Chapter 3. Data Integration, Quality, and Enrichment
In the preceding chapter, we understood the details of obtaining huge volumes of data into the Data Lake's Intake Tier from various External Data Sources. We learned various Hadoop-oriented data transfer mechanisms to either; pull the data from sources or push the data in near real-time, and to perform historical or incremental loads. We also saw the key functionalities that are implemented as part of the Data Intake Tier and got architectural guidance on the Big Data tools and technologies.
Now that the data has been acquired into the Data Lake, we will explore the next logical steps that are performed on the data in this chapter. In a nutshell, we will take a closer look at the Management Tier and understand how to efficiently manage the vast amounts of data and deliver it to multiple applications and systems with a high degree of performance and scalability.
In this chapter, we will gain a deeper understanding of the following topics...
Introduction to the Data Management Tier
The key purpose of the Management Tier is to acquire data from the Raw Zone of the Intake Tier and package it so that the data is ready for exploration, discovery, provisioning, and consumption by the end users or applications. The Management tier is a logical intermediary that bridges the gap between the raw data available in the Intake Tier and the discovery efforts performed in the Consumption Tier.
Tip
It is important to recollect that most of the steps in the Management Tier are potentially optional. In many practical implementations of the Data Lake, it is evidenced that the data is directly consumed from the Raw Zone of the Intake Tier. This is true in cases where the raw data is needed for data exploration and building analytical models. Hence, in such cases, all the steps that are part of the Management Tier are deemed optional.
The following figure represents the end-state architecture of the Data Lake as discussed in Chapter 1, The Need for...
Understanding Data Integration
In this section, let us dive deeper into and understand the underlying concepts of Data Integration.
Introduction to Data Integration
In the previous chapter, we saw that the data in the Intake Tier is in its native format with no operations performed on the data to check for its validity.
To make real use of this newly acquired data in its native format, it has to be combined or integrated with the historical data assets residing within the Enterprise Data Centre to improve the success of gathering analytical insights.
The practical goal of Data Integration is to provide a unified view through a single access point to all the data that is residing or that can be accessed by the Data Lake. Without this capability, there would be chaos, due to the multiple access points of the data; without this capability, organizations cannot integrate multiple sources, enrich it, and deliver it to data consumers rapidly to maximize its competitive advantage.
Data Lake's Integration...
Big Data tools and technologies
Data Integration involves a number of sub processes that range from acquiring raw data to enriching the data before the data is used for consumption. There are many tools and technologies available that can sometimes be used independently or together to suit the specific business needs. These range from the packaged tools that natively operate on Big Data, to enabled technologies that let us develop tools that can work on our specific use case.
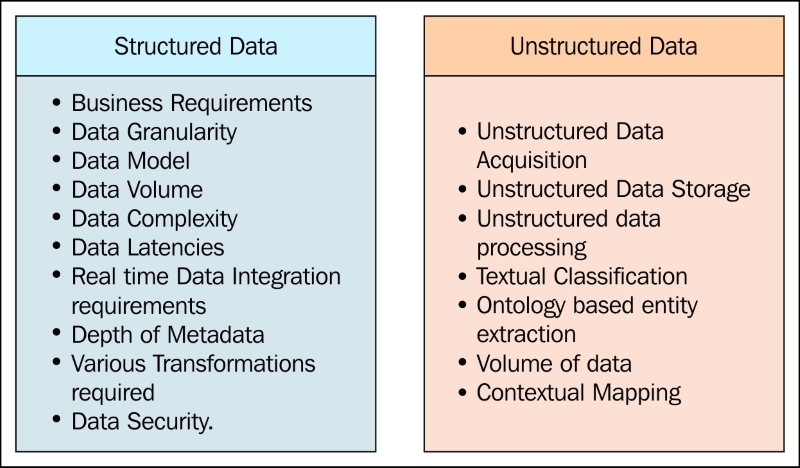
The following figure depicts the key aspects that are to be considered while choosing the right tools and technologies for Data Integration of structured data and unstructured data:
Based on the preceding considerations and the associated trade-offs, you can choose a cloud-based Data Integration tool or an on-premise data Integration tool. The primary driver for making this choice is the cost associated for in-house deployment vs. pay-as-you-go benefits of SaaS models...
This chapter explained the Data Management Tier in detail; we started with understanding Data Integration and its prominent features. Practical Data Integration scenarios were explained to help you comprehend what Data Integration does in real-life scenarios.
The various steps involved in the Data Integration process were explained in detail; we then took a deep dive into how Data Lake excels in performing Data Integration when compared to its traditional counterparts. In the subsequent sections, we took a look at the various Big Data tools and technologies that can be used for performing Data Integration in order to help you in decision making and arrive at the set of technologies that can be used for specific use cases, by giving an overview of where these tools can be used.
In the next chapter, you will understand the Data Discovery and Provisioning Zones of the Data Consumption Tier; it will take you through the key functionalities of this zone and provide architectural guidance...