This chapter gives you a quick overview of one of the most popular data analysis libraries in Scala, how to get them, and their most frequently used functions and data structures.
We will be focusing on Breeze in this first chapter, which is one of the most popular and powerful linear algebra libraries. Spark MLlib, which we will be seeing in the subsequent chapters, builds on top of Breeze and Spark, and provides a powerful framework for scalable machine learning.
In simple terms, Breeze (http://www.scalanlp.org) is a Scala library that extends the Scala collection library to provide support for vectors and matrices in addition to providing a whole bunch of functions that support their manipulation. We could safely compare Breeze to NumPy (http://www.numpy.org/) in Python terms. Breeze forms the foundation of MLlib—the Machine Learning library in Spark, which we will explore in later chapters.
In this first recipe, we will see how to pull the Breeze libraries into our project using Scala Build Tool (SBT). We will also see a brief history of Breeze to better appreciate why it could be considered as the "go to" linear algebra library in Scala.
Note
For all our recipes, we will be using Scala 2.10.4 along with Java 1.7. I wrote the examples using the Scala IDE, but please feel free to use your favorite IDE.
Let's add the Breeze dependencies into our build.sbt so that we can start playing with them in the subsequent recipes. The Breeze dependencies are just two—the breeze (core) and the breeze-native dependencies.
Under a brand new folder (which will be our project root), create a new file called
build.sbt.Next, add the
breezelibraries to the project dependencies:organization := "com.packt" name := "chapter1-breeze" scalaVersion := "2.10.4" libraryDependencies ++= Seq( "org.scalanlp" %% "breeze" % "0.11.2", //Optional - the 'why' is explained in the How it works section "org.scalanlp" %% "breeze-natives" % "0.11.2" )
From that folder, issue a
sbt compilecommand in order to fetch all your dependencies.Note
You could import the project into your Eclipse using
sbt eclipseafter installing thesbteclipseplugin https://github.com/typesafehub/sbteclipse/. For IntelliJ IDEA, you just need to import the project by pointing to the root folder where yourbuild.sbtfile is.
Let's look into the details of what the breeze and breeze-native library dependencies we added bring to us.
Breeze has a long history in that it isn't written from scratch in Scala. Without the native dependency, Breeze leverages the power of netlib-java that has a Java-compiled version of the FORTRAN Reference implementation of BLAS/LAPACK. The netlib-java also provides gentle wrappers over the Java compiled library. What this means is that we could still work without the native dependency but the performance won't be great considering the best performance that we could leverage out of this FORTRAN-translated library is the performance of the FORTRAN reference implementation itself. However, for serious number crunching with the best performance, we should add the breeze-natives dependency too.
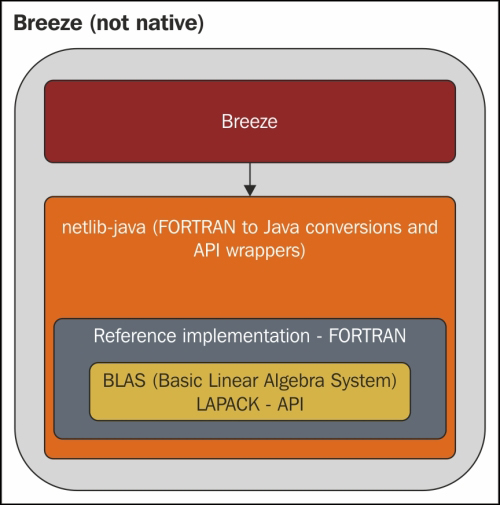
With its native additive, Breeze looks for the machine-specific implementations of the BLAS/LAPACK libraries. The good news is that there are open source and (vendor provided) commercial implementations for most popular processors and GPUs. The most popular open source implementations include ATLAS (http://math-atlas.sourceforge.net) and OpenBLAS (http://www.openblas.net/).
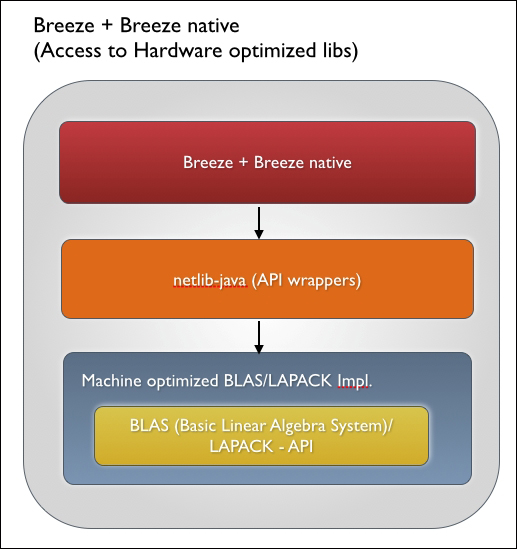
If you are running a Mac, you are in luck—Native BLAS libraries come out of the box on Macs. Installing NativeBLAS on Ubuntu / Debian involves just running the following commands:
sudo apt-get install libatlas3-base libopenblas-base sudo update-alternatives --config libblas.so.3 sudo update-alternatives --config liblapack.so.3
Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
For Windows, please refer to the installation instructions on https://github.com/xianyi/OpenBLAS/wiki/Installation-Guide.
