Chapter 8. Basic Performance Tuning
In this chapter, we will cover:
Setting up Hadoop to spread disk I/O
Using a network topology script to make the Hadoop rack-aware
Mounting disks with noatime and nodiratime
Setting vm.swappiness to 0 to avoid swap
Java GC and HBase heap settings
Using compression
Managing compactions
Managing a region split
Performance is one of the most interesting characteristics of an HBase cluster's behavior. It is a challenging operation for administrators, because performance tuning requires deep understanding of not only HBase but also of Hadoop, Java Virtual Machine Garbage Collection (JVM GC), and important tuning parameters of an operating system.
The structure of a typical HBase cluster is shown in the following diagram:
There are several components in the cluster—the ZooKeeper cluster, the HBase master node, region servers, the Hadoop Distributed File System (HDFS) and the HBase client.
The ZooKeeper cluster acts as a coordination service for the entire HBase cluster, handling master selection, root region server lookup, node registration, and so on. The master node does not do heavy tasks. Its job includes region allocation and failover, log splitting, and load balancing. Region servers hold the actual regions; they handle I/O requests to the hosting regions, flush the in-memory...
Setting up Hadoop to spread disk I/O
Modern servers usually have multiple disk devices to provide large storage capacities. These disks are usually configured as RAID arrays, as their factory settings. This is good for many cases but not for Hadoop.
The Hadoop slave node stores HDFS data blocks and MapReduce temporary files on its local disks. These local disk operations benefit from using multiple independent disks to spread disk I/O.
In this recipe, we will describe how to set up Hadoop to use multiple disks to spread its disk I/O.
We assume you have multiple disks for each DataNode node. These disks are in a JBOD (Just a Bunch Of Disks) or RAID0 configuration. Assume that the disks are mounted at /mnt/d0, /mnt/d1, ..., /mnt/dn, and the user who starts HDFS has write permission on each mount point.
In order to set up Hadoop to spread disk I/O, follow these instructions:
1. On each DataNode node, create directories on each disk for HDFS to store its data blocks...
Using network topology script to make Hadoop rack-aware
Hadoop has the concept of "Rack Awareness". Administrators are able to define the rack of each DataNode in the cluster. Making Hadoop rack-aware is extremely important because:
In this recipe, we will describe how to make Hadoop rack-aware and why it is important.
You will need to know the rack to which each of your slave nodes belongs. Log in to the master node as the user who started Hadoop.
The following steps describe how to make Hadoop rack-aware:
1. Create a topology.sh script and store it under the Hadoop configuration directory. Change the path for topology.data, in line 3, to fit your environment:
Mounting disks with noatime and nodiratime
If you are mounting disks purely for Hadoop and you use ext3 or ext4, or the XFS file system, we recommend that you mount the disks with the noatime and nodiratime attributes.
If you mount the disks as noatime, the access timestamps are not updated when a file is read on the filesystem. In the case of the nodiratime attribute, mounting disks does not update the directory inode access times on the filesystem. As there is no more disk I/O for updating the access timestamps, this speeds up filesystem reads.
In this recipe, we will describe why the noatime and nodiratime options are recommended for Hadoop, and how to mount disks with noatime and nodiratime.
You will need root privileges on your slave nodes. We assume you have two disks for only Hadoop—/dev/xvdc and /dev/xvdd. The two disks are mounted at /mnt/is1 and /mnt/is2, respectively. Also, we assume you are using the ext3 filesystem.
To mount disks with noatime and...
Setting vm.swappiness to 0 to avoid swap
Linux moves the memory pages that have not been accessed for some time to the swap space, even if there is enough free memory available. This is called swap out. On the other hand, reading swapped out data from the swap space to memory is called swap in. Swapping is necessary in many situations, but as Java Virtual Machine (JVM) does not behave well under swapping, HBase may run into trouble if swapped. The ZooKeeper session expiring is a typical problem that may be introduced by a swap.
