


















 Download code from GitHub
Download code from GitHub
Chapter 1: The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere
Today, data is recognized as the most valuable property available. As the so-called warehouses for this most valuable property, databases were not always given the enviable amount of attention they have been getting as of late. The hyper-growth of the internet, as well as its related and non-related industries (think traditional sectors affected by the positive externalities of increased connectivity, such as transportation and retail), the emergence of cloud-native, the development of the database industry, and distributed technology, have brought up new requirements and renewed pressure on businesses and their infrastructure.
Additionally, changes in societies at large, coupled with changes to people's lifestyles, have also raised new issues, concerns, and requirements for any modern company. Accordingly, companies must review their products, services, and architectures for their end users and consider upgrading and innovating from the frontend to the backend. Ultimately, they must consider the database and data as the most vital parts of this evolutionary process.
Simply put, data drives businesses. Stakeholders from C-suite executives, such as CIOs, to database managers are aware of the important role that data plays in transforming their businesses, satisfying users, and allowing them to maintain or create new competitive advantages.
Such recognition created a focus on three key areas all related to data – data collection, data storage, and data security – all of which will be discussed in detail in this book. The absence of databases from this list is by no means a lack of appreciation toward their integral role within organizations, but only the omission of an obvious fact.
Overlooking databases can create inefficiencies that can quickly snowball and become seriously threatening problems, such as a poor database experience for employees and customers, cost overruns, and poor workload optimization. At the same time, enterprises also need capable experts to leverage their databases and manage and efficiently utilize the data. Hence, the data, database, and database administrator (DBA) form a system that allows enterprises to efficiently store, protect, and leverage their assets.
In this chapter, we will cover the following topics:
- The evolution of DBMSs
- The evolving role of the DBA
- The opportunities and future directions for DBMSs
- Understanding Apache ShardingSphere
By the end of this chapter, you will have developed a comprehensive understanding of the current challenges for DBMSs. For those of you that are already familiar with the ongoing evolution of the database industry, this chapter will serve either as a refresher of the most pressing challenges or as a reference that organizes these challenges for you into one place.
Understanding these challenges will be followed by an introduction to the Apache ShardingSphere ecosystem and its driving concepts. Finally, you will be able to answer how ShardingSphere can help you solve the most pressing DBMS challenges and support you well into the future evolution of the database industry.
The evolution of DBMSs
With the rapid adoption of the cloud, SaaS delivery models, and open source repositories that are driving innovation, the proliferation of data has exploded in the past 10 years. These large datasets have made it mandatory for organizations who want an optimal customer experience to deploy effective and reliable database management systems (DBMSs). Nevertheless, this renewed focus for organizations on DBMSs and their requirements has not only created multiple opportunities for new technologies and new players in the industry but also numerous challenges. If you are reading this book, you are probably looking to upskill yourself and improve or expand your knowledge on how to effectively manage DBMSs.
Databases exist to store and access information. As a result, organizations now find it crucial to understand the latest techniques, technologies, and best practices to store and retrieve extensive data and the resulting traffic. The shift to cloud-based storage has also led to the expanded use of data clusters, and the related data science around data storing strategies. Data use for apps goes up and down throughout a typical day.
Reliable and scalable databases are required to help collect and process data by breaking large datasets into smaller ones. Such a need gave rise to concepts such as database sharding and partitioning, where both are used to scale extensive datasets into smaller ones while preserving performance and uptime. These concepts will be discussed in Chapter 3, Key Features and Use Cases – Your Distributed Database Essentials, in the Understanding data sharding section, and Chapter 10, Testing Frequently Encountered Application Scenarios.
Let's summarize what open source means according to The Open Source Definition (https://opensource.org/osd) – when we talk about open source, we refer to software that's released under a license where the copyright holder gives you and any other user the rights to use or change and distribute the software, even its source code, to anyone for any purpose deemed fit.
When it comes to databases, the role of open source is not only non-negligible, but it may come as a surprise to many. As of June 2021, over 50% of database management systems worldwide use an open source license (DB-Engines, Statista 2021). If we consider the recent developments of open source database software, we'll notice the proliferation of initiatives and communities dedicated to cloud-native database software.
Cloud-native databases have become increasingly important with the ushering-in of the cloud computing era. Its benefits include elasticity and the ability to meet on-demand application usage needs. Such a development creates the need for cloud migration capabilities and skills as businesses migrate workloads to different cloud platforms.
Currently, hybrid and multi-cloud environments are the norm, with nearly 75% of organizations reporting usage of a multi-cloud environment (https://www.lunavi.com/blog/multi-cloud-survey-72-using-multiple-cloud-providers-but-56-have-no-multi-cloud-strategy). The data that remains stored on-premises is, more often than not, composed of sensitive information that organizations are wary of migrating, or data that is connected to legacy applications or environments that make it too challenging to migrate.
This changed the concept of databases as we used to understand them, creating a new concept that includes data that is on-premises and in the cloud, with workloads running across various environments. The next big thing in terms of databases and infrastructure is the distributed cloud, which can be defined as an architecture where multiple clouds are used concurrently and managed centrally from a public cloud. It brings cloud-based services to organizations and blurs the lines between the cloud and on-premises systems.
The next section will introduce you to the challenges that are currently considered to be significant pain points in the industry. You may be familiar with some or all of them – if you are not, that is OK, and you will find that they are all explained in the next section.
These pain points will then be followed by equally important needs that currently haven't been met or are currently creating new opportunities in the industry.
Industry pain points
Because of the ever-expanding number of database types, engineers have to dedicate more of their time to learning SDKs and SQL dialects, and less time to developing. For an enterprise, technology selection is hard because of more complex tech stacks and the need to match their application frameworks, which can cause an oversized architecture.
The next few sections will introduce you to the most notable industry pain points, followed by new industry needs that are creating new opportunities for DBMSs.
Low-efficiency database management
Database administrators (DBAs) need to dedicate much of their time to surveying and using new databases to identify the differences in cooperation and monitoring methods, as well as to understand how to optimize performance.
