


















Data Collection and Cleaning
The first step in any data analysis project is to collect and clean your data. If you're fortunate enough to have been given a perfectly clean dataset, then congratulations – you're well on your way. For the rest of us, though, there's quite a bit of grunt work to be done before you can get to the joy of analysis (yeah, I know, I really must get a life…).
In this chapter, you'll learn about what the features of a good dataset look like and how the dataset should be formatted to make it amenable to analysis by association and correlation tests.
Most importantly, you'll learn why it's not necessarily a good idea to collect sales data on ice cream and haemorrhoid cream in the same dataset.
If you're happy with your dataset and quite sure that it doesn't need cleaning, then you can safely skip this chapter. I won't take it personally – honest!
Data Collection
The first question you should be asking before starting any project is "What is my question?" If you don't know your question, then you won't know how to get an answer. In science and statistics, this is called having a hypothesis. Typical hypotheses might be:
- Is smoking related to lung cancer?
- Is there an association between sales of ice cream and haemorrhoid cream?
- Is there a correlation between coffee consumption and insomnia?
It's important to start with a question, because this will help you decide what data you should collect (and what data you shouldn't).
It's not usual that you can answer these types of question by collecting data on just those variables. It's much more likely that there will be other factors that may have an influence on the answer and all of these factors must be taken into account. If you want to answer the question is smoking related to lung cancer? then you'll typically also collect data on age, height, weight, family history, genetic factors, and environmental factors, and your dataset will start to become quite large in comparison with your hypothesis.
So, what data should you collect? Well, that depends on your hypothesis, the perceived wisdom of current thinking, and any previous research carried out, but ultimately, if you collect data sensibly, you will likely get sensible results and vice versa, so it's a good idea to take some time to think it through carefully before you start.
I'm not going to go into the finer points of data collection and cleaning here, but it's important that your dataset conforms to a few simple standards before you can start analyzing it.
By the way, if you want a copy of my book Practical Data Cleaning, you can get a free copy of it by following the instructions in the tiny little advert for it at the end of this section…
Dataset Checklist
OK, so here we go. Here are the essential features of a ready-to-go dataset for association and correlation analysis.
Your dataset is a rectangular matrix of data. If your data is spread across different spreadsheets or tables, then it's not a dataset, it's a database, and it's not ready for analysis:
- Each column of data is a single variable corresponding to a single piece of information (such as age, height, or weight, in this case).
- Column 1 is a list of unique consecutive numbers starting from one. This allows you to uniquely identify any given row and recover the original order of your dataset with a single sort command.
- Row 1 contains the names of the variables. If you use rows 2, 3, 4, and so on as the variable names, you won't be able to enter your dataset into a statistics program.
- Each row contains the details for a single sample (patient, case, test tube, and so on).
- Each cell should contain a single piece of information. If you have entered more than one piece of information in a cell (such as date of birth and their age), then you should separate the column into two or more columns (one for date of birth, another for age).
- Don't enter the number zero into a cell unless what has been measured, counted, or calculated results in the answer zero. Don't use the number zero as a code to signify "No Data". By now, you should have a well-formed dataset that is stored in a single Excel worksheet. Each column should be a single variable, with row 1 containing the names of the variables, and below this, each row should be a distinct sample or patient. It should look something like Figure 1.1.

Figure 1.1: A typical dataset used in association and correlation analysis
For the rest of this book, this is how I assume your dataset is laid out, so I might use the terms variable and column interchangeably, the same going for the terms row, sample, and patient.
Data Cleaning
Your next step is cleaning the data. You may well have made some entry errors and some of your data may not be useable. You need to find such instances and correct them. The alternative is that your data may not be fit for purpose and may mislead you in your pursuit of the answers to your questions.
Even after you've corrected the obvious entry errors, there may be other types of errors in your data that are harder to find.
Check That Your Data Is Sensible
Just because your dataset is clean, it doesn't mean that it is correct – real life follows rules, and your data must follow them, too. There are limits on the heights of participants in your study, so check that all data fits within reasonable limits. Calculate the minimum, maximum, and mean values of variables to see whether all values are sensible.
