



















 Download code from GitHub
Download code from GitHub
Chapter 1: An Introduction to Data Engineering
Data engineering is a fast-growing career path, and a role in high demand, as data becomes ever more critical to organizations of all sizes. For those that enjoy the challenge of putting together the "puzzle pieces" that build out complex data pipelines to ingest raw data, and to then transform and optimize that data for various data consumers, it can be a really rewarding career.
In this chapter, we look at the many ways that data has become an important and valuable corporate asset. We also review some of the challenges that organizations face as they deal with increasing volumes of data, and how data engineers can use cloud-based services to help overcome these challenges. We then set the foundations for the rest of the hands-on activities in this book by providing step-by-step details on creating a new Amazon Web Services (AWS) account.
Throughout this book, we are going to cover a number of topics that teach the fundamentals of developing data engineering pipelines on AWS, but we'll get started in this chapter with these topics:
- The rise of big data as a corporate asset
- The challenges of ever-growing datasets
- The role of the data engineer as a big data enabler
- The benefits of the cloud when building big data analytic solutions
- Hands-on - create or access an AWS account for following along with the hands-on activities in this book
Technical requirements
You can find the code files of this chapter in the GitHub repository using the following link: https://github.com/PacktPublishing/Data-Engineering-with-AWS/tree/main/Chapter01
The rise of big data as a corporate asset
You don't need to look too far or too hard these days to hear about how big data and data analytics are transforming organizations and having an impact on society as a whole. We hear about how companies such as TikTok analyze large quantities of data to make personalized recommendations about which clip to show a user next. Also, we know how Amazon recommends products a customer may be interested in based on their purchase history. We read headlines about how big data could revolutionize the healthcare industry, or how stock pickers turn to big data to find the next breakout stock performer when the markets are down.
The most valuable companies in the US today are companies that are masters of managing huge data assets effectively, with the top five most valuable companies in Q4 2021 being the following:
- Microsoft
- Apple
- Alphabet (Google)
- Amazon
- Tesla
For a long time, it was companies that managed natural gas and oil resources, such as ExxonMobil, that were high on the list of the most valuable companies on the US stock exchange. Today, ExxonMobil will often not even make the list of the top 30 companies. It is no wonder that the number of job listings for people with skillsets related to big data is on the rise.
There is also no doubt that data, when harnessed correctly and optimized for maximum analytic value, can be a game-changer for an organization. At the same time, those companies that are unable to effectively utilize their data assets risk losing a competitive advantage to others that do have a comprehensive data strategy and effective analytic and machine learning programs.
Organizations today tend to be in one of the following three states:
- They have an effective data analytics and machine learning program that differentiates them from their competitors.
- They are conducting proof of concept projects to evaluate how analytic and machine learning programs can help them achieve a competitive advantage.
- Their leaders are having sleepless nights worrying about how their competitors are using analytics and machine learning programs to achieve a competitive advantage over them.
No matter where an organization currently is in their data journey, if they have been in existence for a while, they have likely faced a number of common data-related challenges. Let's look at how organizations have typically handled the challenge of ever-growing datasets.
The challenges of ever-growing datasets
Organizations have many assets, such as physical assets, intellectual property, the knowledge of their employees, and trade secrets. But for too long, organizations did not fully recognize that they had another extremely valuable asset, and they failed to maximize the use of it—the vast quantities of data that they had gathered over time.
That is not to say that organizations ignored these data assets, but rather, due to the expense and complex nature of storing and managing this data, organizations tended to only keep a subset of data.
Initially, data may have been stored in a single database, but as organizations, and their data requirements, grew, the number of databases exponentially increased. Today, with the modern application development approach of microservices, companies commonly have hundreds, or even thousands, of databases. Faced with many data silos, organizations invested in data warehousing systems that would enable them to ingest data from multiple siloed databases into a central location for analytics. But due to the expense of these systems, there were limitations on how much data could be stored, and some datasets would either be excluded or only aggregate data would be loaded into the data warehouse. Data would also only be kept for a limited period of time as data storage for these systems was expensive, and therefore it was not economical to keep historical data for long periods. There was also a lack of widely available tools and compute power to enable the analysis of extremely large, comprehensive datasets.