The peripheral services and experience of a certain database are not universal or replicable. In production, the usage and maintenance cost of databases rises. The more database types a company deploys, the more investment will be required. If an enterprise adopts new databases suitable for new scenarios without a second thought, the investment is doomed to exponentially grow sooner or later.
New demands and increasingly frequent iteration
Different code is required to meet what could seem to be similar demands, with the only difference being the database type and the type of code that it supports. At the time of writing, while iteration frequency is already expected to rise sharply, developer response capability is reduced and inversely proportional to the number of database types. The exponential growth of common demands and database types slows down iteration significantly. The larger the number of databases, the slower the iteration pace and the lower the iteration performance level.
If, for example, the desired outcome is to encrypt all sensitive data at once, but doing so on a one-to-many database failed, the only possible solution is to modify the code on the business application side. Large firms frequently operate with dozens or even hundreds of systems, which poses great challenges for developers in encrypting all systems' data. Data encryption is only one of the many possible example challenges of this kind that developers may face, with other common demands such as permissions control, audit, and others all being frequently encountered in heterogeneous databases.
Lack of database inter-compatibility
We know for a fact that heterogeneous databases currently co-exist and will continue to do so for a long time, but without a common standard, we cannot collaboratively use databases. By common standard, we mean a universally accepted (or at least by a majority) technology reference such as the USB 2.0 or USB-C standard is for external hardware peripherals. If you are looking for a software example, look no further than SDKs that have been released to make apps for iOS or Android.
For databases, as you will learn throughout this book, we at the Apache ShardingSphere community are proponents of what we call Database Plus – which in simple terms means software that allows you to manage and improve any type of database, even to integrate different database types into the same system.
In terms of data computing, demands for a collaborative query engine and transaction management plans across heterogeneous databases are increasing. Nevertheless, at the moment, developers can only contribute to the development on the application side, making it difficult for their contribution to be developed into an infrastructure.
The new industry needs are creating new opportunities for DBMSs
The changing landscape within which enterprises operate is bound to affect their business decisions and operating procedures. This can be traced back to the expanding amounts of data and the internet argument mentioned in the Industry pain points section.
This section will give you an insight into what enterprises are looking to get from their database management systems across different industrial sectors. After that, we will look at the evolving role of a DBA, which some of you will be expected to step into.
Querying and storing enormous chunks of data
A large volume of data can crash standalone databases. We need more storage and servers to house the current enormous amount of data that will only increase in the future. A single database is unable to accommodate this data fortune.
Achieving prompt query data response time
Even though a DBMS has to accommodate enormous amounts of data, the experience and response time that's expected by customers and users do not allow DBMS downtime to organize the data little by little. How to retrieve the requested data from the data lake will be one of the top issues.
Querying and storing fragmented data types
Furthermore, the relational data structure has become one part of various data types. Documents, JSON, graphs, and key-value pairs are all attracting people's attention. This is reasonable since all of them come from varying business scenarios that involve keeping the world moving smoothly and efficiently.
All these new changes and requirements will bring necessary challenges and needs to databases and their operation and maintenance.
You may have been aware of or even already encountered some of these expectations in your professional experience. If you are just stepping into the professional world, you are bound to encounter these expectations, no matter your future industry. This is because the role of the database administrator has changed. More precisely, it has evolved, and the next section will tell you how.
The evolving role of the DBAs
These changes in industry needs have reshaped the role of the DBA as we know it. While the role of DBAs is crucial within any organization, whether it is a technology business or not, its importance has been growing at a speed that is directly correlated to the digital technology adoption rate. They are constantly looking for ways to optimize their database management systems and are the primary strategy designers to counter data spikes and ensure data safety and data availability.
They've been long considered to be key guardians of the vital strategic asset of data. This responsibility is not narrow in scope as it includes many other duties. DBAs must ensure their organizations can meet their data needs, that databases perform at optimal levels and function properly, and that, in case of any issues, they are called upon to recover the data.
Over the past decade, their responsibilities have also been reshaped thanks to new data-producing devices (smartphones and IoT devices, for example) that continue to drive data growth, thus ultimately increasing the number of database instances under management, as well as a wider array of database management systems. More recent developments have even seen DBAs increasingly involved in application development, making them emerging key influencers in the overall data management infrastructure.
In the next few sections, we will look into the most common and pressing challenges that DBMSs are facing today, and for which a DBA should be prepared.
Overwhelming traffic load increase
Ever since the introduction of the iPhone, mobile phones have gained an increasingly important role in our lives, allowing us to do more than place and receive phone calls while on the go. We now shop, order food, book our vacations, do our banking, hunt for jobs, consume entertainment, and connect with our family and friends thanks to the little devices in our pockets. While this interconnectivity gave rise to multiple new industries and business models (think sharing economy and calling an Uber), they all have one thing in common: data. The amount of data we consume and produce has ballooned to levels that were inconceivable just 15 years ago.
With the advent of the internet, it has become the norm for successful websites or business services that support apps to be receiving visits that reach well into the billions every week.
Sales days such as Cyber Monday in North America or 11/11 (also known as Singles Day) in China (the largest shopping festival in the world) are excellent examples of traditional retail enterprises that adapted to the digital world. Now, they must contend with new needs to successfully achieve their business goals. In cases such as these, retailers are looking to drive traffic to their pages or online stores. But what happens if they succeed and their database clusters are put under incredible pressure? The question becomes a technical one, with DBAs and R&D teams wondering if their database cluster will be able to handle the visitors' traffic.
Microservice architecture for frontend services
To deal with a large number of visitors, the monolithic architecture has since been phased out and officially became history. Instead, microservices architecture has become the new favorite.
A microservices architecture integrates an application as an ensemble of weakly related services. In other words, this results in an application being built as a set of independent components running the process as a service, performing a part of the whole system. Lightweight APIs are how these components communicate, with each service allowing for deployment, updates, and scaling according to specific business requirements as they are run independently.
Cloud-native disrupts delivery and stale deployment practices
The advent of the cloud has brought deep and significant changes, including overturning the way to host, deliver, and start up software.
One of the major changes that can be attributed to the advent of the cloud is the conceptual advance it brought by breaking the barrier between hardware and software. All our media, emails, and the digits of our bank accounts are spread across thousands of servers controlled by hundreds of companies. This is even more impressive if we consider that, not even 20 years ago, the internet was in its inception stages, and only used by early adopters or academics that knew how to search a directory or operate an FTP file.
