





















































Multilayer perceptron — the first example of a network
In this chapter, we define the first example of a network with multiple linear layers. Historically, perceptron was the name given to a model having one single linear layer, and as a consequence, if it has multiple layers, you would call it multilayer perceptron (MLP). The following image represents a generic neural network with one input layer, one intermediate layer and one output layer.
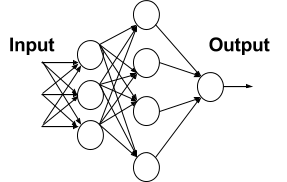
In the preceding diagram, each node in the first layer receives an input and fires according to the predefined local decision boundaries. Then the output of the first layer is passed to the second layer, the results of which are passed to the final output layer consisting of one single neuron. It is interesting to note that this layered organization vaguely resembles the patterns of human vision we discussed earlier.
Note
The net is dense, meaning that each neuron in a layer is connected to all neurons located in the previous layer and to all the neurons in the following layer.
Problems in training the perceptron and a solution
Let's consider a single neuron; what are the best choices for the weight w and the bias b? Ideally, we would like to provide a set of training examples and let the computer adjust the weight and the bias in such a way that the errors produced in the output are minimized. In order to make this a bit more concrete, let's suppose we have a set of images of cats and another separate set of images not containing cats. For the sake of simplicity, assume that each neuron looks at a single input pixel value. While the computer processes these images, we would like our neuron to adjust its weights and bias so that we have fewer and fewer images wrongly recognized as non-cats. This approach seems very intuitive, but it requires that a small change in weights (and/or bias) causes only a small change in outputs.
If we have a big output jump, we cannot progressively learn (rather than trying things in all possible directions—a process known as exhaustive search—without knowing if we are improving). After all, kids learn little by little. Unfortunately, the perceptron does not show this little-by-little behavior. A perceptron is either 0 or 1 and that is a big jump and it will not help it to learn, as shown in the following graph:
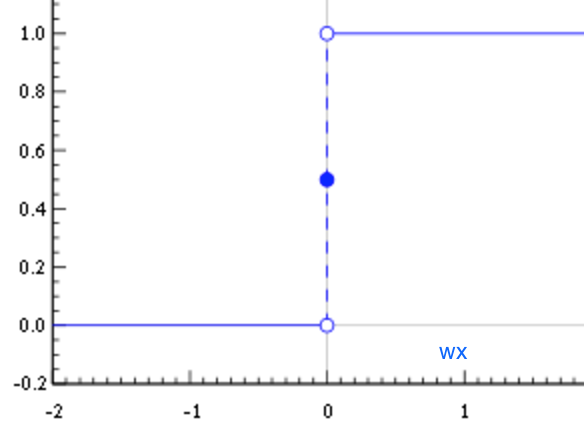
We need something different, smoother. We need a function that progressively changes from 0 to 1 with no discontinuity. Mathematically, this means that we need a continuous function that allows us to compute the derivative.
Activation function — sigmoid
The sigmoid function is defined as follows:
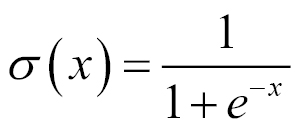
As represented in the following graph, it has small output changes in (0, 1) when the input varies in
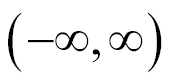
. Mathematically, the function is continuous. A typical sigmoid function is represented in the following graph:
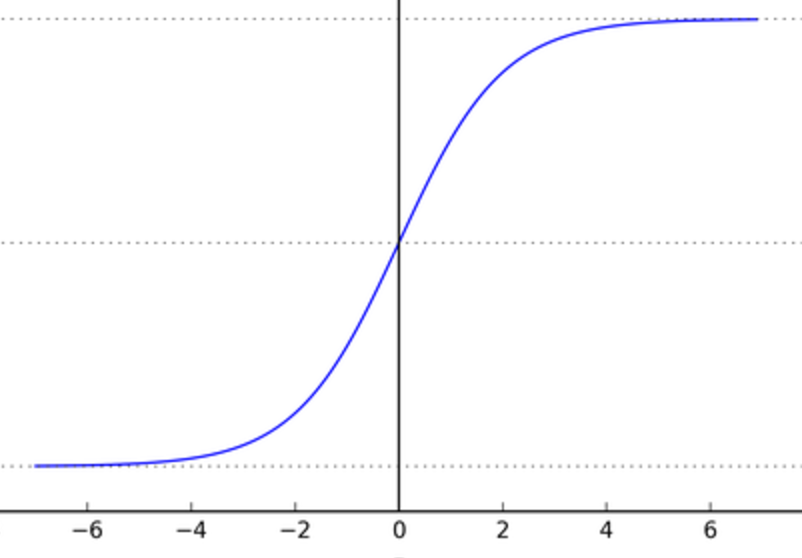
A neuron can use the sigmoid for computing the nonlinear function
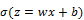
. Note that, if
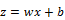
is very large and positive, then
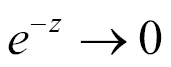
, so
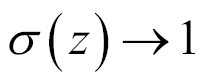
, while if
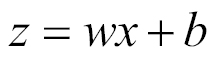
is very large and negative
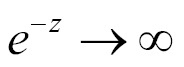
so
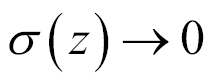
. In other words, a neuron with sigmoid activation has a behavior similar to the perceptron, but the changes are gradual and output values, such as 0.5539 or 0.123191, are perfectly legitimate. In this sense, a sigmoid neuron can answer maybe.
