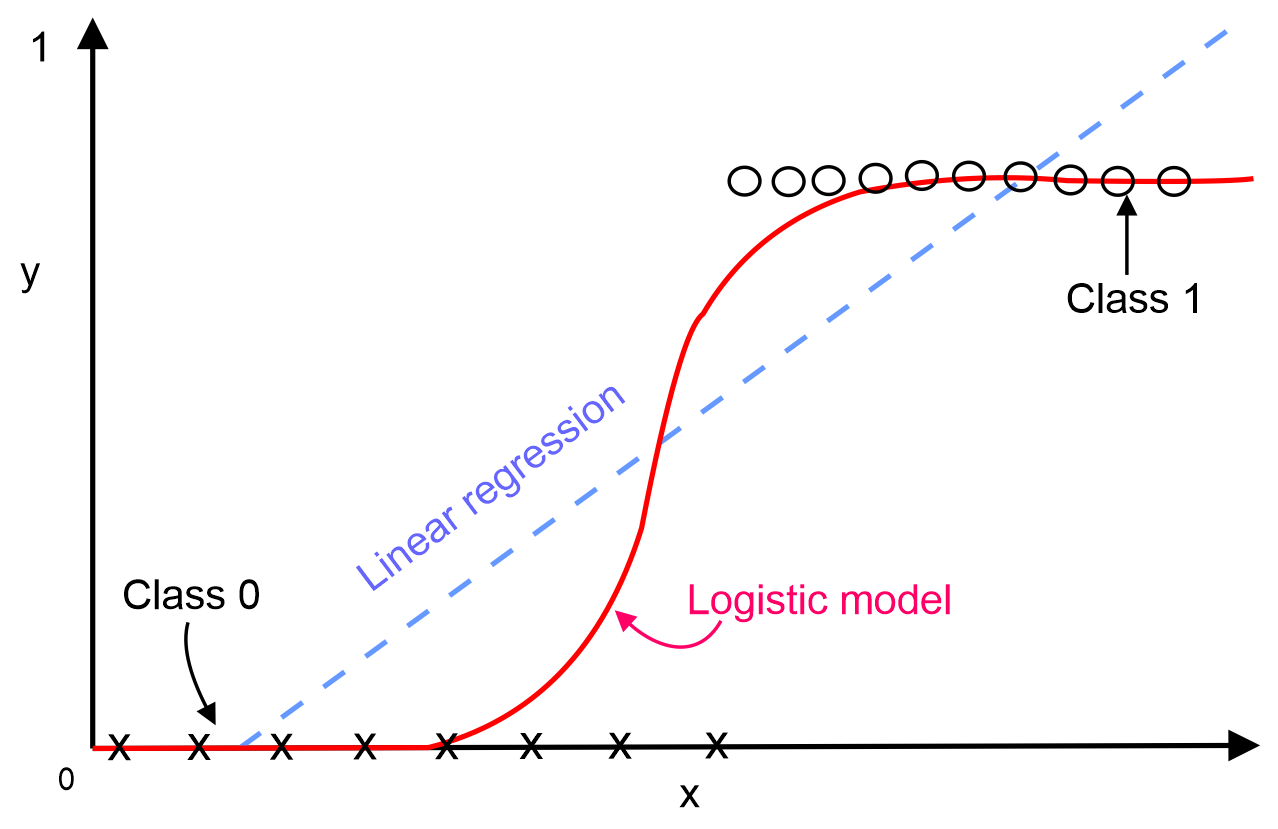
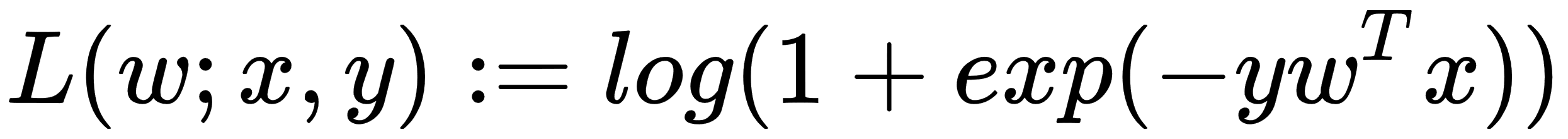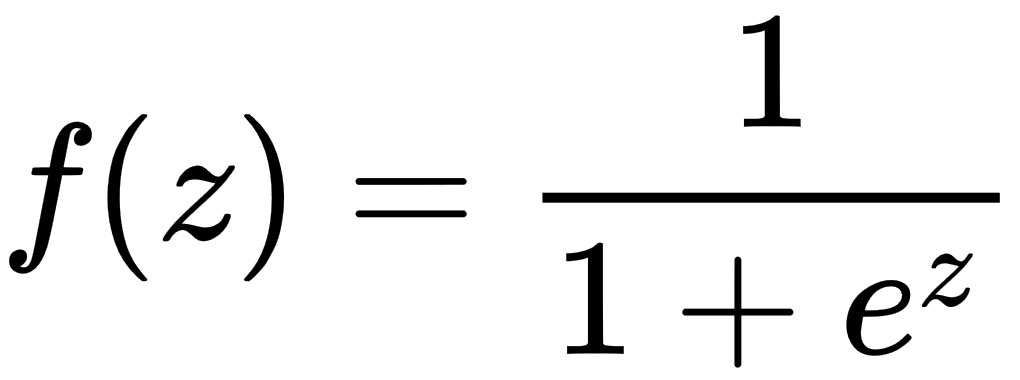In the previous chapter, we saw how to develop a predictive model for analyzing insurance severity claims as a regression analysis problem. We applied very simple linear regression, as well as generalized linear regression (GLR).
In this chapter, we'll learn about another supervised learning task, called classification. We'll use widely used algorithms such as logistic regression, Naive Bayes (NB), and Support Vector Machines (SVMs) to analyze and predict whether a customer is likely to cancel the subscription of their telecommunication contract or not.
In particular, we will cover the following topics:
- Introduction to classification
- Learning classification with a real-life example
- Logistic regression for churn prediction
- SVM for churn prediction
- NB for prediction