Supervised machine learning algorithms are mostly broadly classified into two major categories: classification and regression.
I found the following analogy to geometry very useful when thinking about these algorithms.
Let's say you have two points in 2D. You can calculate the Euclidean distance between those two and if that distance is small, you can conclude that those points are close to each other. In other words, if those two points represent two cities in a country, you might conclude that they are in the same district.
Now if you extrapolate this theory to the N dimension, you can immediately see that any measurement can be represented as a point with the N dimension or as a vector of size N and a label can be associated with it. Then an algorithm can be deployed to learn the associativity or the pattern, and thus it learns to predict the label for an unseen/unknown/new instance represented in the similar format.
The distance metric used is generally Euclidean, that you learnt in high school. For example, given two points in 3D.
In this preceding example, 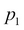 and
and 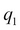 denote their values in the X axis,
denote their values in the X axis, 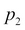 and
and 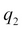 denote their values in the Y axis, and
denote their values in the Y axis, and 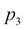 and
and 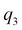 denote their values in the
denote their values in the 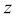 axis.
axis.
Extrapolating this, we get the following formula for calculating the distance in N dimension:
Thus, after calculating the distance from all the training set data, we can create a list of tuples with the distance and the class, as follows. This list is made for the sake of demonstration. This is not calculated from the actual data.
Let's assume that k is set to be 4. Now for each k, we take into consideration the class. So for the first three entries, we found that the class is B and for the last one, it is M. Since the number of B's is more than the number of M's, k-NN will conclude that the new patient's data is of type B.
Have you ever played the game where you had to guess about a thing that your friend had been thinking about by asking questions? And you were allowed to guess only a certain number of times and had to get back to your friend with your answer about what he/she could probably be thinking about.
The strategy to guess the correct answer is to start asking questions that segregate the possible answer space as evenly as possible. For example, if your friend told you that he/she had imagined about something, then probably the first question you would like to ask him/her is that whether he/she is thinking about an animal or a thing. That would broadly classify the answer space and then later you can ask more direct/specific questions based on the answers previously provided by your friend.
Decision tree is a set of classification algorithm that uses this approach to determine the class of an unknown entry. As the name suggests, a decision tree is a tree where the nodes depict the questions asked and the edges represent the decisions (yes/no). Leaf nodes determine the final class of the unknown entry. Following is a classic textbook example of a decision tree:
The preceding figure depicts the decision whether we can play lawn tennis or not, based on several attributes such as Outlook, Humidity, and Wind. Now the question that you may have is why outlook was chosen as the root node of the tree. The reason was that by choosing outlook as the first feature/attribute to split the dataset, the outcomes were split more evenly than if the split had been done with other attributes such as "humidity" or "wind".
The process of finding the attribute that can split the dataset more evenly than others is guided by entropy. Lesser the entropy, better the parameter. Entropy is known as the measure of information gain. It is calculated by the following formula:
Here 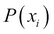 stands for the probability of
stands for the probability of 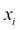 and
and 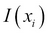 denotes the information gain.
denotes the information gain.
Let's take the example of tennis dataset from Weka. Following is the file in the CSV format:
outlook,temperature,humidity,wind,playTennis
sunny, hot, high, weak, no
sunny, hot, high, strong, no
overcast, hot, high, weak, yes
rain, mild, high, weak, yes
rain,cool, normal, weak, yes
rain, cool, normal, strong, no
overcast, cool, normal, strong, yes
sunny, mild, high, weak, no
sunny, cool, normal, weak, yes
rain, mild, normal, weak, yes
sunny, mild, normal, strong, yes
overcast, mild, high, strong, yes
overcast, hot, normal, weak, yes
rain, mild, high, strong, no
You can see from the dataset that out of 14 instances (there are 14 rows in the file), 5 instances had the value no for playTennis and 9 instances had the value yes. Thus, the overall information is given by the following formula:
This roughly evaluates to 0.94. Now from the next steps, we must pick the attribute that maximizes the information gain. Information gain is denoted as the difference between the total entropy and the entropy calculated for each possible split.
