


















 Download code from GitHub
Download code from GitHub
You have probably at least once written some very neat Haskell you were very proud of, until you test the code and it took ages to give an answer or even ran out of memory. This is very normal, especially if you are used to performance semantics in which performance can be analyzed on a step-by-step basis. Analyzing Haskell code requires a different mental model that is more akin to graph traversal.
Luckily, there is no reason to think that writing efficient Haskell is sorcery known only by math wizards or academics. Most bottlenecks are straightforward to identify with some understanding of Haskell's evaluation schema. This chapter will help you to reason about the performance of Haskell programs and to avoid some easily recognizable patterns of bad performance:
Understanding lazy evaluation schemas and their implications
Handling intended and unintended value memoization (CAFs)
Utilizing (guarded) recursion and the worker/wrapper pattern efficiently
Using accumulators correctly to avoid space leaks
Analyzing strictness and space usage of Haskell programs
Important compiler code optimizations, inlining and fusion
The default evaluation strategy in Haskell is lazy, which intuitively means that evaluation of values is deferred until the value is needed. To see lazy evaluation in action, we can fire up GHCi and use the :sprint command to inspect only the evaluated parts of a value. Consider the following GHCi session:
> let xs = enumFromTo 1 5 :: [Int] > :sprint xs xs = _ > xs !! 2 3 > :sprint xs xs = 1 : 2 : 3 : _
Tip
The code bundle for the book is also hosted on GitHub at https://github.com/PacktPublishing/Haskell-High-Performance-Programming. We also have other code bundles from our rich catalog of books and videos available at https://github.com/PacktPublishing/. Check them out!
Underscores in the output of :sprint stand for unevaluated values. The enumFromTo function builds a linked list lazily. At first, xs is only an unevaluated thunk. Thunks are in a way pointers to some calculation that is performed when the value is needed. The preceding example illustrates this: after we have asked for the third element of the list, the list has been evaluated up to the third element. Note also how pure values are implicitly shared; by evaluating the third element after binding the list to a variable, the original list was evaluated up to the third element. It will remain evaluated as such in memory until we destroy the last reference to the list head.
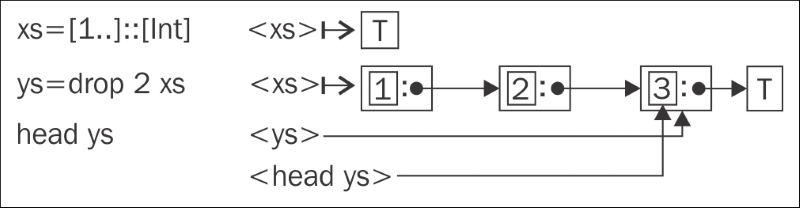
The preceding figure is a graphical representation of how a list is stored in memory. A T stands for a thunk; simple arrows represent pointers.
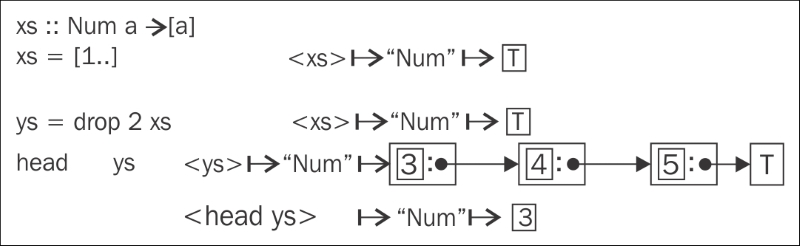
The preceding scenario is otherwise identical to the previous one, but now the list is polymorphic. Polymorphic values are simply functions with implicit parameters that provide the required operations when the type is specialized.
Note
Be careful with :sprint and ad hoc polymorphic values! For example, xs' = enumFromTo 1 5 is by default given the type Num a => [a]. To evaluate such an expression, the type for a must be filled in, meaning that in :sprint xs', the value xs' is different from its first definition. Fully polymorphic values such as xs'' = [undefined, undefined] are okay.
A shared value can be either a performance essential or an ugly space leak. Consider the following seemingly similar scenarios (run with ghci +RTS -M20m to not throttle your computer):
> Data.List.foldl' (+) 0 [1..10^6] 500000500000 > let xs = [1..10^6] :: [Int] > Data.List.foldl' (+) 0 xs <interactive>: Heap exhausted;
So what happened? By just assigning the list to a variable, we exhausted the heap of a calculation that worked just fine previously. In the first calculation, the list could be garbage-collected as we folded over it. But in the second scenario, we kept a reference to the head of the linked list. Then the calculation blows up, because the elements cannot be garbage-collected due to the reference to xs.
