


















 Download code from GitHub
Download code from GitHub
Chapter 1: Introduction to Azure Databricks
Modern information systems work with massive amounts of data, with a constant flow that increases every day at an exponential rate. This flow comes from different sources, including sales information, transactional data, social media, and more. Organizations have to work with this information in processes that include transformation and aggregation to develop applications that seek to extract value from this data.
Apache Spark was developed to process this massive amount of data. Azure Databricks is built on top of Apache Spark, abstracting most of the complexities of implementing it, and with all the benefits that come with integration with other Azure services. This book aims to provide an introduction to Azure Databricks and explore the applications it has in modern data pipelines to transform, visualize, and extract insights from large amounts of data in a distributed computation environment.
In this introductory chapter, we will explore these topics:
- Introducing Apache Spark
- Introducing Azure Databricks
- Discovering core concepts and terminology
- Interacting with the Azure Databricks workspace
- Using Azure Databricks notebooks
- Exploring data management
- Exploring computation management
- Exploring authentication and authorization
These concepts will help us to later understand all of the aspects of the execution of our jobs in Azure Databricks and to move easily between all its assets.
Technical requirements
To understand the topics presented in this book, you must be familiar with data science and data engineering terms, and have a good understanding of Python, which is the main programming language used in this book, although we will also use SQL to make queries on views and tables.
In terms of the resources required, to execute the steps in this section and those presented in this book, you will require an Azure account as well as an active subscription. Bear in mind that this is a service that is paid, so you will have to introduce your credit card details to create an account. When you create a new account, you will receive a certain amount of free credit, but there are certain options that are limited to premium users. Always remember to stop all the services if you are not using them.
Introducing Apache Spark
To work with the huge amount of information available to modern consumers, Apache Spark was created. It is a distributed, cluster-based computing system and a highly popular framework used for big data, with capabilities that provide speed and ease of use, and includes APIs that support the following use cases:
- Easy cluster management
- Data integration and ETL procedures
- Interactive advanced analytics
- ML and deep learning
- Real-time data processing
It can run very quickly on large datasets thanks to its in-memory processing design that allows it to run with very few read/write disk operations. It has a SQL-like interface and its object-oriented design makes it very easy to understand and write code for; it also has a large support community.
Despite its numerous benefits, Apache Spark has its limitations. These limitations include the following:
- Users need to provide a database infrastructure to store the information to work with.
- The in-memory processing feature makes it fast to run, but also implies that it has high memory requirements.
- It isn't well suited for real-time analytics.
- It has an inherent complexity with a significant learning curve.
- Because of its open source nature, it lacks dedicated training and customer support.
Let's look at the solution to these issues: Azure Databricks.
Introducing Azure Databricks
With these and other limitations in mind, Databricks was designed. It is a cloud-based platform that uses Apache Spark as a backend and builds on top of it, to add features including the following:
- Highly reliable data pipelines
- Data science at scale
- Simple data lake integration
- Built-in security
- Automatic cluster management
Built as a joint effort by Microsoft and the team that started Apache Spark, Azure Databricks also allows easy integration with other Azure products, such as Blob Storage and SQL databases, alongside AWS services, including S3 buckets. It has a dedicated support team that assists the platform's clients.
Databricks streamlines and simplifies the setup and maintenance of clusters while supporting different languages, such as Scala and Python, making it easy for developers to create ETL pipelines. It also allows data teams to have real-time, cross-functional collaboration thanks to its notebook-like integrated workspace, while keeping a significant amount of backend services managed by Azure Databricks. Notebooks can be used to create jobs that can later be scheduled, meaning that locally developed notebooks can be deployed to production easily. Other features that make Azure Databricks a great tool for any data team include the following:
- A high-speed connection to all Azure resources, such as storage accounts.
- Clusters scale and are terminated automatically according to use.
- The optimization of SQL.
- Integration with BI tools such as Power BI and Tableau.
Let's examine the architecture of Databricks next.
Examining the architecture of Databricks