There are subtle yet powerful differences between Breeze vectors and Scala's own scala.collection.Vector. As we'll see in this recipe, Breeze vectors have a lot of functions that are linear algebra specific, and the more important thing to note here is that Breeze's vector is a Scala wrapper over netlib-java and most calls to the vector's API delegates the call to it.
Vectors are one of the core components in Breeze. They are containers of homogenous data. In this recipe, we'll first see how to create vectors and then move on to various data manipulation functions to modify those vectors.
In this recipe, we will look at various operations on vectors. This recipe has been organized in the form of the following sub-recipes:
Creating vectors:
Creating a vector from values
Creating a zero vector
Creating a vector out of a function
Creating a vector of linearly spaced values
Creating a vector with values in a specific range
Creating an entire vector with a single value
Slicing a sub-vector from a bigger vector
Creating a Breeze vector from a Scala vector
Vector arithmetic:
Scalar operations
Calculating the dot product of a vector
Creating a new vector by adding two vectors together
Appending vectors and converting a vector of one type to another:
Concatenating two vectors
Converting a vector of int to a vector of double
Computing basic statistics:
Mean and variance
Standard deviation
Find the largest value
Finding the sum, square root and log of all the values in the vector
In order to run the code, you could either use the Scala or use the Worksheet feature available in the Eclipse Scala plugin (or Scala IDE) or in IntelliJ IDEA. The reason these options are suggested is due to their quick turnaround time.
Let's look at each of the above sub-recipes in detail. For easier reference, the output of the respective command is shown as well. All the classes that are being used in this recipe are from the breeze.linalg package. So, an "import breeze.linalg._" statement at the top of your file would be perfect.
Let's look at the various ways we could construct vectors. Most of these construction mechanisms are through the apply method of the vector. There are two different flavors of vector—breeze.linalg.DenseVector and breeze.linalg.SparseVector—the choice of the vector depends on the use case. The general rule of thumb is that if you have data that is at least 20 percent zeroes, you are better off choosing SparseVector but then the 20 percent is a variant too.
Creating a dense vector from values: Creating a
DenseVectorfrom values is just a matter of passing the values to theapplymethod:val dense=DenseVector(1,2,3,4,5) println (dense) //DenseVector(1, 2, 3, 4, 5)
Creating a sparse vector from values: Creating a
SparseVectorfrom values is also through passing the values to theapplymethod:val sparse=SparseVector(0.0, 1.0, 0.0, 2.0, 0.0) println (sparse) //SparseVector((0,0.0), (1,1.0), (2,0.0), (3,2.0), (4,0.0))
Notice how the SparseVector stores values against the index.
Obviously, there are simpler ways to create a vector instead of just throwing all the data into its apply method.
Calling the vector's zeros function would create a zero vector. While the numeric types would return a 0, the object types would return null and the Boolean types would return false:
val denseZeros=DenseVector.zeros[Double](5) //DenseVector(0.0, 0.0, 0.0, 0.0, 0.0) val sparseZeros=SparseVector.zeros[Double](5) //SparseVector()
Not surprisingly, the SparseVector does not allocate any memory for the contents of the vector. However, the creation of the SparseVector object itself is accounted for in the memory.
The tabulate function in vector is an interesting and useful function. It accepts a size argument just like the zeros function but it also accepts a function that we could use to populate the values for the vector. The function could be anything ranging from a random number generator to a naïve index based generator, which we have implemented here. Notice how the return value of the function (Int) could be converted into a vector of Double by using the type parameter:
val denseTabulate=DenseVector.tabulate[Double](5)(index=>index*index) //DenseVector(0.0, 1.0, 4.0, 9.0, 16.0)
The linspace function in breeze.linalg creates a new Vector[Double] of linearly spaced values between two arbitrary numbers. Not surprisingly, it accepts three arguments—the start, end, and the total number of values that we would like to generate. Please note that the start and the end values are inclusive while being generated:
val spaceVector=breeze.linalg.linspace(2, 10, 5) //DenseVector(2.0, 4.0, 6.0, 8.0, 10.0)
The range function in a vector has two variants. The plain vanilla function accepts a start and end value (start inclusive):
val allNosTill10=DenseVector.range(0, 10) //DenseVector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
The other variant is an overloaded function that accepts a "step" value:
val evenNosTill20=DenseVector.range(0, 20, 2) // DenseVector(0, 2, 4, 6, 8, 10, 12, 14, 16, 18)
Just like the range function, which has all the arguments as integers, there is also a rangeD function that takes the start, stop, and the step parameters as Double:
val rangeD=DenseVector.rangeD(0.5, 20, 2.5) // DenseVector(0.5, 3.0, 5.5, 8.0, 10.5, 13.0, 15.5)
Filling an entire vector with the same value is child's play. We just say HOW BIG is this vector going to be and then WHAT value. That's it.