Notice that in the previous example we used a strict variant of left-fold called foldl' from Data.List and not the foldl exported from Prelude. Why couldn't we have just as well used the latter? After all, we are only asking for a single numerical value and, given lazy evaluation, we shouldn't be doing anything unnecessary. But we can see that this is not the case (again with ghci +RTS -M20m):
> Prelude.foldl (+) 0 [1..10^6] <interactive>: Heap exhausted;
To understand the underlying issue here, let's step away from the fold abstraction for a moment and instead write our own sum function:
mySum :: [Int] -> Int mySum [] = 0 mySum (x:xs) = x + mySum xs
By testing it, we can confirm that mySum too exhausts the heap:
> :load sums.hs > mySum [1..10^6] <interactive>: Heap exhausted;
Because mySum is a pure function, we can expand its evaluation by hand as follows:
mySum [1..100]
= 1 + mySum [2..100]
= 1 + (2 + mySum [2..100])
= 1 + (2 + (3 + mySum [2..100]))
= ...
= 1 + (2 + (... + mySum [100]))
= 1 + (2 + (... + (100 + 0)))From the expanded form we can see that we build up a huge sum chain and then start reducing it, starting from the very last element on the list. This means that we have all the elements of the list simultaneously in memory. From this observation, the obvious thing we could try is to evaluate the intermediate sum at each step. We could define a mySum2 which does just this:
mySum2 :: Int -> [Int] -> Int mySum2 s [] = s mySum2 s (x:xs) = let s' = s + x in mySum2 s' xs
But to our disappointment mySum2 blows up too! Let's see how it expands:
mySum2 0 [1..100]
= let s1 = 0 + 1 in mySum2 s1 [2..100]
= let s1 = 0 + 1
s2 = s1 + 2
in mySum2 s2 [2..100]
...
= let s1 = 0 + 1
...
s100 = s99 + 100
in mySum2 s100 []
= s100
= s99 + 100
= (s89 + 99) + 100
...
= ((1 + 2) + ... ) + 100Oops! We still build up a huge sum chain. It may not be immediately clear that this is happening. One could perhaps expect that 1 + 2 would be evaluated immediately as 3 as it is in strict languages. But in Haskell, this evaluation does not take place, as we can confirm with :sprint:
> let x = 1 + 2 :: Int > :sprint x x = _
Note that our mySum is a special case of foldr and mySum2 corresponds to foldl.
The problem in our mySum2 function was too much laziness. We built up a huge chain of numbers in memory only to immediately consume them in their original order. The straightforward solution then is to decrease laziness: if we could force the evaluation of the intermediate sums before moving on to the next element, our function would consume the list immediately. We can do this with a system function, seq:
mySum2' :: [Int] -> Int -> Int
mySum2' [] s = s
mySum2' (x:xs) s = let s' = s + x
in seq s' (mySum2' xs s')This version won't blow up no matter how big a list you give it. Speaking very roughly, the seq function returns its second argument and ties the evaluation of its first argument to the evaluation of the second. In seq a b, the value of a is always evaluated before b. However, the notion of evaluation here is a bit ambiguous, as we will see soon.
When we evaluate a Haskell value, we mean one of two things:
Consider the following GHCi session:
> let t = const (Just "a") () :: Maybe String > :sprint t t = _ > t `seq` () > :sprint t t = Just _
Even though we seq the value of t, it was only evaluated up to the Just constructor. The list of characters inside was not touched at all. When deciding whether or not a seq is necessary, it is crucial to understand WHNF and your data constructors. You should take special care of accumulators, like those in the intermediate sums in the mySum* functions. Because the actual value of the accumulator is often used only after the iterator has finished, it is very easy to accidentally build long chains of unevaluated thunks.
Now going back to folds, we recall that both foldl and foldr failed miserably, while (+) . foldl' instead did the right thing. In fact, if you just turn on optimizations in GHC then foldl (+) 0 will be optimized into a tight constant-space loop. This is the mechanism behind why we can get away with Prelude.sum, which is defined as foldl (+) 0.
What do we then have the foldr for? Let's look at the evaluation of foldr f a xs:
foldr f a [x1,x2,x3,x4,...]