In a sense, the cloud is the natural result of the stars aligning and all the right conditions being met. If we look back, we can see how the success of the cloud was thanks to the wider adoption of broadband internet, the higher penetration rate of smartphones, allowing constant internet connectivity, and all the other innovations that made data centers easier to build and maintain. This is one of the rare instances where enterprise and consumer innovation seem to be advancing at a comparable pace. From a consumer angle, we can already see how physical storage will soon be unnecessary thanks to the internet, while for business needs, we now find offerings that allow us to run computing tasks on third-party servers – even for free.
In the perennial pursuit of flexibility, many enterprises are now moving their technologies to the cloud because of the scalability and affordability it brings. Being flexible can arguably be interpreted as being adaptable, which is exactly what executives would be after to be able to respond to industry or broader market changes. Plus, it opens the door for startups to sell their product and services directly on the cloud. It also allows them to build, manage, and deploy their applications anywhere with freedom and flexibility.
Considering the significant potential opportunities offered by the cloud, some organizations have already started to adopt a cloud-first strategy, which simply means including or moving to a cloud-based solution at the expense of a strategy built around in-house data centers. This new IT trend is going to move the databases to the cloud as a Database-as-a-Service (DBaaS).
Considering the numerous and significant changes and requirements that businesses and services face in their quest for digital transformation, to keep up the pace with their relative industries, we can easily understand the drive behind companies' motivation to change the way they store, query, and manage data from their databases. The following diagram shows how databases are used to store, query, and manage data:
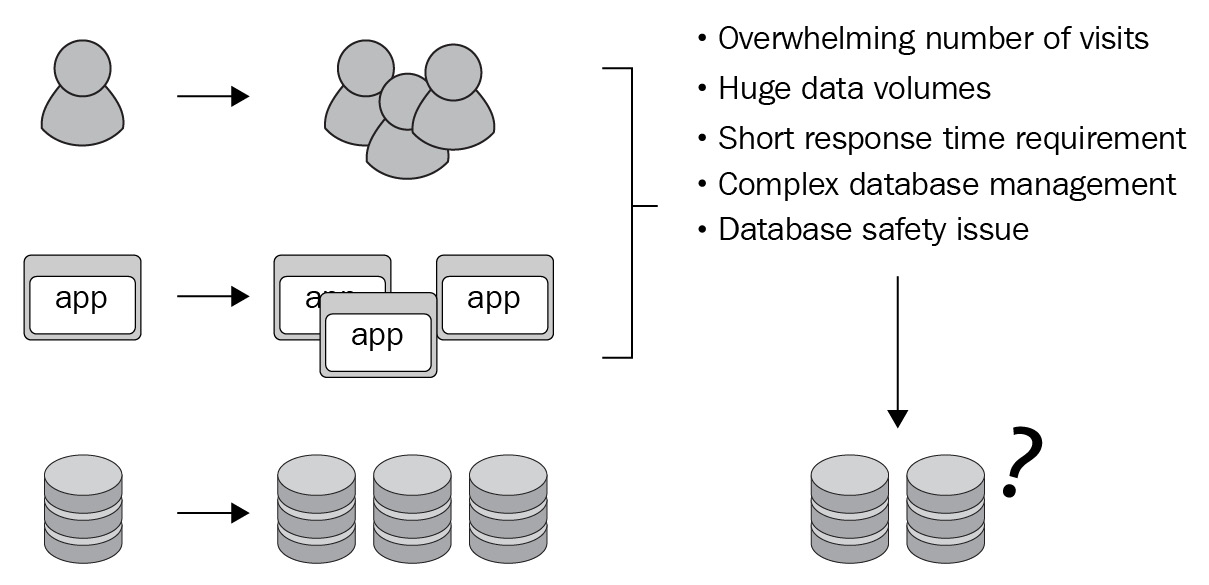
Figure 1.1 – Database challenges flow
As you can see, the databases on the right are marked with a question mark. This represents two things: what are the possibilities, and what are the directions that you can undertake in your role as a database professional to be prepared for them?
In the next section, you will be introduced to the opportunities and future directions that you should be aware of when it comes to databases. Not only can they give you an advantage in your profession, but they can also help you chart your career if you keep them in mind when it's time to make decisions about your professional development.
The opportunities and future directions for DBMSs
Let's review the opportunities, as well as future directions, that DBMSs are headed in. In the next few subsections, you will encounter topics ranging from database security to industry novelties such as DBaaS.
Database safety
Database safety has been one of the key focus areas for DBMSs. On the one hand, database vendors strive to deliver and iterate on existing solutions to solve database issues.
Cloud vendors are committed to protecting the data and applications that exist in the cloud infrastructure. The internet, software, load balancers, and all the components of the data transmission flow are seeing their safety measures being upgraded one by one.
Considering this ongoing improvement process, the natural question that arises is this: how can we achieve the seamless integration that's needed between the projects that are developed in different languages and various databases?
To answer this question and the necessary challenges that come with dealing with such important questions, we are seeing an increasingly significant number of resources being dedicated to both leading enterprises and promising new start-up ventures.
More than two-thirds of CIOs are concerned about the constraints that could emerge because of cloud providers. It is for these reasons that open source databases are becoming the go-to solution.
Data security has not only become paramount for enterprises but can be the determinant between survival or being forgotten forever as another firm that went out of business. If you think about ransomware and how it is increasingly widespread, you may be able to understand how open source technology empowers organizations to defend themselves against such risks. Open source allows organizations to be in total control of their security needs by giving them complete access to source code, as well as the flexibility that comes with being able to configure and extend the software as they see fit.
There is certainly a counter-argument to the criticism about the security of open source that was prevalent years ago. Rapid adoption by enterprises seems to be settling the argument in favor of open source. No company will remain untouched by the power of open source database progress.
SQL, NoSQL, and NewSQL
When SQL is brought up in a conversation, people immediately think about the good old relational database, which has been supporting higher-level services for the past couple of decades.
