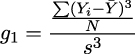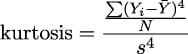Chapter 15
Project 5.1: Modeling Base Application
The next step in the pipeline from acquisition to clean-and-convert is the analysis and some preliminary modeling of the data. This may lead us to use the data for a more complex model or perhaps machine learning. This chapter will guide you through creating another application in the three-stage pipeline to acquire, clean, and model a collection of data. This first project will create the application with placeholders for more detailed and application-specific modeling components. This makes it easier to insert small statistical models that can be replaced with more elaborate processing if needed.
In this chapter, we’ll look at two parts of data analysis:
CLI architecture and how to design a more complex pipeline of processes for gathering and analyzing data
The core concepts of creating a statistical model of the data
Viewed from a distance, all analytical work can be considered to be creating a simplified model of important...