= f x1 (foldr f a [x2,x3,x4,...])
= f x1 (f x2 (foldr f a [x3,x4,...]))
= f x1 (f x2 (f x3 (foldr f a [x4,...])))
…Note that, if the operator f isn't strict in its second argument, then foldr does not build up chains of unevaluated thunks. For example, let's consider foldr (:) [] [1..5]. Because (:) is just a data constructor, it is for sure lazy in its second (and first) argument. That fold then simply expands to 1 : (2 : (3 : ...)), so it is the identity function for lists.
Monadic bind (>>) for the IO monad is another example of a function that is lazy in its second argument:
foldr (>>) (return ()) [putStrLn "Hello", putStrLn "World!"]
For those monads whose actions do not depend on later actions, (that is, printing "Hello" is independent from printing "World!" in the IO monad), bind is non-strict in its second argument. On the other hand, the list monad is an example where bind is generally non-strict in its second argument. (Bind for lists is strict unless the first argument is the empty list.)
To sum up, use a left-fold when you need an accumulator function that is strict in both its operands. Most of the time, though, a right-fold is the best option. And with infinite lists, right-fold is the only option.
Memoization is a dynamic programming technique where intermediate results are saved and later reused. Many string and graph algorithms make use of memoization. Calculating the Fibonacci sequence, instances of the knapsack problem, and many bioinformatics algorithms are almost inherently solvable only with dynamic programming. A classic example in Haskell is the algorithm for the nth Fibonacci number, of which one variant is the following:
-- file: fib.hs
fib_mem :: Int -> Integer
fib_mem = (map fib [0..] !!)
where fib 0 = 1
fib 1 = 1
fib n = fib_mem (n-2) + fib_mem (n-1)Try it with a reasonable input size (10000) to confirm it does memoize the intermediate numbers. The time for lookups grows in size with larger numbers though, so a linked list is not a very appropriate data structure here. But let's ignore that for the time being and focus on what actually enables the values of this function to be memoized.
Looking at the top level, fib_mem looks like a normal function that takes input, does a computation, returns a result, and forgets everything it did with regard to its internal state. But in reality, fib_mem will memoize the results of all inputs it will ever be called with during its lifetime. So if fib_mem is defined at the top level, the results will persist in memory over the lifetime of the program itself!
The short story of why memoization is taking place in fib_mem stems from the fact that in Haskell functions exist at the same level with normal values such as integers and characters; that is, they are all values. Because the parameter of fib_mem does not occur in the function body, the body can be reduced irrespective of the parameter value. Compare fib_mem to this fib_mem_arg:
fib_mem_arg :: Int -> Integer
fib_mem_arg x = map fib [0..] !! x
where fib 0 = 1
fib 1 = 1
fib n = fib_mem_arg (n-2) + fib_mem_arg (n-1)Running fib_mem_arg with anything but very small arguments, one can confirm it does no memoization. Even though we can see that map fib [0..] does not depend on the argument number and could be memorized, it will not be, because applying an argument to a function will create a new expression that cannot implicitly have pointers to expressions from previous function applications. This is equally true with lambda abstractions as well, so this fib_mem_lambda is similarly stateless:
fib_mem_lambda :: Int -> Integer
fib_mem_lambda = \x -> map fib [0..] !! x
where fib 0 = 1
fib 1 = 1
fib n = fib_mem_lambda (n-2) + fib_mem_lambda (n-1)With optimizations, both fib_mem_arg and fib_mem_lambda will get rewritten into a form similar to fib_mem. So in simple cases, the compiler will conveniently fix our mistakes, but sometimes it is necessary to reorder complex computations so that different parts are memoized correctly.
Tip
Be wary of memoization and compiler optimizations. GHC performs aggressive inlining (Explained in the section, Inlining and stream fusion) as a routine optimization, so it's very likely that values (and functions) get recalculated more often than was intended.
The formal difference between fib_mem and the others is that the fib_mem is something called a
constant applicative form, or CAF for short. The compact definition of a CAF is as follows: a supercombinator that is not a lambda abstraction. We already covered the not-a-lambda abstraction, but what is a supercombinator?
A supercombinator is either a constant, say 1.5 or ['a'..'z'], or a combinator whose subexpressions are supercombinators. These are all supercombinators:
\n -> 1 + n \f n -> f 1 n \f -> f 1 . (\g n -> g 2 n)
But this one is not a supercombinator:
\f g -> f 1 . (\n -> g 2 n)
This is because g is not a free variable of the inner lambda abstraction.