Each Databricks cluster is a Databricks application composed of a set of pre-configured, VMs running as Azure resources managed as a single group. You can specify the number and type of VMs that it will use while Databricks manages other parameters in the backend. The managed resource group is deployed and populated with a virtual network called VNet, a security group that manages the permissions of the resources, and a storage account that will be used, among other things, as the Databricks filesystem. Once everything is deployed, users can manage these clusters through the Azure Databricks UI. All the metadata used is stored in a geo-replicated and fault-tolerant Azure database. This can all be seen in Figure 1.1:
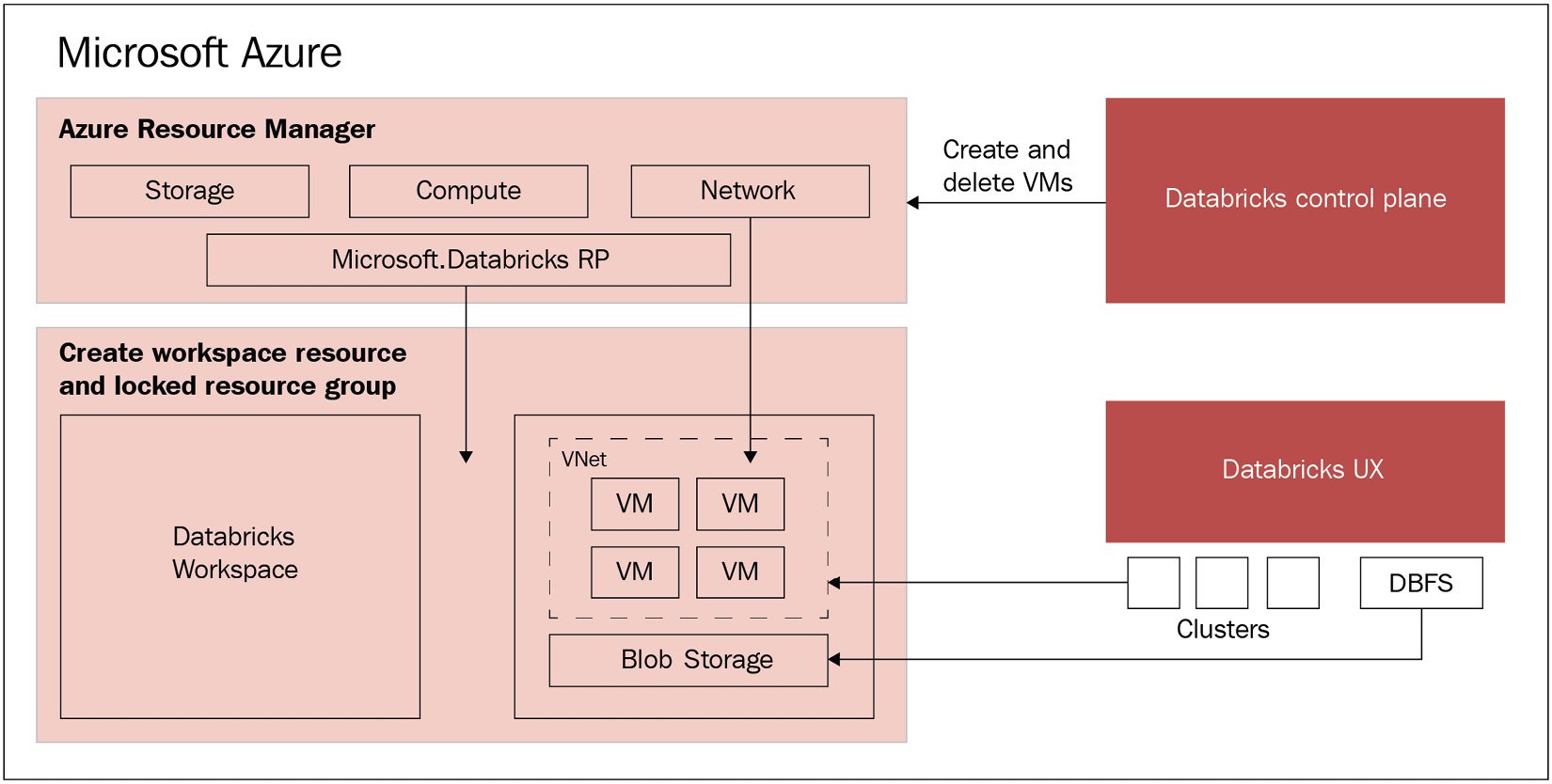
Figure 1.1 – Databricks architecture
The immediate benefit this architecture gives to users is that there is a seamless connection with Azure, allowing them to easily connect Azure Databricks to any resource within the same Azure account and have a centrally managed Databricks from the Azure control center with no additional setup.
As mentioned previously, Azure Databricks is a managed application on the Azure cloud that is composed by a control plane and a data plane. The control plane is on the Azure cloud and hosts services such as cluster management and jobs services. The data plane is a component that includes the aforementioned VNet, NSG, and the storage account that is known as DBFS.
You could also deploy the data plane in a customer-managed VNet to allow data engineering teams to build and secure the network architecture according to their organization policies. This is called VNet injection.
Now that we have seen how everything is laid out under the hood, let's discuss some of the core concepts behind Databricks.
Discovering core concepts and terminology
Before diving into the specifics of how to create our cluster and start working with Databricks, there are a certain number of concepts with which we must familiarize ourselves first. Together, these define the fundamental tools that Databricks provides to the user and are available both in the web application UI as well as the REST API:
- Workspaces: An Azure Databricks workspace is an environment where the user can access all of their assets: jobs, notebooks, clusters, libraries, data, and models. Everything is organized into folders and this allows the user to save notebooks and libraries and share them with other users to collaborate. The workspace is used to store notebooks and libraries, but not to connect or store data.
- Data: Data can be imported into the mounted Azure Databricks distributed filesystem from a variety of sources. This can be uploaded as tables directly into the workspace, from Azure Blob Storage or AWS S3.
- Notebooks: Databricks notebooks are very similar to Jupyter notebooks in Python. They are web interface applications that are designed to run code thanks to runnable cells that operate on files and tables, and that also provide visualizations and contain narrative text. The end result is a document with code, visualizations, and clear text documentation that can be easily shared. Notebooks are one of the two ways that we can run code in Azure Databricks. The other way is through jobs. Notebooks have a set of cells that allow the user to execute commands and can hold code in languages such as Scala, Python, R, SQL, or Markdown. To be able to execute commands, they have to be connected to a cluster, but this connection is not necessarily permanent. This allows an easy way to share these notebooks via the web or in a local machine. Notebooks can be scheduled and triggered as jobs to create a data pipeline, run ML models, or update dashboards:
Figure 1.2 – Azure Databricks notebook. Source: https://databricks.com/wp-content/uploads/2015/10/notebook-example.png
- Clusters: A cluster is a set of connected servers that work together collaboratively as if they are a single (much more powerful) computer. In this environment, you can perform tasks and execute code from notebooks working with data stored in a certain storage facility or uploaded as a table. These clusters have the means to manage and control who can access each one of them. Clusters are used to improve performance and availability compared to a single server, while typically being more cost-effective than a single server of comparable speed or availability. It is in the clusters where we run our data science jobs, ETL pipelines, analytics, and more.
There is a distinction between all-purpose clusters and job clusters. All-purpose clusters are where we work collaboratively and interactively using notebooks, but job clusters are where we execute automatic and more concrete jobs. The way of creating these clusters differs depending on whether it is an all-purpose cluster or a job cluster. The former can be created using the UI, CLI, or REST API, while the latter is created using the job scheduler to run a specific job and is terminated when this is done.
- Jobs: Jobs are the tasks that we run when executing a notebook, JAR, or Python file in a certain cluster. The execution can be created and scheduled manually or by the REST API.
- Apps: Third-party apps such as Table can be used inside Azure Databricks. These integrations are called apps.
- Apache SparkContext/environments: Apache SparkContext is the main application in Apache Spark running internal services and connecting to the Spark execution environment. While, historically, Apache Spark has had two core contexts available to the user (SparkContext and SQLContext), in the 2.X versions, there is just one – the SparkSession.
