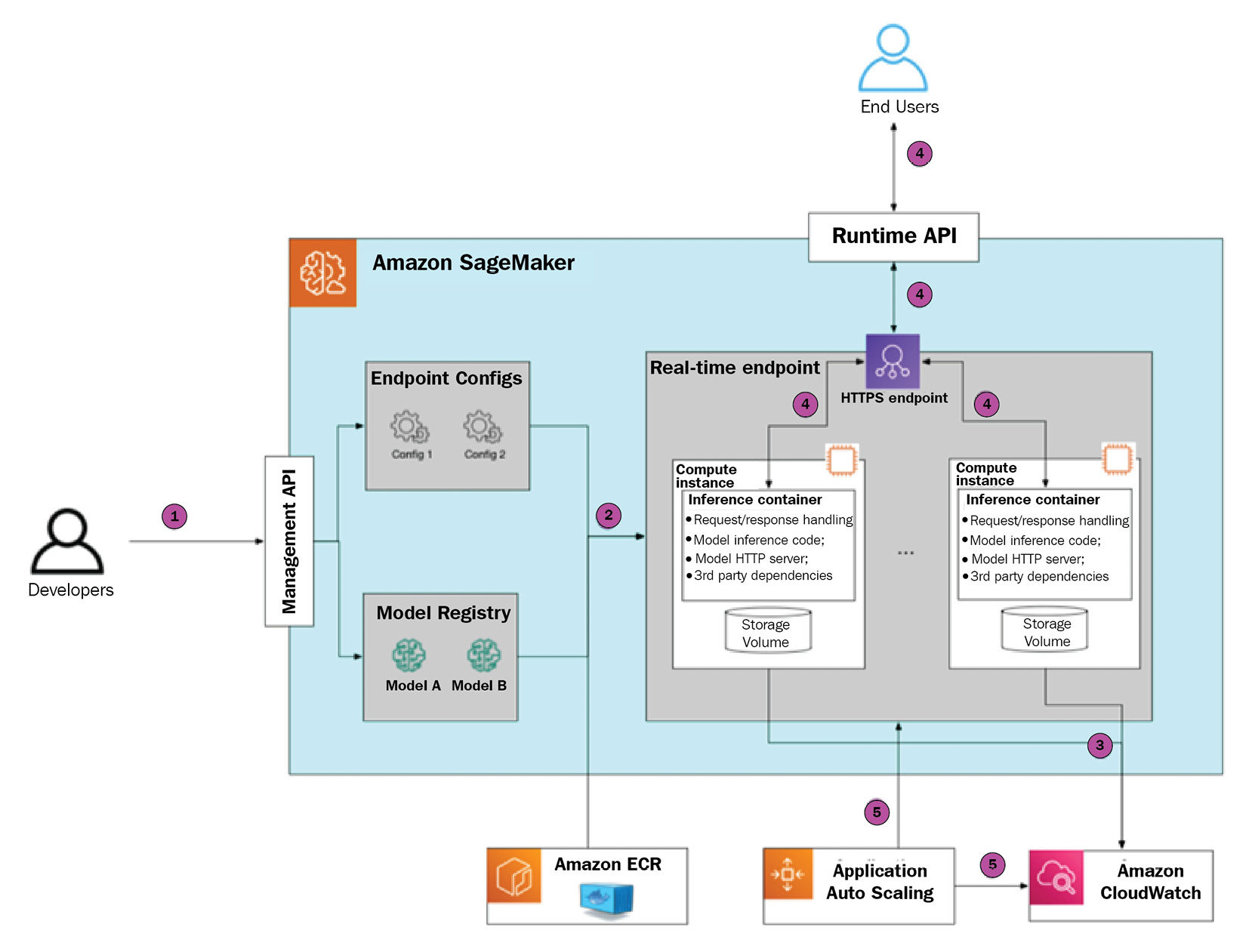
Figure 1.3 – SageMaker inference endpoint deployment and usage
Step 1 – initiating endpoint creation
There are several ways to initiate SageMaker endpoint creation: the SageMaker Python SDK, the boto3 SDK, the AWS CLI, or via a CloudFormation template. As part of the request, there are several parameters that you need to provide, as follows:
- Model definition in SageMaker Model Registry, which will be used at inference time. The model definition includes references to serialized model artifacts in S3 and a reference to the inference container (or several containers in the case of a multi-container endpoint) in Amazon ECR.
- Endpoint configuration, which defines the number and type of compute instances, and (optional) a combination of several models (in the case of a multi-model endpoint) or several model production variants (in the case of A/B testing).