CAFs are constant in the sense that they contain no free variables, which guarantees that all thunks a CAF references directly are also constants. Actually, the constant subvalues are a part of the value. Subvalues are automatically memoized within the value itself.
A top-level [Int], say, is just as valid a value as the fib_mem function for holding references to other values. You should pay attention to CAFs in your code because memoized values are space leaks when the memoization was unintended. All code that allocates lots of memory should be wrapped in functions that take one or more parameters.
Recursion is perhaps the most important pattern in functional programming. Recursive functions are more practical in Haskell than in imperative languages, due to referential transparency and laziness. Referential transparency allows the compiler to optimize the recursion away into a tight inner loop, and laziness means that we don't have to evaluate the whole recursive expression at once.
Next we will look at a few useful idioms related to recursive definitions: the worker/wrapper transformation, guarded recursion, and keeping accumulator parameters strict.
Worker/wrapper transformation is an optimization that GHC sometimes does, but worker/wrapper is also a useful coding idiom. The idiom consists of a (locally defined, tail-recursive) worker function and a (top-level) function that calls the worker. As an example, consider the following naive primality test implementation:
-- file: worker_wrapper.hs
isPrime :: Int -> Bool
isPrime n
| n <= 1 = False
| n <= 3 = True
| otherwise = worker 2
where
worker i | i >= n = True
| mod n i == 0 = False
| otherwise = worker (i+1)Here, isPrime is the wrapper and worker is the worker function. This style has two benefits. First, you can rest assured it will compile into optimal code. Second, the worker/wrapper style is both concise and flexible; notice how we did preliminary checks in the wrapper code before invoking the worker, and how the argument n is also (conveniently) in the worker's scope too.
In strict languages, tail-call optimization is often a concern with recursive functions. A function f is tail-recursive if the result of a recursive call to f is the result. In a lazy language such as Haskell, tail-call "optimization" is guaranteed by the evaluation schema. Actually, because in Haskell evaluation is normally done only up to WHNF (outmost data constructor), we have something more general than just tail-calls, called guarded recursion. Consider this simple moving average implementation:
-- file: sma.hs sma :: [Double] -> [Double] sma (x0:x1:xs) = (x0 + x1) / 2 : sma (x1:xs) sma xs = xs
The sma function is not tail-recursive, but nonetheless it won't build up a huge stack like an equivalent in some other language might do. In sma, the recursive callis guarded by the (:) data constructor. Evaluating the first element of a call to sma does not yet make a single recursive call to sma. Asking for the second element initiates the first recursive call, the third the second, and so on.
As a more involved example, let's build a reverse polish notation (RPN) calculator. RPN is a notation where operands precede their operator, so that (3 1 2 + *) in RPN corresponds to ((3 + 1) * 2), for example. To make our program easier to understand, we wish to separate parsing the input from performing the calculation:
-- file: rpn.hs
data Lex = Number Double Lex
| Plus Lex
| Times Lex
| End
lexRPN :: String -> Lex
lexRPN = go . words
where go ("*":rest) = Times (go rest)
go ("+":rest) = Plus (go rest)
go (num:rest) = Number (read num) (go rest)
go [] = EndThe Lex datatype represents a formula in RPN and is similar to the standard list type. The lexRPN function reads a formula from string format into our own datatype. Let's add an evalRPN function, which evaluates a parsed RPN formula:
evalRPN :: Lex -> Double
evalRPN = go []
where
go stack (Number num rest)
= go (num : stack) rest
go (o1:o2:stack) (Plus rest)
= let r = o1 + o2 in r `seq` go (r : stack) rest
go (o1:o2:stack) (Times rest)
= let r = o1 * o2 in r `seq` go (r : stack) rest
go [res] End
= resWe can test this implementation to confirm that it works:
> :load rpn.hs > evalRPN $ lexRPN "5 1 2 + 4 * *" 60.0
The RPN expression (5 1 2 + 4 * *) is (5 * ((1 + 2) * 4)) in infix, which is indeed equal to 60.
Note how the lexRPN function makes use of guarded recursion when producing the intermediate structure. It reads the input string incrementally and yields the structure an element at a time. The evaluation function evalRPN consumes the intermediate structure from left to right and is tail-recursive, so we keep the minimum amount of things in memory at all times.
