





















































We touched upon shared variables in Chapter 2, Transformations and Actions with Spark RDDs, we did not go into more details as this is considered to be a slightly advanced topic with lots of nuances around what can and cannot be shared. To briefly recap we discussed two types of Shared Variables:
- Broadcast variables
- Accumulators
Spark is an MPP architecture where multiple nodes work in parallel to achieve operations in an optimal way. As the name indicates, you might want to achieve a state where each node has its own copy of the input/interim data set, and hence broadcast that across the cluster. From previous knowledge we know that Spark does some internal broadcasting of data while executing various actions. When you run an action on Spark, the RDD is transformed into a series of stages consisting of TaskSets, which are then executed in parallel on the executors. Data is distributed using shuffle operations and the common data needed by the tasks within each stage is broadcasted automatically. So why do you need an explicit broadcast when the needed data is already made available by Spark? We talked about serialization earlier in the Appendix, There's More with Spark, and this is a time when that knowledge will come in handy. Basically Spark will cache the serialized data, and explicitly deserializes it before running a task. This can incur some overhead, especially when the size of the data is huge. The following two key checkpoints should tell you when to use broadcast variables:
- Tasks across multiple stages need the same copy of the data.
- You will like to cache the data in a deserialized form.
So how do you Broadcast data with Spark?
Code Example: You can broadcast an array of string as follows.
val groceryList = sc.broadcast(Array("Biscuits","Milk","Eggs","Butter","Bread"))You can also access its value using the .value method:

Figure 11.15: Broadcasting an array of strings
It is important to remember that all data being broadcasted is read only and you cannot broadcast an RDD. If you try to do that Spark will complain with the message Illegal Argument passed to broadcast() method. You can however call collect() on an RDD for it to be broadcasted. This can be seen in the following screenshot:

Figure 11.16: Broadcasting an RDD
While broadcast variables are read only, Spark Accumulators can be used to implement shared variables which can be operated on (added to), from various tasks running as a part of the job. At a first glance, especially to those who haven a background in MapReduce programming, they seem to be an implementation of MapReduce style counters and can help with a number of potential use cases including for example debugging, where you might to compute the records associated to a product line, or number of check-outs or basket abandonments in a particular window, or even looking at the distribution of records across tasks.
However, unlike MapReduce they are not limited to long data types, and user can define their own data types that can be merged using custom merge implementations rather than the traditional addition on natural numbers. Some key points to remember are:
Accumulators are variables that can be added through an associate or commutative operation.
Accumulators due to the associative and commutative property can be operated in parallel.
Spark provides support for:
Datatype
Accumulator creation and registration method
doubledoubleAccumulator(name: String)longlongAccumulator(name: String)CollectionAccumulatorcollectionAccumulator[T](name: String)Spark developers can create their own types by sub classing Accumulator V2 abstract class and implementing various methods such as:
reset(): Reset the value of this accumulator to a zero value. The call to isZero()must return true.add(): Take the input and accumulate.merge(): Merge another same-type accumulator into this one and update its state. This should be a merge-in-place.
If the updates to an accumulator are performed inside a Spark action, Spark guarantees that each task's update to the accumulator will only be applied once. So if a task is restarted the task will not update the value of the accumulator.
If the updates to an accumulator are performed inside a Spark Transformation, the update may be applied more than once of the task or the job stage is reexecuted.
Tasks running on the cluster can add to the accumulator using the add method, however they cannot read its value. The values can only be read from the driver program using the value method.
Code Example - You can create an accumulator using any of the standard methods, and then manipulate it in the course of execution of your task:
//Create an Accumulator Variable
val basketDropouts = sc.longAccumulator("Basket Dropouts")
//Reset it to ZerobasketDropouts.reset
//Let us see the value of the variable.
basketDropouts.value
//Parallelize a collection and for each item, add it to the Accumulator variable
sc.parallelize(1 to 100,1).foreach(num => basketDropouts.add(num))
//Get the current value of the variable
basketDropouts.valueLet's look at the following screenshot where we see the above programming example in action:
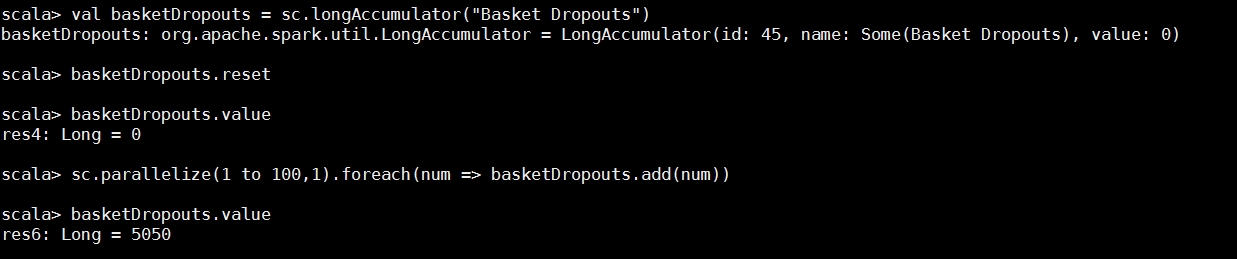
Figure 11.17: Accumulator variables
The Spark Driver UI will show the accumulators registered and their current value. As we can see on the driver UI, we have a BasketDropouts registered in the Accumulators section, and the current value is 5050. While this is a relatively simple example, in practice you can use it for a range of use cases.
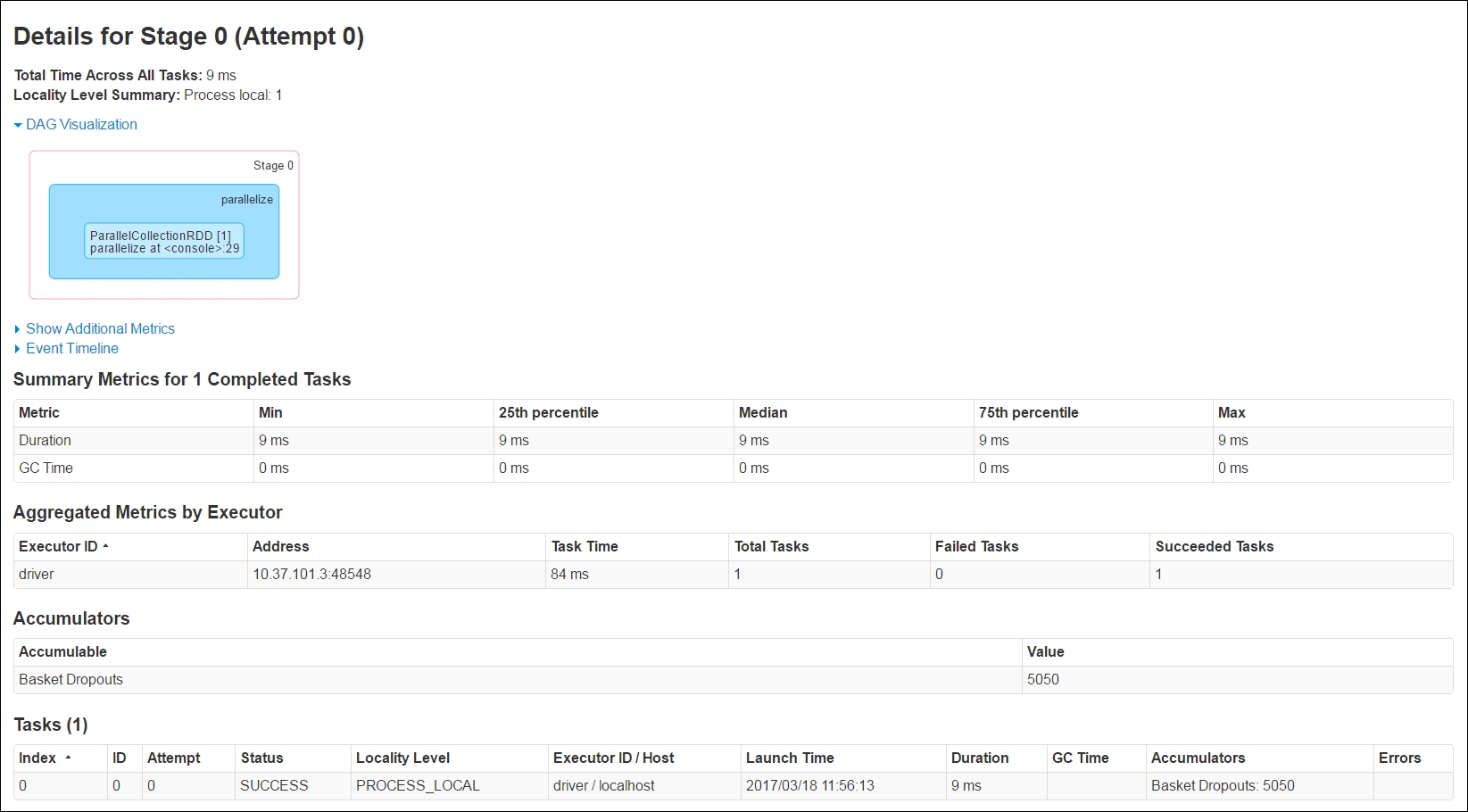
Figure 11-18: Accumulator Variables



