Unfortunately, the relational database has since started to show its age and is now considered by many as not adequate to meet the new requirements that businesses must nowadays respond to. This has caused industry giants in the database field to take aggressive actions to reshape their product offerings or deliver new solutions.
NoSQL is one such example. It was the initiator of the non-relational database, which provides a mechanism for storing and retrieving data modeled in a non-relational fashion, such as key-value pairs, graphs, documents, or wide columns. Nevertheless, many NoSQL products compromise consistency in favor of availability and partition tolerance. Without transaction and SQL's standard advantages, NoSQL databases gain the high availability and elastic scale-out that's necessary to respond to the vital concerns of the new era. The success of Couchbase, HBase, MongoDB, and others all stand as clear evidence in support of this thesis. NoSQL databases also sometimes emphasize that they are Not Only SQL and that they do recognize the value of the traditional SQL database. This type of appreciation has led to NoSQL databases gradually adopting some of the benefits of mainstream SQL products.
NewSQL can be defined as a type of relational database management system (RDBMS) looking to make NoSQL systems scalable for online transaction processing (OLTP) tasks, all while keeping the ACID qualities of a traditional database system.
The discussion is still ongoing both in academia and in the industry, with the definition being regarded as fluid and evolving. An excellent resource is the paper What's Really New with NewSQL? (https://dl.acm.org/doi/10.1145/3003665.3003674https://dl.acm.org/doi/10.1145/3003665.3003674), which set out to categorize the databases according to their architecture and functions.
All the databases shouting out they are one of the NewSQL products are seeking a nice balance between capability, availability, and partition tolerance (CAP theorem). But which products belong to NewSQL?
New architecture
Among the opportunities for DBMSs that are currently available and stated to bring significant changes to the industry in the short to medium term, new database architectures certainly merit consideration. This is where databases are effectively designed from an entirely new code base, thus leaving behind any of the architectural baggage of legacy systems – a clean slate of sorts that allows for near endless possibilities, as new databases are being conceptualized and built to meet the needs of the new era.
Embracing a transparent sharding middleware
A transparent sharding middleware splits a database into multiple shards that are stored across a cluster of a single-node DBMS instance, just as Apache ShardingSphere does. Sharding middleware exists to allow a user – or in this case, an organization – to split a database into multiple shards to be stored across multiple single-node DBMS instances, such as Apache ShardingSphere. This section will help you understand what data sharding is. Database administrators are constantly looking for ways to optimize their database management systems. When data input spikes, you must have strategies in place to handle it. One of the best techniques for this is to split the data into separate rows and columns, and such examples include data sharding or partitioning. The following sections will introduce you to, or refresh, these concepts and the difference between them.
Data sharding
When a large database table is split into multiple small tables, shards are created. The newly created tables are called shards or partitions. These shards are stored across multiple nodes to work efficiently, improving scalability and performance. This type of scalability is known as horizontal scalability. Sharding eventually helps database administrators such as yourself utilize computing resources in the most efficient way possible and is collectively known as database optimization.
Optimizing computing resources is one key benefit. More critical is that the network can scan fewer rows and respond to queries on the user side much faster than going through one colossal database.
Data partitioning
When we talk about partitioning, it may sound confusing. The reason for your potential confusion is completely normal as data partitioning is often mistakenly thought about when it comes to data sharding.
Partitioning refers to a database that has been broken down into different subsets but is still stored within a single database. This single database is sometimes referred to as the database instance. So what is the difference between sharding and partitioning? Both sharding and partitioning include breaking large data sets into smaller ones. But a key difference is that sharding implies that the breakdown of data is spread across multiple computers, either as horizontal partitioning or vertical.
Database-as-a-Service
The DBaaS providers not only provide the remodeled cloud databases but are responsible for maintaining their physical configuration as well. Users do not need to care about where the database is located; the cloud allows the cloud database providers to take care of the physical databases' maintenance and related operations.
NoSQL and NewSQL are unavoidable opportunities, towards which most if not all database vendors are moving and represent the future of DBMSs. Many startups are moving into this space to fill this market gap and deliver services that directly complete with the ones provided by established industry giants.
AI database management platform
The technological developments of the last 10 years are allowing advances in nascent fields such as machine learning (ML) and artificial intelligence (AI). Such technologies will eventually impact all aspects of our lives, and enterprises and their databases are no different.
AI database operation and maintenance are poised to become the main growth drivers for the future of DBMSs. The relationship between AI and databases may not seem to be evident at first; while AI has become a sort of buzzword these days, database management has remained automatic, platform-based, and observed while requiring intensive human interaction.
When AI technology is eventually integrated into databases' operation and maintenance work, new avenues will be opened. The historical experience of the previous operations that were performed during database management tasks will be machine-learned, and databases empowered by AI will be able to provide suggestions and specific actions to manage, operate, maintain, and protect database clusters.
Furthermore, AI database management platforms will also be able to contact the monitoring and warning system, or even undertake some pressing operations to avoid significant production accidents. Productivity improvement and headcount optimization reduction are always central concerns of enterprises.
Database migration
When it comes to database migration, there is some good news and some bad news. In the spirit of optimism about the future, let's consider the good news first: we have new database candidates, such as all the NewSQL and NoSQL offerings that have hit the market recently.
When it comes to the bad news, it'll be necessary to be able to deliver data migration at the lowest price.
In this old-to-new process, data migration and database selection occupy an important part of peoples' minds. Many enterprises choose to stick with stale database architecture to avoid any negative effect on production and the instability that could be caused by new databases.
Additionally, legacy and complicated IT systems contribute significantly to discouraging risk-taking, and confidence in performing data migration. In such cases, many database vendors or database service companies will offer to develop new products for this bulky work and insert themselves into this market to get a piece of the billion dollars' worth pie that is the database industry.
To recap, some of the main opportunities for DBMSs in the future include database security, leveraging new database architectures, considering embracing data sharding or DBaaS, and fully mastering database migration.
