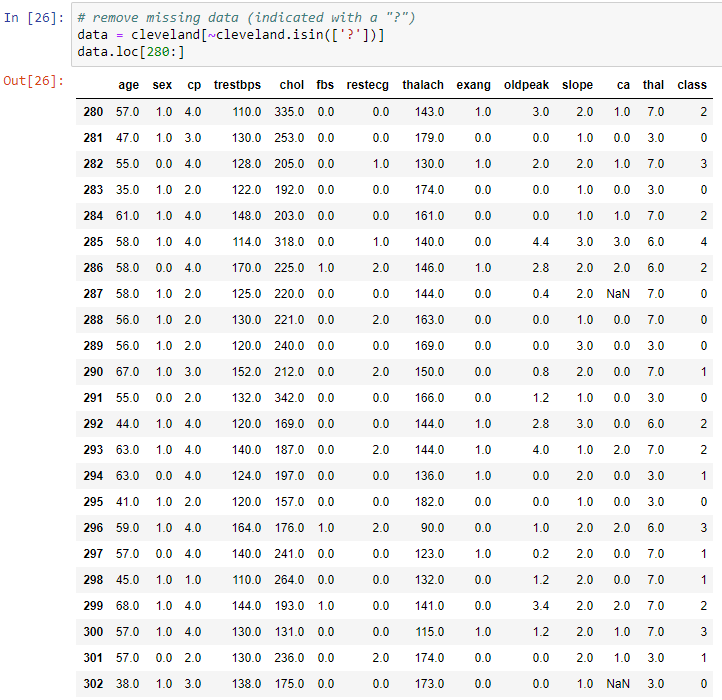
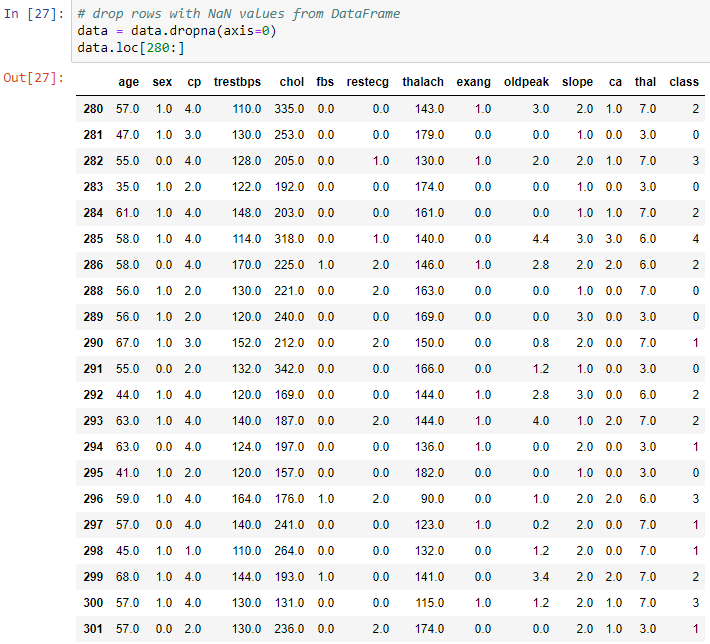
In this chapter, we will be predicting heart disease using neural networks. We will also be looking at a dataset from the UCI repository, which has data on 76 health-related attributes for over 300 patients. We will use this data to predict coronary artery disease. So, if you're looking to get started with machine learning in general—or, more specifically, machine learning applications in the field of healthcare; then this is the project for you.
In this chapter, we will familiarize ourselves with the following topics:
- The dataset
- Fixing missing data
- Splitting the dataset
- Training the neural network
- A comparison of categorical and binary problems