val denseJust2s=DenseVector.fill(10, 2) // DenseVector(2, 2, 2, 2, 2, 2 , 2, 2, 2, 2)
Choosing a part of the vector from a previous vector is just a matter of calling the slice method on the bigger vector. The parameters to be passed are the start index, end index, and an optional "step" parameter. The step parameter adds the step value for every iteration until it reaches the end index. Note that the end index is excluded in the sub-vector:
val allNosTill10=DenseVector.range(0, 10) //DenseVector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) val fourThroughSevenIndexVector= allNosTill10.slice(4, 7) //DenseVector(4, 5, 6) val twoThroughNineSkip2IndexVector= allNosTill10.slice(2, 9, 2) //DenseVector(2, 4, 6)
A Breeze vector object's apply method could even accept a Scala Vector as a parameter and construct a vector out of it:
val vectFromArray=DenseVector(collection.immutable.Vector(1,2,3,4)) // DenseVector(Vector(1, 2, 3, 4))
Operations with scalars work just as we would expect, propagating the value to each element in the vector.
Adding a scalar to each element of the vector is done using the + function (surprise!):
val inPlaceValueAddition=evenNosTill20 +2 //DenseVector(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
Similarly the other basic arithmetic operations—subtraction, multiplication, and division involves calling the respective functions named after the universally accepted symbols (-, *, and /):
//Scalar subtraction val inPlaceValueSubtraction=evenNosTill20 -2 //DenseVector(-2, 0, 2, 4, 6, 8, 10, 12, 14, 16) //Scalar multiplication val inPlaceValueMultiplication=evenNosTill20 *2 //DenseVector(0, 4, 8, 12, 16, 20, 24, 28, 32, 36) //Scalar division val inPlaceValueDivision=evenNosTill20 /2 //DenseVector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
Each vector object has a function called dot, which accepts another vector of the same length as a parameter.
Let's fill in just 2s to a new vector of length 5:
val justFive2s=DenseVector.fill(5, 2) //DenseVector(2, 2, 2, 2, 2)
We'll create another vector from 0 to 5 with a step value of 1 (a fancy way of saying 0 through 4):
val zeroThrough4=DenseVector.range(0, 5, 1) //DenseVector(0, 1, 2, 3, 4)
Here's the dot function:
val dotVector=zeroThrough4.dot(justFive2s) //Int = 20
It is to be expected of the function to complain if we pass in a vector of a different length as a parameter to the dot product - Breeze throws an IllegalArgumentException if we do that. The full exception message is:
Java.lang.IllegalArgumentException: Vectors must be the same length!
The + function is overloaded to accept a vector other than the scalar we saw previously. The operation does a corresponding element-by-element addition and creates a new vector:
val evenNosTill20=DenseVector.range(0, 20, 2) //DenseVector(0, 2, 4, 6, 8, 10, 12, 14, 16, 18) val denseJust2s=DenseVector.fill(10, 2) //DenseVector(2, 2, 2, 2, 2, 2, 2, 2, 2, 2) val additionVector=evenNosTill20 + denseJust2s // DenseVector(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
There's an interesting behavior encapsulated in the addition though. Assuming you try to add two vectors of different lengths, if the first vector is smaller and the second vector larger, the resulting vector would be the size of the first vector and the rest of the elements in the second vector would be ignored!
val fiveLength=DenseVector(1,2,3,4,5) //DenseVector(1, 2, 3, 4, 5) val tenLength=DenseVector.fill(10, 20) //DenseVector(20, 20, 20, 20, 20, 20, 20, 20, 20, 20) fiveLength+tenLength //DenseVector(21, 22, 23, 24, 25)
On the other hand, if the first vector is larger and the second vector smaller, it would result in an ArrayIndexOutOfBoundsException:
tenLength+fiveLength // java.lang.ArrayIndexOutOfBoundsException: 5
There are two variants of concatenation. There is a vertcat function that just vertically concatenates an arbitrary number of vectors—the size of the vector just increases to the sum of the sizes of all the vectors combined:
val justFive2s=DenseVector.fill(5, 2) //DenseVector(2, 2, 2, 2, 2) val zeroThrough4=DenseVector.range(0, 5, 1) //DenseVector(0, 1, 2, 3, 4) val concatVector=DenseVector.vertcat(zeroThrough4, justFive2s) //DenseVector(0, 1, 2, 3, 4, 2, 2, 2, 2, 2)
No surprise here. There is also the horzcat method that places the second vector horizontally next to the first vector, thus forming a matrix.
val concatVector1=DenseVector.horzcat(zeroThrough4, justFive2s) //breeze.linalg.DenseMatrix[Int] 0 2 1 2 2 2 3 2 4 2
Note
While dealing with vectors of different length, the vertcat function happily arranges the second vector at the bottom of the first vector. Not surprisingly, the horzcat function throws an exception:
java.lang.IllegalArgumentException, meaning all vectors must be of the same size!