- Dashboards: Dashboards are a way to display the output of the cells of a notebook without the code that is required to generate them. They can be created from notebooks:
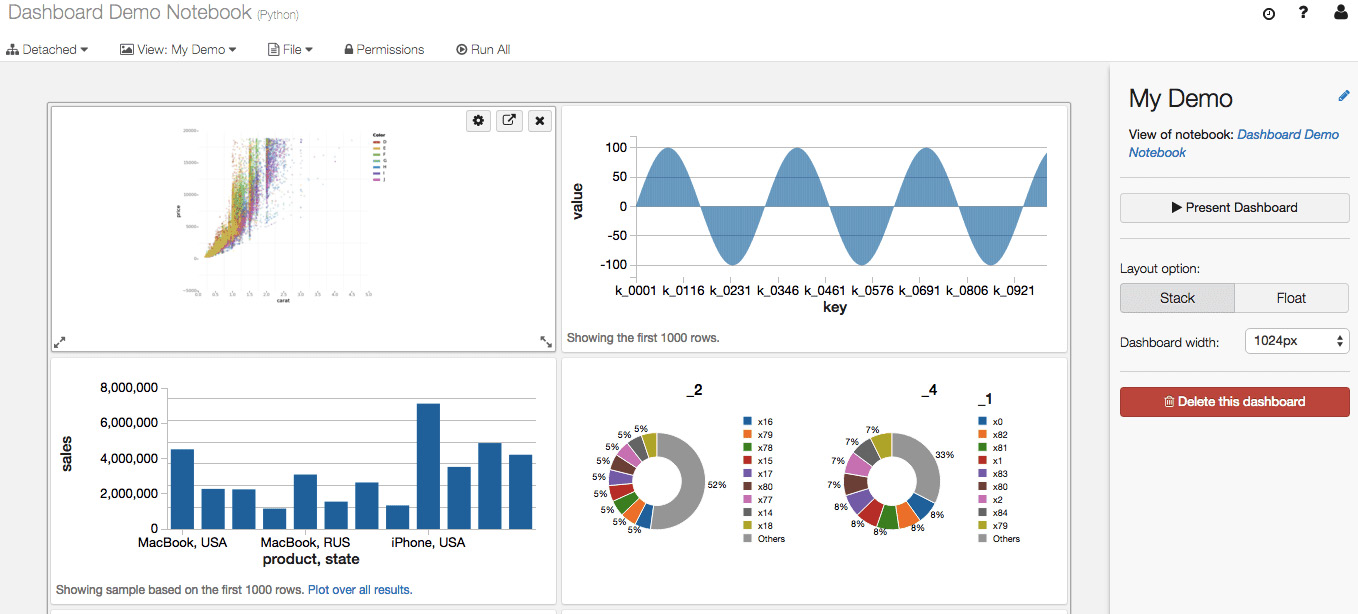
Figure 1.3 – Azure Databricks notebook. Source: https://databricks.com/wp-content/uploads/2016/02/Databricks-dashboards-screenshot.png
- Libraries: Libraries are modules that add functionality, written in Scala or Python, that can be pulled from a repository or installed via package management systems utilities such as PyPI or Maven.
- Tables: Tables are structured data that you can use for analysis or for building models that can be stored on Amazon S3 or Azure Blob Storage, or in the cluster that you're currently using cached in memory. These tables can be either global or local, the first being available across all clusters. A local table cannot be accessed from other clusters.
- Experiments: Every time we run MLflow, it belongs to a certain experiment. Experiments are the central way of organizing and controlling all the MLflow runs. In each experiment, the user can search, compare, and visualize results, as well as downloading artifacts or metadata for further analysis.
- Models: While working with ML or deep learning, the models that we train and use to infer are registered in the Azure Databricks MLflow Model Registry. MLflow is an open source platform designed to manage ML life cycles, which includes the tracking of experiments and runs, and MLflow Model Registry is a centralized model store that allows users to fully control the life cycle of MLflow models. It has features that enable us to manage versions, transition between different stages, have a chronological model heritage, and control model version annotations and descriptions.
- Azure Databricks workspace filesystem: Azure Databricks is deployed with a distributed filesystem. This system is mounted in the workspace and allows the user to mount storage objects and interact with them using filesystem paths. It allows us to persist files so the data is not lost when the cluster is terminated.
This section focused on the core pieces of Azure Databricks. In the next section, you will learn how to interact with Azure Databricks through the workspace, which is the place where we interact with our assets.
Interacting with the Azure Databricks workspace
The Azure Databricks workspace is where you can manage objects such as notebooks, libraries, and experiments. It is organized into folders and it also provides access to data, clusters, and jobs:
Figure 1.4 – Databricks workspace. Source: https://docs.microsoft.com/en-us/azure/databricks/workspace/
Access and control of a workspace and its assets can be made through the UI, CLI, or API. We will focus on using the UI.
Workspace assets
In the Azure Databricks workspace, you can manage different assets, most of which we have discussed in the terminology. These assets are as follows:
In the following sections, we will dive deeper into how to work with folders and other workspaces objects. The management of these objects is central to running our tasks in Azure Databricks.
Folders
All of our static assets within a workspace are stored in folders within the workspace. The stored assets can be notebooks, libraries, experiments, and other folders. Different icons are used to represent folders, notebooks, directories, or experiments. Click a directory to deploy the drop-down list of items:
Figure 1.5 – Workspace folders
Clicking on the drop-down arrow in the top-right corner will unfold the menu item, allowing the user to perform actions with that specific folder:
Figure 1.6 – Workspace folders drop-down menu
Special folders
The Azure Databricks workspace has three special folders that you cannot rename or move to a special folder. These special folders are as follows:
- Workspace
- Shared
- Users
Workspace root folder
The Workspace root folder is a folder that contains all of your static assets. To navigate to this folder, click the workspace or home icon and then click the go back icon:
Figure 1.7 – Workspace root folder
Within the Workspace root folder, you either select Shared or Users. The former is for sharing objects with other users that belong to your organization, and the latter contains a folder for a specific user.
By default, the Workspace root folder and all of its contents are available for all users, but you can control and manage access by enabling workspace access control and setting permissions.
User home folders
Within your organization, every user has their own directory, which will be their root directory:
Figure 1.8 – Workspace Users folder
Objects in a user folder will be private to a specific user if workspace access control is enabled. If a user's permissions are removed, they will still be able to access their home folder.
Workspace object operations
To perform an action on a workspace object, right-click the object or click the drop-down icon at the right side of an object to deploy the drop-down menu:
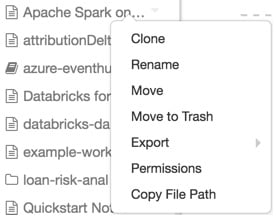
Figure 1.9 – Operations on objects in the workspace
If the object is a folder, from this menu, the user can do the following:
- Create a notebook, library, MLflow experiment, or folder.
- Import a Databricks archive.
If it is an object, the user can choose to do the following:
- Clone the object.
- Rename the object.
- Move the object to another folder.
- Move the object to Trash.
- Export a folder or notebook as a Databricks archive.
- If the object is a notebook, copy the notebook's file path.
- If you have Workspace access control enabled, set permissions on the object.
When the user deletes an object, this object goes to the Trash folder, in which everything is deleted after 30 days. Objects can be restored from the Trash folder or be eliminated permanently.
Now that you have learned how to interact with Azure Databricks assets, we can start working with Azure Databricks notebooks to manipulate data, create ETLs, ML experiments, and more.
