





















































It is crucial to identify the right neural network type to solve a business problem efficiently. A standard neural network can be a best fit for most use cases and can produce approximate results. However, in some scenarios, the core neural network architecture needs to be changed in order to accommodate the features (input) and to produce the desired results. In the following recipe, we will walk through key steps to decide the best network architecture for a deep learning problem with the help of known use cases.
Determining the right network type to solve deep learning problems
How to do it...
- Determine the problem type.
- Determine the type of data engaged in the system.
How it works...
To solve use cases effectively, we need to use the right neural network architecture by determining the problem type. The following are globally some use cases and respective problem types to consider for step 1:
- Fraud detection problems: We want to differentiate between legitimate and suspicious transactions so as to separate unusual activities from the entire activity list. The intent is to reduce false-positive (that is, incorrectly tagging legitimate transactions as fraud) cases. Hence, this is an anomaly detection problem.
- Prediction problems: Prediction problems can be classification or regression problems. For labeled classified data, we can have discrete labels. We need to model data against those discrete labels. On the other hand, regression models don't have discrete labels.
- Recommendation problems: You would need to build a recommender system (a recommendation engine) to recommend products or content to customers. Recommendation engines can also be applied to an agent performing tasks such as gaming, autonomous driving, robotic movements, and more. Recommendation engines implement reinforcement learning and can be enhanced further by introducing deep learning into it.
We also need to know the type of data that is consumed by the neural network. Here are some use cases and respective data types for step 2:
- Fraud detection problems: Transactions usually happen over a number of time steps. So, we need to continuously collect transaction data over time. This is an example of time series data. Each time sequence represents a new transaction sequence. These time sequences can be regular or irregular. For instance, if you have credit card transaction data to analyze, then you have labeled data. You can also have unlabeled data in the case of user metadata from production logs. We can have supervised/unsupervised datasets for fraud detection analysis, for example. Take a look at the following CSV supervised dataset:
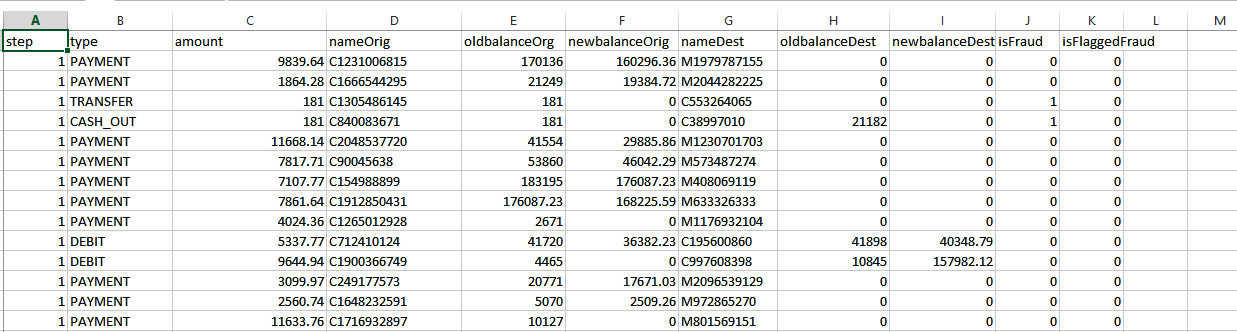
In the preceding screenshot, features such as amount, oldBalanceOrg, and so on make sense and each record has a label indicating whether the particular observation is fraudulent or not.