The conversion of one type of vector into another is not automatic in Breeze. However, there is a simple way to achieve this:
val evenNosTill20Double=breeze.linalg.convert(evenNosTill20, Double)
Other than the creation and the arithmetic operations that we saw previously, there are some interesting summary statistics operations that are available in the library. Let's look at them now:
Note
Needs import of breeze.linalg._ and breeze.numerics._. The operations in the Other operations section aim to simulate the NumPy's UFunc or universal functions.
Now, let's briefly look at how to calculate some basic summary statistics for a vector.
Calling the
stddev on a Double vector could give the standard deviation:
stddev(evenNosTill20Double) //Double = 6.0553007081949835
The max universal function inside the breeze.linalg package would help us find the maximum value in a vector:
val intMaxOfVectorVals=max (evenNosTill20) //18
The same as with
max, the sum universal function inside the breeze.linalg package calculates the sum of the vector:
val intSumOfVectorVals=sum (evenNosTill20) //90
The functions sqrt, log, and various other universal functions in the breeze.numerics package calculate the square root and log values of all the individual elements inside the vector:
val sqrtOfVectorVals= sqrt (evenNosTill20) // DenseVector(0.0, 1. 4142135623730951, 2.0, 2.449489742783178, 2.8284271247461903, 3.16227766016 83795, 3.4641016151377544, 3.7416573867739413, 4.0, 4.242640687119285)
As we discussed in the Working with vectors recipe, you could use the Eclipse or IntelliJ IDEA Scala worksheets for a faster turnaround time.
There are a variety of functions that we have in a matrix. In this recipe, we will look at some details around:
Creating matrices:
Creating a matrix from values
Creating a zero matrix
Creating a matrix out of a function
Creating an identity matrix
Creating a matrix from random numbers
Creating from a Scala collection
Matrix arithmetic:
Addition
Multiplication (also element-wise)
Appending and conversion:
Concatenating a matrix vertically
Concatenating a matrix horizontally
Converting a matrix of Int to a matrix of Double
Getting column vectors
Getting row vectors
Getting values inside the matrix
Getting the inverse and transpose of a matrix
Computing basic statistics:
Mean and variance
Standard deviation
Finding the largest value
Finding the sum, square root and log of all the values in the matrix
Calculating the eigenvectors and eigenvalues of a matrix
Let's first see how to create a matrix.
The simplest way to create a matrix is to pass in the values in a row-wise fashion into the apply function of the matrix object:
val simpleMatrix=DenseMatrix((1,2,3),(11,12,13),(21,22,23)) //Returns a DenseMatrix[Int] 1 2 3 11 12 13 21 22 23
There's also a Sparse version of the matrix too—the Compressed Sparse Column Matrix (CSCMatrix):
val sparseMatrix=CSCMatrix((1,0,0),(11,0,0),(0,0,23)) //Returns a SparseMatrix[Int] (0,0) 1 (1,0) 11 (2,2) 23
Creating a zero matrix is just a matter of calling the matrix's zeros function. The first integer parameter indicates the rows and the second parameter indicates the columns:
val denseZeros=DenseMatrix.zeros[Double](5,4) //Returns a DenseMatrix[Double] 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 val compressedSparseMatrix=CSCMatrix.zeros[Double](5,4) //Returns a CSCMatrix[Double] = 5 x 4 CSCMatrix
The tabulate function in a matrix is very similar to the vector's version. It accepts a row and column size as a tuple (in the example (5,4)). It also accepts a function that we could use to populate the values for the matrix. In our example, we generated the values of the matrix by just multiplying the row and column index:
val denseTabulate=DenseMatrix.tabulate[Double](5,4)((firstIdx,secondIdx)=>firstIdx*secondIdx) Returns a DenseMatrix[Double] = 0.0 0.0 0.0 0.0 0.0 1.0 2.0 3.0 0.0 2.0 4.0 6.0 0.0 3.0 6.0 9.0 0.0 4.0 8.0 12.0
The type parameter is needed only if you would like to convert the type of the matrix from an Int to a Double. So, the following call without the parameter would just return an Int matrix:
val denseTabulate=DenseMatrix.tabulate(5,4)((firstIdx,secondIdx)=>firstIdx*secondIdx) 0 1 2 3 0 2 4 6 0 3 6 9 0 4 8 12
The eye function of the matrix would generate an identity square matrix with the given dimension (in the example's case, 3):
val identityMatrix=DenseMatrix.eye[Int](3) Returns a DenseMatrix[Int] 1 0 0 0 1 0 0 0 1
The rand function in the matrix would generate a matrix of a given dimension (4 rows * 4 columns in our case) with random values between 0 and 1. We'll have an in-depth look into random number generated vectors and matrices in a subsequent recipe.