Step 2 – configuring the SageMaker endpoint for image classification
The following Python code sample shows how to create and deploy an endpoint using the previously trained image classification model:
- Begin with your initial imports, IAM role, and SageMaker session instantiation:
import sagemaker from sagemaker import get_execution_role role = get_execution_role() sess = sagemaker.Session()
- Retrieve the inference container URI for the image classification algorithm:
image_uri = sagemaker.image_uris.retrieve('image-classification', sess.boto_region_name) - Define where the model artifacts (such as trained weights) are stored in S3:
model_data = f"s3://{sess.default_bucket}/model_location" - Create a SageMaker
Modelobject that encapsulates the model configuration:model = Model( image_uri=image_uri, model_data=model_data, name="image-classification-endpoint", sagemaker_session=sess, role=role )
- Define the endpoint configuration parameters:
endpoint_name = "image-classification-endpoint" instance_type = "ml.g4dn.xlarge" instance_count = 1
- The
.predict()method submits a request to SageMaker to create an endpoint with a specific model deployed:predictor = model.deploy( instance_type=instance_type, initial_instance_count=instance_count, endpoint_name=endpoint_name, )
With that done, SageMaker gets to work.
Step 3 – SageMaker provisions the endpoint
Once your provision request is submitted, SageMaker performs the following actions:
- It will allocate several instances according to the endpoint configuration
- It will deploy an inference container
- It will download the model artifacts
It takes several minutes to complete endpoint provisioning from start to finish. The provisioning time depends on the number of parameters, such as instance type, size of the inference container, and the size of the model artifacts that need to be uploaded to the inference instance(s).
Please note that SageMaker doesn’t expose inference instances directly. Instead, it uses a fronting load balancer, which then distributes the traffic between provisioned instances. As SageMaker is a managed service, you will never interact with inference instances directly, only via the SageMaker API.
Step 4 – SageMaker starts the model server
Once the endpoint has been fully provisioned, SageMaker starts the inference container by running the following command, which executes the ENTRYPOINT command in the container:
docker run image serve
This script does the following:
- Starts the model server, which exposes the HTTP endpoint
- Makes the model server load the model artifacts in memory
- At inference time, it makes the model server execute the inference script, which defines how to preprocess data
In the case of SageMaker-managed Docker images, the model server and startup logic are already implemented by AWS. If you choose to BYO serving container, then this needs to be implemented separately.
SageMaker captures the stdout/stderr streams and automatically streams them to CloudWatch logs. It also streams instances metrics such as the number of invocations total and per instance, invocation errors, and latency measures.
Step 5 – the SageMaker endpoint serves traffic
Once the model server is up and running, end users can send a POST request to the SageMaker endpoint. The endpoint authorizes the request based on the authorization headers (these headers are automatically generated when using the SageMaker Python SDK or the AWS CLI based on the IAM profile). If authorization is successful, then the payload is sent to the inference instance.
The running model server handles the request by executing the inference script and returns the response payload, which is then delivered to the end user.
Step 6 – SageMaker scales the inference endpoint in or out
You may choose to define an auto-scaling policy to scale endpoint instances in and out. In this case, SageMaker will add or remove compute nodes behind the endpoint to match demand more efficiently. Please note that SageMaker only supports horizontal scaling, such as adding or removing compute nodes, and not changing instance type.
SageMaker supports several types of scaling events:
- Manual, where the user updates the endpoint configuration via an API call
- A target tracking policy, where SageMaker scales in or out based on the value of the user-defined metric (for example, the number of invocations or resource utilization)
- A step scaling policy, which provides the user with more granular control over how to adjust the number of instances based on how much threshold is breached
- A scheduled scaling policy, which allows you to scale the SageMaker endpoint based on a particular schedule (for example, scale in during the weekend, where there’s low traffic, and scale out during the weekday, where there’s peak traffic)
Advanced model deployment patterns
We just reviewed the anatomy of a simple, single-model real-time endpoint. However, in many real-life scenarios where there are tens or hundreds of models that need to be available at any given point in time, this approach will lead to large numbers of underutilized or unevenly utilized inference nodes.
This is a generally undesirable situation as it will lead to high compute costs without any end user value. To address this problem, Amazon SageMaker provides a few advanced deployment options that allow you to combine several models within the same real-time endpoint and, hence, utilize resources more efficiently.
Multi-container endpoint
When deploying a multi-container endpoint, you may specify up to 15 different containers within the same endpoint. Each inference container has model artifacts and its own runtime environment. This allows you to deploy models built in various frameworks and runtime environments within a single SageMaker endpoint.
At creation time, you define a unique container hostname. Each container can then be invoked independently. During endpoint invocation, you are required to provide this container hostname as one of the request headers. SageMaker will automatically route the inference request to a correct container based on this header.
This feature comes in handy when there are several models with relatively low traffic and different runtime environments (for example, Pytorch and TensorFlow).
