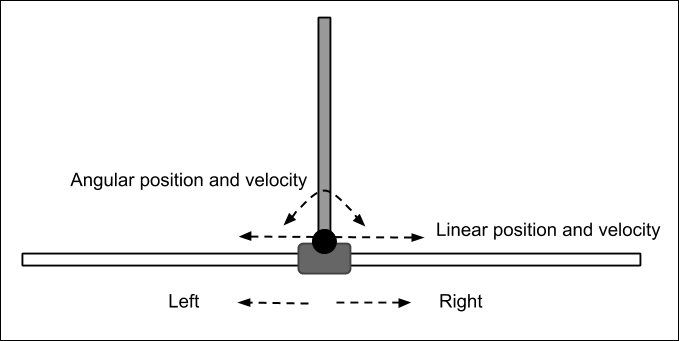
Reinforcement Learning (RL) is a framework that is used by an agent for decision-making. The agent is not necessarily a software entity such as in video games. Instead, it could be embodied in hardware such as a robot or an autonomous car. An embodied agent is probably the best way to fully appreciate and utilize reinforcement learning since a physical entity interacts with the real-world and receives responses.
The agent is situated within an environment. The environment has a state that can be partially or fully observable. The agent has a set of actions that it can use to interact with its environment. The result of an action transitions the environment to a new state. A corresponding scalar reward is received after executing an action. The goal of the agent is to maximize the accumulated future reward by learning a policy that will decide which action to take given a state.
Reinforcement learning has a strong similarity to human...