Sometimes, putting together two or more pieces of data can reveal errors that can otherwise be difficult to detect. Does the difference between date of birth and date of diagnosis give you a negative number? Is your patient over 300 years old?
Figure 1.2 gives you a list of the most useful measures that will help you discover errors in your data and find out whether real-life rules have been followed.
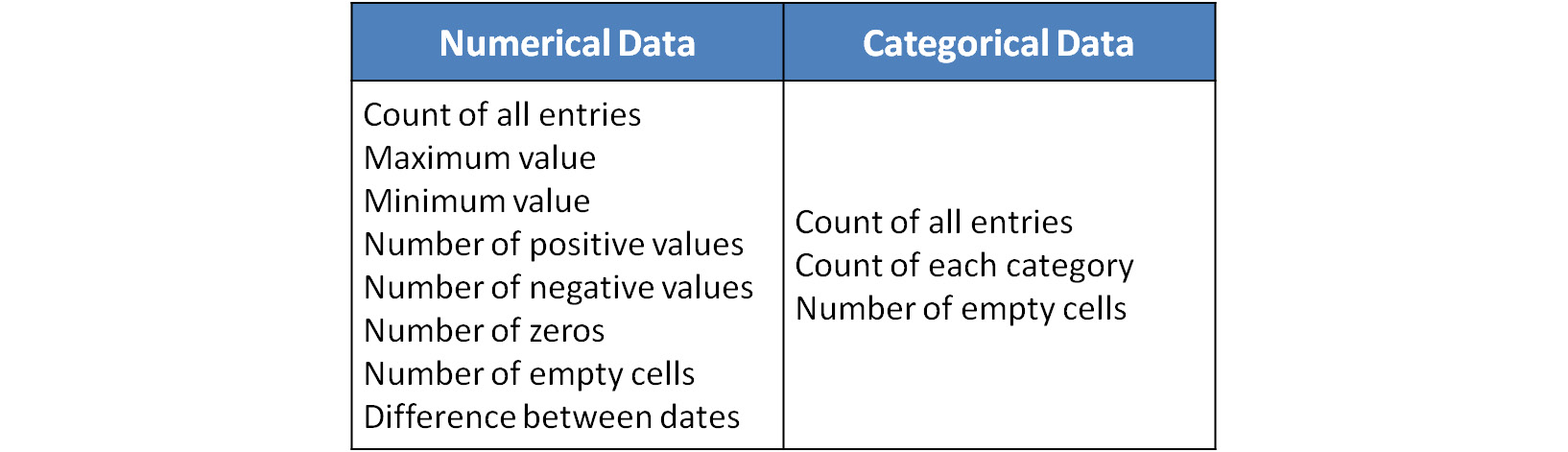
Figure 1.2: Essential descriptive statistics
Check That Your Variables Are Sensible
Once you have a perfectly clean dataset it is relatively easy to compare variables with each other to find out whether there is a relationship between them (the subject of this book). But just because you can, it doesn't mean that you should. If there is no good reason why there should be a relationship between sales of ice cream and haemorrhoid cream, then you should consider expelling one of or both of those variables from the dataset. If you've collected your own data from original sources, then you'll have considered beforehand what data is sensible to collect (you have, haven't you?), but if your dataset is a pastiche of two or more datasets, then you might find strange combinations of variables.
You should check your variables before doing any analyses and consider whether it is sensible to make these comparisons.
So, now you have collected your data, cleaned your data, and checked that your data is sensible and fit for purpose. In the next chapter, we'll go through the basics of data classification and introduce the four types of data.
Data Collection
The first question you should be asking before starting any project is "What is my question?" If you don't know your question, then you won't know how to get an answer. In science and statistics, this is called having a hypothesis. Typical hypotheses might be:
- Is smoking related to lung cancer?
- Is there an association between sales of ice cream and haemorrhoid cream?
- Is there a correlation between coffee consumption and insomnia?
It's important to start with a question, because this will help you decide what data you should collect (and what data you shouldn't).