Using Azure Databricks notebooks
In this section, we will describe the basics of working with notebooks within Azure Databricks.
Creating and managing notebooks
There are different ways to interact with notebooks in Azure Databricks. We can either access them through the UI using CLI commands, or by means of the workspace API. We will focus on the UI for now:
- By clicking on the Workspace or Home button in the sidebar, select the drop-down icon next to the folder in which we will create the notebook. In the Create Notebook dialog, we will choose a name for the notebook and select the default language:

Figure 1.10 – Creating a new notebook
- Running clusters will show notebooks attached to them. We can select one of them to attach the new notebook to; otherwise, we can attach it once the notebook has been created in a specific location.
- To open a notebook, in your workspace, click on the icon corresponding to the notebook you want to open. The notebook path will be displayed when you hover over the notebook title.
Note
If you have an Azure Databricks Premium plan, you can apply access control to the workspace assets.
External notebook formats
Azure Databricks supports several notebook formats, which can be scripts in one of the supported languages (Python, Scala, SQL, and R), HTML documents, DBC archives (Databricks native file format), IPYNB Jupyter notebooks, and R Markdown documents.
Importing a notebook
We can import notebooks into the Azure workspace by clicking in the drop-down menu and selecting Import. After this, we can specify either a file or a URL that contains the file in one of the supported formats and then click Import:
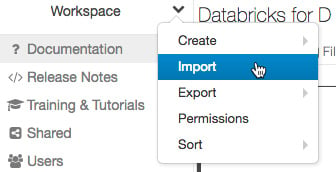
Figure 1.11 – Importing a notebook into the workspace
Exporting a notebook
You can export a notebook in one of the supported file formats by clicking on the File button in the notebook toolbar and then selecting Export. Bear in mind that the results of each cell will be included if you have not cleared them.
Notebooks and clusters
To be able to work, a notebook needs to be attached to a running cluster. We will now learn about how notebooks connect to the clusters and how to manage these executions.
Execution contexts
When a notebook is attached to a cluster, a read-eval-print-loop (REPL) environment is created. This environment is specific to each one of the supported languages and is contained in an execution context.
There is a limit of 145 execution contexts running in a single cluster. Once that number is reached, you cannot attach any more notebooks to that cluster or create a new execution context.
Idle execution contexts
If an execution context has passed a certain time threshold without any executions, it is considered idle and automatically detached from the notebook. This threshold is, by default, 25 hours.
One thing to consider is that when a cluster reaches its maximum context limit, Azure Databricks will remove the least recently used idle execution contexts. This is called an eviction.
If a notebook gets evicted from the cluster it was attached to, the UI will display a message:

Figure 1.12 – Detached notebook notification
We can configure this behavior when creating the cluster or we can disable it by setting the following:
spark.databricks.chauffeur.enableIdleContextTracking false
Attaching a notebook to a cluster
Notebooks are attached to a cluster by selecting one from the drop-down menu in the notebook toolbar.
A notebook attached to a running cluster has the following Spark environment variables by default:
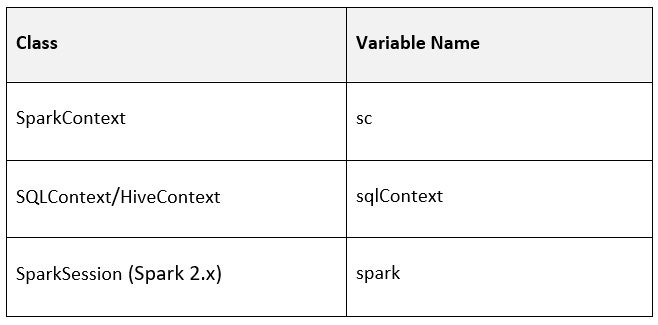
Figure 1.13 – A table showing Spark environment variables
We can check the Spark version running in the cluster where the notebook is attached by running the following Python code in one of the cells:
spark.version
We can also see the current Databricks runtime version with the following command:
spark.conf.get("spark.databricks.clusterUsageTags.sparkVersion")
These properties are required by the Clusters and Jobs APIs to communicate between themselves.
On the cluster details page, the Notebooks tab will show all the notebooks attached to the cluster, as well as the status and the last time it was used:
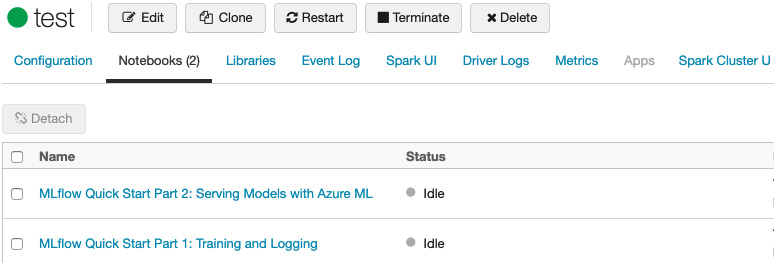
Figure 1.14 – Notebooks attached to a cluster
Attaching a notebook to a cluster is necessary in order to make them work; otherwise, we won't be able to execute the code in it.
Notebooks are detached from a cluster by clicking in the currently attached cluster and selecting Detach:
Figure 1.15 – Detaching a notebook from a cluster
This causes the cluster to lose all the values stored as variables in that notebook. It is good practice to always detach the notebooks from the cluster once we have finished working on them. This prevents the autostopping of running clusters, in case there is a process running in the notebook (which could cause undesired costs).
Scheduling a notebook
As mentioned before, notebooks can be scheduled to be executed periodically. To schedule a notebook job to run periodically, click the Schedule button at the top right of the notebook toolbar.
A notebook's core functionalities
Now, we'll look at how you can use a notebook.
Notebook toolbar
Notebooks have a toolbar that contains information on the cluster to which it is attached, and to perform actions such as exporting the notebook or changing the predefined language (depending on the Databricks runtime version):

Figure 1.16 – Notebook toolbar
This toolbar helps us to navigate the general options in our notebook and makes it easier to manage how we interact with the computation cluster.
Cells
Cells have code that can be executed:
Figure 1.17 – Execution cells
At the top-left corner of a cell, in the cell actions, you have the following options: Run this cell, Dashboard, Edit, Hide, and Delete:
- You can use the Undo keyboard shortcut to restore a deleted cell by selecting Undo Delete Cell from Edit.
- Cells can be cut using cell actions or the Cut keyboard shortcut.
- Cells are added by clicking on the Plus icon at the bottom of each cell or by selecting Add Cell Above or Add Cell Below from the cell menu in the notebook toolbar.