On the other hand, an unsupervised dataset will not give you any clue about input features. It doesn't have any labels either, as shown in the following CSV data:
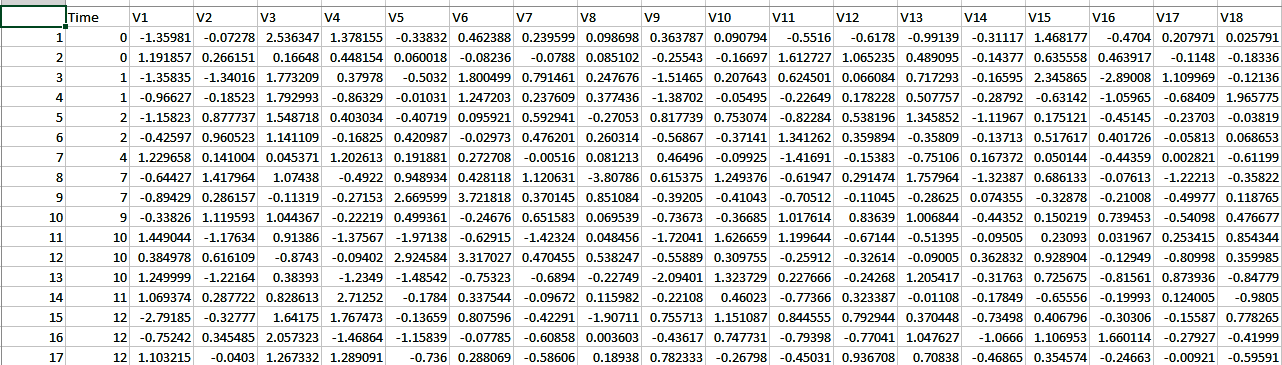
As you can see, the feature labels (top row) follow a numbered naming convention without any clue as to its significance for fraud detection outcomes. We can also have time series data where transactions are logged over a series of time steps.
- Prediction problems: Historical data collected from organizations can be used to train neural networks. These are usually simple file types such as a CSV/text files. Data can be obtained as records. For a stock market prediction problem, the data type would be a time series. A dog breed prediction problem requires feeding in dog images for network training. Stock price prediction is an example of a regression problem. Stock price datasets usually are time series data where stock prices are measured over a series as follows:
In most stock price datasets, there are multiple files. Each one of them represents a company stock market. And each file will have stock prices recorded over a series of time steps, as shown here:
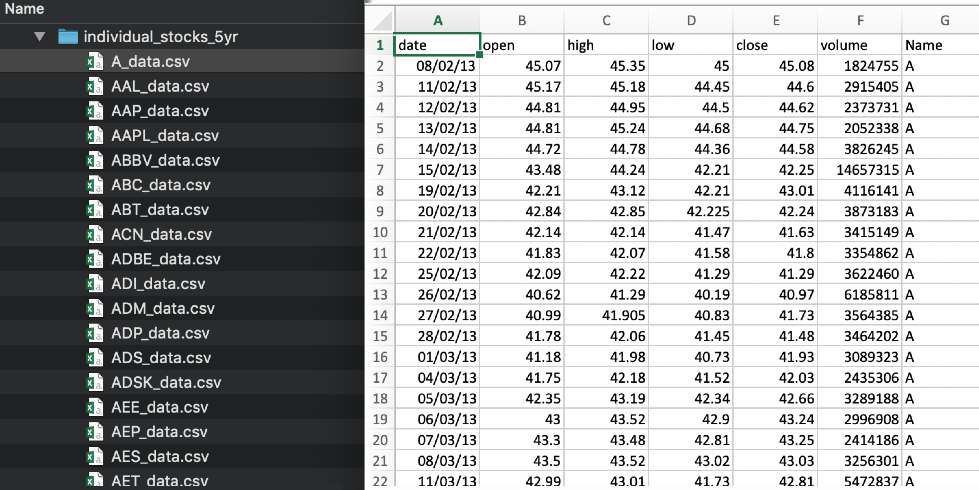
- Recommendation problems: For a product recommendation system, explicit data might be customer reviews posted on a website and implicit data might be the customer activity history, such as product search or purchase history. We will use unlabeled data to feed the neural network. Recommender systems can also solve games or learn a job that requires skills. Agents (trained to perform tasks during reinforcement learning) can take real-time data in the form of image frames or any text data (unsupervised) to learn what actions to make depending on their states.
There's more...
The following are possible deep learning solutions to the problem types previously discussed:
- Fraud detection problems: The optimal solution varies according to the data. We previously mentioned two data sources. One was credit card transactions and the other was user metadata based on their login/logoff activities. In the first case, we have labeled data and have a transaction sequence to analyze.