Activation function — ReLU
The sigmoid is not the only kind of smooth activation function used for neural networks. Recently, a very simple function called rectified linear unit (ReLU) became very popular because it generates very good experimental results. A ReLU is simply defined as
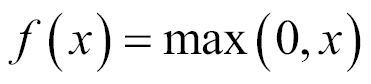
, and the nonlinear function is represented in the following graph. As you can see in the following graph, the function is zero for negative values, and it grows linearly for positive values:
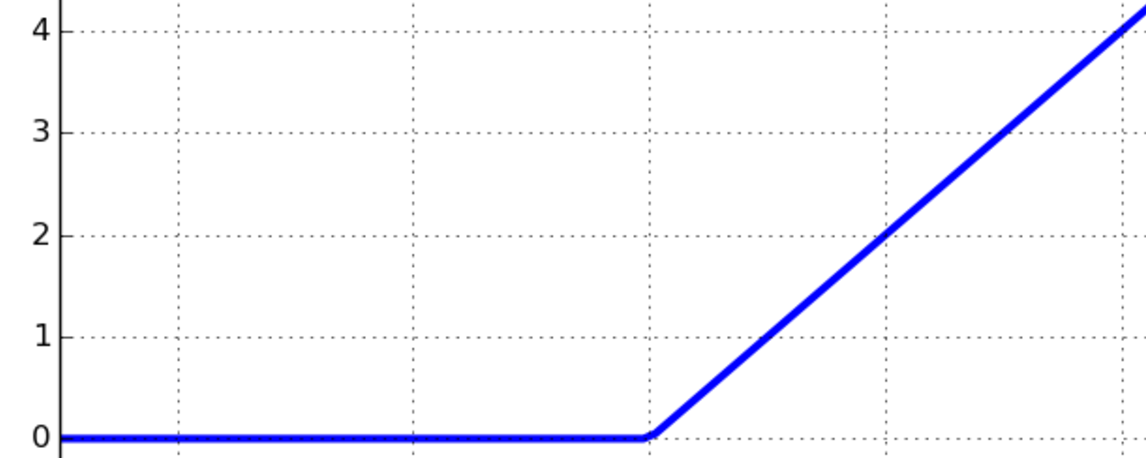
Activation functions
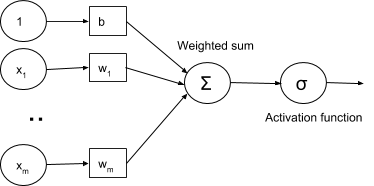
Sigmoid and ReLU are generally called activation functions in neural network jargon. In the Testing different optimizers in Keras section, we will see that those gradual changes, typical of sigmoid and ReLU functions, are the basic building blocks to developing a learning algorithm which adapts little by little, by progressively reducing the mistakes made by our nets. An example of using the activation function σ with the (x1, x2, ..., xm) input vector, (w1, w2, ..., wm) weight vector, b bias, and Σ summation is given in the following diagram:
Keras supports a number of activation functions, and a full list is available at https://keras.io/activations/.



