It's not usual that you can answer these types of question by collecting data on just those variables. It's much more likely that there will be other factors that may have an influence on the answer and all of these factors must be taken into account. If you want to answer the question is smoking related to lung cancer? then you'll typically also collect data on age, height, weight, family history, genetic factors, and environmental factors, and your dataset will start to become quite large in comparison with your hypothesis.
So, what data should you collect? Well, that depends on your hypothesis, the perceived wisdom of current thinking, and any previous research carried out, but ultimately, if you collect data sensibly, you will likely get sensible results and vice versa, so it's a good idea to take some time to think it through carefully before you start.
I'm not going to go into the finer points of data collection and cleaning here, but it's important that your dataset conforms to a few simple standards before you can start analyzing it.
By the way, if you want a copy of my book Practical Data Cleaning, you can get a free copy of it by following the instructions in the tiny little advert for it at the end of this section…
Dataset Checklist
OK, so here we go. Here are the essential features of a ready-to-go dataset for association and correlation analysis.
Your dataset is a rectangular matrix of data. If your data is spread across different spreadsheets or tables, then it's not a dataset, it's a database, and it's not ready for analysis:
- Each column of data is a single variable corresponding to a single piece of information (such as age, height, or weight, in this case).
- Column 1 is a list of unique consecutive numbers starting from one. This allows you to uniquely identify any given row and recover the original order of your dataset with a single sort command.
- Row 1 contains the names of the variables. If you use rows 2, 3, 4, and so on as the variable names, you won't be able to enter your dataset into a statistics program.
- Each row contains the details for a single sample (patient, case, test tube, and so on).
- Each cell should contain a single piece of information. If you have entered more than one piece of information in a cell (such as date of birth and their age), then you should separate the column into two or more columns (one for date of birth, another for age).
- Don't enter the number zero into a cell unless what has been measured, counted, or calculated results in the answer zero. Don't use the number zero as a code to signify "No Data". By now, you should have a well-formed dataset that is stored in a single Excel worksheet. Each column should be a single variable, with row 1 containing the names of the variables, and below this, each row should be a distinct sample or patient. It should look something like Figure 1.1.
Figure 1.1: A typical dataset used in association and correlation analysis
For the rest of this book, this is how I assume your dataset is laid out, so I might use the terms variable and column interchangeably, the same going for the terms row, sample, and patient.
Data Cleaning
Your next step is cleaning the data. You may well have made some entry errors and some of your data may not be useable. You need to find such instances and correct them. The alternative is that your data may not be fit for purpose and may mislead you in your pursuit of the answers to your questions.
Even after you've corrected the obvious entry errors, there may be other types of errors in your data that are harder to find.
Check That Your Data Is Sensible
Just because your dataset is clean, it doesn't mean that it is correct – real life follows rules, and your data must follow them, too. There are limits on the heights of participants in your study, so check that all data fits within reasonable limits. Calculate the minimum, maximum, and mean values of variables to see whether all values are sensible.
Sometimes, putting together two or more pieces of data can reveal errors that can otherwise be difficult to detect. Does the difference between date of birth and date of diagnosis give you a negative number? Is your patient over 300 years old?
Figure 1.2 gives you a list of the most useful measures that will help you discover errors in your data and find out whether real-life rules have been followed.
Figure 1.2: Essential descriptive statistics
Check That Your Variables Are Sensible
Once you have a perfectly clean dataset it is relatively easy to compare variables with each other to find out whether there is a relationship between them (the subject of this book). But just because you can, it doesn't mean that you should. If there is no good reason why there should be a relationship between sales of ice cream and haemorrhoid cream, then you should consider expelling one of or both of those variables from the dataset. If you've collected your own data from original sources, then you'll have considered beforehand what data is sensible to collect (you have, haven't you?), but if your dataset is a pastiche of two or more datasets, then you might find strange combinations of variables.
You should check your variables before doing any analyses and consider whether it is sensible to make these comparisons.
So, now you have collected your data, cleaned your data, and checked that your data is sensible and fit for purpose. In the next chapter, we'll go through the basics of data classification and introduce the four types of data.
