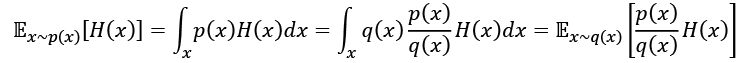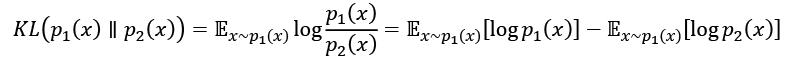The Cross-Entropy Method
In the last chapter, you got to know PyTorch. In this chapter, we will wrap up part one of this book and you will become familiar with one of the reinforcement learning (RL) methods: cross-entropy.
Despite the fact that it is much less famous than other tools in the RL practitioner's toolbox, such as deep Q-network (DQN) or advantage actor-critic, the cross-entropy method has its own strengths. Firstly, the cross-entropy method is really simple, which makes it an easy method to follow. For example, its implementation on PyTorch is less than 100 lines of code.
Secondly, the method has good convergence. In simple environments that don't require complex, multistep policies to be learned and discovered, and that have short episodes with frequent rewards, the cross-entropy method usually works very well. Of course, lots of practical problems don't fall into this category, but sometimes they do. In such cases, the cross-entropy method (on its...