Recurrent networks may be best suited to sequencing data. You can add LSTM (https://deeplearning4j.org/api/latest/org/deeplearning4j/nn/layers/recurrent/LSTM.html) recurrent layers, and DL4J has an implementation for that. For the second case, we have unlabeled data and the best choice would be a variational (https://deeplearning4j.org/api/latest/org/deeplearning4j/nn/layers/variational/VariationalAutoencoder.html) autoencoder to compress unlabeled data.
- Prediction problems: For classification problems that use CSV records, a feed-forward neural network will do. For time series data, the best choice would be recurrent networks because of the nature of sequential data. For image classification problems, you would need a CNN (https://deeplearning4j.org/api/latest/org/deeplearning4j/nn/conf/layers/ConvolutionLayer.Builder.html).
- Recommendation problems: We can employ Reinforcement Learning (RL) to solve recommendation problems. RL is very often used for such use cases and might be a better option. RL4J was specifically developed for this purpose. We will introduce RL4J in Chapter 9, Using RL4J for Reinforcement Learning, as it would be an advanced topic at this point. We can also go for simpler options such as feed-forward networks RNNs) with a different approach. We can feed an unlabeled data sequence to recurrent or convolutional layers as per the data type (image/text/video). Once the recommended content/product is classified, you can apply further logic to pull random products from the list based on customer preferences.
In order to choose the right network type, you need to understand the type of data and the problem it tries to solve. The most basic neural network that you could construct is a feed-forward network or a multilayer perceptron. You can create multilayer network architectures using NeuralNetConfiguration in DL4J.
Refer to the following sample neural network configuration in DL4J:
MultiLayerConfiguration configuration = new NeuralNetConfiguration.Builder()
.weightInit(WeightInit.RELU_UNIFORM)
.updater(new Nesterovs(0.008,0.9))
.list()
.layer(new DenseLayer.Builder().nIn(layerOneInputNeurons).nOut(layerOneOutputNeurons).activation(Activation.RELU).dropOut(dropOutRatio).build())
.layer(new DenseLayer.Builder().nIn(layerTwoInputNeurons).nOut(layerTwoOutputNeurons).activation(Activation.RELU).dropOut(0.9).build())
.layer(new OutputLayer.Builder(new LossMCXENT(weightsArray))
.nIn(layerThreeInputNeurons).nOut(numberOfLabels).activation(Activation.SOFTMAX).build())
.backprop(true).pretrain(false)
.build();
We specify activation functions for every layer in a neural network, and nIn() and nOut() represent the number of connections in/out of the layer of neurons. The purpose of the dropOut() function is to deal with network performance optimization. We mentioned it in Chapter 3, Building Deep Neural Networks for Binary Classification. Essentially, we are ignoring some neurons at random to avoid blindly memorizing patterns during training. Activation functions will be discussed in the Determining the right activation function recipe in this chapter. Other attributes control how weights are distributed between neurons and how to deal with errors calculated across each epoch.
Let's focus on a specific decision-making process: choosing the right network type. Sometimes, it is better to use a custom architecture to yield better results. For example, you can perform sentence classification using word vectors combined with a CNN. DL4J offers the ComputationGraph (https://deeplearning4j.org/api/latest/org/deeplearning4j/nn/graph/ComputationGraph.html) implementation to accommodate CNN architecture.
ComputationGraph allows an arbitrary (custom) neural network architecture. Here is how it is defined in DL4J:
public ComputationGraph(ComputationGraphConfiguration configuration) {
this.configuration = configuration;
this.numInputArrays = configuration.getNetworkInputs().size();
this.numOutputArrays = configuration.getNetworkOutputs().size();
this.inputs = new INDArray[numInputArrays];
this.labels = new INDArray[numOutputArrays];
this.defaultConfiguration = configuration.getDefaultConfiguration();
//Additional source is omitted from here. Refer to https://github.com/deeplearning4j/deeplearning4j
}
Implementing a CNN is just like constructing network layers for a feed-forward network:
public class ConvolutionLayer extends FeedForwardLayer
A CNN has ConvolutionalLayer and SubsamplingLayer apart from DenseLayer and OutputLayer.













