


















Database design is one of the most important tasks in the Systems Development Life Cycle (SDLC), also referred to as Application Development Life Cycle (ADLC). That's because databases are essential for all businesses, and good design is crucial to any business-critical, high-performance application. Poor database design results in wasted time during the development process and often leads to unusual databases that are unfit for use.
We'll be covering the following topics in this chapter:
The database design process and considerations
The table design process, which includes identifying entities and attributes, creating a relationship between entities, and ensuring data integrity
The basics of data normalization
The SQL Server database architecture
The importance of choosing the appropriate data type
The database design process consists of a number of steps. The general aim of a database design process is to develop an efficient, high-quality database that meets the needs and demands of the application and business stakeholders. Once you have a solid design, you can build the database quickly. In most organizations, database architects and database administrators (DBAs) are responsible for designing a database. Their responsibility is to understand the business and operational requirements of an organization, model the database based on these requirements, and establish who will use the database and how. They simply take the lead on the database design project and are responsible for the management and control of the overall database design process.
The database design process can usually be broken down into six phases, as follows:
The requirement collection and analysis phase
The conceptual design phase
The logical design phase
The physical design phase
The implementation and loading phase
The testing and evaluation phase
These phases of design do not have clear boundaries and are not strictly linear. In addition, the design phases might overlap, and you will often find that due to real-world limitations, you might have to revisit a previous design phase and rework some of your initial assumptions.
In this phase, you interview the prospective users, gather their requirements, and discuss their expectations from the new database application. Your objective in this phase is to gather as much information as possible from potential users and then document these requirements. This phase results in a concise set of user and functional requirements, which should be detailed and complete. Functional requirements typically include user operations that need to be applied to the database, information flow, type of operation, frequency of transactions, and data updates. You can document functional requirements using diagrams, such as sequence diagrams, data flow diagrams (DFDs), scenarios, and so on.
Moreover, you can also conduct an analysis of the current operating environment—whether it's manual, a file processing system, or an old DBMS system—and interact with users extensively to analyze the nature of the business to be supported; you can also justify the need for data and databases. The requirement collection and analysis phase can take a significant amount of time; however, it plays a vital role in the success of the new database application. The outcome of this phase is the document that contains the user's specifications, which is then used as the basis for the design of the new database application.
Your goal during the conceptual design phase is to develop the conceptual schema of the database, which is then used to ensure that all user requirements are met and do not conflict. In this step, you need to select the appropriate data model and then translate the requirements that arise from the preceding phase into the conceptual database schema by applying the concepts of the chosen data model, which does not depend on RDBMS. The most general data model used in this phase is the entity-relationship (ER) model, which is usually used to represent the conceptual database design. The conceptual schema includes a concise description of the user's data requirements, including a detailed description of the entity types, relationships, and constraints.
The conceptual design phase does not include the implementation details. Thus, end users can easily understand them, and they can be used as a communication tool. During this phase, you are not concerned with how the solution will be implemented. In the conceptual design phase, you only make general design decisions that may or may not hold when you start looking at the technologies and project budget available. The information you gather during the conceptual design phase is critical to the success of your database design.
During the logical design phase, you map the high-level, conceptual, entity-relationship data model into selected RDBMS constructs. The data model that is chosen will represent the company and its operations. From there, a framework of how to provide a solution based on the data model will be developed. In this phase, you also determine the best way to represent the data, the services required by the solution, and how to implement these services. The data model of a logical design will be a more detailed framework than the one developed during the conceptual design phase. This phase provides specific guidelines, which you can use to create the physical database design.
You do little, if any, physical implementation work at this point, although you may want to do a limited prototyping to see whether the solution meets user expectations.
During the physical design phase, you make decisions about the database environment (database server), application development environment, database file organization, physical database objects, and so on. The physical design phase is a very technical stage in the database design process. The result of this phase will be a physical design specification that will be used to build and deploy your database solution.
