























































Python to RDD communications
Whenever a PySpark program is executed using RDDs, there is a potentially large overhead to execute the job. As noted in the following diagram, in the PySpark driver, the Spark Context uses Py4j to launch a JVM using the JavaSparkContext. Any RDD transformations are initially mapped to PythonRDD objects in Java.
Once these tasks are pushed out to the Spark Worker(s), PythonRDD objects launch Python subprocesses using pipes to send both code and data to be processed within Python:
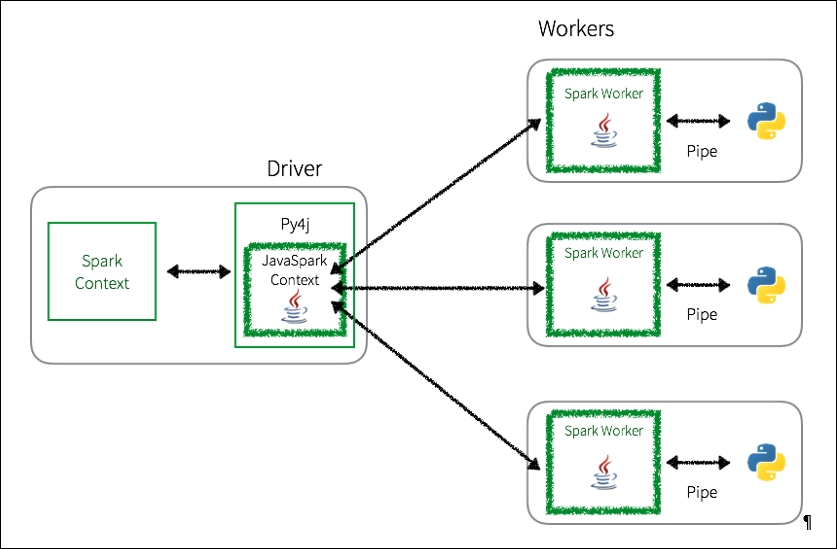
While this approach allows PySpark to distribute the processing of the data to multiple Python subprocesses on multiple workers, as you can see, there is a lot of context switching and communications overhead between Python and the JVM.
Note
An excellent resource on PySpark performance is Holden Karau's Improving PySpark Performance: Spark performance beyond the JVM: http://bit.ly/2bx89bn.
























