Text Classification Reimagined: Delving Deep into Deep Learning Language Models
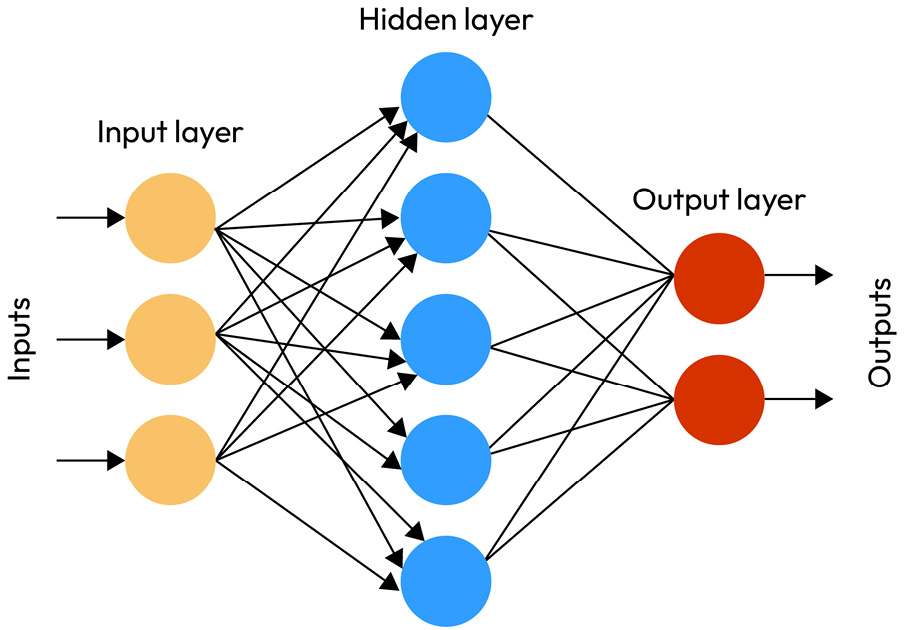
In this chapter, we delve into the realm of deep learning (DL) and its application in natural language processing (NLP), specifically focusing on the groundbreaking transformer-based models such as Bidirectional Encoder Representations from Transformers (BERT) and generative pretrained transformer (GPT). We begin by introducing the fundamentals of DL, elucidating its powerful capability to learn intricate patterns from large amounts of data, making it the cornerstone of state-of-the-art NLP systems.
Following this, we delve into transformers, a novel architecture that has revolutionized NLP by offering a more effective method of handling sequence data compared to traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs). We unpack the transformer’s unique characteristics, including its attention mechanisms, which allow it to focus on different parts of the input sequence...