As an organization continued to grow, multiple data warehouses and data marts would be implemented for different business units or groups, and organizations still lacked a centralized, single-source-of-truth repository for their data. Organizations were also faced with new types of data, such as semi-structured or even unstructured data, and analyzing these datasets with traditional tooling was a challenge.
As a result, new technologies were invented that were able to better work with very large datasets and different data types. Hadoop was a technology created in the early 2000s at Yahoo as part of a search engine project that wanted to index 1 billion web pages. Over the next few years, Hadoop, and the underlying MapReduce technology, became a popular way for all types of companies to store and process much larger datasets. However, running a Hadoop cluster was a complex and expensive operation requiring specialized skills.
The next evolution for big data processing was the development of Spark (later taken on as an Apache project and now known as Apache Spark), a new processing framework for working with big data. Spark showed significant increases in performance when working with large datasets due to the fact that it did most processing in memory, significantly reducing the amount of reading and writing to and from disks. Today, Apache Spark is often regarded as the gold standard for processing large datasets and is used by a wide array of companies, although there are still a lot of Hadoop MapReduce clusters in production in many companies.
In parallel with the rise of Apache Spark as a popular big data processing tool was the rise of the concept of data lakes—an approach that uses low-cost object storage as a physical storage layer for a variety of data types, provides a central catalog of all the datasets, and makes that data available for processing with a wide variety of tools, including Apache Spark. AWS uses the following definition when talking about data lakes:
You can find this definition here: https://aws.amazon.com/big-data/datalakes-and-analytics/what-is-a-data-lake/.
Having looked at how data analytics became an essential tool in organizations, let's now look at the roles that enable maximizing the value of data for a modern organization.
Data engineers – the big data enablers
Amid the increasing recognition of data as a valuable corporate asset and the introduction of new technologies to store and process vast amounts of data, there has been an increase in the opportunities and roles available for data-related careers.
Let's look at a sample use case, where a sales manager for a consumer goods organization wants to better understand which alternative products a customer considers before purchasing their product. In addition, they also want to have a better way of predicting product demand by category based on external factors, such as the expected weather.
Achieving the desired outcomes as specified by the sales manager will require bringing in data from multiple internal and external sources. Datasets that could be relevant to this scenario may include the following:
- Customer, product, and order relational databases
- Web server logs from the consumer-facing storefront
- Third-party sales data from online marketplaces where relevant products are sold (such as Amazon.com)
- Other relevant third-party datasets that may influence sales (for example, weather-related data)
Multiple teams would need to be involved in the project, with the following three roles playing a primary part in implementing the required solution.
Understanding the role of the data engineer
The role of a data engineer is to do the following:
- Design, implement, and maintain the pipelines that enable the ingestion of raw data into a storage platform.
- Transform that data to be optimized for analytics.
- Make that data available for various data consumers using their tool of choice.
In our scenario, the data engineer will first need to design the pipelines that ingest data from the various internal and external sources. To achieve this, they will use a variety of tools (more on that in future chapters), depending on the source system and whether it will be scheduled batch ingestion or real-time streaming ingestion.
The data engineer is also responsible for transforming the raw input datasets to optimize them for analytics, using various techniques (as discussed later in this book). The data engineer must also create processes to verify the quality of data, add metadata about the data to a data catalog, and manage the life cycle of code related to data transformation.
Finally, the data engineer may need to assist in integrating various data consumption tools with the transformed data, enabling data analysts and data scientists to use their preferred tools to draw insights from the data.
The data engineer uses tools such as Apache Spark, Apache Kafka, and Presto, as well as other commercially available products, to build the data pipeline and optimize data for analytics.
The data engineer is much like a civil engineer for a new residential development. The civil engineer is responsible for designing and building the roads, bridges, train stations, and so on to enable commuters to easily commute in and out of the development, while the data engineer is responsible for designing and building the infrastructure required to bring data into a central source and for optimizing the data for use by various data consumers.
Understanding the role of the data scientist
The role of a data scientist is to draw complex insights and make predictions based on various datasets, using machine learning and artificial intelligence. The data scientist will combine a number of skills, including computer science, statistics, analytics, and math, in order to help an organization answer complex questions and make informed decisions using data.
Data scientists need to understand the raw data and know how to use that data to develop and train complex machine learning models that will help recognize patterns in the data and predict future trends. In our scenario, the data scientist may build a machine learning model that uses past sales data, correlated with weather information for each day in the reporting period. They can then design and train this model to help business users get predictions on the likely top-selling categories for future dates based on the expected weather forecast.
