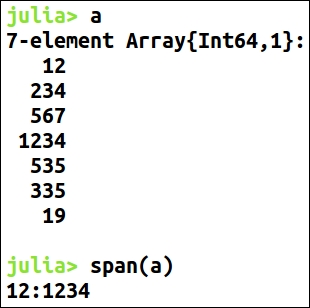
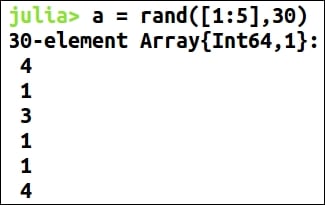
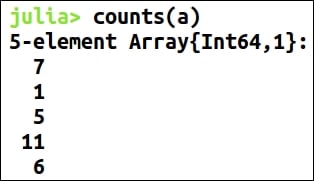
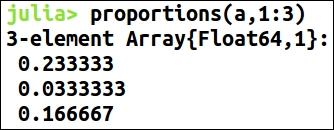
When we first receive a dataset, most of the times we only know what it is related to—an overview that is not enough to start applying algorithms or create models on it. Data exploration is of paramount importance in data science. It is the necessary process prior to creating a model because it gives a highlight of the dataset and definitely makes clear the path to achieving our objectives. Data exploration familiarizes the data scientist with the data and helps to know what general hypothesis we can infer from the dataset. So, we can say it is a process of extracting some information from the dataset, not knowing beforehand what to look for.
In this chapter, we will study:
Sampling, population, and weight vectors
Inferring column types
Summary of a dataset
Scalar statistics
Measures of variation
Data exploration using visualizations
Data exploration involves descriptive statistics. Descriptive statistics is a field of data analysis that finds out patterns by meaningfully...