val randomMatrix=DenseMatrix.rand(4, 4) Returns DenseMatrix[Double] 0.09762565779429777 0.01089176285376725 0.2660579009292807 0.19428193961985674 0.9662568115400412 0.718377391997945 0.8230367668470933 0.3957540854393169 0.9080090988364429 0.7697780247035393 0.49887760321635066 0.26722019105654415 3.326843165250004E-4 0.447925644082819 0.8195838733418965 0.7682752255172411
We could create a matrix out of a Scala array too. The constructor of the matrix accepts three arguments—the rows, the columns, and an array with values for the dimensions. Note that the data from the array is picked up to construct the matrix in the column first order:
val vectFromArray=new DenseMatrix(2,2,Array(2,3,4,5)) Returns DenseMatrix[Int] 2 4 3 5
If there are more values than the number of values required by the dimensions of the matrix, the rest of the values are ignored. Note how (6,7) is ignored in the array:
val vectFromArray=new DenseMatrix(2,2,Array(2,3,4,5,6,7)) DenseMatrix[Int] 2 4 3 5
However, if fewer values are present in the array than what is required by the dimensions of the matrix, then the constructor call would throw an ArrayIndexOutOfBoundsException:
val vectFromArrayIobe=new DenseMatrix(2,2,Array(2,3,4)) //throws java.lang.ArrayIndexOutOfBoundsException: 3
Now let's look at the basic arithmetic that we could do using matrices.
Let's consider a simple 3*3 simpleMatrix and a corresponding identity matrix:
val simpleMatrix=DenseMatrix((1,2,3),(11,12,13),(21,22,23)) //DenseMatrix[Int] 1 2 3 11 12 13 21 22 23 val identityMatrix=DenseMatrix.eye[Int](3) //DenseMatrix[Int] 1 0 0 0 1 0 0 0 1
Adding two matrices will result in a matrix whose corresponding elements are summed up.
val additionMatrix=identityMatrix + simpleMatrix // Returns DenseMatrix[Int] 2 2 3 11 13 13 21 22 24
Now, as you would expect, multiplying a matrix with its identity should give you the matrix itself:
val simpleTimesIdentity=simpleMatrix * identityMatrix //Returns DenseMatrix[Int] 1 2 3 11 12 13 21 22 23
Breeze also has an alternative element-by-element operation that has the format of prefixing the operator with a colon, for example, :+,:-, :*, and so on. Check out what happens when we do an element-wise multiplication of the identity matrix and the simple matrix:
val elementWiseMulti=identityMatrix :* simpleMatrix //DenseMatrix[Int] 1 0 0 0 12 0 0 0 23
Let's briefly see how to append two matrices and convert matrices of one numeric type to another.
Similar to vectors, matrix has a vertcat function, which vertically concatenates an arbitrary number of matrices—the row size of the matrix just increases to the sum of the row sizes of all matrices combined:
val vertConcatMatrix=DenseMatrix.vertcat(identityMatrix, simpleMatrix) //DenseMatrix[Int] 1 0 0 0 1 0 0 0 1 1 2 3 11 12 13 21 22 23
Attempting to concatenate a matrix of different columns would, as expected, throw an IllegalArgumentException:
java.lang.IllegalArgumentException: requirement failed: Not all matrices have the same number of columns
Not surprisingly, the horzcat function concatenates the matrix horizontally—the column size of the matrix increases to the sum of the column sizes of all the matrices:
val horzConcatMatrix=DenseMatrix.horzcat(identityMatrix, simpleMatrix) // DenseMatrix[Int] 1 0 0 1 2 3 0 1 0 11 12 13 0 0 1 21 22 23
Similar to the vertical concatenation, attempting to concatenate a matrix of a different row size would throw an IllegalArgumentException:
java.lang.IllegalArgumentException: requirement failed: Not all matrices have the same number of rows
Let's create a simple 2*2 matrix that will be used for the rest of this section:
val simpleMatrix=DenseMatrix((4.0,7.0),(3.0,-5.0)) //DenseMatrix[Double] = 4.0 7.0 3.0 -5.0
The first column vector could be retrieved by passing in the column parameter as 0 and using :: in order to say that we are interested in all the rows.
val firstVector=simpleMatrix(::,0) //DenseVector(4.0, 3.0)
Getting the second column vector and so on is achieved by passing the correct zero-indexed column number:
val secondVector=simpleMatrix(::,1) //DenseVector(7.0, -5.0)
Alternatively, you could explicitly pass in the columns to be extracted:
val firstVectorByCols=simpleMatrix(0 to 1,0) //DenseVector(4.0, 3.0)
While explicitly stating the range (as in 0 to 1), we have to be careful not to exceed the matrix size. For example, the following attempt to select 3 columns (0 through 2) on a 2 * 2 matrix would throw an ArrayIndexOutOfBoundsException:
val errorTryingToSelect3ColumnsOn2By2Matrix=simpleMatrix(0,0 to 2) //java.lang.ArrayIndexOutOfBoundsException
If we would like to get the row vector, all we need to do is play with the row and column parameters again. As expected, it would give a transpose of the column vector, which is simply a row vector.
