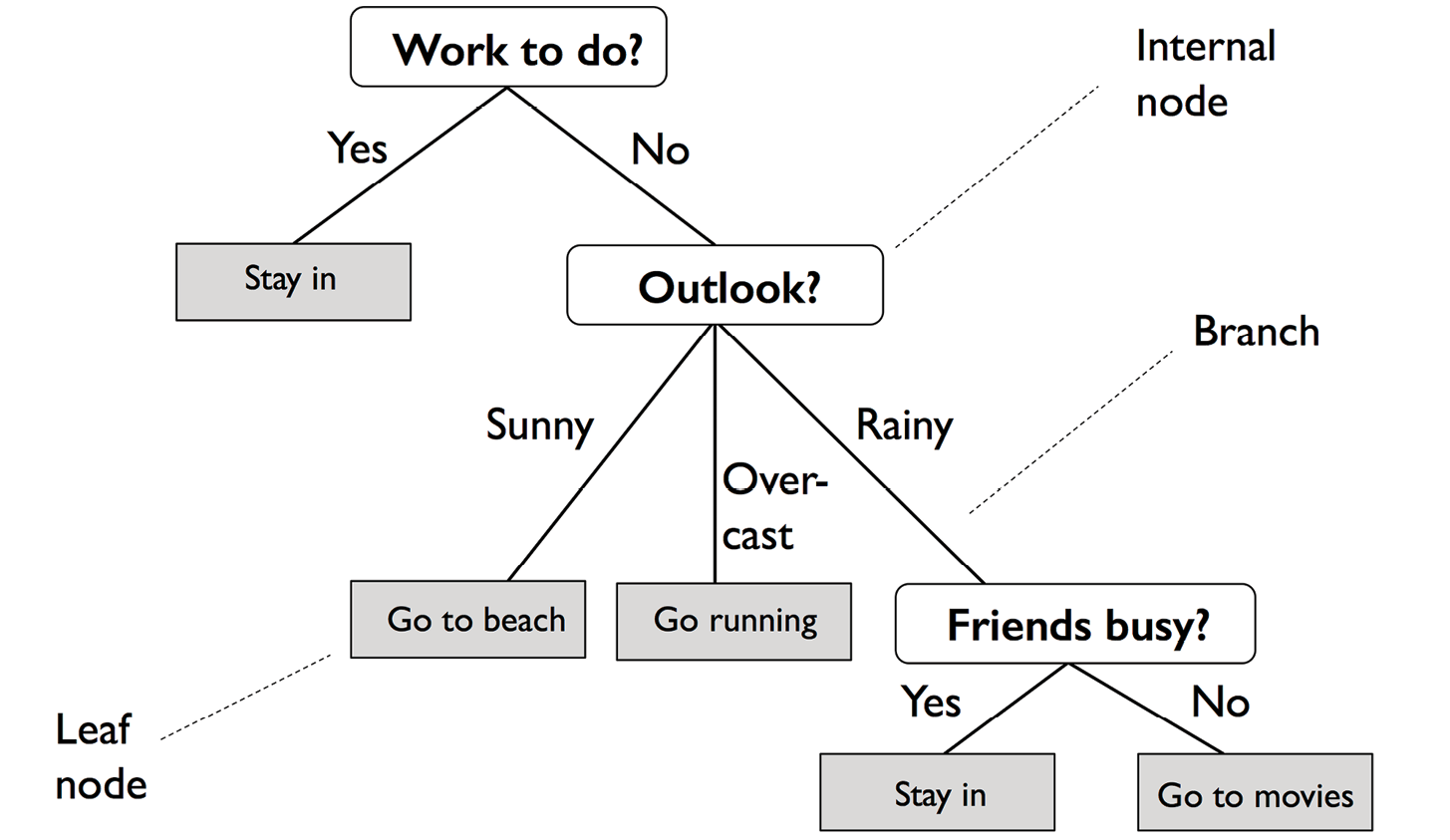
A Tour of Machine Learning Classifiers Using Scikit-Learn
In this chapter, we will take a tour of a selection of popular and powerful machine learning algorithms that are commonly used in academia as well as in industry. While learning about the differences between several supervised learning algorithms for classification, we will also develop an appreciation of their individual strengths and weaknesses. In addition, we will take our first steps with the scikit-learn library, which offers a user-friendly and consistent interface for using those algorithms efficiently and productively.
The topics that will be covered throughout this chapter are as follows:
- An introduction to robust and popular algorithms for classification, such as logistic regression, support vector machines, decision trees, and k-nearest neighbors
- Examples and explanations using the scikit-learn machine learning library, which provides a wide variety of machine learning algorithms via a user...