"What I cannot create, I do not understand." | ||
| --Richard Feynman | ||
So far in this book, we have only discussed the discriminative models. The use of these in deep learning is to model the dependencies of an unobserved variable y on an observed variable x. Mathematically, it is formulated as P(y|x). In this chapter, we will discuss deep generative models to be used in deep learning.
Generative models are models, which when given some hidden parameters, can randomly generate some observable data values out of them. The model works on a joint probability distribution over label sequences and observation.
The generative models are used in machine and deep learning either as an intermediate step to generate a conditional probability density function or modeling observations directly from a probability density function.
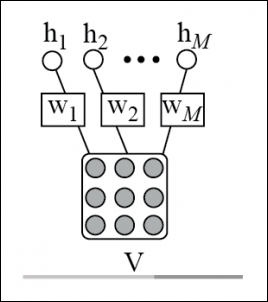
Restricted Boltzmann machines (RBMs) are a popular generative model that will be discussed in this chapter. RBMs are basically probabilistic...