Like the column vector, we could either explicitly state our columns or pass in a wildcard (::) to cover the entire range of columns:
val firstRowStatingCols=simpleMatrix(0,0 to 1) //Transpose(DenseVector(4.0, 7.0)) val firstRowAllCols=simpleMatrix(0,::) //Transpose(DenseVector(4.0, 7.0))
Getting the second row vector is achieved by passing the second row (1) and all the columns (::) in that vector:
val secondRow=simpleMatrix(1,::) //Transpose(DenseVector(3.0, -5.0))
Assuming we are just interested in the values within the matrix, pass in the exact row and the column number of the matrix. In order to get the first row and first column of the matrix, just pass in the row and the column number:
val firstRowFirstCol=simpleMatrix(0,0) //Double = 4.0
Getting the inverse and the transpose of a matrix is a little counter-intuitive in Breeze. Let's consider the same matrix that we dealt with earlier:
val simpleMatrix=DenseMatrix((4.0,7.0),(3.0,-5.0))
On the one hand, transpose is a function on the matrix object itself, like so:
val transpose=simpleMatrix.t 4.0 3.0 7.0 -5.0
inverse, on the other hand is a universal function under the breeze.linalg package:
val inverse=inv(simpleMatrix) 0.12195121951219512 0.17073170731707318 0.07317073170731708 -0.0975609756097561
Let's do a matrix product to its inverse and confirm whether it is an identity matrix:
simpleMatrix * inverse 1.0 0.0 -5.551115123125783E-17 1.0
As expected, the result is indeed an identity matrix with rounding errors when doing floating point arithmetic.
Now, just like vectors, let's briefly look at how to calculate some basic summary statistics for a matrix.
Tip
This needs import of breeze.linalg._, breeze.numerics._ and, breeze.stats._. The operations in the "Other operations" section aims to simulate the NumPy's UFunc or universal functions.
Calculating the mean and variance of a matrix could be achieved by calling the meanAndVariance universal function in the breeze.stats package. Note that this needs a matrix of Double:
meanAndVariance(simpleMatrixAsDouble) // MeanAndVariance(12.0,75.75,9)
Alternatively, converting an Int matrix to a Double matrix and calculating the mean and variance for that Matrix could be merged into a one-liner:
meanAndVariance(convert(simpleMatrix, Double))
Calling the stddev on a Double vector could give the standard deviation:
stddev(simpleMatrixAsDouble) //Double = 8.703447592764606
Next up, let's look at some basic aggregation operations:
val simpleMatrix=DenseMatrix((1,2,3),(11,12,13),(21,22,23))
The (apply method of the) max object (a universal function) inside the breeze.linalg package will help us do that:
val intMaxOfMatrixVals=max (simpleMatrix) //23
The same as with max, the
sum object inside the breeze.linalg package calculates the sum of all the matrix elements:
val intSumOfMatrixVals=sum (simpleMatrix) //108
The functions sqrt, log, and various other objects (universal functions) in the breeze.numerics package calculate the square root and log values of all the individual values inside the matrix.
