


















CISO and CTO have been spending a huge amount of money on web applications and general IT security without getting the benefits, and they are living with a false sense of security. Although IT security has been a top priority for organizations, there have been some big security breaches in the last few years. The attack on the Target Corp, one of the biggest retailers in the US, exposed around 40 million debit and credit card details and the CEO and CIO were forced to step down. The attack on the Sony PlayStation network was a result of a SQL injection attack—one of the most common web application attacks—and the network was down for 24 days. This exposed personal information of 77 million accounts. These personal details and financial records then end up in underground markets and are used for malicious activities. There have been many more attacks that have not reported in the news with much vigor. Web applications may not be the sole reason for such huge security breaches, but they have always played an assisting role that has helped the attacker to achieve their main goal of planting malware for exposing private data.
It's not only the web server or the website that is responsible for such attacks; the vulnerabilities in the client web browser are equally responsible. A fine example would be the Aurora attack that was aimed at a dozen of high-profile organizations, including Google, Adobe, Yahoo!, and a few others. The attackers exploited a zero-day heap spray vulnerability in Internet Explorer to gain access to corporate systems through end user devices; in this case, a vulnerability in the web browser was a contributing factor.
Another reason why web applications are so prone to attacks is because the typical IT security policies and investments are reactive and not proactive. Although we are moving ahead in the right direction, we are still far away from our goal. A disgruntled employee or a hacker would not read your network and access control policy before stealing data or think twice before kicking the server off the network, so creating documents would not really help. Application layer firewalls and IPS devices are not keeping up with the pace of evolving attacks. The embracing of BYOD by many companies has increased the attack surface for attackers and has also created additional problems for IT security teams. However, they are here to stay and we need to adapt.
Internet-facing websites have been a favorite of attackers and script kiddies. Over-the-counter developed websites and web solutions have mounted more problems. No or little investment in code reviews and a lack of understanding of the importance of encrypting data on a network and on a disk makes the job of your adversaries far easier.
If we take a look at the two of most common types of attack on web applications, that is, SQL injection and Cross-site scripting attack (XSS) (more on this in the coming chapters), both of these attacks are caused because the application did not handle the input from the user properly. You can test your applications in a more proactive way. During the testing phase, you can use different inputs that an attacker would use to exploit the input field in the web form and test it from a perspective of the attacker, rather than waiting for the attacker to exploit it and then remediate it. The network firewalls and proxy devices were never designed to block such intrusions; you need to test your applications just how the attacker would do it and this is exactly what we will be covering in the coming chapters.
Penetration testing or ethical hacking is a proactive way of testing your web applications by simulating an attack that's similar to a real attack that could occur on any given day. We will use the tools provided in Kali Linux to accomplish it. Kali Linux is a re-branded version of Backtrack and is now based on Debian-derived Linux distribution. It is used by security professionals to perform offensive security tasks and is maintained by a company known as Offensive Security Ltd. The predecessor of Kali Linux was Backtrack, which was one of the primary tools used by hackers for more than 6 years until 2013 when it was replaced by Kali Linux. In August 2015 the second version of Kali Linux was released with code name Kali Sana. This version includes new tools and comes with a rebranded GUI based on GNOME3. Kali Linux comes with a large set of popular hacking tools that are ready to use with all the prerequisites installed. We will dive deep into the tools and use them to test web applications which are vulnerable to major flaws found in real-world web applications.
A hacker is a person who loves to dig deep into a system out of curiosity in order to understand the internal working of that particular system and to find vulnerabilities in it. A hacker is often misunderstood as a person who uses the information acquired with malicious intent. A cracker is the one who intends to break into a system with malicious intent.
Hacking into a system that is owned by someone else should always be done after the consent of the owner. Many organizations have started to hire professional hackers who point out flaws in in their systems. Getting a written consent from the client before you start the engagement should always be at the top of your to-do list. Hacking is also a hotly debated topic in the media; a research paper detailing a vulnerability that you discovered and released without the consent of the owner of the product could drag you into a lot of legal trouble even if you had no malicious intent of using that information.
