





















































Reinforcement Learning
This chapter introduces reinforcement learning (RL)—the least explored and yet most promising learning paradigm. Reinforcement learning is very different from both supervised and unsupervised learning models we have done in earlier chapters. Starting from a clean slate (that is, having no prior information), the RL agent can go through multiple stages of hit and trials, and learn to achieve a goal, all the while the only input being the feedback from the environment. The latest research in RL by OpenAI seems to suggest that continuous competition can be a cause for the evolution of intelligence. Many deep learning practitioners believe that RL will play an important role in the big AI dream: Artificial General Intelligence (AGI). This chapter will delve into different RL algorithms, the following topics will be covered:
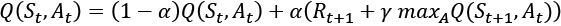
 is the learning rate, and its value lies in the range [0,1]. The first term represents the...
is the learning rate, and its value lies in the range [0,1]. The first term represents the... is approximated directly.
is approximated directly. 


