val sqrtOfMatrixVals= sqrt (simpleMatrix) //DenseMatrix[Double] = 1.0 1.4142135623730951 1.7320508075688772 3.3166247903554 3.4641016151377544 3.605551275463989 4.58257569495584 4.69041575982343 4.795831523312719
val log2MatrixVals=log(simpleMatrix) //DenseMatrix[Double] 0.0 0.6931471805599453 1.0986122886681098 2.3978952727983707 2.4849066497880004 2.5649493574615367 3.044522437723423 3.091042453358316 3.1354942159291497
Calculating eigenvectors is straightforward in Breeze. Let's consider our simpleMatrix from the previous section:
val simpleMatrix=DenseMatrix((4.0,7.0),(3.0,-5.0))
Calling the breeze.linalg.eig universal function on a matrix returns a breeze.linalg.eig.DenseEig object that encapsulate eigenvectors and eigenvalues:
val denseEig=eig(simpleMatrix)
This line of code returns the following:
Eig( DenseVector(5.922616289332565, -6.922616289332565), DenseVector(0.0, 0.0) ,0.9642892971721949 -0.5395744865143975 0.26485118719604456 0.8419378679586305)
We could extract the eigenvectors and eigenvalues by calling the corresponding functions on the returned Eig reference:
val eigenVectors=denseEig.eigenvectors //DenseMatrix[Double] = 0.9642892971721949 -0.5395744865143975 0.26485118719604456 0.8419378679586305
The two eigenValues corresponding to the two eigenvectors could be captured using the eigenvalues function on the Eig object:
val eigenValues=denseEig.eigenvalues //DenseVector[Double] = DenseVector(5.922616289332565, -6.922616289332565)
Let's validate the eigenvalues and the vectors:
Let's multiply the matrix with the first eigenvector:
val matrixToEigVector=simpleMatrix*denseEig.eigenvectors (::,0) //DenseVector(5.7111154990610915, 1.568611955536362)
Then let's multiply the first eigenvalue with the first eigenvector. The resulting vector will be the same with a marginal error when doing floating point arithmetic:
val vectorToEigValue=denseEig.eigenvectors(::,0) * denseEig.eigenvalues (0) //DenseVector(5.7111154990610915, 1.5686119555363618)
The same as with vectors, the initialization of the Breeze matrices are achieved by way of the apply method or one of the various methods in the matrix's Object class. Various other operations are provided by way of polymorphic functions available in the breeze.numeric, breeze.linalg and breeze.stats packages.
The breeze.stats.distributions package supplements the random number generator that is built into Scala. Scala's default generator just provides the ability to get the random values one by one using the "next" methods. Random number generators in Breeze provide the ability to build vectors and matrices out of these generators. In this recipe, we'll briefly see three of the most common distributions of random numbers.
In this recipe, we will cover at the following sub-recipes:
Creating vectors with uniformly distributed random values
Creating vectors with normally distributed random values
Creating vectors with random values that have a Poisson distribution
Creating a matrix with uniformly random values
Creating a matrix with normally distributed random values
Creating a matrix with random values that has a Poisson distribution
Before we delve into how to create the vectors and matrices out of random numbers, let's create instances of the most common random number distribution. All these generators are under the breeze.stats.distributions package:
//Uniform distribution with low being 0 and high being 10 val uniformDist=Uniform(0,10) //Gaussian distribution with mean being 5 and Standard deviation being 1 val gaussianDist=Gaussian(5,1) //Poission distribution with mean being 5 val poissonDist=Poisson(5)
We could actually directly sample from these generators. Given any distribution we created previously, we could sample either a single value or a sequence of values:
//Samples a single value println (uniformDist.sample()) //eg. 9.151191360491392 //Returns a sample vector of size that is passed in as parameter println (uniformDist.sample(2)) //eg. Vector(6.001980062275654, 6.210874664967401)
With no generator parameter, the DenseVector.rand method accepts a parameter for the length of the vector to be returned. The result is a vector (of length 10) with uniformly distributed values between 0 and 1:
val uniformWithoutSize=DenseVector.rand(10) println ("uniformWithoutSize \n"+ uniformWithoutSize) //DenseVector(0.1235038023750481, 0.3120595941786264, 0.3575638744660876, 0.5640844223813524, 0.5336149399548831, 0.1338053814330793, 0.9099684427908603, 0.38690724148973166, 0.22561993631651522, 0.45120359622713657)
The DenseVector.rand method optionally accepts a distribution object and generates random values using that input distribution. The following line generates a vector of 10 uniformly distributed random values that are within the range 0 and 10:
val uniformDist=Uniform(0,10) val uniformVectInRange=DenseVector.rand(10, uniformDist) println ("uniformVectInRange \n"+uniformVectInRange) //DenseVector(1.5545833905907314, 6.172564377264846, 8.45578509265587, 7.683763574965107, 8.018688137742062, 4.5876187984930406, 3.274758584944064, 2.3873947264259954, 2.139988841403757, 8.314112884416943)
In the place of the uniformDist generator, we could also pass the previously created Gaussian generator, which is configured to yield a distribution that has a mean of 5 and standard deviation of 1:
val gaussianVector=DenseVector.rand(10, gaussianDist) println ("gaussianVector \n"+gaussianVector) //DenseVector(4.235655596913547, 5.535011377545014, 6.201428236839494, 6.046289604188366, 4.319709374229152, 4.2379652913447154, 2.957868021601233, 3.96371080427211, 4.351274306757224, 5.445022658876723)
Similarly, by passing the previously created Poisson random number generator, a vector of values that has a mean of 5 could be generated:
val poissonVector=DenseVector.rand(10, poissonDist) println ("poissonVector \n"+poissonVector) //DenseVector(5, 5, 7, 11, 7, 6, 6, 6, 6, 6)
We saw how easy it is to create a vector of random values. Now, let's proceed to create a matrix of random values. Similar to DenseVector.rand to generate vectors with random values, we'll use the DenseMatrix.rand function to generate a matrix of random values.