During this phase, you implement the proposed database solution. The phase includes activities such as the creation of the database, the compilation and execution of Data Definition Language (DDL) statements to create the database schema and database files, the manual or automatic loading of the data into a new database system from a previous system, and finally, the configuration of the database and application security.
In this phase, you perform the testing of your database solution to tune it for performance, integrity, concurrent access, and security restrictions. Typically, this is done in parallel with the application programming phase. If the test fails, you take several actions such as adjusting the performance based on a reference manual, modifying the physical design, modifying the logical design, and upgrading or changing the SQL Server software and database server hardware.

As mentioned earlier, you complete the table and data design activities during the conceptual and logical design phases of the database design. During the conceptual design phase, you identify specific data needs and determine how to present the data in the database solution, which is based on the information you collected in the requirement gathering phase. You then use the information from the conceptual design phase in the logical design phase to design and organize your data structure. In the logical design phase, you also identify the requirements for database objects to store and organize the data.
Often, one of the most time-consuming and important tasks in the physical design phase is the table design. During the physical design phase, you identify the following:
Entities and attributes
Relationships between entities
You use tables to store and organize data in the database. A table contains columns and rows. For example, the following is an example of how a Customer table might look. Each row in the Customer table represents an individual customer. The column contains information that describes the data for the individual customer. Each column has a data type, which identifies a format in which the data is stored in that column. Some data types can have a fixed length, which means that the size does not depend on the data stored in it. You also have data types with variable lengths, which means their length changes to fit the data they possess.

Entities are business objects that your database contains, and they are used to logically separate the data in the database. An entities list, which you need to create, is used to determine the tables as part of the physical design phase. You create a separate table in the database for each entity (such as customers, employees, orders, and the payroll). Entities are characterized by attributes. For example, you declare each individual attribute of an entity (such as an individual customer, an individual order, an individual employee, or an individual payroll record) as a row in the table.
An attribute is a property of an entity. For example, the employee entity has attributes such as the employee ID, first name, last name, birthday, social security number, address, country, and so on. Some attributes are unique values. For example, each customer in a Customer table has a unique customer number. Attributes are used to organize specific data within the entity.
Relationships identify associations between the data stored in different tables. Entities relate to other entities in a variety of ways. Table relationships come in several forms, listed as follows:
A one-to-one relationship
A one-to-many relationship
A many-to-many relationship
A one-to-one relationship represents a relationship between entities in which one occurrence of data is related to one and only one occurrence of data in the related entity. For example, every employee should have a payroll record, but only one payroll record. Have a look at the following diagram to get a better understanding of one-to-one relationships:

A one-to-many relationship seems to be the most common relationship that exists in relational databases. In the one-to-many relationship, each occurrence of data in one entity is related to zero or more occurrences of data in a second entity. For example, each department in a Department table can have one or more employees in the Employee table. The following diagram will give you a better understanding of one-to-many relationships:

In a many-to-many relationship, each occurrence of data in one entity is related to zero or more occurrences of data in a second entity, and at the same time, each occurrence of the second entity is related to zero or more occurrences of data in the first entity. For example, one instructor teaches many classes, and one class is taught by many instructors, as shown in the following diagram:

A many-to-many relationship often causes problems in practical examples of normalized databases, and therefore, it is common to simply break many-to-many relationships in to a series of one-to-many relationships.
Data integrity ensures that the data within the database is reliable and adheres to business rules. Data integrity falls into the following categories:
Domain integrity: This ensures that the values of the specified columns are legal, which means domain integrity ensures that the value meets a specified format and value criteria. You can enforce domain integrity by restricting the type of data stored within columns (through data types), the format (through
CHECKconstraints and rules), or the range of possible values (throughFOREIGN KEYconstraints,CHECKconstraints,DEFAULTdefinitions,NOT NULLdefinitions, and rules).Entity integrity: This ensures that every row in the table is uniquely identified by requiring a unique value in one or more key columns of the table. You can enforce entity integrity through indexes,
UNIQUE KEYconstraints,PRIMARY KEYconstraints, orIDENTITYproperties.Referential integrity: This ensures that the data is consistent between related tables. You can enforce referential integrity through
PRIMARY KEYconstraints andFOREIGN KEYconstraints.User-defined integrity: This ensures that the values stored in the database remain consistent with established business policies. You can maintain user-defined integrity through business rules and enforce user-integrity through stored procedures and triggers.