Before moving on to the next section, there is one last thing you have probably already thought of at some point in your career. There are still concerns during this old-to-new-database transition period, such as the following:
- On-premises versus the cloud
- The lowest cost to migrate data to new databases
- Increased program refactoring work costs caused by using multiple databases
The following diagram illustrates an example of the costs that may be incurred while transitioning from an old to a new database:
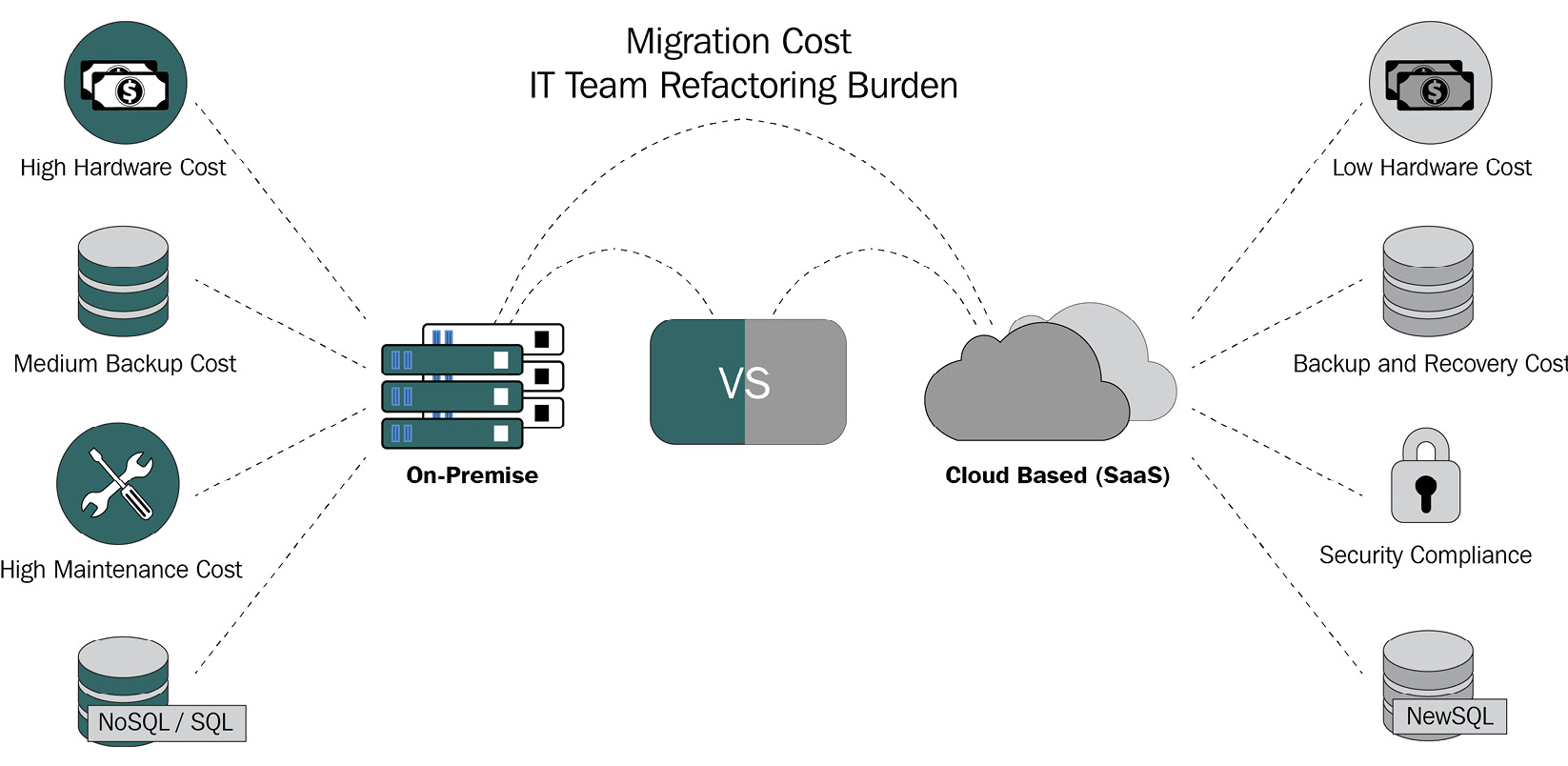
Figure 1.2 – Old-to-new database transition cost
Solving these challenges is not a small feat by any means. There is a multitude of tools and ways that you or an enterprise could employ. The truth is that for most of these solutions, you'd be expected to spend considerable amounts of time and financial resources to succeed as they'd require completely switching database type or vendor, reconfiguring your whole system, or worse, developing custom patches for the databases. Let's not forget that all of these involve risks, such as losing all of your data in the process.
It is for these reasons that we have thought of Apache ShardingSphere. It has been built to be as flexible and unintrusive as possible to make your life easier. You could set it up quickly without having to disturb anything in your system, answer all of the previously mentioned challenges, and set yourself up to be ready for the future developments mentioned in this chapter as well. The next section will give you an introductory overview of what Apache ShardingSphere is and its main concept.
Understanding Apache ShardingSphere
A unified data service platform is the best solution to the bottleneck issues of a peer-to-peer data service model. Apache ShardingSphere is an independent database middleware platform with a supportive ecosystem, positioned as Database Plus, to build a criterion and ecosystem above multi-model databases. The three key elements of Apache ShardingSphere are connect, enhance, and pluggable. We will discuss these concepts in detail in the following sections.
Connect
The basic feature of Apache ShardingSphere is to make it incredibly easy to connect data and applications. Instead of creating a new API to build an entirely new database standard, it chooses to pursue compatibility with existing databases, making you feel as if nothing has changed in your interaction with and among the various original databases.
Its unified database access entry, known as database gateway, enables Apache ShardingSphere to simulate target databases and transparently access databases and their peripheral ecosystems, such as application SDKs, command-line tools, GUIs, monitoring systems, and more. ShardingSphere currently supports many types of database protocols, including MySQL and PostgreSQL protocols.
Connect refers to ShardingSphere's strong database compatibility – that is, building a database-independent connection between data and applications to greatly improve enhanced features.
Enhance
To only connect without including additional service features can already be considered an implementation plan – good or bad as it may be. The result would, in nature, be equivalent to directly connecting databases. Such a plan not only increases network costs but damages performance as well, not to mention the low value you'd get from it.