Running cells
Specific cells can be run from the cell actions toolbar. To run several cells, we can choose between Run all, all above, or all below. We can also select Run All, Run All Above, or Run All Below from the Run option in the notebook toolbar. Bear in mind that Run All Below includes the cells you are currently in.
Default language
The default language for each notebook is shown in parentheses next to the notebook name, which, in the following example, is SQL:

Figure 1.18 – Cell default language
If you click the name of the language in parentheses, you will be prompted by a dialog box in which you can change the default language of the notebook:
Figure 1.19 – Changing the default language of a cell
When the default language is changed, magic commands will be added to the cells that are not in the new default language in order to keep them working.
The language can also be specified in each cell by using the magic commands. Four magic commands are supported for language specification: %python, %r, %scala, and %sql.
There are also other magic commands such as %sh, which allows you to run shell code; %fs to use dbutils filesystem commands; and %md to specify Markdown, for including comments and documentation. We will look at this in a bit more detail.
Including documentation
Markdown is a lightweight markup language with plain text-formatting syntax, often used for formatting readme files, which allows the creation of rich text using plain text.
As we have seen before, Azure Databricks allows Markdown to be used for documentation by using the %md magic command. The markup is then rendered into HTML with the desired formatting. For example, the next code is used to format text as a title:
%md # Hello This is a Title
It is rendered as an HTML title:

Figure 1.20 – Markdown title
Documentation blocks are one of the most important features of Azure Databricks notebooks. They allow us to state the purpose of our code and how we interpret our results.
Command comments
Users can add comments to specific portions of code by highlighting it and clicking on the comment button in the bottom-right corner of the cell:

Figure 1.21 – Selecting a portion of code
This will prompt a textbox in which we can place comments to be reviewed by other users. Afterward, the commented text will be highlighted:

Figure 1.22 – Commenting on the selection
Comments allow us to propose changes or require information on specific portions of the notebook without intervening in the content.
Downloading a cell result
You can download the tabular results from a cell to your local machine by clicking on the download button at the bottom of a cell:
Figure 1.23 – Downloading full results from a cell
By default, Azure Databricks limits you to viewing 1,000 rows of a DataFrame, but if there is more data present, we can click on the drop-down icon and select Download full results to see more.
Formatting SQL
Formatting SQL code can take up a lot of time, and enforcing standards across notebooks can be difficult.
Azure Databricks has a functionality for formatting SQL code in notebook cells, so as to reduce the amount of time dedicated to formatting code, and also to help in applying the same coding standards in all notebooks. To apply automatic SQL formatting to a cell, you can select it from the cell context menu. This is only applicable to SQL code cells:
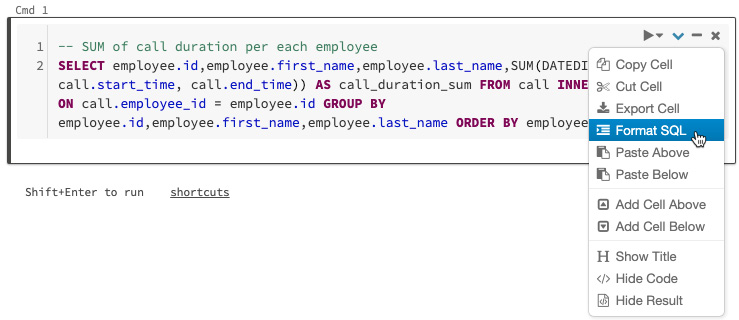
Figure 1.24 – Automatic formatting of SQL code
Applying the autoformatting of SQL code is a feature that can improve the readability of our code, and reduce possible mistakes due to bad formatting.
Exploring data management
In this section, we will dive into how to manage data in Azure Databricks in order to perform analytics, create ETL pipelines, train ML algorithms, and more. First, we will briefly describe types of data in Azure Databricks.
Databases and tables
In Azure Databricks, a database is composed of tables; table collections of structured data. Users can work with these tables, using all of the operations supported by Apache Spark DataFrames, and query tables using Spark API and Spark SQL.
These tables can be either global or local, accessible to all clusters. Global tables are stored in the Hive metastore, while local tables are not.
Tables can be populated using files in the DBFS or with data from all of the supported data sources.
Viewing databases and tables
Tables related to the cluster you are currently using can be viewed by clicking on the data icon button in the sidebar. The Databases folder will display the list of tables in each of the selected databases:
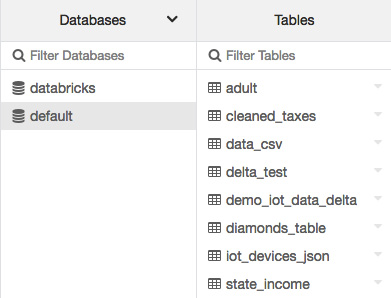
Figure 1.25 – Default tables
Users can select a different cluster by clicking on the drop-down icon at the top of the Databases folder and selecting the cluster:
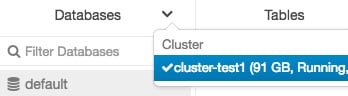
Figure 1.26 – Selecting databases in a different cluster
We can have several queries on a cluster, each with its own filesystem. This is very important when we reference data in our notebooks.
Importing data
Local files can be uploaded to the Azure Databricks filesystem using the UI.
Data can be imported into Azure Databricks DBFS to be stored in the FileStore using the UI. To do this, you can either go to the Upload Data UI and select the files to be uploaded as well as the DBFS target directory:
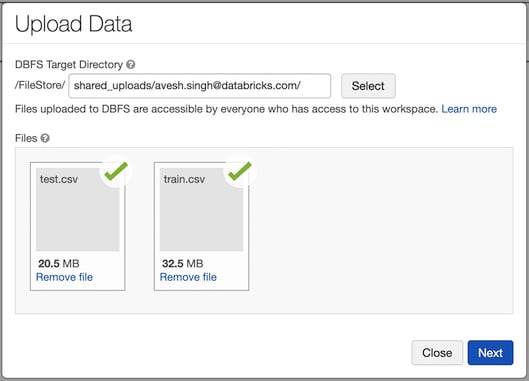
Figure 1.27 – Uploading the data UI
Another option available to you for uploading data to a table is to use the Create Table UI, accessible in the Import & Explore Data box in the workspace:
Figure 1.28 – Creating a table UI in Import & Explore Data
For production environments, it is recommended to use the DBFS CLI, DBFS API, or the Databricks filesystem utilities (dbutils.fs).
