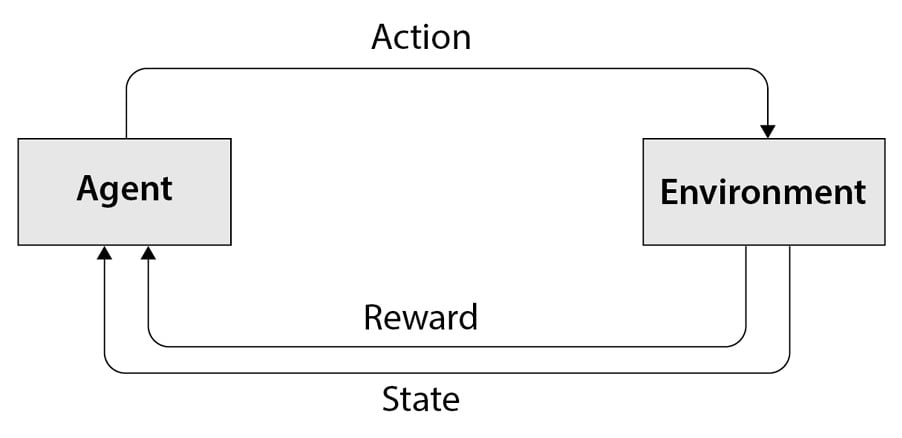
Deep Neural Architecture Search
The previous chapters introduced and recapped different neural networks (NNs) that are designed to handle different types of data. Designing these networks requires knowledge and intuition that can only be gained by consuming years of research in the field. The bulk of these networks are hand-designed by experts and researchers. This includes inventing completely novel NN layers and constructing an actually usable architecture by combining and stacking NN layers that already exist. Both tasks require a ton of iterative experimentation time to burn to actually achieve success in creating a network that is useful.
Now, imagine a world where we can focus on inventing useful novel layers while the software takes care of automating the final architecture-building process. Automated architecture search methods help to accomplish exactly that by streamlining the task of designing the best final NN architecture, as long as appropriate search spaces are selected...