The primary feature of Apache ShardingSphere is to capture database access entry and provide additional features transparently, such as redirect (sharding, read/write splitting, and shadow databases), transform (data encrypting and masking), authentication (security, auditing, and authority), and governance (circuit breaker, access limitation and analysis, QoS, and observability).
The ongoing trend of database fragmentation makes it impossible to centralize the management of all database features. The additional features of Apache ShardingSphere neither target a single database, nor make up for the shortages of database features; instead, they get rid of the shackle of databases simply serving as storage and give unified services that answer DBMSs' concerns.
Pluggable
The progressive addition of new features has expanded Apache ShardingSphere throughout its development history. To avoid creating a steep learning curve that could discourage prospective new users and developers from integrating Apache ShardingSphere into their database environment, Apache ShardingSphere chose to pursue and ultimately adopt a fully pluggable architecture.
The core value of the ShardingSphere project is not the number of different database access and functions, but its developer-oriented and highly extensible pluggable architecture.
As a developer, you are allowed to create custom features without having to modify the source code of Apache ShardingSphere.
The pluggable architecture of Apache ShardingSphere adopts a microkernel and a three-layer pluggable mode. Apache ShardingSphere's architecture is directed toward top-level APIs, so the kernel cannot be aware of the existence of specific functions. If you don't need a function, all you have to do is delete the dependency – it'll have zero impact on the system.
The following diagram shows how ShardingSphere is built:
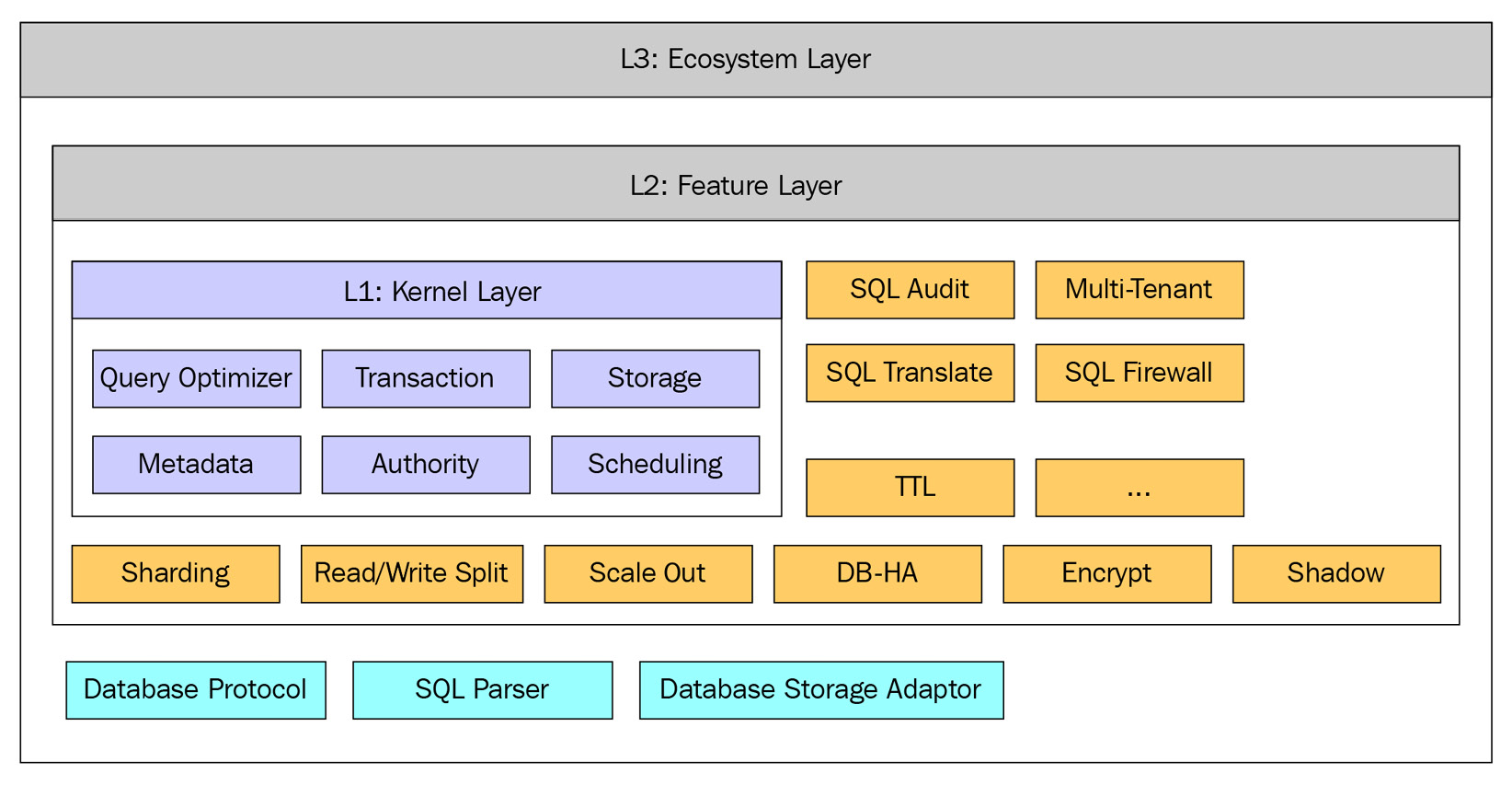
Figure 1.3 – The Apache ShardingSphere ecosystem
As you can see, the three layers are fully independent. Being focused on a plugin-oriented design means that the kernel and feature components fully support ShardingSphere's extensibility, allowing you to build a ShardingSphere instance without it affecting your overall experience if you were to drop (choose to not install) some feature modules, for example.
The architectural possibilities at your disposal
Database middleware requires two things: a driver to access the database and an independent proxy. Since no adaptor of an architecture model is flawless, Apache ShardingSphere chose to develop multiple adaptors.
ShardingSphere-JDBC and ShardingSphere-Proxy are two independent products, but you can choose what we interchangeably refer to as the hybrid model or mixed deployment, and deploy them together. They both provide dozens of enhanced features that see databases as storage nodes that apply to scenarios such as Java isomorphism, heterogeneous languages, cloud-native, and more.