Creating a table
Users can create tables either programmatically using SQL, or via the UI, which creates global tables. By clicking on the data icon button in the sidebar, you can select Add Data in the top-right corner of the Databases and Tables display:
Figure 1.29 – Adding data to create a new table
After this, you will be prompted by a dialog box in which you can upload a file to create a new table, selecting the data source and cluster, the path to where it will be uploaded into the DBFS, and also be able to preview the table:
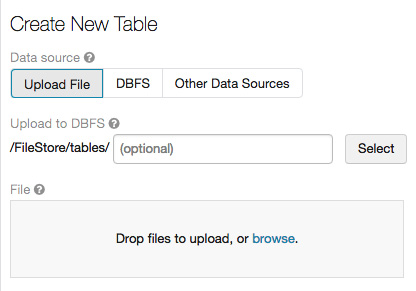
Figure 1.30 – Creating a new table UI
Creating tables through the UI or the Add data options are two of the many options that we have to ingest data into Azure Databricks.
Table details
Users can preview the contents of a table by clicking the name of the table in the Tables folder. This will show a view of the table where we can see the table schema and a sample of the data that is contained within:
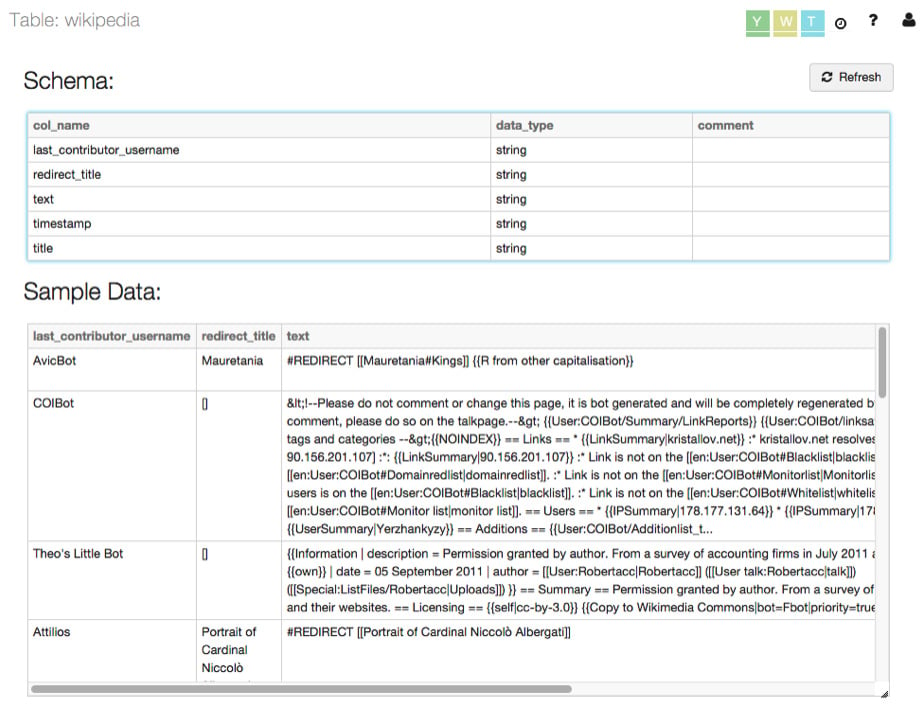
Figure 1.31 – Table details
These table details allow us to plan transformations in advance to fit data to our needs.
Exploring computation management
In this section, we will briefly describe how to manage Azure Databricks clusters, the computational backbone of all of our operations. We will describe how to display information on clusters, as well as how to edit, start, terminate, delete, and monitor logs.
Displaying clusters
To display the clusters in your workspace, click the clusters icon in the sidebar. You will see the Cluster page, which displays clusters in two tabs: All-Purpose Clusters and Job Clusters:
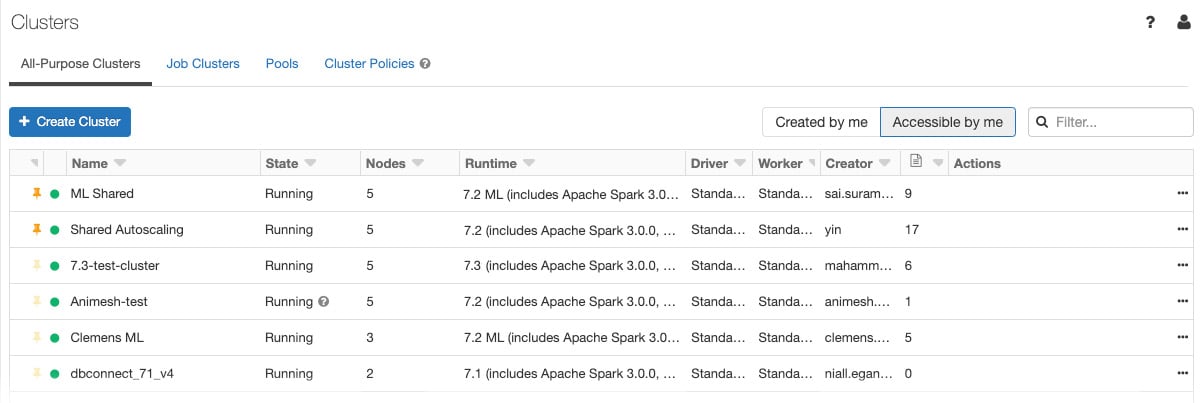
Figure 1.32 – Cluster details
On top of the common cluster information, All-Purpose Clusters displays information on the number of notebooks attached to them.
Actions such as terminate, restart, clone, permissions, and delete actions can be accessed at the far right of an all-purpose cluster:
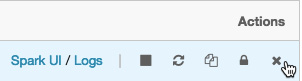
Figure 1.33 – Actions on clusters
Cluster actions allow us to quickly operate in our clusters directly from our notebooks.
Starting a cluster
Apart from creating a new cluster, you can also start a previously terminated cluster. This lets you recreate a previously terminated cluster with its original configuration. Clusters can be started from the Cluster list, on the cluster detail page of the notebook in the cluster icon attached dropdown:
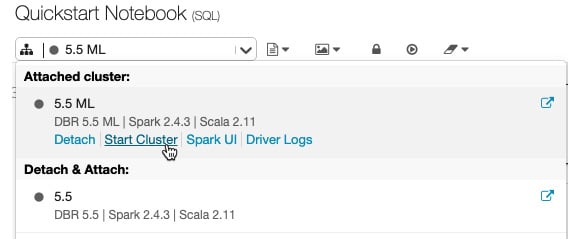
Figure 1.34 – Starting a cluster from the notebook toolbar
You also have the option of using the API to programmatically start a cluster.