The DenseMatrix.rand defaults to the uniform distribution and generates a matrix of random values given the row and the column parameter. However, if we would like to have a distribution within a range, then as in vectors, we could use the optional parameter:.
//Uniform distribution, Creates a 3 * 3 Matrix with random values from 0 to 1 val uniformMat=DenseMatrix.rand(3, 3) println ("uniformMat \n"+uniformMat) 0.4492155777289115 0.9098840386699856 0.8203022252988292 0.0888975848853315 0.009677790736892788 0.6058885905934237 0.6201415814136939 0.7017492438727635 0.08404147915159443 //Creates a 3 * 3 Matrix with uniformly distributed random values with low being 0 and high being 10 val uniformMatrixInRange=DenseMatrix.rand(3,3, uniformDist) println ("uniformMatrixInRange \n"+uniformMatrixInRange) 7.592014659345548 8.164652560340933 6.966445294464401 8.35949395084735 3.442654641743763 3.6761640240938442 9.42626645215854 0.23658921372298636 7.327120138868571
Just as in vectors, in place of the uniformDist generator, we could also pass the previously created Gaussian generator to the rand function to generate a matrix of random values that has a mean of 5 and standard deviation of 1:
//Creates a 3 * 3 Matrix with normally distributed random values with mean being 5 and Standard deviation being 1 val gaussianMatrix=DenseMatrix.rand(3, 3,gaussianDist) println ("gaussianMatrix \n"+gaussianMatrix) 5.724540885605018 5.647051873430568 5.337906135107098 6.2228893721489875 4.799561665187845 5.12469779489833 5.136960834730864 5.176410360757703 5.262707072950913
Similarly, by passing the previously created Poisson random number generator, a matrix of random values that has a mean of 5 could be generated:
//Creates a 3 * 3 Matrix with Poisson distribution with mean being 5 val poissonMatrix=DenseMatrix.rand(3, 3,poissonDist) println ("poissonMatrix \n"+poissonMatrix) 4 11 3 6 6 5 6 4 2
Reading and writing a CSV file in Breeze is really a breeze. We just have two functions in breeze.linalg package to play with. They are very intuitively named csvread and csvwrite.
In this recipe, you'll see how to:
Read a CSV file into a matrix
Save selected columns of a matrix into a new matrix
Write the newly created matrix into a CSV file
Extract a vector out of the matrix
Write the vector into a CSV
There are just two functions that we need to remember in order to read and write data from and to CSV files. The signatures of the functions are pretty straightforward too:
csvread(file, separator, quote, escape, skipLines) csvwrite(file, mat, separator, quote, escape, skipLines)
Let's look at the parameters by order of importance:
file:java.io.File: Represents the file location.separator: Defaults to a comma so as to represent a CSV. Could be overridden when needed.skipLines: This is the number of lines to be skipped while reading the file. Generally, if there is a header, we pass askipLines=1.mat: While writing, this is the matrix object that is being written.quote: This defaults to double quotes. It is a character that implies that the value inside is one single value.escape: This defaults to a backspace. It is a character used to escape special characters.
Let's see these in action. For the sake of clarity, I have skipped the quote and the escape parameter while calling the csvread and csvwrite functions. For this recipe, we will do three things:
Read a CSV file as a matrix
Extract a sub-matrix out of the read matrix
Write the matrix
Read the CSV as a matrix:
Let's use the
csvreadfunction to read a CSV file into a 100*3 matrix. We'll also skip the header while reading and print 5 rows as a sample:
val usageMatrix=csvread(file=new File("WWWusage.csv"), separator=',', skipLines=1) //print first five rows println ("Usage matrix \n"+ usageMatrix(0 to 5,::)) Output : 1.0 1.0 88.0 2.0 2.0 84.0 3.0 3.0 85.0 4.0 4.0 85.0 5.0 5.0 84.0 6.0 6.0 85.0
Extract a sub-matrix out of the read matrix:
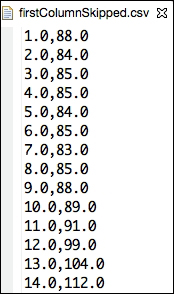
For the sake of generating a submatrix let's skip the first column and save the second and the third column into a new matrix. Let's call it
firstColumnSkipped:val firstColumnSkipped= usageMatrix(::, 1 to usageMatrix.cols-1) //Sample some data so as to ensure we are fine println ("First Column skipped \n"+ firstColumnSkipped(0 to 5, ::)) Output : 1.0 88.0 2.0 84.0 3.0 85.0 4.0 85.0 5.0 84.0 6.0 85.0
Write the matrix:
As a final step, let's write the
firstColumnSkippedmatrix to a new CSV file namedfirstColumnSkipped.csv://Write this modified matrix to a file csvwrite(file=new File ("firstColumnSkipped.csv"), mat=firstColumnSkipped, separator=',')