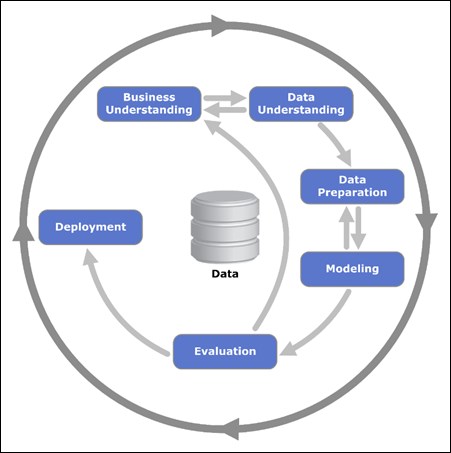
In the era of big data when lack of methodology is likely to produce random and false discoveries, a robust framework for delivery is extremely important. According to a Dataversity poll in 2015, it was found that only 17% of survey respondents said they had a well-developed Predictive or Prescriptive Analytics program in place. On the other hand, 80% of respondents said they planned on implementing such a program within five years. How can we ensure that our projects are successful?
There is an increasing amount of data in the world, and in our databases. The data deluge is not going to go away anytime soon! Businesses risk wasting the useful business value of information contained in databases, unless they are able to excise useful knowledge from the data.
There is a saying in the world of data: garbage in, garbage out. Data needs to be cleaned before it is turned into information. There is a difference between original...