Inference pipeline
Like a multi-container endpoint, the inference pipeline allows you to combine different models and container runtimes within a single SageMaker endpoint. However, the containers are called sequentially. This feature is geared toward scenarios where an inference request requires pre and/or post-processing with different runtime requirements; for example:
- The pre-processing phase is done using the scikit-learn library
- Inference is done using a DL framework
- Post-processing is done using a custom runtime environment, such as Java or C++
By encapsulating different phases of the inference pipeline in separate containers, changes in one container won’t impact adversely other containers, such as updating the dependency version. Since containers within inference pipelines are located on the same compute node, this guarantees low latency during request handoff between containers.
Multi-model endpoint
Multi-model endpoints allow you to deploy hundreds of models within a single endpoint. Unlike multi-container endpoints and inference pipelines, a multi-model endpoint has a single runtime environment. SageMaker automatically loads model artifacts into memory and handles inference requests. When a model is no longer needed, SageMaker unloads it from memory to free up resources. This leads to some additional latency when invoking the model for the first time after a while. Model artifacts are stored on Amazon S3 and loaded by SageMaker automatically.
At the core of the multi-model endpoint is the AWS-developed open source Multi-Model Server, which provides model management capabilities (loading, unloading, and resource allocation) and an HTTP frontend to receive inference requests, execute inference code for a given model, and return the resulting payload.
Multi-model endpoints are optimal when there’s a large number of homogeneous models and end users can tolerate warmup latency.
SageMaker asynchronous endpoints
So far, we have discussed SageMaker real-time endpoints, which work synchronously: users invoke the endpoint by sending a POST request, wait for the endpoint to run inference code, and then return the inference results in the response payload. The inference code is expected to complete within 60 seconds; otherwise, the SageMaker endpoint will return a timeout response.
In certain scenarios, however, this synchronous communication pattern can be problematic:
- Large models can take a considerable time to perform inference
- Large payload sizes (for instance, high-resolution imagery)
For such scenarios, SageMaker provides Asynchronous Endpoints, which allow you to queue inference requests and process them asynchronously, avoiding potential timeouts. Asynchronous endpoints also allow for a considerably larger payload size of up to 1 GB, whereas SageMaker real-time endpoints have a limit of 5 MB. Asynchronous endpoints can be scaled to 0 instances when the inference queue is empty to provide additional cost savings. This is specifically useful for scenarios with sporadic inference traffic patterns.
The main tradeoff of asynchronous endpoints is that the inference results are delivered in near real-time and may not be suited for scenarios where consistent latency is expected:

Figure 1.4 – SageMaker asynchronous endpoint
SageMaker Batch Transform
SageMaker Batch Transform allows you to get predictions for a batch of inference inputs. This can be useful for scenarios where there is a recurrent business process and there are no strict latency requirements. An example is a nightly job that calculates risks for load applications.
SageMaker Batch Transform is beneficial for the following use cases:
- Customers only pay for resources that are consumed during job execution
- Batch Transform jobs can scale to GBs and tens of compute nodes
When scheduling a Batch Transform job, you define the cluster configuration (type and number of compute nodes), model artifacts, inference container, the input S3 location for the inference dataset, and the output S3 location for the generated predictions. Please note that customers can use the same container for SageMaker real-time endpoints and the Batch Transform job. This allows developers to use the same models/containers for online predictions (as real-time endpoints) and offline (as Batch Transform jobs):

Figure 1.5 – SageMaker Batch Transform job
With that, you understand how to train a simple DL model using a SageMaker training job and then create a real-time endpoint to perform inference. Before we proceed further, we need to learn about several foundational AWS services that are used by Amazon SageMaker that you will see throughout this book.
Integration with AWS services
Amazon SageMaker relies on several AWS services, such as storage and key management. In this section, we will review some key integrations with other AWS services and use cases when they can be useful.
Data storage services
Data storage services are key to building any ML workload. AWS provides several storage solutions to address a wide range of real-life use cases.
Amazon S3 is a form of serverless object storage and one of AWS’s foundational services. SageMaker utilizes S3 for a wide range of use cases, such as the following:
- To store training datasets
- To store model artifacts and training output
- To store inference inputs and outputs for Asynchronous Endpoints and Batch Transform jobs
Amazon S3 is a highly durable, scalable, and cost-efficient storage solution. When accessing data stored on S3, developers may choose to either download the full dataset from the S3 location to SageMaker compute nodes or stream the data. Downloading a large dataset from S3 to SageMaker compute nodes to add to the training job’s startup time.
Amazon EFS
Amazon Elastic File System (EFS) is an elastic filesystem service. Amazon SageMaker supports storing training datasets in EFS locations. At training time, SageMaker nodes mount to the EFS location and directly access the training datasets. In this case, no data movement is required for nodes to access data, which typically results in reduced startup times for training jobs. EFS also allows multiple nodes to persist and seamlessly share data (since this is a shared system). This can be beneficial when the cache or system state needs to be shared across training nodes.
