





















































The R language has been in the community since the 90's (even though it was developed a decade before). With its open source GNU license, R gained popularity for its no-fuss installation and ability to evoke any available package for additional statistical learning functions. This was a clear advantage to R as there were not that many statistical programs available on the market in the '80s and '90s; in addition, most of them were not free. The extensibility with emerging new packages for the core R engine gave a broader community and users more and more abilities to use the R language for multiple purposes, in addition to its strong statistical analysis and predictive modeling capabilities.
SQL Server 2005 introduced SQL Server Analysis Services (SSAS) data mining features to be applied against the customer's existing rich data stored in SQL Server and SSAS OLAP cubes. This feature allows users to use Data Mining eXpression (DMX) for creating predictive queries. In the next couple of years, several questions, requests, and ideas emerged on SQL forums, blogs, and community websites regarding additional statistical and predictive methods and approaches.
Back in 2011, I started working on the idea of extending the capabilities of statistical analysis in SQL Server 2008 R2 with the help of open source R language. One reason for that decision was to have flexibility of running statistical analysis (from data provisioning to multivariate analysis) without feeding the data into OLAP cube first, and another reason was more business orientated, with the need to get faster, statistical insights from all the people involved in data preparing, data munging, and data cleaning.
I kicked in and started working on a framework that was based on a combination of T-SQL stored procedure and R package RODBC (https://cran.r-project.org/web/packages/RODBC). The idea was simple; get the transactional or OLAP data, select the columns you want to perform analysis against, and the analysis itself (from simple to predictive analytics, which would stretch beyond SSAS, T-SQL, or CLR capabilities):
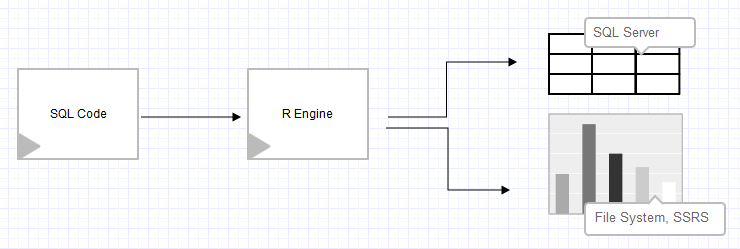
The framework was far from simple, and calling the procedure considered calling a mixture of R code, T-SQL select statements, and configurations to your R engine.
The stored procedure with all its parameters looked like this:
EXECUTE AdventureWorks2012.dbo.sp_getStatistics
@TargetTable = '[vStoreWithAddresses]'
,@Variables = 'Name'
,@Statistics = '8'
,@ServerName = 'WORKSTATION-31'
,@DatabaseName = 'AdventureWorks2012'
,@WorkingDirectory = 'C:\DataTK'
,@RPath = 'C:\Program Files\R\R-3.0.3\bin';
The nuts and bolts explanation is outside the scope of this book and is well-documented at: http://www.sqlservercentral.com/articles/R+Language/106760/.
Looking back on this framework and the feedback from the community and people on forums, it was accepted positively and many commented that they needed something similar for their daily business.
The framework in general had, besides pioneering the idea and bringing R engine one step closer to SQL Server, many flaws. The major one was security. Because it needed access to a working local directory for generating R files to be run by the vanilla R engine, it needed xp_cmdshell enabled. The following reconfiguration was mandatory and many sysadmins would not approve of it:
EXECUTE SP_CONFIGURE 'xp_cmdshell', 1;
GO
RECONFIGURE;
GO
EXECUTE SP_CONFIGURE 'Ole Automation Procedures', 1;
GO
RECONFIGURE;
GO
In addition, the framework needed to have access to R engine installation, together with R packages to execute the desired code. Installing open source programs and providing read/write access was again a drawback in terms of security and corporate software decisions. Nevertheless, one of the bigger issues—later when everything was installed and put into production—was performance and memory issues. R is memory-based, meaning all the computations are done in the memory. So, if your dataset is bigger than the size of the available memory, the only result you will get will be error messages. Another aspect of performance issues was also the speed. With no parallel and distributive computations, the framework was bound to dexterity of an author of the package. For example, if the package was written in C or C++, rather than in Fortran, the framework performed better, respectively.
The great part of this framework was the ability to deliver results from statistical analysis or predictive modeling much faster, because it could take OLTP or any other data that needed statistical analysis. Furthermore, statisticians and data scientists could prepare the R code that was stored in the table, which was later run by data wranglers, data analysts, or data stewards. Therefore, one version of truth is maintained, because there was no need for data movement or data copying and all users were reading the same data source. In terms of predictive modeling, the framework also enabled users to take advantage of various additional predictive algorithms (for example, decision forest, glm, CNN, SVM, and word cloud) that were not part of SSAS Data Mining at that time.
Besides the pros and cons, the framework was a successful initial attempt to get more data insights that were easily distributable among different business units through pushing visualizations in SQL Server Reporting Services. In the years prior to the release of SQL Server 2016, I had met people from the SQL Server community that developed similar frameworks, in order to push predictions to the SQL Server database to support business applications and solutions. With SQL Server 2016, many such similar solutions were internalized and brought closer to the SQL Server engine to achieve better performance and to address many of the issues and cons.



