Normalization is the process of reducing or completely eliminating the occurrence of redundant data in the database. Normalization refers to the process of designing relational database tables from the ER model. It is a part of the logical design process and is a requirement for online transaction processing (OLTP) databases. This is important because it eliminates (or reduces as much as possible) redundant data. During the normalization process, you usually split large tables with many columns into one or more smaller tables with a smaller number of columns. The main advantage of normalization is to promote data consistency between tables and data accuracy by reducing the redundant information that is stored. In essence, data only needs to be changed in one place if an occurrence of the data is stored only once.
The disadvantage of normalization is that it produces many tables with a relatively small number of columns. These columns have to then be joined together in order for the data to be retrieved. Normalization could affect the performance of a database drastically. In fact, the more the database is normalized, the more the performance will suffer.
Traditional definitions of normalization refer to the process of modifying database tables to adhere to accepted normal forms. Normal forms are the rules of normalization. They are a way to measure the levels or depth that a database is normalized to. There are five different normal forms; however, most database solutions are implemented with the third normal form (3NF). Both the forth normal form (4NF) and the fifth normal form (5NF) are rarely used and, hence, are not discussed in this chapter. Each normal form builds from the previous. For example, the second normal form (2NF) cannot begin before the first normal form (1NF) is completed.
Note
A detailed discussion of all of the normal forms is outside the scope of this book. For help with this, refer to the Wikipedia article at http://en.wikipedia.org/wiki/Database_normalization.
In 1NF, you divide the base data into logical units called entities or tables. When you design each entity or table, you assign the primary key to it, which uniquely identifies each record inside the table. You create a separate table for each set of related attributes. There can be only one value for each attribute or column heading. The 1NF eliminates the repetition of groups by putting each one in a separate table and connecting them with a one-to-many relationship.
The objective of 2NF is to avoid the duplication of data between tables. In 2NF, you take data that is partly dependent on the primary key and enter it into another table. The entity is in 2NF when it meets all of the requirements of 1NF and has no composite primary key. In 2NF, you cannot subdivide the primary key into separate logical entities. You can, however, eliminate functional dependencies on partial keys by putting those fields in a separate table from the ones that are dependent on the whole key.
The 3NF objective is used to remove the data in a table that is not dependant on the primary key. In 3NF, no non-key column can depend on another non-key column, so all of the data applies specifically to the table entity. The entity is in 3NF when it meets all of the requirements of 1NF and 2NF and there is no transitive functional dependency.
Denormalization is the reverse of the normalization process, where you combine smaller tables that contain related attributes. Applications such as online analytical processing (OLAP) applications are good candidates for denormalized data. This is because all of the necessary data is in one place, and SQL Server does not require to combine data when queried.
SQL Server maps the database over a set of operating system files that store the database objects. Physically, a SQL Server database is a set of two or more operating system files. Each database file has two names:
SQL Server database files can be stored on either a FAT or an NTFS filesystem. You can create three types of SQL Server database files, listed as follows:
Primary data file: This is the initial default file that contains the configuration information for the database, pointers to the other files in the database, and all of the database objects. Every database has one primary data file. The preferred filename extension for a primary data file is
.mdf. Although you can store user objects within the main data file, but it is not recommended.Secondary data file: Secondary data files are optional and used to hold user database objects. You can create one or more secondary files within the database to hold the user database objects. The recommend filename extension for a secondary data file is
.ndf. Secondary data files can be spread across multiple disks and are useful as the database's additional storage area.Transaction log file: This is the log file for the database that holds information about all database modification events. The information in the transaction log file is used to recover the database. A database can have one or more transaction log files. Multiple transaction log files do not improve database performance as the SQL Server database engine writes log information sequentially. The recommended filename extension for transaction logs is
.ldf.
