Machine learning is an interesting topic, and if you are reading this book cover to cover, you might be wondering what topic can perhaps overshadow the impressive capability in the day-to-day use machine learning. Well if you haven't heard of graphs before (not graphics!), this is the chapter where we will cover the interesting topic of graphs.
We'll look at the following major topics, such as:
- Graphs in everyday life
- What is a graph?
- Why are Graphs elegant?
- What is GraphX?
- Graph operators in Spark
- Graph algorithms in Spark
- Examples of graph algorithms
Let's get started with this interesting chapter!
You are on Facebook and being a privacy freak you lie about almost everything on your profile including your personal information, but Facebook is still able to recommend a huge number of people that you have met in daily life, and acquaintances that you might have met a decade ago. If you weren't smart enough, you would think that it is magic. If you are still wondering about this mystery (without thinking it is magic), you aren't the only one. This mystery led to a full scale investigation by the Irish Data Protection Commissioner; however, what we all believe today is that Facebook hasn't been malicious about their suggestions, but rather has used Graph algorithms to the most optimum effect. When you sign-up for Facebook, you may allow Facebook access to your contacts (desktop, e-mail, and phone numbers), and using these details Facebook would try to find other users who have similar information on their contacts and build an initial social circle of friends and...
A graph is a mathematical representation of linked data. It is a study of relationships or relationships objects, and it is formed by vertices (also known as nodes or points), which are connected by edges (also known as arcs or lines). A graph may be directed or undirected, where a directed graph implies that edges have direction associated with them, while an undirected graph implies that the edges do not have a direction associated with them.
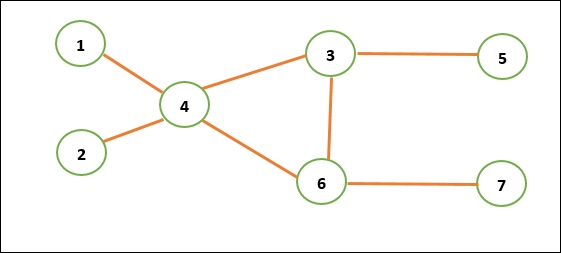
A graph is therefore represented as an ordered pair of G=(V,E) where V is a set of vertices, nodes, or points connected by E, which is a set of edges, arcs, or lines. For example, in Figure 7.1, we have a set of vertices numbered 1 to 7, and certain vertices are connected by more than one edges, for example, 4 connected to vertices 1,2,3,6 while 7 is only connected to 6.
Figure 7.1: An example of a Graph
In computer science, graphs are used to represent networks of communication such as data organization, a set of computational...
Graphs are elegant and provide a simpler way to frame complex problems within the computer sciences domain. Graph problems are typically NP-Complete and are therefore useful for study in computational complexity. Graphs are used to model different scenarios from routing algorithms to finite state machines, and if you go into a bit more detail, you will see that graph algorithms can be parallelized in a much better way.
Google realized the importance of graphs, visualized the web as a series of connected web pages via hyperlinks, and created a competitive advantage by building the fastest search engine around.
The simplicity of Graph computation can be gauged from the fact that all the algorithms operate in the same pattern, that is, access the directly connected neighbors of a particular vertex. The beauty of this approach is that you can easily parallelize this over an MPP environment.
Consider the following graph:
You can have any particular algorithm that...
Spark GraphX is not the first system to bring graph parallel computation to the mainstream, as even before this project, people used to perform graph computation on Hadoop, although they had to spend considerable time to build a graph on Hadoop. This resulted in creation of specialized systems such as Apache Giraph (an open source version of Google's Pregel), which ensured that the graph processing times come down to a fraction of what they were on Hadoop. However, graph processing is not isolated, and is very similar to MLLib where you have to spend time to load the data and pre-process it before running a machine learning pipeline. Similarly, the full data processing pipeline isn't just about running a graph algorithm, and graph creation is an important aspect of the problem, including performing post-processing, that is, what to do with the result. This was beautifully presented in a UC Berkley AmpLab talk in 2013 by Joseph Gonzalez and Reynold Xin.
The following figure...
Creating your first Graph (RDD API)
For the RDD API, the basic class in GraphX is called a Graph (org.apache.spark.graphx.Graph), which contains two types of RDDs as you might have guessed:
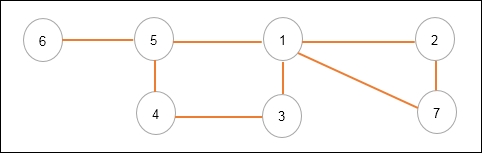
In the following graph, you can see we have a number of different vertices, namely Fawad,
Aznan, Ben, Tom, and Marathon.
Figure 7.6: Depiction of a graph
This is a labeled graph where the edges and vertices have labels associated with them.