Note
Linked lists equipped with guarded recursion (and lazy I/O) actually provide a lightweight streaming facility – for more on streaming see Chapter 6, I/O and Streaming.
In our examples so far, we have encountered a few functions that used some kind of accumulator. mySum2 had an Int that increased on every step. The go worker function in evalRPN passed on a stack (a linked list). The former had a space leak, because we didn't require the accumulator's value until at the end, at which point it had grown into a huge chain of pointers. The latter case was okay because the stack didn't grow in size indefinitely and the parameter was sufficiently strict in the sense that we didn't unnecessarily defer its evaluation. The fix we applied in mySum2' was to force the accumulator to WHNF at every iteration, even though the result was not strictly speaking required in that iteration.
The final lesson is that you should apply special care to your accumulator's strictness properties. If the accumulator must always be fully evaluated in order to continue to the next step, then you're automatically safe. But if there is a danger of an unnecessary chain of thunks being constructed due to a lazy accumulator, then adding a seq (or a bang pattern, see Chapter 2, Choose the Correct Data Structures) is more than just a good idea.
It is often necessary to have numbers about the time and space usage of Haskell programs, either to have an indicator of how well the program performs or to identify unnecessary allocations. The GHC Runtime System flag -s enables printing allocation and garbage-collection statistics when the program finishes.
Let's try this with an example program, which naively calculates the covariance of two lists:
-- file: time_and_space.hs
import Data.List (foldl')
sum' = foldl' (+) 0
mean :: [Double] -> Double
mean v = sum' v / fromIntegral (length v)
covariance :: [Double] -> [Double] -> Double
covariance xs ys =
sum' (zipWith (\x y -> (x - mean xs) * (y - mean ys)) xs ys)
/ fromIntegral (length xs)
main = do
let xs = [1, 1.1 .. 500]
ys = [2, 2.1 .. 501]
print $ covariance xs ysTo enable passing options for the Runtime System, we must compile with -rtsopts:
$ ghc -rtsopts time_and_space.hs
For the time being, we ignore optimizations GHC could do for us and compile the program without any:
$ ./time_and_space +RTS -s 20758.399999992813 802,142,688 bytes allocated in the heap 1,215,656 bytes copied during GC 339,056 bytes maximum residency (2 sample(s)) 88,104 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 1529 colls, 0 par 0.008s 0.007s 0.0000s 0.0004s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0003s 0.0006s INIT time 0.000s ( 0.000s elapsed) MUT time 1.072s ( 1.073s elapsed) GC time 0.008s ( 0.008s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 1.083s ( 1.082s elapsed) %GC time 0.8% (0.7% elapsed) Alloc rate 747,988,284 bytes per MUT second Productivity 99.2% of total user, 99.3% of total elapsed
On the first line of output from the Runtime System, we see that we allocated over 800 megabytes of memory. This is quite a lot for a program that only handles two lists of 5,000 double-precision values. There is definitely something in our code that could be made a lot more efficient. The output also contains other useful information, such as the total memory in use and, more importantly, some statistics on garbage collection. Our program spent only 0.8% of time in GC, meaning the program was doing productive things 99.2% of the time. So our performance problem lies in the calculations our program performs themselves.
If we look at the definition of covariance, we can spot the many invocations to mean in the argument lambda to zipWith: we actually calculate the means of both lists thousands of times over. So let's optimize that away:
covariance' :: [Double] -> [Double] -> Double
covariance' xs ys =
let mean_xs = mean xs
mean_ys = mean ys
in
sum' (zipWith (\x y -> (x - mean_xs) * (y - mean_ys)) xs ys)
/ fromIntegral (length xs)With covariance' we get down to three megabytes of allocation:
3,263,680 bytes allocated in the heap 915,024 bytes copied during GC 339,032 bytes maximum residency (2 sample(s)) 112,936 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 5 colls, 0 par 0.002s 0.002s 0.0003s 0.0005s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0005s 0.0010s INIT time 0.000s ( 0.000s elapsed) MUT time 0.003s ( 0.003s elapsed) GC time 0.003s ( 0.003s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 0.008s ( 0.006s elapsed) %GC time 35.3% (44.6% elapsed) Alloc rate 1,029,648,194 bytes per MUT second Productivity 63.1% of total user, 79.6% of total elapsed
That's over a 250-fold decrease in heap allocation! With the new version, we now have a considerable amount of time going to GC, about a third. This is about as good as we can get without enabling compiler optimizations; if we compile with -O, we would get to under two megabytes of heap allocation. And if you tried the original covariance performance with optimizations on, you should get exactly the same performance as with the newer hand-optimized variant. In fact, both versions compile to the same assembly code. This is a demonstration of the sophistication of GHC's optimizer, which we will take a deeper look at in a later chapter.