Each cluster is uniquely identified and when you start a terminated cluster, Azure Databricks automatically installs libraries and reattaches notebooks to it.
Terminating a cluster
To save resources, you can terminate a cluster. The configuration of a terminated cluster is stored so that it can be reused later on.
Clusters can be terminated manually or automatically following a specified period of inactivity:
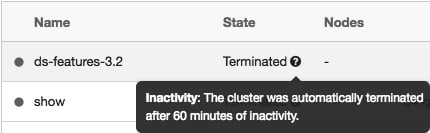
Figure 1.35 – A terminated cluster
It's good to bear in mind that inactive clusters will be terminated automatically.
Deleting a cluster
Deleting a cluster terminates the cluster and removes its configuration. Use this carefully because this action cannot be undone.
To delete a cluster, click the delete icon in the cluster actions on the Job Clusters or All-Purpose Clusters tab:

Figure 1.36 – Deleting a cluster from the Job Clusters tab
You can also invoke the permanent delete API endpoint to programmatically delete a cluster.
Cluster information
Detailed information on Spark jobs is displayed in the Spark UI, which can be accessed from the cluster list or the cluster details page. The Spark UI displays the cluster history for both active and terminated clusters:
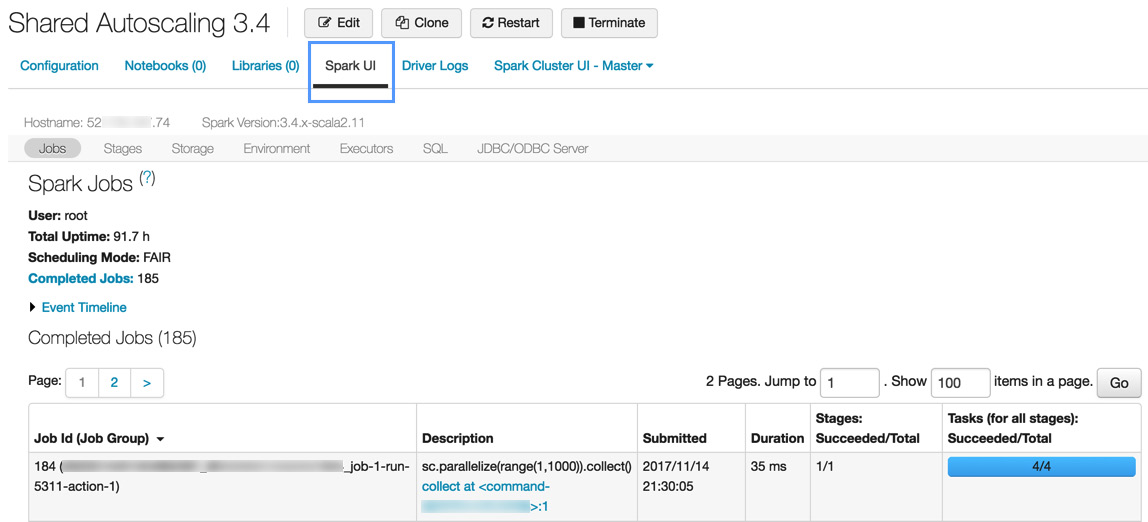
Figure 1.37 – Cluster information
Cluster information allows us to have an insight into the progress of our process and identify any possible bottlenecks that could point us to possible optimization opportunities.
Cluster logs
Azure Databricks provides three kinds of logging of cluster-related activity:
- Cluster event logs for life cycle events, such as creation, termination, or configuration edits
- Apache Spark driver and worker logs, which are generally used for debugging
- Cluster init script logs, valuable for debugging init scripts
Azure Databricks provides cluster event logs with information on life cycle events that are manually or automatically triggered, such as creation and configuration edits. There are also logs for Apache Spark drivers and workers, as well cluster init script logs.
Events are stored for 60 days, which is comparable to other data retention times in Azure Databricks.
To view a cluster event log, click on the Cluster button at the sidebar, click on the cluster name, and then finally click on the Event Log tab:
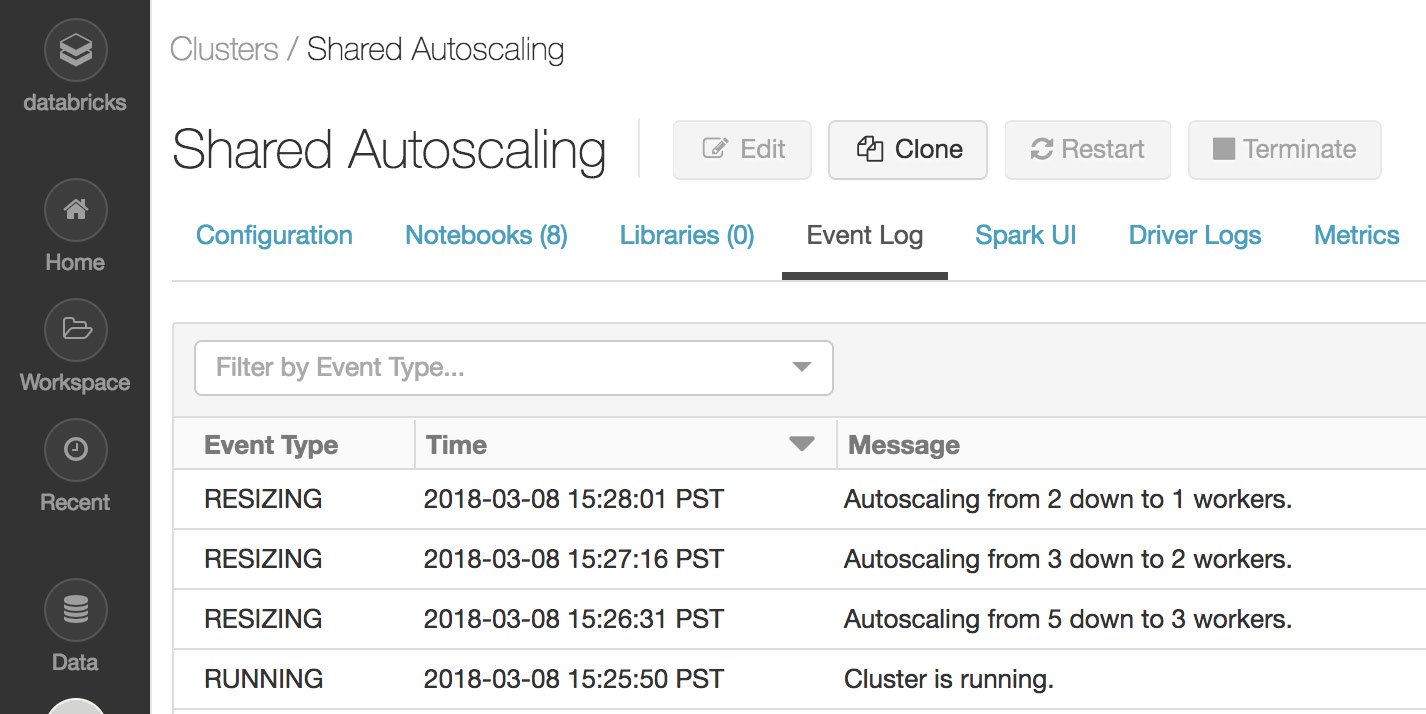
Figure 1.38 – Cluster event logs
Cluster events provide us with specific information on the actions that were taken on the cluster during the execution of our jobs.
