





















































Probabilistic latent semantic analysis
Probabilistic latent semantic analysis (pLSA) takes a statistical perspective on LSI/LSA and creates a generative model to address the lack of theoretical underpinnings of LSA (Hofmann 2001).
pLSA explicitly models the probability word w appearing in document d, as described by the DTM as a mixture of conditionally independent multinomial distributions that involve topics t.
There are both symmetric and asymmetric formulations of how word-document co-occurrences come about. The former assumes that both words and documents are generated by the latent topic class. In contrast, the asymmetric model assumes that topics are selected given the document, and words result in a second step given the topic.
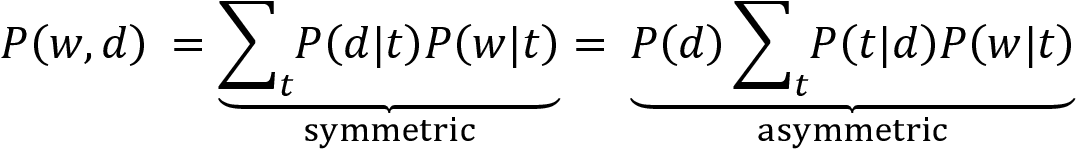
The number of topics is a hyperparameter chosen prior to training and is not learned from the data.
The plate notation in Figure 15.4 describes the statistical dependencies in a probabilistic model. More specifically,...



