Tip
GHCi tip:
By setting +s in the interpreter, you can get time and space statistics of every evaluation, which can be handy for quick testing. Keep in mind though that no optimizations can be enabled for interpreted code, so compiled code can have very different performance characteristics. To test with optimizations, you should compile the module with optimizations and then import it into GHCi.
In the covariance example, we observed that we could improve code performance by explicitly sharing the result of an expensive calculation. Alternatively, enabling compiler optimizations would have had that same effect (with some extras). Most of the time, the optimizer does the right thing, but that is not always the case. Consider the following versions of rather a silly function:
-- file: time_and_space_2.hs goGen u = sum [1..u] + product [1..u] goGenShared u = let xs = [1..u] in sum xs + product xs
Try reasoning which of these functions executes faster. The first one builds two possibly very large lists and then immediately consumes them, independent of each other. The second one shares the list between sum and product.
The list-sharing function is about 25% slower than the list-rebuilding function. When we share the list, we need to keep the whole list in memory, whereas by just enumerating the elements we can discard the elements as we go. The following table confirms our reasoning. The list-sharing function has a larger maximum residency in system memory and does more GC:
|
U = 10000 |
Time |
Allocated heap |
Copied during GC |
Maximum residency |
Total memory |
Time in GC |
|---|---|---|---|---|---|---|
|
|
0.050ms |
87 MB |
10 MB |
0.7 MB |
6 MB |
60% |
|
|
0.070ms |
88 MB |
29 MB |
0.9 MB |
7 MB |
70% |
Recall that, in the covariance example, the compiler automatically shared the values of sin x and cos x for us when we enabled optimizations. But in the previous example, we didn't get implicit sharing of the lists, even though they are thunks just like the results of sin x and cos x. So what magic enabled the GHC optimizer to choose the best sharing schema in both cases? The optimizer is non-trivial, and unfortunately, in practice it's not feasible to blindly rely on the optimizer always doing "the right thing." If you need to be sure that some sharing will take place, you should test it yourself.
Let's go back to our previous example of sum and product. Surely we could do better than spending 60% of the time in GC. The obvious improvement would be to make only one pass through one list and calculate both the sum and product of the elements simultaneously. The code is then a bit more involved:
goGenOnePass u = su + pu
where
(su, pu) = foldl f (0,1) [1..u]
f (s, p) i = let s' = s+i
p' = p*i
in s' `seq` p' `seq` (s', p')Note the sequential use of seq in the definition of goGenOnePass. This version has a much better performance: only 10% in GC and about 50% faster than our first version:
|
U = 10000 |
Time |
Allocated heap |
Copied during GC |
Maximum residency |
Total memory |
Time in GC |
|---|---|---|---|---|---|---|
|
|
0.025ms |
86 MB |
0.9 MB |
0.05 MB |
2 MB |
10% |
The takeaway message is that once again algorithmic complexity matters more than technical optimizations. The one-pass version executed in half the time of the original two-pass version, as would be expected.
Note
With the Bang Patterns (BangPatterns) language extension (available since GHC 6.6) the f binding could have been written more cleanly as f (!s, !p) i = (s + i, p * I) with very slightly degraded performance (0.7%). Annotating a binding with a bang means that evaluation of that binding will be bound to the evaluation of its surrounding tuple.
Haskell compilers perform aggressive optimization transformations on code. GHC optimization passes are highly sophisticated, so much that one rarely needs to worry about performance. We have seen some of the effects of ghc -O1 in our examples so far; in all cases,-O1increased performance relative to no optimizations, or -Onot, and in some optimizations passes were the difference between constant and exponential complexity.
GHC performs aggressive inlining, which simply means rewriting a function call with the function's definition. Because all values in Haskell are referentially transparent, any function can be inlined within the scope of its definition. Especially in loops, inlining improves performance drastically. The GHC inliner does inlining within a module, but also to some extent cross-module and cross-package.
Some rules of thumb regarding inlining:
If a definition is only used once, and isn't exported, it will always be inlined.