Where the data engineer is like a civil engineer building infrastructure for a new development, the data scientist is developing cars, airplanes, and other forms of transport used to move in and out of the development. Data scientists create machine learning models that enable data consumers and business analysts to draw new insights and predictions from data.
Understanding the role of the data analyst
The role of a data analyst is to examine and combine multiple datasets in order to help a business understand trends in the data and to make more informed business decisions. While a data scientist develops models that make future predictions or identifies non-obvious patterns in data, the data analyst works with well-structured and modeled data to understand current conditions and to highlight recent patterns from the data.
A data analyst may answer questions such as which menu item sold best in different geographic regions over the past month, or which medical procedure had the best outcome for patients of different ages. These insights help an organization make better decisions for the future.
In our scenario, the data analyst may run complex queries against the different datasets that are available (such as an orders database or web server logs), joining together subsets of data from each source to gain new insights. For example, the data analyst may create a report highlighting which alternate products are most often browsed by a customer before a specific product is purchased. The data analyst may also make use of advanced machine learning models developed by the data scientists to gain further valuable insights.
Where the data engineer is like a civil engineer building infrastructure, and the data scientist is developing means of transportation, the data analyst is like a skilled pilot, using their expertise to get users to their end destination.
Understanding other common data-related roles
Organizations may have other role titles and job descriptions for data-related positions, but generally, these will be a subset of the roles described in the preceding sections.
For example, a big data architect could be a subset of the data engineer role, focused on designing the architecture for big data pipelines, but not building the actual pipelines. Or, a data visualization developer may be focused on building out visualizations using business intelligence tools, but this is effectively a subset of the data analyst role.
Larger organizations tend to have more focused job roles, while in a smaller organization a single person may take on the role of data engineer, data scientist, and data analyst.
In this book, we will focus on the role of the data engineer, and dive deep into how a data engineer is able to build complex data pipelines using the power of cloud computing services. Let's now look at how cloud computing has simplified how organizations are able to build and scale out big data processing solutions.
The benefits of the cloud when building big data analytic solutions
For a long time, organizations relied on complex systems that they would run in their own data centers to help them capture, store, and process large amounts of data. But over the last decade, there has been a trend of an increasing amount of data that organizations want to store and analyze, and on-premises systems have struggled to scale to keep up with demand. Scaling up these traditional tools for managing ever-increasing datasets has been expensive, complex, and time-consuming, and organizations have been seeking alternative solutions to cope with the increasing data volumes.
Ever since Amazon launched AWS in 2006, organizations have been realizing the benefits of running their workloads in the cloud. Cloud computing enables scalability, cost efficiency, security, and automation, which most companies find impossible to achieve within their own data centers, and this applies to the area of data analytics as well. One of the first AWS services was Amazon Simple Storage Service (Amazon S3), a cloud-based object store that offers essentially unlimited scalability at low cost, and yet provides durability and availability that most data center managers could only dream of achieving. Today, Amazon S3 has become the physical storage layer for thousands of data lake projects, and a wide ecosystem of analytic tools has been created to work with the service.
Successful data engineers need to understand the tools available in the cloud for building out complex data analytic projects and understand which set of tools is best to achieve the outcome needed for their project. In this book, you will learn more about AWS tools for working with big data, and you will gain hands-on experience in developing a data engineering pipeline in AWS.
To get started, you will either need an existing AWS account or you will need to create a new AWS account so that you can follow along with the practical examples. Follow along with the next section as we provide step-by-step instructions for creating a new AWS account.
Hands-on – creating and accessing your AWS account
The projects in this book require you to access an AWS account with administrator privileges. If you already have administrator privileges for an AWS account and know how to access the AWS Management Console, you can skip this section and move on to Chapter 2, Data Marts, Data Lakes, and the Data Lakehouse.
If you are making use of a corporate AWS account, you will want to check with your AWS cloud operations team to ensure that your account has administrative privileges. Even if your daily-use account does not allow full administrative privileges, your cloud operations team may be able to create a sandbox account for you.
What is a sandbox account?
A sandbox account is an account isolated from your corporate production systems with relevant guardrails and governance in place, and is used by many organizations to provide a safe space for teams or individual developers to experiment with cloud services.
