





















































Why Do Neural Networks Work So Well?
Why are neural networks so powerful? Neural networks are powerful because they can be used to predict any given function with reasonable approximation. If we can represent a problem as a mathematical function and we have data that represents that function correctly, a deep learning model can, given enough resources, be able to approximate that function. This is typically called the Universal Approximation Theorem. For more information, refer to Michael Nielsen: Neural Networks and Deep Learning: A visual proof that neural nets can compute any function, available at http://neuralnetworksanddeeplearning.com/chap4.html.
We will not be exploring mathematical proofs of the universality principle in this book. However, two characteristics of neural networks should give you the right intuition on how to understand that principle: representation learning and function approximation.
Note
For more information, refer to A Brief Survey of Deep Reinforcement Learning, Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath, arXiv, September 28, 2017, available at https://www.arxiv-vanity.com/papers/1708.05866/.
Representation Learning
The data used to train a neural network contains representations (also known as features) that explain the problem you are trying to solve. For instance, if we are interested in recognizing faces from images, the color values of each pixel from a set of images that contain faces will be used as a starting point. The model will then continuously learn higher-level representations by combining pixels together as it goes through its training process. A pictorial depiction is displayed here:

Figure 1.1: A series of higher-level representations based on input data
Note
Figure 1.1 is a derivate image based on an original image from Yann LeCun, Yoshua Bengio, and Geoffrey Hinton in Deep Learning, published in Nature, 521, 436–444 (28 May 2015) doi:10.1038/ nature14539. You can find the paper at: https://www.nature.com/articles/nature14539.
In formal words, neural networks are computation graphs in which each step computes higher abstraction representations from input data. Each of these steps represents a progression into a different abstraction layer. Data progresses through each of these layers, thereby building higher-level representations. The process finishes with the highest representation possible: the one the model is trying to predict.
Function Approximation
When neural networks learn new representations of data, they do so by combining weights and biases with neurons from different layers. They adjust the weights of these connections every time a training cycle occurs using a mathematical technique called backpropagation. The weights and biases improve at each round, up to the point that an optimum is achieved. This means that a neural network can measure how wrong it is on every training cycle, adjust the weights and biases of each neuron, and try again. If it determines that a certain modification produces better results than the previous round, it will invest in that modification until an optimal solution is achieved.
So basically, in a single cycle, three things happen. The first one is forward propagation where we calculate the results using weights, biases, and inputs. In the second step, we calculate how far the calculated value is from the expected value using a loss function. The final step is to update the weights and biases moving in the reverse direction of forward propagation, which is called backpropagation.
Since the weights and biases in the earlier layers do not have a direct connection with the later layers, we use a mathematical tool called the chain rule to calculate new weights for the earlier layers. Basically, the change in the earlier layer is equal to the multiplication of the gradients or derivatives of all the layers below it.
In a nutshell, that procedure is the reason why neural networks can approximate functions. However, there are many reasons why a neural network may not be able to predict a function with perfection, chief among them being the following:
- Many functions contain stochastic properties (that is, random properties).
- There may be overfitting to peculiarities from the training data. Overfitting is a situation where the model we are training doesn't generalize well to data it has never seen before. It just learns the training data instead of finding some interesting patterns.
- There may be a lack of training data.
In many practical applications, simple neural networks can approximate a function with reasonable precision. These sorts of applications will be our focus throughout this book.
Limitations of Deep Learning
Deep learning techniques are best suited to problems that can be defined with formal mathematical rules (such as data representations). If a problem is hard to define this way, it is likely that deep learning will not provide a useful solution. Moreover, if the data available for a given problem is either biased or only contains partial representations of the underlying functions that generate that problem, deep learning techniques will only be able to reproduce the problem and not learn to solve it.
Remember that deep learning algorithms learn different representations of data to approximate a given function. If data does not represent a function appropriately, it is likely that the function will be incorrectly represented by the neural network. Consider the following analogy: you are trying to predict the national prices of gasoline (that is, fuel) and create a deep learning model. You use your credit card statement with your daily expenses on gasoline as an input data for that model. The model may eventually learn the patterns of your gasoline consumption, but it will likely misrepresent price fluctuations of gasoline caused by other factors only represented weekly in your data such as government policies, market competition, international politics, and so on. The model will ultimately yield incorrect results when used in production.
