





















































This recipe guides you through exporting the structure and content of your PDI repository using the PDI command-line tools. The first trivial use of this option is for something such as the backup of our job. The job and all of its dependencies will be exported to a ZIP file that we can, for example, move to another location for archiving. But at the end, what's the funny part of all of this? The job that you exported in your .zip archive starts directly from the exported archive file. For details about how to start a job from an archive file, follow what we explained in the recipe Executing PDI jobs packaged in archive files (Intermediate). This recipe will work the same for both Kitchen and Pan.
To get ready for this recipe, you need to check that the JAVA_HOME environment variable is set properly and then configure your environment variables so that the Kitchen script can start from anywhere without specifying the complete path to your PDI home directory. For details about these checks, refer to the recipe Executing PDI jobs from a filesystem (Simple).
To dump the jobs stored in a PDI repository to an archive file, use the following steps:
Dumping a job stored in a repository, either authenticated or not, is an easy thing. To try the following examples, use the filesystem repository we defined during the recipe Executing PDI jobs from the repository (Simple).
To export a job and all of its dependencies, we need to use the
exportargument followed by the base name of the.ziparchive file that we want to create. Remember that you don't need to specify any extension for the exported file because it will get attached automatically.This kind of repository is unauthenticated, but you can do exactly the same things using an authenticated repository by specifying the username and password to connect to the repository.
To export the job
export-jobfrom thesamples3repository on Linux/Mac, type the following command:$ kitchen.sh -rep:sample3 -job:export-job -export:sample-exportTo export the job
export-jobfrom thesamples3repository on Windows, type the following command:C:\temp\samples>Kitchen.bat /rep:sample3 /job:export-job /export:sample-export
To dump the jobs stored in the filesystem to an archive file, use the following steps:
You can do the same things to export jobs stored in the plain filesystem; in this case, the job must specify the files related to the job that is to be exported:
Using the
fileargument and giving the complete path to the job file in the filesystemUsing the
fileanddirarguments together
For details about the usage of these arguments, see the recipe Executing PDI jobs from a filesystem (Simple). Let's go to the directory
<books_samples>/sample1.To try to export all of the files related to the
export-job.kjbjob in Windows, type the following command:kitchen.sh -file:./export-job.kjb -export:sample-exportTo try to export all of the files related to the
export-job.kjbjob in Linux/Mac, type the following command:C:\temp\samples>Kitchen.bat /file:./export-job.kjb /export:sample-export
There is no magic behind the creation of the archive containing our job and all of its referenced files of jobs and transformations. Everything is always made using the Apache VFS library to let PDI create the exported .zip archive file very easily. You can find more details about the Apache VFS library and how it works on the Apache website at http://commons.apache.org/proper/commons-vfs.
Just a few words on some simple hints that can help you prevent unexpected behavior from the application.
Be careful when you are working with input steps that take an input as a set of files through a list. In our sample transformation, this is the case with the TextInput step. This step reads the file containing the customer dataset and sends the dataset into the transformation flow. All of these steps take as input a set of files to process. It could happen very easily that you forget an empty line at the very end of that file list as shown in the following screenshot:
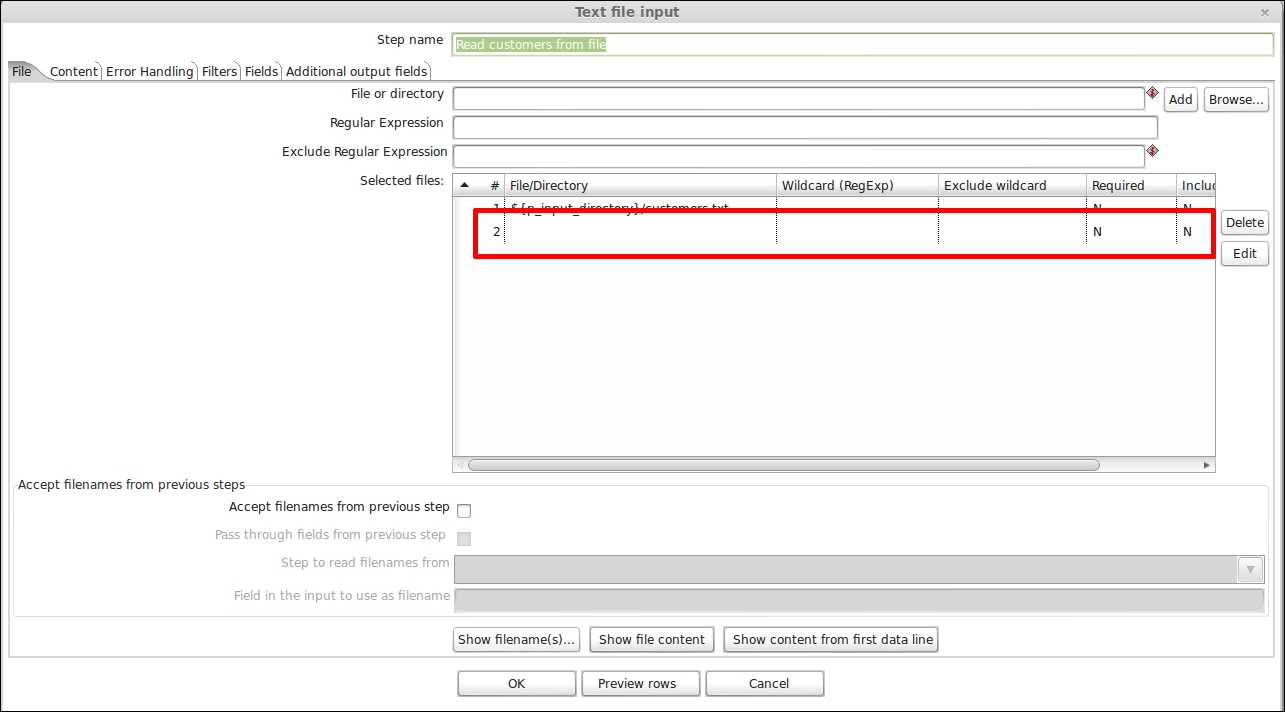
PDI does not give you an error while designing your transformation in Spoon if you leave the unused line highlighted in the preceding screenshot blank. But you could get into trouble if you try to export the job that uses that transformation by preventing the successful export of the job. So remember to check for this; and if these situations do exist, remember to clean it up.







