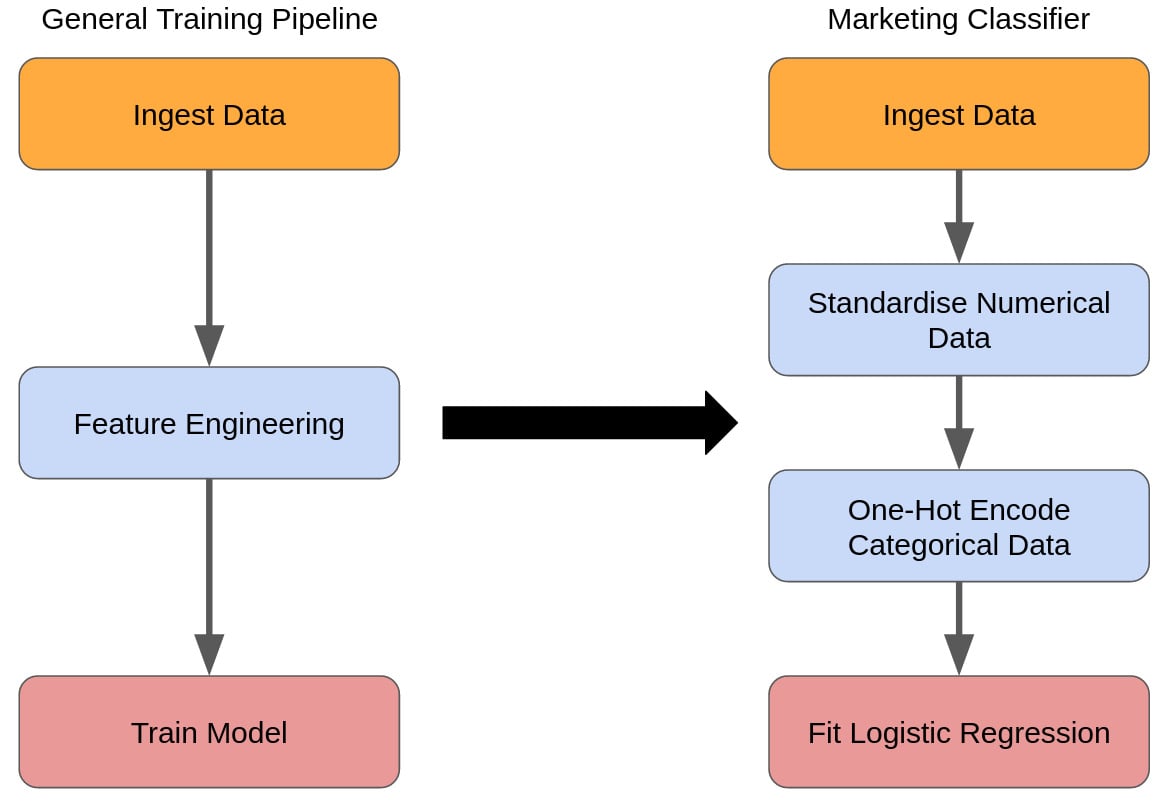
Train-persist
Option 2 is that training runs in batch, while prediction runs in whatever mode is deemed appropriate, with the prediction solution reading in the trained model from a store. We will call this design pattern train-persist. This is shown in the following diagram:
If we are going to train our model and then persist the model so that it can be picked up later by a prediction process, then we need to ensure a few things are in place:
- What are our model storage options?
- Is there a clear mechanism for accessing our model store (writing to and reading from)?
- How often should we train versus how often will we predict?
In our case, we will solve the first two questions by using MLflow, which we introduced in Chapter 2, The Machine Learning Development Process, but will revisit in later sections. There are also lots of other solutions available. The key point is that no matter what you use as a model store and handover point between...