SQL Server uses pages as a basic unit of data storage. The disk space allocated to a data file (.mdf or .ndf) in a database is logically divided into pages that are numbered contiguously from 0 to n. SQL Server performs disk I/O operations at a page level, which means that the SQL Server database engine reads or writes the whole data page during the Data Manipulation Language (DML) operation.
In SQL Server, the page is an 8 KB block of contiguous disk space. SQL Server can store 128 pages per megabyte of allocated storage space. Each page starts with 96 bytes of header information about the page. If the rows are small, multiple rows can be stored on a page, as shown in the following diagram:
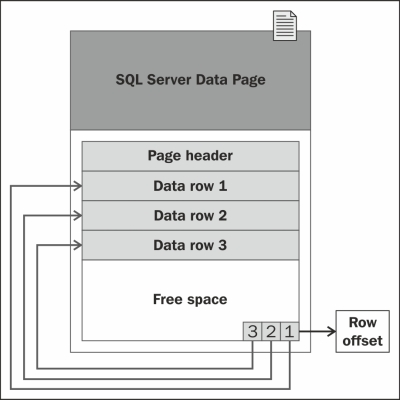
The rows of a SQL Server table cannot span multiple pages of data. That is why the rows are limited to a maximum of 8,060 bytes of data. However, there is an exception to this rule for data types that are used to store large blocks of text. The data for such data types is stored separately from the pages of the small row data. For example, if you have a row that exceeds 8,060 bytes, which includes a column that contains large blocks of text, SQL Server dynamically moves this text to a separate text/image page, as shown in the following diagram:
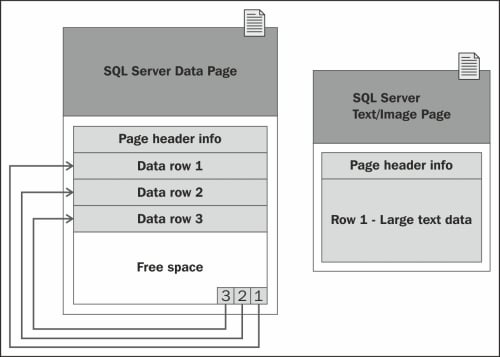
Note
SQL Server uses the following page types in the data files of a SQL Server database: Data, Index, Text/Image, Global Allocation Map, Shared Global Allocation Map, Page Free Space, Index Allocation Map, Bulk Changed Map, and Differential Changed Map. A detailed discussion about the contents of these page types used in the data files of a SQL Server database is beyond the scope of this chapter. For help with this, refer to the Understanding Pages and Extents article at http://technet.microsoft.com/en-US/library/ms190969(v=sql.120).aspx.
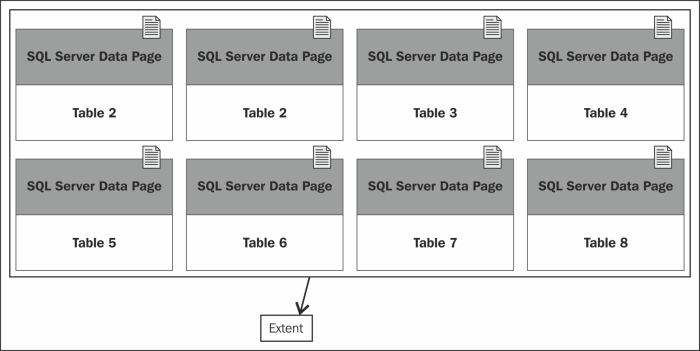
An extent is eight contiguous pages (64 KB) of disk storage. SQL Server can store 16 extents per megabyte of allocated storage space. A small table can share extents with other database objects to make better use of available space, with the limitation of eight objects per extent. Each page in an extent can be owned by different user objects as shown in the following diagram:
SQL Server database transaction log files contain the information that is needed to recover the SQL Server database if a system failure occurs. A database can have one or more transaction log files. SQL Server records each DML operation performed against the database in the transaction log file. When a system failure occurs, SQL Server enters into the automatic recovery mode on startup, and it uses the information in the transaction log to recover the database. The automatic recovery process rolls committed transactions forward (which means that it makes changes to the database) and reverts any uncommitted transactions post system failure.