Let's go with one example. For the outlook attribute, there are three possible values: rain, sunny, and overcast, and for each of these values, the value of the attribute playTennis is either no or yes.
For rain, out of 5 instances, 3 instances have the value yes for the attribute playTennis; thus, the entropy is as follows:
This is equal to 0.97.
For overcast, every instance has the value yes:
This is equal to 0.0.
For sunny, out of 5 instances, only 2 have the value yes:
So the expected new entropy is given by the following formula:
This is roughly equal to 0.69. If you follow these steps for the other attributes, you will find that the new entropies are like as follows:
So the highest information gain is attained if we split the dataset based on the outlook attribute.
Sometimes multiple trees are constructed by generating a random subset of all the available features. This technique is known as random forest.
Regression is used to predict the target value of the real valued variable. For example, let's say we have data about the number of bedrooms and the total area of many houses in a locality. We also have their prices listed as follows:
Now let's say we have this data in a real estate site's database and we want to create a feature to predict the price of a new house with three bedrooms and total area of 1650 square feet.
Linear regression is used to solve these types of problems. As you can see, these types of problems are pretty common.
In linear regression, you start with a model where you represent the target variable—the variable for which you want to predict the value. A polynomial model is selected that minimizes the least square error (this will be explained later in the chapter). Let me walk you through this example.
Each row of the available data can be represented as a tuple where the first few elements represent the value of the known/input parameters and the last parameter shows the value of the price (the target variable). So taking inspiration from mathematics, we can represent the unknown with 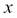 and known as
and known as 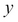 . Thus, each row can be represented as
. Thus, each row can be represented as 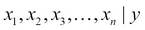 where
where 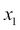 to
to 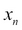 represent the parameters (the total area and the number of bedrooms) and
represent the parameters (the total area and the number of bedrooms) and 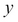 represents the target value (the price of the house). Linear regression works on a model where y is represented with the x values.
represents the target value (the price of the house). Linear regression works on a model where y is represented with the x values.
The hypothesis is represented by an equation as the following. Here 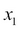 and theta denotes the input parameters (the number of bedrooms and the total area in square feet) and
and theta denotes the input parameters (the number of bedrooms and the total area in square feet) and 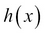 represents the predicted value of the new house.
represents the predicted value of the new house.
Note that this hypothesis is still a polynomial model and we are just using two features: the number of bedrooms and the total area represented by 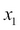 and
and 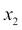 .
.
So the square error is calculated by the following formula:
The task of linear regression is to choose a set of values for the coefficients 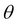 which minimizes this error. The algorithm that minimizes this error is called gradient descent or batch gradient descent. You will learn more about it in Chapter 2, Linear Regression.
which minimizes this error. The algorithm that minimizes this error is called gradient descent or batch gradient descent. You will learn more about it in Chapter 2, Linear Regression.
Unlike linear regression, logistic regression predicts a Boolean value indicating the class/tag/category of the target variable. Logistic regression is one of the most popular binary classifiers and is modelled by the equation that follows. 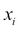 and
and 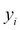 stands for the independent input variables and their classes/tags respectively. Logistic regression is discussed at length in Chapter 3, Classification Techniques.
stands for the independent input variables and their classes/tags respectively. Logistic regression is discussed at length in Chapter 3, Classification Techniques.
Whenever you buy something from the web (say Amazon), it recommends you stuff that you might find interesting and might eventually buy as well. This is the result of recommender system. Let's take the following example of a movie rating:
So in this toy example, we have 5 users and they have rated 5 movies. But not all the users have rated all the movies. For example, Jane hasn't rated "Focus" and Jacob hasn't rated "Jurassic World". The task of a recommender system is to initially guess what would be the ratings for the movies that aren't rated by the user and then recommend movies that have a guessed rating which is beyond a threshold (say 3).
There are several algorithms to solve this problem. One popular algorithm is known as collaborative filtering where the algorithm takes clues from the other user ratings. You will learn more about this in Chapter 5, Collaborative Filtering.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States















![Pentesting Web Applications: Testing real time web apps [Video]](https://content.packt.com/V07343/cover_image_large.png)