To avoid this problem, make sure that the data used to train a model represents the problem the model is trying to address as accurately as possible.
Inherent Bias and Ethical Considerations
Researchers have suggested that the use of deep learning models without considering the inherent bias in the training data can lead not only to poorly performing solutions but also to ethical complications.
For instance, in late 2016, researchers from the Shanghai Jiao Tong University in China created a neural network that correctly classified criminals using only pictures of their faces. The researchers used 1,856 images of Chinese men, of which half had been convicted. Their model identified inmates with 89.5% accuracy.
Note
To know more about this, refer to https://blog.keras.io/the-limitations-of-deep-learning.html and MIT Technology Review. Neural Network Learns to Identify Criminals by Their Faces, November 22, 2016, available at https://www.technologyreview.com/2016/11/22/107128/neural-network-learns-to-identify-criminals-by-their-faces/.
The paper resulted in a great furor within the scientific community and popular media. One key issue with the proposed solution is that it fails to properly recognize the bias inherent in the input data. Namely, the data used in this study came from two different sources: one for criminals and one for non-criminals. Some researchers suggest that their algorithm identifies patterns associated with the different data sources used in the study instead of identifying relevant patterns from people's faces. While there are technical considerations that we can make about the reliability of the model, the key criticism is on ethical grounds: researchers ought to clearly recognize the inherent bias in input data used by deep learning algorithms and consider how its application will impact on people's lives. Timothy Revell. Concerns as face recognition tech used to 'identify' criminals. New Scientist. December 1, 2016. Available at: https://www.newscientist.com/article/2114900-concerns-as-face-recognition-tech-used-to-identify-criminals/.
There are different types of biases that can occur in a dataset. Consider a case where you are building an automatic surveillance system that can operate both in the daytime and nighttime. So, if your dataset just included images from the daytime, then you would be introducing a sample bias in the model. This could be eliminated by including nighttime data and covering all the different types of cases possible, such as images from a sunny day, a rainy day, and so on. Another example to consider is where, let's suppose, a similar kind of system is installed in a workplace to analyze the workers and their activities. Now, if your model has been fed with thousands of examples with men coding and women cooking, then this data clearly reflects stereotypes. A solution to this problem is the same as earlier: to expose the model to data that is more evenly distributed.
Note
To find out more about the topic of ethics in learning algorithms (including deep learning), refer to the work done by the AI Now Institute (https://ainowinstitute.org/), an organization created for the understanding of the social implications of intelligent systems.
Common Components and Operations of Neural Networks
Neural networks have two key components: layers and nodes.