In this recipe, we will describe how to tune the Linux vm.swappiness parameter to avoid swap.
Make sure you have root privileges on your nodes in the cluster.
How to do it... To tune the Linux parameter to avoid swapping, invoke the following on each node in the cluster:
1. Execute the following command to set vm.swappiness to 0:
2. Add the...
Java GC and HBase heap settings
As HBase runs within JVM, the JVM Garbage Collection (GC) settings are very important for HBase to run smoothly, with high performance. In addition to the general guideline for configuring HBase heap settings, it's also important to have the HBase processes output their GC logs and then tune the JVM settings based on the GC logs' output.
We will describe the most important HBase JVM heap settings as well as how to enable and understand GC logging, in this recipe. We will also cover some general guidelines to tune Java GC settings for HBase.
Log in to your HBase region server.
The following are the recommended Java GC and HBase heap settings:
1. Give HBase enough heap size by editing the hbase-env.sh file. For example, the following snippet configures a 8000-MB heap size for HBase:
2. Enable GC logging by using the following command:
One of the most important features of HBase is the use of data compression. It's important because:
HBase supports the GZip and LZO codec. Our suggestion is to use the LZO compression algorithm because of its fast data decompression and low CPU usage. As a better compression ratio is preferred for the system, you should consider GZip.
Unfortunately, HBase cannot ship with LZO because of a license issue. HBase is Apache-licensed, whereas LZO is GPL-licensed. Therefore, we need to install LZO ourselves. We will use the hadoop-lzo library, which brings splittable LZO compression to Hadoop.
In this recipe, we will describe how to install LZO and how to configure HBase to use LZO compression.
Make sure Java is installed on the machine on which hadoop-lzo is to be built.
Apache Ant is required to build...
An HBase table has the following physical storage structure:
It consists of multiple regions. While a region may have several Stores, each holds a single column family. An edit first writes to the hosting region store's in-memory space, which is called MemStore. When the size of MemStore reaches a threshold, it is flushed to StoreFiles on HDFS.
As data increases, there may be many StoreFiles on HDFS, which is not good for its performance. Thus, HBase will automatically pick up a couple of the smaller StoreFiles and rewrite them into a bigger one. This process is called minor compaction. For certain situations, or when triggered by a configured interval (once a day by default), major compaction runs automatically. Major compaction will drop the deleted or expired cells and rewrite all the StoreFiles in the Store into a single StoreFile; this usually improves the performance.
However, as major compaction rewrites all of the Stores' data, lots of disk I/O and network...
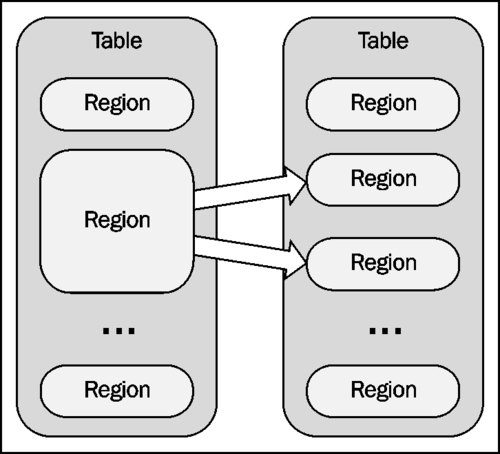
Usually an HBase table starts with a single region. However, as data keeps growing and the region reaches its configured maximum size, it is automatically split into two halves, so that they can handle more data. The following diagram shows an HBase region splitting:
This is the default behavior of HBase region splitting. This mechanism works well for many cases, however there are situations wherein it encounters problems, such as the split/compaction storms issue.
With a roughly uniform data distribution and growth, eventually all the regions in the table will need to be split at the same time. Immediately following a split, compactions will run on the daughter regions to rewrite their data into separate files. This causes a large amount of disk I/O and network traffic.
In order to avoid this situation, you can turn off automatic splitting and manually invoke it. As you can control at what time to invoke the splitting, it helps spread the I/O load. Another advantage...