Exploring authentication and authorization
Azure Databricks allows the user to perform access control to manage access to workspace objects, clusters, pools, and data tables. Admin users manage access control lists and also users with delegated permissions.
Clustering access control
By default, in Azure Databricks, all users can create or modify clusters. Before using cluster access control, an admin user must enable it. After this, there are two types of cluster permissions, which are as follows:
- The Allow Cluster Creation permission allows the creation of clusters.
- Cluster-level permissions allow you to manage clusters.
When cluster access control is enabled, only admins and users with Can Manage permissions can configure, create, terminate, or delete clusters.
Configuring cluster permissions
Cluster access control can be configured by clicking on the cluster button in the sidebar and, in the Actions options, selecting the Permissions button. This will prompt a permission dialog box where users can do the following:
- Apply granular access control to users and groups using the Add Users and Groups options.
- Manage granted access for users and groups.
These options are visible in Figure 1.39:
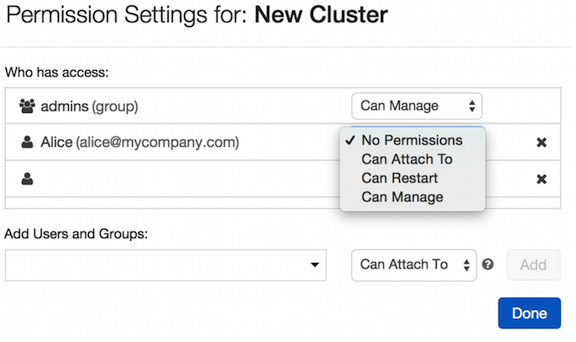
Figure 1.39 – Managing cluster permissions
Cluster permissions allow us to enforce fine-grained control over the computational resources used in our projects.
Folder permissions
Folders have five levels of permissions: No Permissions, Read, Run, Edit, and Manage. Any notebook or experiment will inherit the folder permissions that contain them.
Default folder permissions
Besides the current access control, these permissions are maintained:
- Objects in the Shared folder can be managed by anyone.
- Users can manage objects created by themselves.
When there is no workspace access control, users can only edit items in their Workspace folder.
With workspace access control enabled, the following permissions exist:
- Only admins can create items in the Workspace folder, but users can manage existing items.
- Permissions applied to a folder will be applied to the items it contains.
- Users keep having Manage permission to their home directories.
Understanding these permissions helps us to know in advance how possible changes in these policies could affect how users interact with the organization's data.
Notebook permissions
Notebooks have the same five permission levels as folders: No Permissions, Read, Run, Edit, and Manage.
Configuring notebook and folder permissions
Users can configure notebook permissions by clicking on the Permissions button in the notebook context bar. Select the folder and then click on Permissions from the drop-down menu:

Figure 1.40 – Notebook permissions
From there, you can grant permissions to users or groups as well as edit existing permissions:
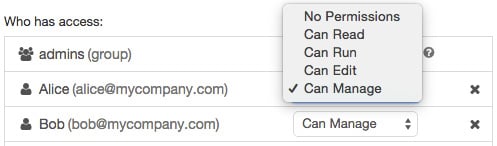
Figure 1.41 – Access control on notebooks
Access control on notebooks can easily be applied in this way by selecting one of the options from the drop-down menu.
MLflow Model permissions
You can assign six permission levels to MLflow Models registered in the MLflow Model Registry: No Permissions, Read, Edit, Manage Staging Versions, Manage Production Versions, and Manage.
Default MLflow Model permissions
Besides the current workspace access control, these permissions are maintained:
- Models in the registry can be created by anyone.
- Administrators can manage any model in the registry.
When there is no workspace access control, users can manage any of the models in the registry.
With workspace access control enabled, the following permissions exist:
- Users can manage only the models they have created.
- Only administrators can manage models created by other users.
These options are applied to MLflow Models created in Azure Databricks.
Configuring MLflow Model permissions
One thing to keep in mind is that only administrators belong to the admins with the Manage permissions group, while the rest of the users belong to the all users group.
MLflow Model permissions can be modified by clicking on the model's icon in the sidebar, selecting the model name, clicking on the drop-down icon to the right of the model name, and finally selecting Permissions. This will show us a dialog box from which we can select specific users or groups and add specific permissions:

Figure 1.42 – MLflow permissions
You can update the permissions of a user or group by selecting the new permission from the Permission drop-down menu:
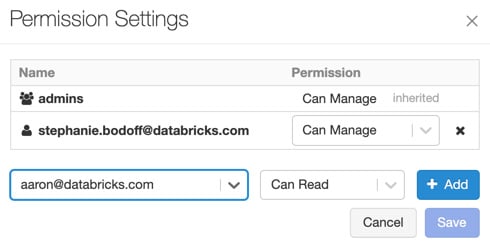
Figure 1.43 – MLflow access management
By selecting one of these options, we can control how MLflow experiments interact with our data and which users can create models that work with it.
Summary
In this chapter, we have tried to cover all the main aspects of how Azure Databricks works. Some of the things we have discovered include how notebooks can be created to execute code, how we can import data to use, how to create and manage clusters, and so on. This is important because when creating ETLs and ML experiments in Azure Databricks within an organization, aside from how to code the ETL in our notebooks, we will need to know how to manage the data and computational resources required, how to share assets, and how to manage the permissions of each one of them.
In the next chapter, we will apply this knowledge to explore in more detail how to create and manage the resources needed to work with data in Azure Databricks, and learn more about custom VNets and the different alternatives that we have in order to interact with them, either through the Azure Databricks UI or the CLI tool.