Following the Graph, we will look at a code example, where we:
-
Create the vertices
-
Create the edges
- Instantiate a graph object
-
View the vertices configured with the graph
The following code example can be used to create a Graph similar to the one shown in the preceding figure.
Let's look at the code example:
import org.apache.spark.graphx._
val myVertices = sc.parallelize(Array(
(1L, "Fawad"),
(2L, "Aznan"),
(3L, "Ben"),
(4L, "Tom"),
(5L, "Marathon"))
)
val myEdges =...
Basic graph operators (RDD API)
We have already looked at some basic RDD operators while discussing the RDD API earlier in this book. Graphs also support basic operators to help create new graphs and manipulate them. The two major classes for graphs are:
org.apache.spark.graphx.Graph: This is an abstract class that represents a graph with arbitrary objects associated with vertices and edges. This class provides basic operations to access and manipulate the data associated with the vertices and edges, as well as the underlying structure. Like the RDD API, graph API provides a functional structure in which mutating operations would return a new Graph object.org.apache.spark.graphx.GraphOps: The GraphOps class contains additional functionality for graphs. All operations are expressed in terms of efficient GraphXAPI. This class is implicitly constructed for each graph object and can be obtained from the ops value member as follows. You do not need to explicitly get a GraphOps object as Scala...
Caching and uncaching of graphs
If you remember in the earlier chapters, we discussed the caching of RDDs, which basically referred to the fact that if you intend to use a particular RDD multiple times, you will need to cache the RDD, otherwise the Spark framework will recompute the RDD from scratch every time it is called.
Graphs (like RDDs) are not persisted in memory by default, and caching is the ideal option when using the graph multiple times. The implementation is quite similar where you simply call the cache on the Graph object:
myGraph.cache()
Uncaching unused objects from memory may improve performance. Cached RDDs and graphs remain memory resident until they are evicted due to memory pressures in an LRU order. For iterative computations, intermediate results from previous iterations will fill up the cache, resulting in slow garbage collection due to memory being filled up with unnecessary information.
Suggested approach: Uncache intermediate results as soon as possible, which might...
Graph algorithms in GraphX
GraphX supports sophisticated Graph processing and while you can build your own graph algorithms, GraphX provides a number of algorithms as a part of GraphX directly available as methods of graph or GraphOps objects. The three major components that GraphX supports include:
- PageRank
- Connected components
- Triangle counting
PageRank measure the importance of a vertex in the graph. For example, a Twitter user with lots of Twitter followers, or a LinkedIn user with lots of LinkedIn connections and followers is often considered influential and ranked highly.
GraphX supports both static and dynamic versions of PageRank, where static PageRank runs for a fixed number of iterations, while a dynamic PageRank runs until convergence (changes less than the tolerance level after each iteration).
Let's look at a very simple example. We have a set of call detail records (dummy data), and we are trying to identify the most important person in the community. There are other metrics...
Having seen GraphX over the course of this chapter, have you not wondered what happened to DataFrame? If you are reading/following this book cover to cover, you might be asking yourself why is there a switch between RDD and the DataFrame API? We saw that DataFrame has become the primary API for Spark, and all new optimizations can only be benefitted from if you are using a DataFrame API, so why is there no DataFrame API for GraphX?
Well the reality is that there is a lot of focus on GraphFrames, which is the DataFrame based API for graphs in Spark. There are certain motivations to have a DataFrame based API for Spark and some of these stem from some shortcomings of GraphX.
GraphX poses certain challenges, for example:
- Supports Scala only: The promise of Spark lies in the fact that you can have the same set of algorithms available to a wide variety of users, who can program in Java, Scala, Python, or R. GraphX only supports Scala API. This is a serious limitation...
Comparison between GraphFrames and GraphX
It is important to look at a quick comparison between GraphX and GraphFrames as it gives you an idea as to where GraphFrames are going. Joseph Bradley, who is a software Engineer at Databricks, gave a brilliant talk on GraphFrames and the difference between the two APIs. The talk is available at http://bit.ly/2hBrDwH. Here is a summary of the comparison:
If you have invested heavily into GraphX already and are wondering how you will migrate your existing code to GraphFrames, you are about to receive some good news. Apache Spark provides seamless conversions...
The following books, articles, blog, posts and videos have been referred to when writing this book to and can aid as additional reference for the reader.
In this chapter, we have covered details around GraphX, looked at various operations and algorithms of GraphX, before moving on to GraphFrames, which is a very similar programming API to what we had recently worked with in recent chapters. I hope that this chapter has given you a starting point and helped you understand the importance of graph analytics in addition to working with practical examples of GraphX and GraphFrames. If you would like to learn more, I would recommend looking at the Apache Spark Graph Processing by Rindra Ramamonjison, Packt Publishing.
The next chapter is focussed around setting up Spark in a clustered environment including Standalone scheduler, YARN, and Mesos. We will then cover two case studies before wrapping up with an Appendix, There's More with Spark of helpful topics.