SQL Server divides the physical transaction log file into smaller segments called Virtual Log Files (VLFs). The virtual log file only contains a log record for active transactions. SQL Server truncates the virtual log file once it is no longer contains active transactions. The virtual log file has no fixed size, and there is no fixed number of virtual log files per physical transaction log file. You cannot configure the size and number of virtual log files; the SQL Server database engine dynamically manages the size and number of the virtual log files each time you create or extend the physical transaction log file.
SQL Server tries to keep the number of virtual log files to a minimum; however, you will end up with too many virtual log files if you incorrectly size the physical transaction log file or set it to grow in small increments. This is because whenever the physical transaction log file grows, the SQL Server database engine adds more virtual log files to the physical transaction log file. Having too many virtual log files can significantly impair the performance of the database. Therefore, you need to periodically monitor the physical transaction log file to check for a high number of virtual log files. You can run DBCC LOGINFO to check the number of the virtual log files in the database. The following is the syntax of this command:
USE [YourDatabaseName]; DBCC LOGINFO;
You can also use DBCC SQLPREF to view the amount of space available in the transaction log file.
The following diagram illustrates the workings of the transaction log during the data manipulation language operation:
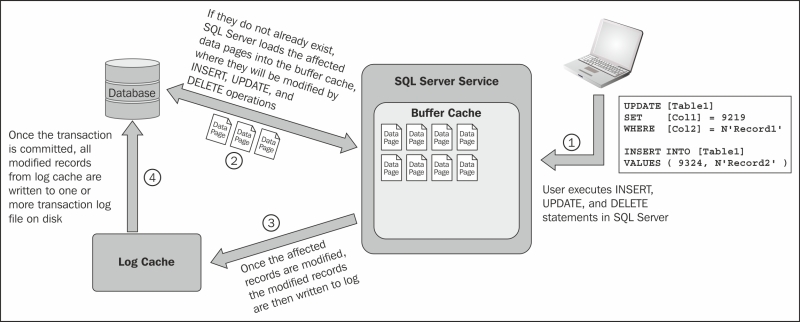
The SQL Server database transaction log acts as a write-ahead log (as SQL Sever writes to the log before writing to the disk) for modifications to the database, which means that the modification of the data is not written to disk until a checkpoint occurs in the database. For example, as illustrated in the previous diagram, when you execute an INSERT, UPDATE, or DELETE statement, the SQL Server database engine first checks the buffer cache for the affected data pages. If the affected data pages are not in the buffer cache, the SQL Server database engine loads these affected data pages into a buffer cache.
The SQL Server database engine then logs the operation in the log cache, which is another designated area in memory. When the transaction is committed, the modifications associated with the transaction are written from the log cache to the transaction log file on disk. Completed transactions are written to the database periodically by the checkpoint process.
In SQL Server databases, you can group the secondary data files logically for administrative purposes. This administrative grouping of data files is called filegroups. By default, the SQL Server databases are created with one filegroup, also known as the default filegroup (or primary filegroup) for the database. The primary database is a member of the default filegroup. You can add secondary database files to the default filegroup; however, this is not recommended. It is recommended that you create separate filegroups for your secondary data files. This is known as a secondary filegroup (or user-defined filegroup). The SQL Server database engine allows you to create one or more filegroups, which can contain one or more secondary data files. Transaction log files do not belong to any filegroup. You can query the sys.filegroups system catalog to list all of the information about filegroups created within the SQL Server database.
The main advantage of filegroups is that they can be backed up or restored separately, or they can be brought online or taken offline separately.
