























































Understanding limitations and opportunities to expand
In this chapter, we’ve implemented and used the 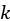 -means clustering algorithm to find regions where the data is localized. This is by no means the only algorithm for accomplishing this task. In fact, we’ve faced many challenges with this approach, most notably in finding the appropriate value of for our clustering. The binary search we use in tandem with our modified silhouette score does work (at least on our test cases) to find such a value, but it is by no means guaranteed to do so. We can afford such shortcuts here because of the nature and geometry of our data (being naturally clustered and distributed over the surface of the sphere). Our approach might not work as well, or at all, if our data were more randomly distributed and loosely clustered. Remember, this chapter is less about how to use -means as a tool for data science and more about the process of solving the problem.
-means clustering algorithm to find regions where the data is localized. This is by no means the only algorithm for accomplishing this task. In fact, we’ve faced many challenges with this approach, most notably in finding the appropriate value of for our clustering. The binary search we use in tandem with our modified silhouette score does work (at least on our test cases) to find such a value, but it is by no means guaranteed to do so. We can afford such shortcuts here because of the nature and geometry of our data (being naturally clustered and distributed over the surface of the sphere). Our approach might not work as well, or at all, if our data were more randomly distributed and loosely clustered. Remember, this chapter is less about how to use -means as a tool for data science and more about the process of solving the problem.
Ideally, data problems such as...












