


















 Download code from GitHub
Download code from GitHub
Hello, Concurrent World!
This chapter is an introduction to concurrency and how Kotlin approaches concurrency challenges. In this chapter, we will also take a first look at asynchronous code written using coroutines. It's important to mention that while the keywords, primitives, and functions related to concurrency in pure Kotlin will be explained through the book, some knowledge of Kotlin is required in order to be able to fully comprehend the code examples.
The following topics will be covered in this chapter:
- Processes, threads, coroutines, and their relationships
- Introduction to concurrency
- Concurrency versus parallelism
- CPU-bound and I/O-bound algorithms
- Why concurrency is often feared
- Concurrency in Kotlin
- Concepts and terminology
Processes, threads, and coroutines
When you start an application, the operating system will create a process, attach a thread to it, and then start the execution of that thread – commonly known as the main thread. In this section, we will detail the relationship between processes, threads, and coroutines. This is necessary in order to be able to understand and implement concurrency.
Processes
A process is an instance of an application that is being executed. Each time an application is started, a process is started for it. A process has a state; things such as handles to open resources, a process ID, data, network connections, and so on, are part of the state of a process and can be accessed by the threads inside that process.
An application can be composed of many processes, a common practice for example for internet browsers. But implementing a multi-process application brings challenges that are out of the scope of this book. For this book, we will cover the implementation of applications that run in more than one thread, but still in a single process.
Threads
A thread of execution encompasses a set of instructions for a processor to execute. So a process will contain at least one thread, which is created to execute the point of entry of the application; usually this entry point is the main() function of the application. This thread is called the main thread, and the life cycle of the process will be tied to it; if this thread ends, the process will end as well, regardless of any other threads in the process. For example:
fun main(args: Array<String>) {
doWork()
}
When this basic application is executed, a main thread is created containing the set of instructions of the main() function. doWork() will be executed in the main thread, so whenever doWork() ends, the execution of the application will end with it.
Each thread can access and modify the resources contained in the process it's attached to, but it also has its own local storage, called thread-local storage.
Only one of the instructions in a thread can be executed at a given time. So if a thread is blocked, the execution of any other instruction in that same thread will not be possible until the blocking ends. Nevertheless, many threads can be created for the same process, and they can communicate with each other. So it is expected that an application will never block a thread that can affect negatively the experience of the user; instead, the blocking operations should be assigned to threads that are dedicated to them.
In Graphic User Interface (GUI) applications, there is a thread called a UI thread; its function is to update the User Interface and listen to user interactions with the application. Blocking this thread, obstructs the application from updating its UI and from receiving interactions from the user. Because of this, GUI applications are expected to never block the UI thread, in order to keep the application responsive at all times.
Android 3.0 and above, for example, will crash an application if a networking operation is made in the UI thread, in order to discourage developers from doing it, given that networking operations are thread-blocking.
Throughout the book, we will refer to the main thread of a GUI application both as a UI thread and as a main thread (because in Android, by default, the main thread is also the UI thread), while for command-line applications we will refer to it only as a main thread. Any thread different from those two will be called a background thread, unless a distinction between background threads is required, in which case each background thread will receive a unique identifier for clarity.
Given the way that the Kotlin has implemented concurrency, you will find that it's not necessary for you to manually start or stop a thread. The interactions that you will have with threads will commonly be limited to tell Kotlin to create or use a specific thread or pool of threads to run a coroutine – usually with one or two lines of code. The rest of the handling of threads will be done by the framework.
Coroutines
Kotlin's documentation often refers to coroutines as lightweight threads. This is mostly because, like threads, coroutines define the execution of a set of instructions for a processor to execute. Also, coroutines have a similar life cycle to that of threads.
A coroutine is executed inside a thread. One thread can have many coroutines inside it, but as already mentioned, only one instruction can be executed in a thread at a given time. This means that if you have ten coroutines in the same thread, only one of them will be running at a given point in time.
The biggest difference between threads and coroutines, though, is that coroutines are fast and cheap to create. Spawning thousands of coroutines can be easily done, it is faster and requires fewer resources than spawning thousands of threads.
Take this code as an example. Don't worry about the parts of the code you don't understand yet:
suspend fun createCoroutines(amount: Int) {
val jobs = ArrayList<Job>()
for (i in 1..amount) {
jobs += launch {
delay(1000)
}
}
jobs.forEach {
it.join()
}
}
This function creates as many coroutines as specified in the parameter amount, delays each one for a second, and waits for all of them to end before returning. This function can be called, for example, with 10,000 as the amount of coroutines:
fun main(args: Array<String>) = runBlocking {
val time = measureTimeMillis {
createCoroutines(10_000)
}
println("Took $time ms")
}
In a test environment, running it with an amount of 10,000 took around 1,160 ms, while running it with 100,000 took 1,649 ms. The increase in execution time is so small because Kotlin will use a pool of threads with a fixed size, and distribute the coroutines among those threads – so adding thousands of coroutines will have little impact. And while a coroutine is suspended – in this case because of the call to delay() – the thread it was running in will be used to execute another coroutine, one that is ready to be started or resumed.
How many threads are active can be determined by calling the activeCount() method of the Thread class. For example, let's update the main() function to do so:
fun main(args: Array<String>) = runBlocking {
println("${Thread.activeCount()} threads active at the start")
val time = measureTimeMillis {
createCoroutines(10_000)
}
println("${Thread.activeCount()} threads active at the end")
println("Took $time ms")
}
In the same test environment as before, it was found that in order to create 10,000 coroutines, only four threads needed to be created:

But once the value of the amount being sent to createCoroutines() is lowered to one, for example, only two threads are created:

It's important to understand that even though a coroutine is executed inside a thread, it's not bound to it. As a matter of fact, it's possible to execute part of a coroutine in a thread, suspend the execution, and later continue in a different thread. In our previous example this is happening already, because Kotlin will move coroutines to threads that are available to execute them. For example, by passing 3 as the amount to createCoroutines(), and updating the content of the launch() block so that it prints the current thread, we can see this in action:
suspend fun createCoroutines(amount: Int) {
val jobs = ArrayList<Job>()
for (i in 1..amount) {
jobs += launch {
println("Started $i in ${Thread.currentThread().name}")
delay(1000)
println("Finished $i in ${Thread.currentThread().name}")
}
}
jobs.forEach {
it.join()
}
}
You will find that in many cases they are being resumed in a different thread:

A thread can only execute one coroutine at a time, so the framework is in charge of moving coroutines between threads as necessary. As will be explained in detail later, Kotlin is flexible enough to allow the developer to specify which thread to execute a coroutine on, and whether or not to confine the coroutine to that thread.
Putting things together
So far, we have learned that an application is composed of one or more processes and that each process has one or more threads. We have also learned that blocking a thread means halting the execution of the code in that thread, and for that reason, a thread that interacts with a user is expected to never be blocked. We also know that a coroutine is basically a lightweight thread that resides in a thread but is not tied to one. The following diagram encapsulates the content of this section so far. Notice how each coroutine is started in one thread but at some point is resumed in a different one:

In a nutshell, concurrency occurs when an application runs in more than one thread at the same time. So in order for concurrency to happen, two or more threads need to be created, and both communication and synchronization of those threads will most likely be needed for correct functioning of the application.
Introduction to concurrency
Correct concurrent code is one that allows for a certain variability in the order of its execution while still being deterministic on the result. For this to be possible, different parts of the code need to have some level of independence, and some degree of orchestration may also be required. The best way to understand concurrency is by comparing sequential code with concurrent code. Let's start by looking at some non-concurrent code:
fun getProfile(id: Int) : Profile {
val basicUserInfo = getUserInfo(id)
val contactInfo = getContactInfo(id)
return createProfile(basicUserInfo, contactInfo)
}
If I ask you what is going to be obtained first, the user information or the contact information – assuming no exceptions – you will probably agree with me that 100% of the time the user information will be retrieved first. And you will be correct. That is, first and foremost, because the contact information is not being requested until the contact information has already been retrieved:

And that's the beauty of sequential code: you can easily see the exact order of execution, and you will never have surprises on that front. But sequential code has two big issues:
- It may perform poorly compared to concurrent code
- It may not take advantage of the hardware that it's being executed on
Let's say, for example, that both getUserInfo and getContactInfo call a web service, and each service will constantly take around one second to return a response. That means that getProfile will take not less than two seconds to finish, always. And since it seems like getContactInfo doesn't depend on getUserInfo, the calls could be done concurrently, and by doing so it would be possible can halve the execution time of getProfile.
Let's imagine a concurrent implementation of getProfile:
suspend fun getProfile(id: Int) {
val basicUserInfo = asyncGetUserInfo(id)
val contactInfo = asyncGetContactInfo(id)
createProfile(basicUserInfo.await(), contactInfo.await())
}
In this updated version of the code, getProfile() is a suspending function – notice the suspend modifier in its definition – and the implementation of asyncGetUserInfo() and asyncGetContactInfo() are asynchronous – which will not be shown in the example code to keep things simple.
Because asyncGetUserInfo() and asyncGetContactInfo() are written to run in different threads, they are said to be concurrent. For now, let's think of it as if they are being executed at the same time – we will see later that it's not necessarily the case, but will do for now. This means that the execution of asyncGetContactInfo() will not depend on the completion of asyncGetUserInfo(), so the requests to the web services could be done around at the same time. And since we know that each service takes around one second to return a response, createProfile() will be called around one second after getProfile() is started, sooner than it could ever be in the sequential version of the code, where it will always take at least two seconds to be called. Let's take a look at how this may look:

But in this updated version of the code, we don't really know if the user information will be obtained before the contact information. Remember, we said that each of the web services takes around one second, and we also said that both requests will be started at around the same time.
This means that if asyncGetContactInfo is faster than asyncGetUserInfo, the contact information will be obtained first; but the user information could be obtained first if asyncGetUserInfo returns first; and since we are at it, it could also happen that both of them return the information at the same time. This means that our concurrent implementation of getProfile, while possibly performing twice as fast as the sequential one, has some variability in its execution.
That's the reason there are two await() calls when calling createProfile(). What this is doing is suspending the execution of getProfile() until both asyncGetUserInfo() and asyncGetContactInfo() have completed. Only when both of them have completed createProfile() will be executed. This guarantees that regardless of which of the concurrent call ends first, the result of getProfile() will be deterministic.
And that's where the tricky part of concurrency is. You need to guarantee that no matter the order in which the semi-independent parts of the code are completed, the result needs to be deterministic. For this example, what we did was suspend part of the code until all the moving parts completed, but as we will see later in the book, we can also orchestrate our concurrent code by having it communicate between coroutines.
Concurrency is not parallelism
There's common confusion as to what the difference between concurrency and parallelism is. After all, both of them sound quite similar: two pieces of code running at the same time. In this section, we will define a clear line to divide both of them.
Let's start by going back to our non-concurrent example from the first section:
fun getProfile(id: Int) : Profile {
val basicUserInfo = getUserInfo(id)
val contactInfo = getContactInfo(id)
return createProfile(basicUserInfo, contactInfo)
}
If we go back to the timeline for this implementation of getProfile(), we will see that the timelines of getUserInfo() and getContactInfo() don't overlap.
The execution of getContactInfo() will happen after getUserInfo() has finished, always:

Let's now look again at the concurrent implementation:
suspend fun getProfile(id: Int) {
val basicUserInfo = asyncGetUserInfo(id)
val contactInfo = asyncGetContactInfo(id)
createProfile(basicUserInfo.await(), contactInfo.await())
}
A timeline for the concurrent execution of this code would be something like the following diagram. Notice how the execution of asyncGetUserInfo() and asyncGetContactInfo() overlaps, whereas createProfile() doesn't overlap with either of them:
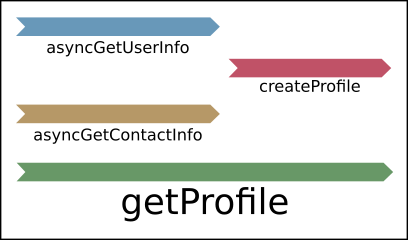
A timeline for the parallel execution would look exactly the same as the one above. The reason why both concurrent and parallel timelines look the same is because this timeline is not granular enough to reflect what is happening at a lower level.
The difference is that concurrency happens when the timeline of different sets of instructions in the same process overlaps, regardless of whether they are being executed at the exact same point in time or not. The best way to think of this is by picturing the code of getProfile() being executed in a machine with only one core. Because a single core would not be able to execute both threads at the same time, it would interleave between asyncGetUserInfo() and asyncGetContactInfo(), making their timelines overlap – but they would not be executing simultaneously.
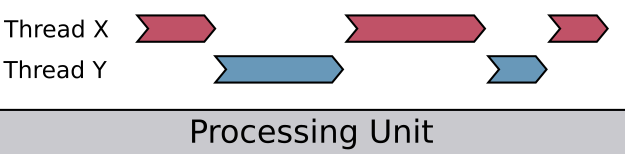
The following diagram is a representation of concurrency when it happens in a single core – it's concurrent but not parallel. A single processing unit will interleave between threads X and Y, and while both of their overall timelines overlap, at a given point in time only one of them is being executed:
Parallel execution, on the other hand, can only happen if both of them are being executed at the exact same point in time. For example, if we picture getProfile() being executed in a computer with two cores, one core executing the instructions of asyncGetUserInfo() while a second core is executing those of asyncGetContactInfo().
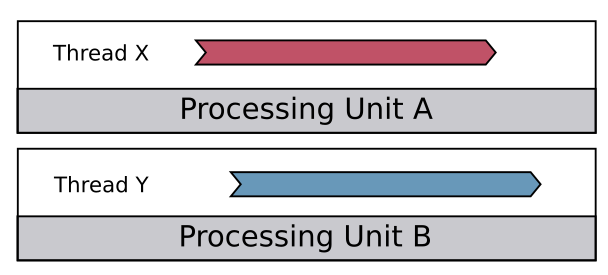
The following diagram is a representation of concurrent code being executed in parallel, using two processing units, each of them executing a thread independently. In this case, not only the timelines of thread X and Y are overlapping, but they are indeed being executed at the exact same point in time:
Here is a summarized explanation:
- Concurrency happens when there is overlapping in the timeline of two or more algorithms. For this overlap to happen, it's necessary to have two or more active threads of execution. If those threads are executed in a single core, they are not executed in parallel, but they are executed concurrently nonetheless, because that single core will interleave between the instructions of the different threads, effectively overlapping their execution.
- Parallelism happens when two algorithms are being executed at the exact same point in time. For this to be possible, it's required to have two or more cores and two or more threads, so that each core can execute the instructions of a thread simultaneously. Notice that parallelism implies concurrency, but concurrency can exist without parallelism.
As we will see in the next section, this difference is not just a technicality, and understanding it, along with understanding your code, will help you to write code that performs well.
CPU-bound and I/O-bound
Bottlenecks are the most important thing to understand when it comes to optimizing the performance of applications, because they will indicate the points in which any type of throttling occurs. In this section we will talk about how concurrency and parallelism can affect the performance of an algorithm based on whether it's bound to the CPU or to I/O operations.
CPU-bound
Many algorithms are built around operations that need only the CPU to be completed. The performance of such algorithms will be delimited by the CPU in which they are running, and solely upgrading the CPU will usually improve their performance.
Let's think, for example, of a simple algorithm that takes a word and returns whether it's a palindrome or not:
fun isPalindrome(word: String) : Boolean {
val lcWord = word.toLowerCase()
return lcWord == lcWord.reversed()
}
Now, let's consider that this function is called from another function, filterPalindromes(), which takes a list of words and returns the ones that are palindromes:
fun filterPalindromes(words: List<String>) : List<String> {
return words.filter { isPalindrome(it) }
}
Finally, filterPalindromes() is called from the main method of the application where a list of words has been already defined:
val words = listOf("level", "pope", "needle", "Anna", "Pete", "noon", "stats")
fun main(args: Array<String>) {
filterPalindromes(words).forEach {
println(it)
}
}
In this example, all the parts of the execution depend on the CPU. If the code is updated to send hundreds of thousands of words, filterPalindromes() will take longer. Also, if the code is executed in a faster CPU, the performance will be improved without code changes.
I/O-bound
I/O-bound, on the other hand, are algorithms that rely on input/output devices, so their execution times depend on the speed of those devices, for example, an algorithm that reads a file and passes each word in the document to filterPalindromes() in order to print the palindromes in the document. Changing a few lines of the previous example will do:
fun main(args: Array<String>) {
val words = readWordsFromJson("resources/words.json")
filterPalindromes(words).forEach {
println(it)
}
}
The readWordsFromJson() function will read the file from the filesystem. This is an I/O operation that will depend on the speed at which the file can be read. If the file is stored in a hard drive, the performance of the application will be worse than if the file is stored in an SSD, for example.
Many other operations, such as networking or receiving input from the peripherals of the computer, are also I/O operations. Algorithms that are I/O-bound will have performance bottleneck based on the I/O operations, and this means that optimizations are dependent on external systems or devices.
Concurrency versus parallelism in CPU-bound algorithms
CPU-bound algorithms will benefit from parallelism but probably not from single-core concurrency. For example, the previous algorithm that takes a list of words and filters the palindromes could be modified so that a thread is created per each 1,000 words received. So, if isPalindrome() receives 3,000 words, the execution could be represented like this:

Single-core execution
If this is executed in a single core, that core will then interleave between the three threads, each time filtering some of the words before switching to the next one. This interleaving process is called context switching.
Context switching adds overhead to the overall process, because it requires saving the state of the current thread and then loading the state of the next one. This overhead makes it likely that this multi-threaded implementation of isPalindrome() will take longer in a single-core machine when compared to the sequential implementation seen before. This happens because the sequential implementation will have one core do all the work but will avoid the context switch.
Parallel execution
If parallel execution is assumed, where each thread is executed in one dedicated core, then the execution of isPalindrome() could be around one third of that of the sequential implementation. Each core will filter its 1,000 words without interruption, reducing the total amount of time needed to complete the operation.
It's important to consider creating a reasonable amount of threads for CPU-bound algorithms, making this decision based on the amount of cores of the current device.. This can be leveraged by using Kotlin's CommonPool, which is a pool of threads created to run CPU-bound algorithms.
Concurrency versus parallelism in I/O-bound algorithms
As seen before, I/O-bound algorithms are constantly waiting on something else. This constant waiting allows single-core devices to use the processor to do other useful tasks while waiting. So concurrent algorithms that are I/O-bound will perform similarly regardless of the execution happening in parallel or in a single core.
It is expected that I/O-bound algorithms will always perform better in concurrent implementations than if they are sequential. So it's recommended for I/O operations to be always executed concurrently. As mentioned before, in GUI applications it's particularly important to not block the UI thread.
Why concurrency is often feared
Writing correct concurrent code is traditionally considered difficult. This is not only because of it being difficult, but also because many programming languages make it more difficult than it should be. Some languages make it too cumbersome, while others make it inflexible, reducing its usability. With that in mind, the Kotlin team tried to make concurrency as simple as possible while still making it flexible enough so that it can be adjusted to many different use cases. Later in the book, we will cover many of those use cases and will use many of the primitives that the Kotlin team has created, but for now let's take a look at common challenges presented when programming concurrent code.
As you can probably guess by now, most of the time it comes down to being able to synchronize and communicate our concurrent code so that changes in the flow of execution don't affect the operation of our application.
Race conditions
Race conditions, perhaps the most common error when writing concurrent code, happen when concurrent code is written but is expected to behave like sequential code. In more practical terms, it means that there is an assumption that concurrent code will always execute in a particular order.
For example, let's say that you are writing a function that has to concurrently fetch something from a database and call a web service. Then it has to do some computation once both operations are completed. It would be a common mistake to assume that going to the database will be faster, so many people may try to access the result of the database operation as soon as the web service operation is done, thinking that by that time the information from the database will always be ready. Whenever the database operation takes longer than the webservice call, the application will either crash or enter an inconsistent state.
A race condition happens, then, when a concurrent piece of software requires semi-independent operations to complete in a certain order to be able to work correctly. And this is not how concurrent code should be implemented.
Let's see a simple example of this:
data class UserInfo(val name: String, val lastName: String, val id: Int)
lateinit var user: UserInfo
fun main(args: Array<String>) = runBlocking {
asyncGetUserInfo(1)
// Do some other operations
delay(1000)
println("User ${user.id} is ${user.name}")
}
fun asyncGetUserInfo(id: Int) = async {
user = UserInfo(id = id, name = "Susan", lastName = "Calvin")
}
The main() function is using a background coroutine to get the information of a user, and after a delay of a second (simulating other tasks), it prints the name of the user. This code will work because of the one second delay. If we either remove that delay or put a higher delay inside asyncGetUserInfo(), the application will crash. Let's replace asyncGetUserInfo() with the following implementation:
fun asyncGetUserInfo(id: Int) = async {
delay(1100)
user = UserInfo(id = id, name = "Susan", lastName = "Calvin")
}
Executing this will cause main() to crash while trying to print the information in user, which hasn't been initialized. To fix this race condition, it is important to explicitly wait until the information has been obtained before trying to access it.
Atomicity violation
Atomic operations are those that have non-interfered access to the data they use. In single-thread applications, all the operations will be atomic, because the execution of all the code will be sequential – and there can't be interference if only one thread is running.
Atomicity is wanted when the state of an object can be modified concurrently, and it needs to be guaranteed that the modification of that state will not overlap. If the modification can overlap, that means that data loss may occur due to, for example, one coroutine overriding a modification that another coroutine was doing. Let's see it in action:
var counter = 0
fun main(args: Array<String>) = runBlocking {
val workerA = asyncIncrement(2000)
val workerB = asyncIncrement(100)
workerA.await()
workerB.await()
print("counter [$counter]")
}
fun asyncIncrement(by: Int) = async {
for (i in 0 until by) {
counter++
}
}
This is a simple example of atomicity violation. The previous code executes the asyncIncrement() coroutine twice, concurrently. One of those calls will increment counter 2,000 times, while the other will do it 100 times. The problem is that both executions of asyncIncrement() may interfere with each other, and they may override increments made by the other instance of the coroutine. This means that while most executions of main() will print counter [2100], many other executions will print values lower than 2,100:

In this example, the lack of atomicity in counter++ results in two iterations, one of workerA and the other of workerB, increasing the value of counter by only one, when those two iterations should increase the value a total of two times. Each time this happens, the value will be one less than the expected 2,100.
The overlapping of the instructions in the coroutines happens because the operation counter++ is not atomic. In reality, this operation can be broken into three instructions: reading the current value of counter, increasing that value by one, and then storing the result of the addition back into counter. The lack of atomicity in counter++ makes it possible for the two coroutines to read and modify the value, disregarding the operations made by the other.
Deadlocks
Often, in order to guarantee that concurrent code is synchronized correctly, it's necessary to suspend or block execution while a task is completed in a different thread. But due to the complexity of these situations, it isn't uncommon to end up in a situation where the execution of the complete application is halted because of circular dependencies:
lateinit var jobA : Job
lateinit var jobB : Job
fun main(args: Array<String>) = runBlocking {
jobA = launch {
delay(1000)
// wait for JobB to finish
jobB.join()
}
jobB = launch {
// wait for JobA to finish
jobA.join()
}
// wait for JobA to finish
jobA.join()
println("Finished")
}
Let's take a look at a simple flow diagram of jobA.

In this example, jobA is waiting for jobB to finish its execution; meanwhile jobB is waiting for jobA to finish. Since both are waiting for each other, none of them is ever going to end; hence the message Finished will never be printed:

This example is, of course, intended to be as simple as possible, but in real-life scenarios deadlocks are more difficult to spot and correct. They are commonly caused by intricate networks of locks, and often happen hand-in-hand with race conditions. For example, a race condition can create an unexpected state in which the deadlock can happen.
Livelocks
Livelocks are similar to deadlocks, in the sense that they also happen when the application can't correctly continue its execution. The difference is that during a livelock the state of the application is constantly changing, but the state changes in a way that further prevents the application from resuming normal execution.
Commonly, a livelock is explained by picturing two people, Elijah and Susan, walking in opposite directions in a narrow corridor. Both of them try to avoid the other by moving to one side: Elijah moves to the left while Susan moves to the right, but since they are walking in opposite directions, they are now blocking each other's way. So, now Elijah moves to the right, just at the same time that Susan moves to the left: once again they are unable to continue on their way. They continue moving like this, and thus they continue to block each other:

In this example, both Elijah and Susan have an idea of how to recover from a deadlock—each blocking the other—but the timing of their attempts to recover further obstructs their progress.
As expected, livelocks often happen in algorithms designed to recover from a deadlock. By trying to recover from the deadlock, they may in turn create a livelock.
Concurrency in Kotlin
Now that we have covered the basics of concurrency, it's a good time to discuss the specifics of concurrency in Kotlin. This section will showcase the most differentiating characteristics of Kotlin when it comes to concurrent programming, covering both philosophical and technical topics.
Non-blocking
Threads are heavy, expensive to create, and limited—only so many threads can be created—So when a thread is blocked it is, in a way, being wasted. Because of this, Kotlin offers what is called Suspendable Computations; these are computations that can suspend their execution without blocking the thread of execution. So instead of, for example, blocking thread X to wait for an operation to be made in a thread Y, it's possible to suspend the code that has to wait and use thread X for other computations in the meantime.
Furthermore, Kotlin offers great primitives like channels, actors, and mutual exclusions, which provide mechanisms to communicate and synchronize concurrent code effectively without having to block a thread.
Being explicit
Concurrency needs to be thought about and designed for, and because of that, it's important to make it explicit in terms of when a computation should run concurrently. Suspendable computations will run sequentially by default. Since they don't block the thread when suspended, there's no direct drawback:
fun main(args: Array<String>) = runBlocking {
val time = measureTimeMillis {
val name = getName()
val lastName = getLastName()
println("Hello, $name $lastName")
}
println("Execution took $time ms")
}
suspend fun getName(): String {
delay(1000)
return "Susan"
}
suspend fun getLastName(): String {
delay(1000)
return "Calvin"
}
In this code, main() executes the suspendable computations getName() and getLastName() in the current thread, sequentially.
Executing main() will print the following:

This is convenient because it's possible to write non-concurrent code that doesn't block the thread of execution. But after some time and analysis, it becomes clear that it doesn't make sense to have getLastName() wait until after getName() has been executed since the computation of the latter has no dependency on the former. It's better to make it concurrent:
fun main(args: Array<String>) = runBlocking {
val time = measureTimeMillis {
val name = async { getName() }
val lastName = async { getLastName() }
println("Hello, ${name.await()} ${lastName.await()}")
}
println("Execution took $time ms")
}
Now, by calling async {...} it's clear that both of them should run concurrently, and by calling await() it's requested that main() is suspended until both computations have a result:

Readable
Concurrent code in Kotlin is as readable as sequential code. One of the many problems with concurrency in other languages like Java is that often it's difficult to read, understand, and/or debug concurrent code. Kotlin's approach allows for idiomatic concurrent code:
suspend fun getProfile(id: Int) {
val basicUserInfo = asyncGetUserInfo(id)
val contactInfo = asyncGetContactInfo(id)
createProfile(basicUserInfo.await(), contactInfo.await())
}
This suspend method calls two methods that will be executed in background threads and waits for their completion before processing the information. Reading and debugging this code is as simple as it would be for sequential code.
Leveraged
Creating and managing threads is one of the difficult parts of writing concurrent code in many languages. As seen before, it's important to know when to create a thread, and almost as important to know how many threads are optimal. It's also important to have threads dedicated to I/O operations, while also having threads to tackle CPU-bound operations. And communicating/syncing threads is a challenge in itself.
Kotlin has high-level functions and primitives that make it easier to implement concurrent code:
- To create a thread it's enough to call newSingleThreadContext(), a function that only takes the name of the thread. Once created, that thread can be used to run as many coroutines as needed.
- Creating a pool of threads is as easy, by calling newFixedThreadPoolContext() with the size and the name of the pool.
- CommonPool is a pool of threads optimal for CPU-bound operations. Its maximum size is the amount of cores in the machine minus one.
- The runtime will take charge of moving a coroutine to a different thread when needed .
- There are many primitives and techniques to communicate and synchronize coroutines, such as channels, mutexes, and thread confinement.
Flexible
Kotlin offers many different primitives that allow for simple-yet-flexible concurrency. You will find that there are many ways to do concurrent programming in Kotlin. Here is a list of some of the topics we will look at throughout the book:
- Channels: Pipes that can be used to safely send and receive data between coroutines.
- Worker pools: A pool of coroutines that can be used to divide the processing of a set of operations in many threads.
- Actors: A wrapper around a state that uses channels and coroutines as a mechanism to offer the safe modification of a state from many different threads.
- Mutual exclusions (Mutexes): A synchronization mechanism that allows the definition of a critical zone so that only one thread can execute at a time. Any coroutine trying to access the critical zone will be suspended until the previous coroutine leaves.
- Thread confinement: The ability to limit the execution of a coroutine so that it always happens in a specified thread.
- Generators (Iterators and sequences): Data sources that can produce information on demand and be suspended when no new information is required.
All of these are tools that are at your fingertips when writing concurrent code in Kotlin, and their scope and use will help you to make the right choices when implementing concurrent code.
Concepts and terminology
To end this chapter, we will cover some basic concepts and terminology when talking about concurrency in Kotlin; these are important in order to more clearly understand the upcoming chapters.
Suspending computations
Suspending computations are those computations that can suspend their execution without blocking the thread in which they reside. Blocking a thread is often inconvenient, so by suspending its own execution, a suspending computation allows the thread to be used for other computations until they need to be resumed.
Suspending functions
Suspending functions are suspending computations in the shape of a function. A suspending function can be easily identified because of the modifier suspend. For example:
suspend fun greetAfter(name: String, delayMillis: Long) {
delay(delayMillis)
println("Hello, $name")
}
In the previous example, the execution of greetAfter() will be suspended when delay() is called – delay() is a suspending function itself, suspending the execution for a give duration. Once delay() has been completed, greetAfter() will resume its execution normally. And while greetAfter() is suspended, the thread of execution may be used to do other computations.
Suspending lambdas
Similar to a regular lambda, a suspending lambda is an anonymous local function. The difference is that a suspending lambda can suspend its own execution by calling other suspending functions.
Coroutine dispatcher
In order to decide what thread to start or resume a coroutine on, a coroutine dispatcher is used. All coroutine dispatchers must implement the CoroutineDispatcher interface:
- DefaultDispatcher: Currently it is the same as CommonPool. In the future, this may change.
- CommonPool: Executes and resumes the coroutines in a pool of shared background threads. Its default size makes it optimal for use in CPU-bound operations.
- Unconfined: Starts the coroutine in the current thread (the thread from which the coroutine was invoked), but will resume the coroutine in any thread. No thread policy is used by this dispatcher.
Along with these dispatchers, there are a couple of builders that can be used to define pools or threads as needed:
- newSingleThreadContext() to build a dispatcher with a single thread; the coroutines executed here will be started and resumed in the same thread, always.
- newFixedThreadPoolContext() creates a dispatcher with a pool of threads of the given size. The runtime will decide which thread to use when starting and resuming the coroutines executed in the dispatcher.
Coroutine builders
A coroutine builder is a function that takes a suspending lambda and creates a coroutine to run it. Kotlin provides many coroutine builders that adjust to many different common scenarios, such as:
- async(): Used to start a coroutine when a result is expected. It has to be used with caution because async() will capture any exception happening inside the coroutine and put it in its result. Returns a Deferred<T> that contains either the result or the exception.
- launch(): Starts a coroutine that doesn't return a result. Returns a Job that can be used to cancel its execution or the execution of its children.
- runBlocking(): Created to bridge blocking code into suspendable code. It's commonly used in main() methods and unit tests. runBlocking() blocks the current thread until the execution of the coroutine is completed.
Here is an example of async():
val result = async {
isPalindrome(word = "Sample")
}
result.await()
In this example, async() is executed in the default dispatcher. It is possible to manually specify the dispatcher:
val result = async(Unconfined) {
isPalindrome(word = "Sample")
}
result.await()
In this second example, Unconfined is used as the dispatcher of the coroutine.
Summary
This chapter was a detailed introduction to many important concepts and tools involved in concurrency, and acts as a foundation for the upcoming chapters. So here's a summary to help you remember some of the most important points that we discussed:
- An application has one or more processes; each of them has at least one thread, and coroutines are executed inside a thread.
- A coroutine can be executed in a different thread each time it's resumed, but can also be confined to a specific thread.
- An application is concurrent when its execution happens in more than one overlapping thread.
- To write correct concurrent code, it's necessary to learn how to communicate and synchronize the different threads, which in Kotlin implies the communication and synchronization of coroutines.
- Parallelism happens when, during the execution of a concurrent application, at least two threads are effectively being executed simultaneously.
- Concurrency can happen without parallelism because modern processing units will interleave between threads, effectively overlapping threads.
- There are many challenges when it comes to writing concurrent code, most of them related to correct communication and the synchronization of threads. Race conditions, atomicity violations, deadlocks, and livelocks are examples of the most common challenges.
- Kotlin has taken a modern and fresh approach to concurrency. With Kotlin, it's possible and encouraged to write non-blocking, readable, leveraged, and flexible concurrent code.
In the next chapter, we will work with coroutines. We will start by configuring Android Studio and creating a project that supports coroutines. Then we will write and run concurrent code in an Android emulator, using coroutines for real-world scenarios such as REST calls. We will look at practical examples of suspending functions.