If you cannot get administrative access to a corporate account, you will need to create a personal AWS account or work with your cloud operations team to request specific permissions needed to complete each section. Where possible, we will provide links to AWS documentation that will list the required permissions, but the full details of the required permissions will not be covered directly in this book.
Important note about the costs associated with the hands-on tasks in this book
If you are creating a new personal account or using an existing personal account, you will incur and be responsible for AWS costs as you follow along in this book. While some services may fall under AWS free-tier usage, some of the services covered in this book will not. We strongly encourage you to set up budget alerts within your account and to regularly check your billing console.
See the AWS documentation on monitoring your usage and costs at https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/monitoring-costs.html.
Creating a new AWS account
To create a new AWS account, you will need the following things:
- An email address (or alias) that has not been used before to register an AWS account
- A phone number that can be used for important account verification purposes
- Your credit or debit card, which will be charged for AWS usage outside of the Free Tier
Tip regarding the phone number you use when registering
It is important that you keep your contact details up to date for your AWS account, as if you lose access to your account, you will need access to the email address and phone number registered for the account. If you expect that your contact number may change in the future, consider registering a virtual number that you will always be able to access and that you can forward to your primary number. One such service that enables this is Google Voice (http://voice.google.com).
The following steps will guide you through creating a new AWS account:
- Navigate to the AWS landing page at http://aws.amazon.com.
- Click on the Create an AWS Account link.
- Provide an email address, specify a secure password (one that you have not used elsewhere), and provide a name for your account.
Tip about reusing an existing email address
Some email systems support adding a
+sign followed by a few characters to the end of the username portion of your email address in order to create a unique email address that still goes to your same mailbox. For example,atest.emailaddress@gmail.comandatest.emailaddress+dataengineering@gmail.comwill both go to the primary email address inbox. If you have used your primary email address previously to register an AWS account, you can use this tip to provide a unique email address during registration, but still have emails delivered to your primary account. - Select Professional or Personal for the account type (note that the functionality and tools available are the same no matter which one you pick).

Figure 1.1 – Contact information during AWS account sign-up
- Provide the requested personal information and then after reviewing the terms of the AWS Customer Agreement, click the checkbox if you agree to the terms, and then click on Create Account and Continue.
- Provide a credit or debit card for payment information and select Verify and Add.
- Provide a phone number for a verification text or call, enter the characters shown for the security check, and complete the verification.

Figure 1.2 – Confirming your identity during AWS account sign-up
- Select a support plan.
- You will receive a notification that your account is being activated. This usually completes in a few minutes, but it can take up to 24 hours. Check your email to confirm account activation.
What to do if you don't receive a confirmation email within 24 hours
If you do not receive an email confirmation within 24 hours confirming that your account has been activated, follow the troubleshooting steps provided by AWS Premium Support at https://aws.amazon.com/premiumsupport/knowledge-center/create-and-activate-aws-account/.
Accessing your AWS account
Once you have received the confirmation email confirming that your account has been activated, follow these steps to access your account and to create a new admin user:
- Access the AWS console login page at http://console.aws.amazon.com.
- Make sure Root user is selected, and then enter the email address that you used when creating the account.
- Enter the password that you set when creating the account.
Best practices for securing your account
When you log in using the email address you specified when registering the account, you are logging in as the account's root user. It is a recommended best practice that you do not use this login for your day-to-day activities, but rather only use this when performing activities that require the root account, such as creating your first Identity and Access Management (IAM) user, deleting the account, or changing your account settings. For more information, see https://docs.aws.amazon.com/IAM/latest/UserGuide/id_root-user.html.
It is also strongly recommended that you enable Multi-Factor Authentication (MFA) on this and other administrative accounts. To enable this, see https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_enable_virtual.html.
In the following steps, we are going to create a new IAM administrative user account:
- In the AWS Management Console, confirm which Region you are currently in. You can select any region, such as the Region closest to you geographically.
Important note about pricing differences in AWS Regions
Note that pricing for AWS services differs from Region to Region, so take this into account when selecting a Region to use for the exercises in this book and make sure you are always in the same Region when working through the exercises.
In the following screenshot, the user is in the Ohio Region (also known as us-east-2):

Figure 1.3 – AWS Management Console
- In the search bar in the top middle of the screen, type in
IAMand press Enter. This brings up the console for IAM. - On the left-hand side menu, click Users and then Add user.
