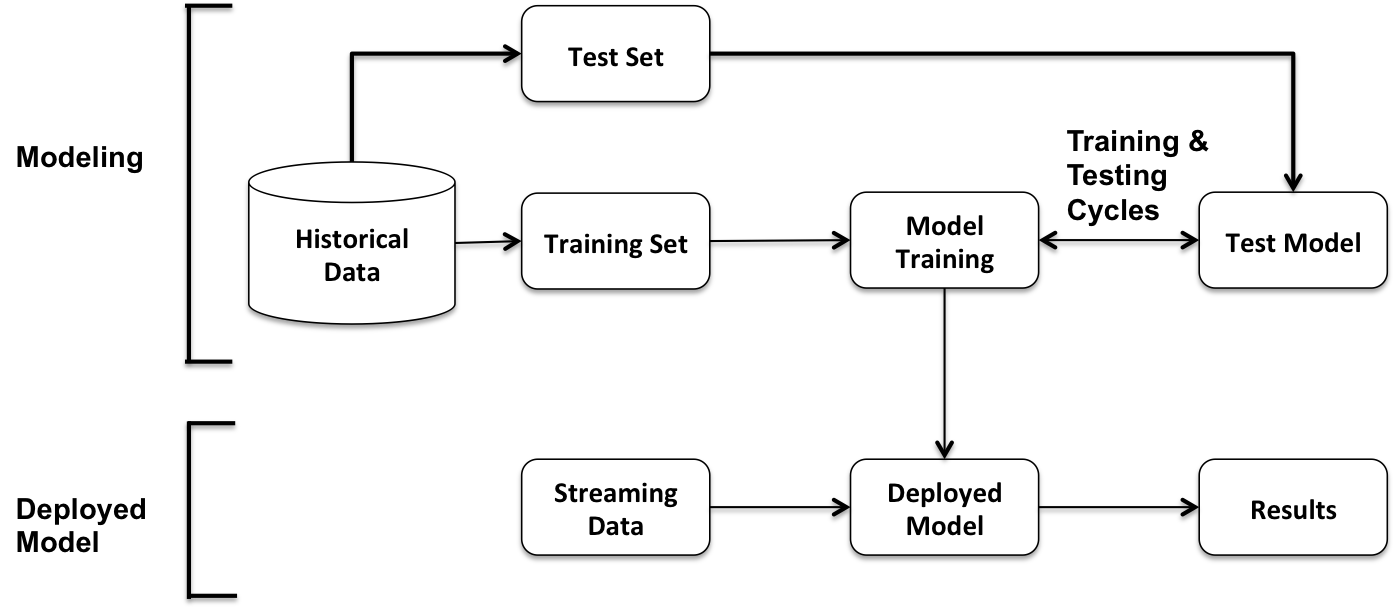
In this book, we started with the basics of Spark SQL and its components, and its role in Spark applications. Later, we presented a series of chapters focusing on its usage in various types of applications. With DataFrame/Dataset API and the Catalyst optimizer at the heart of Spark SQL, it is no surprise that it plays a key role in all applications based on the Spark technology stack. These applications include large-scale machine learning, large-scale graphs, and deep learning applications. Additionally, we presented Spark SQL-based Structured Streaming applications that operate in complex environments as continuous applications. In this chapter, we will explore application architectures that leverage Spark modules and Spark SQL in real-world applications.
More specifically, we will cover key architectural components and patterns in large-scale applications that architects and designers will find useful as a starting point...