When a function body is small, it will almost certainly be inlined no matter where or how often it is used.
Bigger functions may be inlined cross-module. To ensure that foo is always inlined,
add a {-# INLINE foo #-}pragma near the definition offoo.
With these easy rules, you rarely need to worry about problems from bad inlining. For completeness's sake, there is also a NOINLINE pragma which ensures a definition is never inlined. NOINLINE is mostly used for hacks that would break referential transparency; see Chapter 4, The Devil's in the Detail.
Another powerful technique is stream fusion. Behind that fancy name is just a bunch of equations that are used to perform code rewriting (see Chapter 4, The Devil's in the Detail for the technicalities).
When working with lists, you may be tempted to rewrite code like this:
map f . map g . map h
Rather than to use intermediate lists:
map (f . g . h)
But there is no other reason than cosmetics to do this, because with optimizations GHC performs stream fusion, after which both expressions are time- and space-equivalent. Stream fusion is also performed for other structures than [], which we will take a look at in the next chapter.
In principle, (ad hoc) polymorphic programs should carry a performance cost. To evaluate a polymorphic function, a dictionary must be passed in, which contains the specializations for the type specified on the caller side. However, almost always GHC can fill in the dictionary already at compile time, reducing the cost of polymorphism to zero. The big and obvious exception is code that uses reflection (Typeable). Also, some sufficiently complex polymorphic code might defer the dictionary passing to runtime, although, most of the time you can expect a zero cost.
Either way, it might ease your mind to have some notion of the cost of dictionary passing in runtime. Let's write a program with both general and specialized versions of the same function, compile it without optimizations, and compare the performance. Our program will just iterate a simple calculation with double-precision values:
-- file: class_performance.hs
class Some a where
next :: a -> a -> a
instance Some Double where
next a b = (a + b) / 2
goGeneral :: Some a => Int -> a -> a
goGeneral 0 x = x
goGeneral n x = goGeneral (n-1) (next x x)
goSpecialized :: Int -> Double -> Double
goSpecialized 0 x = x
goSpecialized n x = goSpecialized (n-1) (next' x x)
next' :: Double -> Double -> Double
next' a b = (a + b) / 2I compiled and ran both versions separately with their own main entry points using the following command lines:
ghc class_performance.hs time ./class_performance +RTS -s
On my machine, with 5,000,000 iterations, the general version does 1.09 GB of allocation and takes 3.4s. The specialized version does 1.01 GB of allocation and runs in about 3.2s. So the extra memory cost was about 8%, which is considerable. But by enabling optimizations, both versions will have exactly the same performance.
Here's a puzzle: given the following definition, which is faster, partial or total?
partialHead :: [a] -> a
partialHead (x:_) = x
totalHead :: [a] -> Maybe a
totalHead [] = Nothing
totalHead (x:_) = Just x
partial = print $ partialHead [1..]
total = print $ case totalHead [1..] of
Nothing -> 1
Just n -> nThe total variant uses a head that wraps its result inside a new data constructor, whereas the partial one results in a crash when a case is not matched, but in exchange doesn't perform any extra wrapping. Surely the partial variant must be faster, right? Well, almost always it is not. Both functions have exactly the same time and space requirements.
Partial functions are justified in some situations, but performance is rarely if ever one of them. In the example, the Maybe-wrapper of total will have a zero performance cost. The performance cost of the case analysis will be left, however, but a similar analysis is done in the partial variant too; the error case must be handled anyway, so that the program can exit gracefully. Of course, even GHC is not a silver bullet and you should always keep in mind that it might miss some optimizations. If you absolutely need to rely on certain optimizations to take place, you should test your program to confirm the correct results.
In this chapter, we learned how lazy evaluation works, what weak head normal form is, and how to control it by increasing strictness with different methods. We considered the peculiarities of right-fold, left-fold, and strict left-fold, and in which situations one fold strategy works better than another. We introduced the concept of CAF along with memoization techniques, utilized the worker/wrapper pattern, and used guarded recursion to write clean and efficient recursive programs.
We used the :sprint command in GHCi to inspect unevaluated thunks and the Runtime System option -s to inspect the heap usage and GC activity of compiled programs. We took a look at inlining, stream fusion, and the performance costs of partial functions and polymorphism.
In the next chapter, we will take a look at other basic data and control structures, such as different array structures and some monads. But first, we will learn about the performance semantics of Haskell data types and related common optimization techniques.