Nodes are responsible for specific operations, and layers are groups of nodes that differentiate different stages of the system. Typically, neural networks are comprised of the following three layers:
- Input layer: Where the input data is received and interpreted
- Hidden layer: Where computations take place, modifying the data as it passes through
- Output layer: Where the output is assembled and evaluated
The following figure displays the working of layers of neural networks:
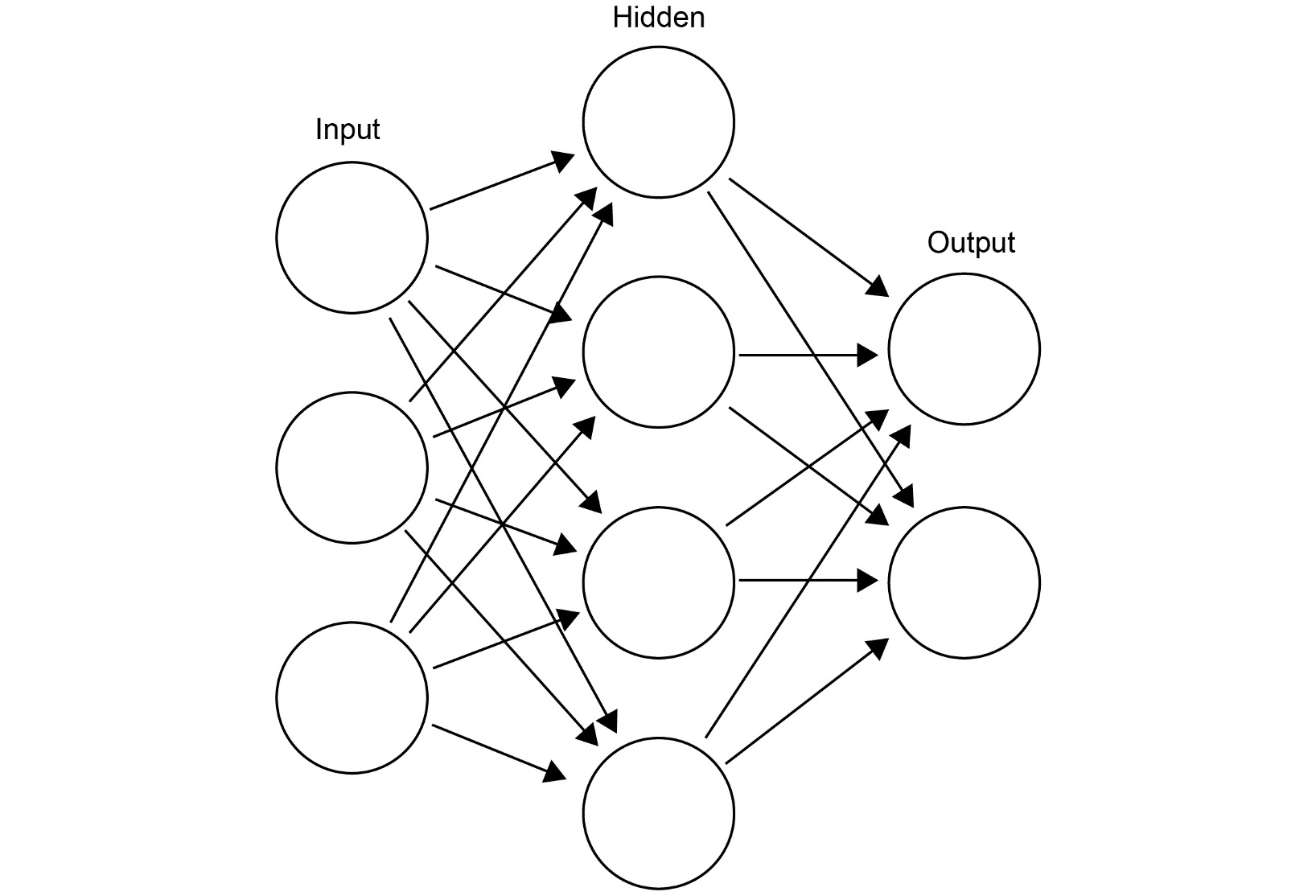
Figure 1.2: An illustration of the most common layers in a neural network
Hidden layers are the most important layers in neural networks. They are referred to as hidden because the representations generated in them are not available in the data, but are learned from it instead. It is within these layers where the main computations take place in neural networks.
Nodes are where data is represented in the network. There are two values associated with nodes: biases and weights. Both values affect how data is represented by the nodes and passed on to other nodes. When a network learns, it effectively adjusts these values to satisfy an optimization function.
Most of the work in neural networks happens in the hidden layers. Unfortunately, there isn't a clear rule for determining how many layers or nodes a network should have. When implementing a neural network, you will probably spend time experimenting with different combinations of layers and nodes. It is advisable to always start with a single layer and also with a number of nodes that reflect the number of features the input data has (that is, how many columns are available in a given dataset).
You can continue to add layers and nodes until a satisfactory performance is achieved—or whenever the network starts overfitting to the training data. Also, note that this depends very much on the dataset – if you were training a model to recognize hand-drawn digits, then a neural network with two hidden layers would be enough, but if your dataset was more complex, say for detecting objects like cars and ambulance in images, then even 10 layers would not be enough and you would need to have a deeper network for the objects to be recognized correctly.
Likewise, if you were using a network with 100 hidden layers for training on handwritten digits, then there would be a strong possibility that you would overfit the model, as that much complexity would not be required by the model in the first place.
Contemporary neural network practice is generally restricted to experimentation with the number of nodes and layers (for example, how deep the network is), and the kinds of operations performed at each layer. There are many successful instances in which neural networks outperformed other algorithms simply by adjusting these parameters.
To start off with, think about data entering a neural network system via the input layer, and then moving through the network from node to node. The path that data takes will depend on how interconnected the nodes are, the weights and the biases of each node, the kind of operations that are performed in each layer, and the state of the data at the end of such operations. Neural networks often require many runs (or epochs) in order to keep tuning the weights and biases of nodes, meaning that data flows over the different layers of the graph multiple times.



