A data type determines the type of data that can be stored in a database table column. When you create a table, you must decide on the data type to be used for the column definitions. You can also use data types to define variables and store procedure input and output parameters. You must select a data type for each column or variable appropriate for the data stored in that column or variable. In addition, you must consider storage requirements and choose data types that allow for efficient storage. For example, you should always use tinyint instead of smallint, int, or bigint if you want to store whole positive integers between 0 and 255. This is because tinyint is a fixed 1-byte field, whereas smallint is 2 bytes, int is 4 bytes, and bigint is a fixed 8-byte field.
Choosing the right data types for your tables, stored procedures, and variables not only improves performance by ensuring a correct execution plan, but it also improves data integrity by ensuring that the correct data is stored within a database. For example, if you use a datetime data type for a column of dates, then only valid dates will be stored in this column. However, if you use a character or numeric data type for the column, then eventually, someone will be able to store any type of character or numeric data value in the column that does not represent a date.
SQL Server 2014 supports three basic data types: system data types defined by SQL Server, alias data types based on system data types, and .NET Framework common language runtime (CLR) user-defined data types (UDT).
SQL Server defines a wide variety of system data types that are designed to meet most of your data storage requirements. The system data types are organized into the following categories:
Exact numeric data types include
bigint,int,smallint,tinyint,bit,numeric,money, andsmallmoneyUnicode character string data types include
nchar,nvarchar, andntextDate and time data types include
date,time,smalldatetime,datetime,datetime2, anddatetimeoffsetBinary string data types include:
binary,varbinary, andimageOther data types include
cursor,timestamp,hierarchyid,uniqueidentifier,sql_variant,xml,table, and spatial types (geometryandgeography)
Out of these data types, the following data types are not supported in memory-optimized tables and natively compiled stored procedures: datetimeoffset, geography, geometry, hierarchyid, rowversion, sql_variant, UDT, xml, varchar(max), nvarchar(max), image, xml, text, and ntext. This is because the size of the memory-optimized tables is limited to 8,060 bytes, and they do not support off-row or
large object (LOB) storage.
Note
For more information on the data types supported in memory-optimized tables and natively compiled stored procedures, refer to the Supported Data Types article at http://msdn.microsoft.com/en-us/library/dn133179(v=sql.120).aspx.
In SQL Server, you can create alias data types, also known as user-defined data types. The purpose of the alias data types is to create a custom data type to help ensure data consistency. The alias data types are based on system data types. You can either use SQL Server 2014 Management Studio or the CREATE TYPE and DROP TYPE Transact-SQL DDL statements to create and drop alias data types.
Perform the following steps to create alias data types:
Launch SQL Server 2014 Management Studio.
In Object Explorer, expand the
Databasesfolder, then the database for which you want to see user-defined types, thenProgrammability, and thenTypes.Right-click on User-Defined Data Types and choose New User-Defined Data Type.
Enter the information about the data type you want to create.
To drop the alias data type, right-click on the data type and choose Delete.
In this section, we will use the CREATE TYPE and DROP TYPE Transact-SQL DDL statements to create and drop alias data types.
The following is the basic syntax for the CREATE TYPE Transact-SQL DDL statement:
CREATE TYPE [schema.]name FROM base_type[(precision [, scale])] [NULL | NOT NULL] [;]
In the following example, T-SQL code creates the alias data type called account_type to hold the six-character book type:
CREATE TYPE dbo.account_type FROM char(6) NOT NULL;
CLR user-defined types are data types based on CLR assemblies. A detailed discussion on CLR data types is outside the scope of this chapter. For help with this, refer to the CLR User-Defined Types article at http://msdn.microsoft.com/en-us/library/ms131120(v=sql.120).aspx.
Designing a new database is very similar to designing anything else, such as a building, a car, a road, a bridge through the city, or a book like this one. In this chapter, we learned about the key stages to design a new database. Next, we talked about the normal form, the process of normalizing and denormalizing data, entities, attributes, relationships, and data integrity. Then, we learned about the architecture of SQL Server databases and got an understanding of how SQL Server uses the transaction log when you execute INSERT, UPDATE, or DELETE statements in SQL Server. Finally, we learned about why it is important to choose appropriate data types for your databases.