ShardingSphere-JDBC
Being the predecessor and eventually the first client of the Apache ShardingSphere ecosystem, ShardingSphere-JDBC is a lightweight Java framework that provides extra services at the Java JDBC layer. ShardingSphere-JDBC's flexibility will be very helpful to you for the following reasons:
- It applies to any ORM framework based on JDBC, such as JPA, Hibernate, Mybatis, and Spring JDBC Template. It can also be used directly with JDBC.
- It supports any third-party database connection pool, such as DBCP, C3P0, BoneCP, and HikariCP.
- It supports any database that meets JDBC's standards. Currently, ShardingSphere JDBC supports MySQL, PostgreSQL, Oracle, SQLServer, and any other databases that support JDBC access.
You have probably recognized many of the databases and ORM frameworks mentioned in the previous list, but what about ShardingSphere-Proxy's support? The next section will quickly introduce you to the proxy.
ShardingSphere-Proxy
ShardingSphere-Proxy was the second client to join the Apache ShardingSphere ecosystem. A transparent database proxy, ShardingSphere-Proxy provides a database server that encapsulates the database binary protocol to support heterogeneous languages. The proxy is as follows:
- Transparent to applications; it can be used directly as MySQL/PostgreSQL.
- Applicable to any kind of client that is compatible with the MySQL/PostgreSQL protocol.
The following diagram illustrates ShardingSphere-Proxy's topography:
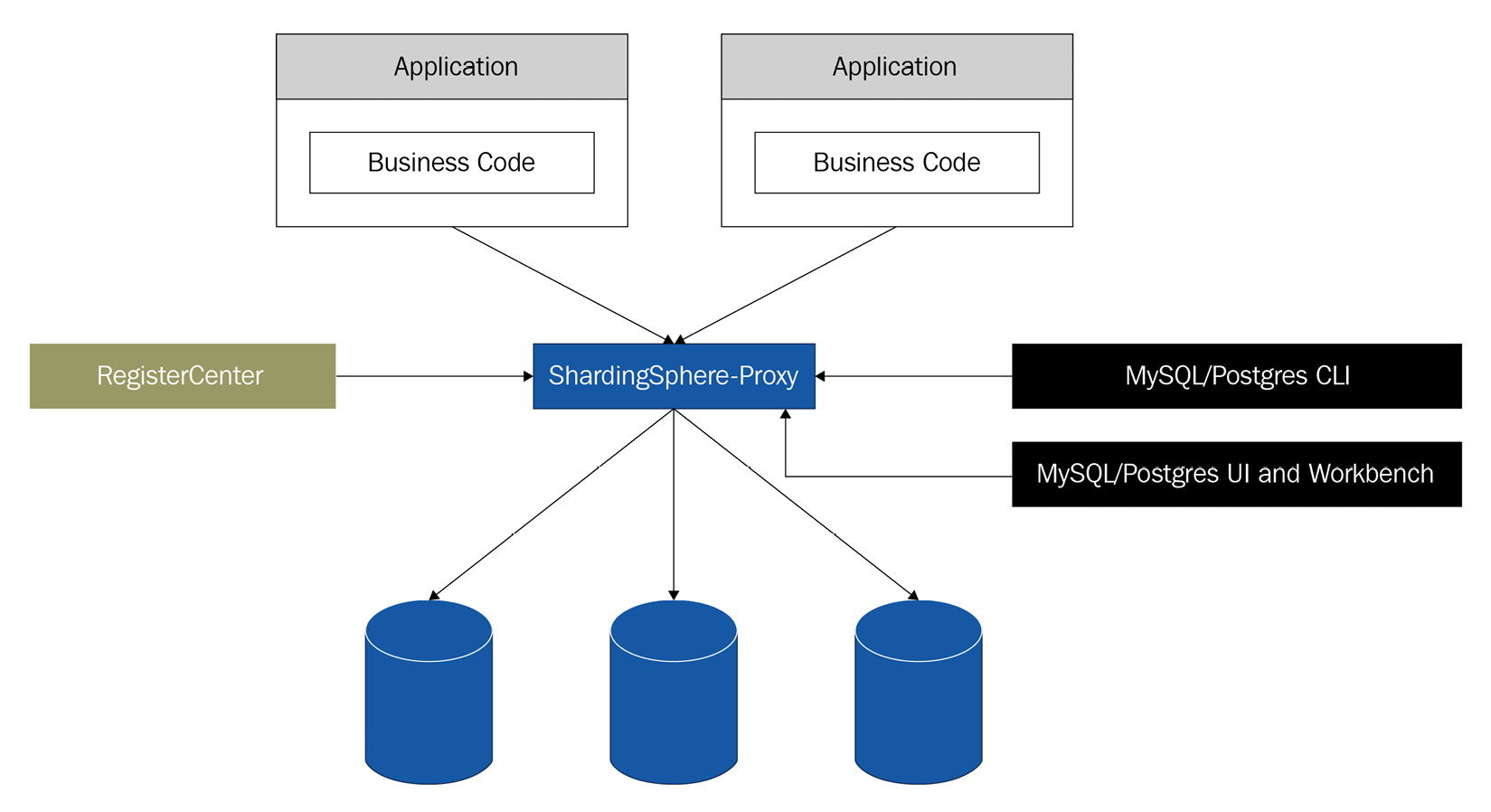
Figure 1.4 – ShardingSphere-Proxy's topography
As you can see, ShardingSphere-Proxy is not intrusive and easily fits into your system, offering you great flexibility.
You may be wondering what the differences between the two clients are and how they compare. The next section will offer you a quick comparison. For a more in-depth comparison, please refer to Chapter 5, Exploring ShardingSphere Adaptors.
Comparing ShardingSphere-JDBC and ShardingSphere-Proxy
If we consider the simple database middleware projects, different access ends mean different deployment structures. But Apache ShardingSphere is the exception: it supports tons of features. So, with the increasing demand for big data computing and resources, different deployment structures have different resource allocation plans.
ShardingSphere-Proxy has a distributed computing module and can be deployed independently. It applies to applications with multidimensional data calculation, which are less sensitive to delay but consume more computing resources. For more details on the comparison between ShardingSphere-JDBC and ShardingSphere-Proxy, please refer to Chapter 5, Exploring ShardingSphere Adaptors, or https://shardingsphere.apache.org/document/current/en/overview/.