Amazon FSx for Lustre
Amazon FSx for Lustre is a shared filesystem service designed specifically for low-latency, high-performance scenarios. Amazon FSx automatically copies data from the S3 source and makes it available for SageMaker compute nodes. Amazon FSx has similar benefits to EFS – that is, a reduced startup time for training jobs and a shared filesystem.
Orchestration services
Orchestration services allow you to integrate SageMaker-based workloads with the rest of the IT ecosystem.
AWS Step Functions
AWS Step Functions is a serverless workflow service that allows you to orchestrate business processes and interactions with other AWS services. With Step Functions, it’s easy to combine individual steps into reusable and deployable workflows. It supports visual design and branching and conditional logic.
Step Functions provides native integration with SageMaker resources. Step Functions can be useful in scenarios where you need to orchestrate complex ML pipelines using multiple services in addition to SageMaker. AWS provides developers with the AWS Step Functions Data Science Python SDK to develop, test, and execute such pipelines.
Amazon API Gateway
Amazon API Gateway is a fully managed API management service that’s used to develop, monitor, and manage APIs. API Gateway supports several features that can be helpful when developing highly-scalable and secure ML inference APIs:
- Authentication and authorization mechanisms
- Request caching, rate limiting, and throttling
- Firewall features
- Request headers and payload transformation
API Gateway allows you to insulate SageMaker real-time endpoints from external traffic and provide an additional layer of security. It also allows you to provide end users with a unified API without exposing the specifics of the SageMaker runtime API.
Security services
Robust security controls are a must-have for any ML workload, especially when dealing with private and sensitive data. While this book does not focus on security, it’s important to understand the basic aspects of permissions and data encryption on AWS.
AWS IAM
AWS Identity and Access Management (IAM) allows customers to manage access to AWS services and resources. In the case of SageMaker, IAM has a twofold function:
- IAM roles and policies define which AWS resources SageMaker jobs can access and manage – for example, whether the training job with the assumed IAM role can access the given dataset on S3 or not.
- IAM roles and policies define which principal (user or service) can access and manage SageMaker resources. For instance, it defines whether the given user can schedule a SageMaker training job with a specific cluster configuration.
Reviewing IAM is outside the scope of this book, but you need to be aware of it. Setting up IAM permissions and roles are prerequisites when working with SageMaker.
Amazon VPC
Amazon Virtual Private Cloud (VPC) is a service that allows you to run your cloud workloads in logically isolated private networks. This network-level isolation provides an additional level of security and control over who can access your workload. SageMaker allows you to run training and inference workloads inside a dedicated VPC so that you can control egress and ingress traffic to and from your SageMaker resources.
AWS KMS
AWS Key Management Service (KMS) is used to encrypt underlying data. It also manages access to cryptographic keys when encrypting and decrypting data. In the context of SageMaker, KMS is primarily used to encrypt training data, model artifacts, and underlying disks in SageMaker clusters. KMS is integrated with all available storage solutions, such as S3, EFS, and EBS (underlying disk volumes).
Monitoring services
AWS has dedicated services to monitor the management, auditing, and execution of other AWS resources.
Amazon CloudWatch
CloudWatch provides monitoring and observability capabilities. In the context of SageMaker, it’s used primarily for two purposes:
- To store and manage logs coming from SageMaker resources such as endpoints or training jobs. By default, SageMaker ships
stdout/stderrlogs to CloudWatch. - To store time series metrics. SageMaker provides several metrics out of the box (for example, for real-time endpoints, it streams latency and invocation metrics). However, developers can implement custom metrics.
Amazon CloudTrail
CloudTrail captures all activities (such as API calls) related to managing any AWS resources, including SageMaker resources. Typically, CloudTrail is used for governance and auditing purposes, but it can be used to build event-driven workflows. For instance, developers can use it to monitor resource creation or update requests and programmatically react to specific events.
Summary
We started this chapter by providing a general overview of the DL domain and its challenges, as well as the Amazon SageMaker service and its value proposition for DL workloads. Then, we reviewed the core SageMaker capabilities: managed training and managed hosting. We examined the life cycle of a SageMaker training job and real-time inference endpoint. Code snippets demonstrated how to configure and provision SageMaker resources programmatically using its Python SDK. We also looked at other relevant AWS services as we will be using them a lot in the rest of this book. This will help us as we now have a good grounding in their uses and capabilities.
In the next chapter, we will dive deeper into the foundational building blocks of any SageMaker workload: runtime environments (specifically, supported DL frameworks) and containers. SageMaker provides several popular pre-configured runtime environments and containers, but it also allows you to fully customize them via its “BYO container” feature. We will learn when to choose one of these options and how to use them.