- Provide a username and select both Programmatic access as well as AWS Management Console access.
- Set a password for the console, and select whether to force a password change on the next login, then click Next: Permissions.

Figure 1.4 – Creating a new user in the AWS Management Console
- For production accounts, it is best practice to grant permissions with a policy of least privilege, giving each user only the permissions they specifically require to perform their role. However, AWS managed policies can be used to cover common use cases in test accounts, and so to simplify the setup of our test account, we will use the AdministratorAccess managed policy. This policy gives full access to all AWS resources in the account.
On the Set permissions screen, select Attach existing policies directly. From the list of policies, select AdministratorAccess. Then, click Next: Tags.
- Optionally, specify tags (key-value pairs), then click Next: Review.
- Review the settings, and then click Create user.
- Take note of the URL to sign in to your account.
- Take note of the access key ID and secret access key as you will need these later. This is the only opportunity you will have to record the secret access key so it is important to safely record this information now:
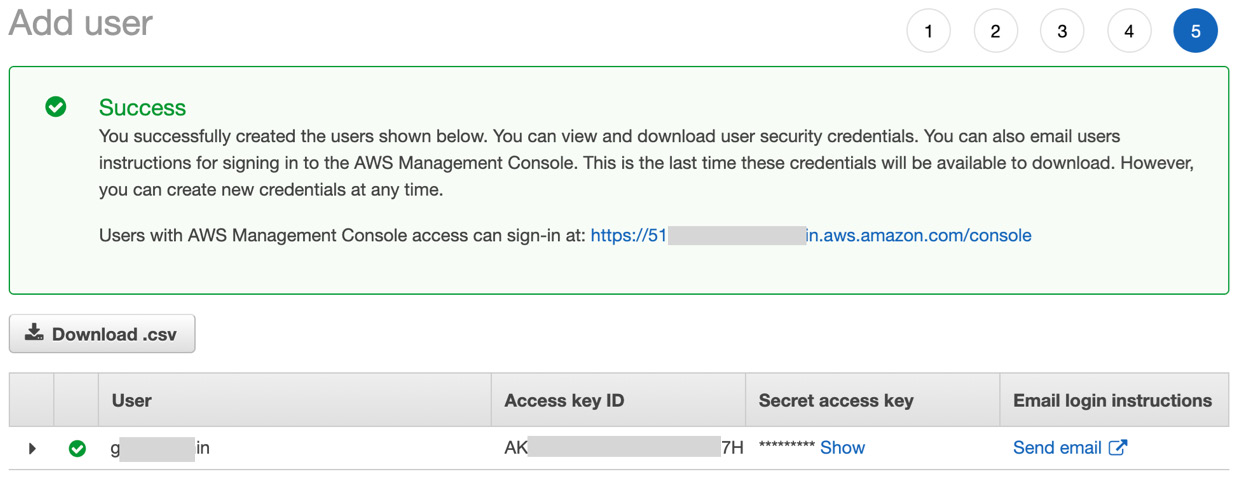
Figure 1.5 – Successful creation of new IAM user
Important note about protecting your account
Make sure you protect this information as anyone who has access to your access key ID and secret access key is able to perform full administrative functions in your account, including deploying resources that you will be responsible for paying for.
For the remainder of the tutorials in this book, you should log in using the URL provided and the username and password you set for your IAM user. You should also strongly consider enabling MFA for this account, a recommended best practice for all accounts with administrator permissions.
Summary
In this chapter, we reviewed how data is becoming ever more important for organizations looking to gain new insights and competitive advantage, and introduced some of the core big data processing technologies. We also looked at the key roles related to managing, processing, and analyzing large datasets, and highlighted how cloud technologies enable organizations to better deal with the increasing volume, variety, and velocity of data.
In our first hands-on exercise, we provided step-by-step instructions for creating a new AWS account that can be used throughout the remainder of this book as we develop our own data engineering pipeline.
In the next chapter, we dig deeper into current approaches, tools, and frameworks that are commonly used to manage and analyze large datasets, including data warehouses, data marts, data lakes, and a relatively new concept, the data lake house. We also get hands-on with AWS again, this time installing and configuring the AWS Command-Line Interface (CLI) tool and creating an Amazon S3 bucket.