Hybrid deployment
Adopting a decentralized architecture, ShardingSphere-JDBC applies to Java-based high-performing and lightweight OLTP applications. On the other hand, ShardingSphere-Proxy provides static entry and comprehensive language support and is suitable for OLAP applications, as well as managing and operating sharding databases.
This results in a ShardingSphere ecosystem that consists of multiple endpoints. Thanks to a unified sharding strategy and the hybrid integration of ShardingSphere-JDBC and ShardingSphere-Proxy, a multi-scenario-compatible application system can be built with ShardingSphere. The following diagram introduces an example topography of a hybrid deployment including both ShardingSphere-JDBC and ShardingSphere-Proxy:
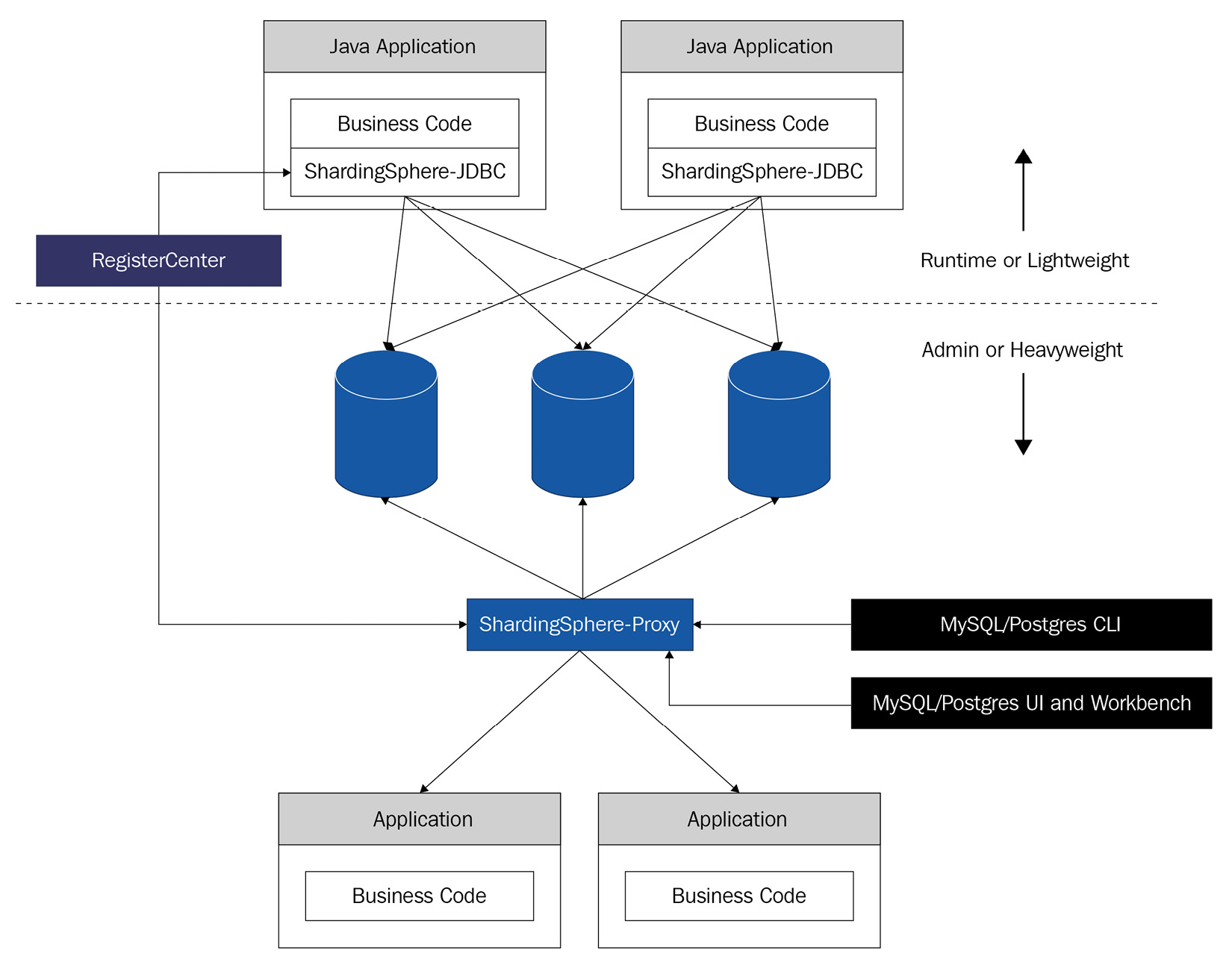
Figure 1.5 – ShardingSphere hybrid deployment topography
When you deploy ShardingSphere-JDBC and ShardingSphere-Proxy together, as shown in the preceding diagram, a hybrid computing capability will be obtained. This allows you to adjust the system architecture to optimally suit your needs.
Summary
In this chapter, you learned about the evolution of DBMSs, the industry pain points, and the new requirements presented by the industry when it comes to databases. This implies that the role of the DBA has to keep up and adapt or, if you will, evolve. If you are reading this book, you are on the right track as you're probably aware of the significant changes that are taking place in the database field and want to be ahead of the curve.
Being ahead of the curve and answering the challenges that databases are facing today has been – and is – our community's driver for developing Apache ShardingSphere. The last section of this chapter gave you a brief introduction to the ShardingSphere clients and how it is built, but this is just the beginning. You have 11 more chapters ahead of you, and by the time you complete them, you not only will master ShardingSphere – you will have acquired a new tool, expanded your skillset, and placed yourself ahead of the curve of upcoming database changes.
By the time this book is published, Apache ShardingSphere will still probably be a unique product in the industry that's aiming to achieve a blue ocean strategy by building Database Plus standards, rather than drowning in the red ocean of distributed databases. A unified database service platform is the only solution to fragmented database tech stacks. Remember, ShardingSphere was born to solve this problem and build the criteria and the ecosystem above multi-model databases.
The next chapter will start your deep dive into Apache ShardingSphere by giving you an architectural overview of the project.
