





















































Measuring event time progress inside data streams
As we have shown, data streams are naturally unordered in terms of event time. Nevertheless, we need a way of measuring the completeness of our computation. Here is where another essential principle appears – watermarks.
A watermark is a (heuristic) algorithm that gives us an estimation of how far we have got in the event time domain. A perfect watermark gives the highest possible time (T) that guarantees no further data arrives with an event time < T. Let's demonstrate this with the following diagram:
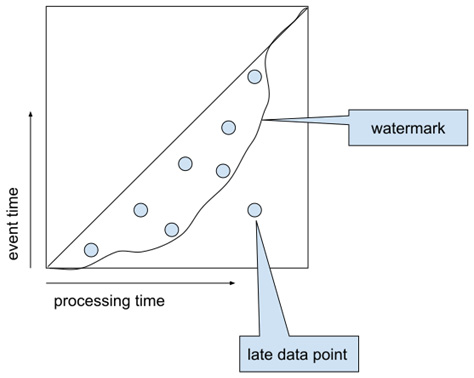
Figure 1.7 – Watermark and late data
We can see from Figure 1.7 that the watermark is a boundary that moves along with the data points, ideally leaving all of the data on its left side. All data points lying on the right side (with a processing time on the x-axis) are called late data. Such data typically requires special handling that will be described in Chapter 2, Implementing, Testing, and Deploying Basic Pipelines.
There are many ways to implement watermarks. They are typically generated at the source and propagated through the pipeline. We will discuss the details of the implementation of some watermarks in later chapters dedicated to I/O connectors. Typically, users do not have to generate watermarks themselves, although it is very useful to have a very good understanding of the concept.
States and triggers
Each computation on a data stream that takes into account more than a single isolated event needs a state. The state holds (accumulates) values derived from the so-far processed stream elements. Let's imagine we want to calculate the current number of elements in a stream. We would do that as follows:
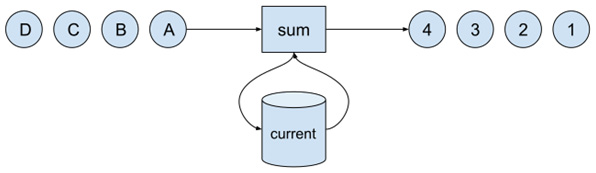
Figure 1.8 – Counting elements in a stream
The computational logic is straightforward – take the incoming element, read the current number of elements from the state, increment that number by one, store the new count into the state, and emit the current value to the output stream.
As simple as this sounds, the overall picture becomes quite complex when we consider that what we are building is an application that is supposed to run for a very long time (theoretically, forever). Such a long-running application will necessarily face disruptions caused by failing hardware, software, or necessary upgrades of the application itself. Therefore, each (sane) stream processing application has to be fault-tolerant by design.
Ensuring fault-tolerance puts specific requirements on the state and on the stream itself. Specifically, we must ensure the following:
- We must keep the state in secure, fault-tolerant storage.
- We must retain the ability to restore both the state and the stream to a defined position.
Both of these requirements dictate that every fault-tolerant stream processing engine must provide state management and state access APIs, and it must incorporate the state into its core concepts. The same holds true for Beam, and we'll dive deeper into the state concept in the following chapters.
Our element-count example raises another question: when should we output the resulting count? In the preceding example, we output the current count for each input element. This might not be adequate for every application. Other options would be to output the current value in the following ways:
- In fixed periods of processing time (for instance, every 5 seconds)
- When the watermark reaches a certain time (for instance, the output count when our watermark signals that we have processed all data up to 5 P.M.)
- When a specific condition is met in the data
Such emitting conditions are called triggers. Each of these possibilities represents one option: a processing time trigger, an event time trigger, and a data-driven trigger. Beam provides full support for processing and event time triggers and supports one data-driven trigger, which is a trigger that outputs after a specific number of elements (for example, after every 10 elements).
If you remember, we have already seen a declaration of a trigger:
PCollection<String> windowed = words.apply( Window.<String>into(new GlobalWindows()) .discardingFiredPanes() .triggering( AfterWatermark.pastEndOfWindow()));
This is one of many event time triggers, which specifies that we want to output a result when our watermark reaches a time, and it is defined as an end-of-window. We'll dive deeper into this in later chapters when we discuss the concept of windows.
Timers
Both event time and processing time triggers require an additional stream processing concept. This concept is a timer. A timer is a tool that lets an application specify a moment in either the processing time or event time domain, and when that moment is reached, an application-defined callback hook is called. For the same reason as with states, timers also need to be fault-tolerant (that is, they have to be kept in fault-tolerant storage). Beam is purposely designed so that there is actually no way to access a watermark directly, and the only way of observing a watermark is by using event time timers. We will investigate timers in more detail in Chapter 3, Implementing Pipelines Using Stateful Processing.
We now know that a streaming data processing engine needs to manage the application's state for us, but what is the life cycle of such a state? Let's find out!