Crackers are often known as Black Hat hackers.
Hacking has played a major role in improving the security of the computers. Hackers have been involved in almost all the technologies, be it mobile phones, SCADA systems, robotics, or airplanes. For example, Windows XP (released in the year 2001) had far too many vulnerabilities and exploits were released on a daily basis; in contrast, Windows 8, that was released in the year 2012, was much more secure and had many mitigation features that could thwart any malicious attempt. This would have not been possible without the large community of hackers who regularly exposed security holes in the operating system and helped make it more secure. IT security is a journey. Although security of computer systems has improved drastically over the past few years, it needs constant attention as new features are added and new technologies are developed, and hackers play a major in it.
The Heartbleed, Shellshock, Poodle, GHOST, and Drupal vulnerabilities discovered over the past 12 months have again emphasized the importance of constantly testing your systems for vulnerabilities. These vulnerabilities also punch a hole in the argument that open source software are more secure since the source code is open; a proper investment of time, money, and qualified resources are the need of the hour.
Often people get confused with the following terms and use them interchangeably without understanding that although there are some aspects that overlap within these, there are also subtle differences that needs attention:
Ethical hacking
Penetration testing
Vulnerability assessment
Security audits
Very few people know that hacking is a misunderstood term; it means different things to different people and more often a hacker is thought of as a person sitting in a closed enclosure with no social life and with a malicious intent. Thus, the word ethical was prefixed to the term hacking. The term ethical hacking is used to refer to professionals who work to identify loopholes and vulnerabilities on systems, report it to the vendor or owner of the system, and also, at times, help them fix it. The tools and techniques used by an ethical hacker are similar to the ones used by a cracker or a Black Hat hacker, but the aim is different as it is used in a more professional way. Ethical hackers are also known as security researchers.
This is a term that we will use very often in this book and it is a subset of ethical hacking. Penetration testing is a more professional term used to describe what an ethical hacker does. If you are planning for a career in hacking, then you would often see job posting with the title penetration tester. Although penetration testing is a subset of ethical hacking, it differs in multiple ways. It's a more streamlined way of identifying vulnerabilities in the systems and finding if the vulnerability is exploitable or not. Penetration testing is bound by a contract between the tester and owner of the systems to be tested. You need to define the scope of the test to identify the systems to be tested. The rules of engagement need to be defined, which decide the way in which the testing is to be done.
At times organizations might want to only identify the vulnerabilities that exist in their systems without actually exploiting it and gaining access. Vulnerability assessments are broader than penetration tests. The end result of vulnerability assessment is a report prioritizing the vulnerabilities found, with the most severe ones on the top and the ones posing lesser risk lower in the report. This report is really helpful for clients who know that they have security issues but need to identify and prioritize the most critical ones.
Auditing is systematic procedure that is used to measure the state of a system against a predetermined set of standards. These standards could be industry best practices or an in-house checklist. The primary objective of an audit is to measure and report on conformance. If you are auditing a web server, some of the initial things to look out for are the ports open on the server, harmful HTTP methods such as TRACE enabled on the server, the encryption standard used, and the key length.
Rules of engagement (RoE) deals with the manner in which the penetration test is to be conducted. Some of the directives that should be clearly mentioned in the rules of engagement before you kick start the penetration test are as follows:
Black box testing or Gray box testing
Client contact details
Client IT team notifications
Sensitive data handling
Status meeting
There are do's and don'ts of both the ways of testing. With Black box testing, you get an exact view of an attacker as the penetration tester starts from scratch and tries to identify the network map, the types of firewalls you use, what are the internet facing website that you have, and so on. But you need to understand that at times this information might be easily obtained by the attacker. For example, to identify the firewall or the web server that you are using, a quick scan through the job postings on job portals by your company could reveal that information, so why waste your precious dollars in it? In order to get maximum value out of your penetration test, you need to choose your tests wisely.
Gray box testing is a more efficient use of your resources, where you provide the testing team sufficient information to start with so that less amount of time is spent on reconnaissance and scanning. The extent of information that you provide to the testing team depends on the aim of the test and threats vectors. You can start by providing the testing team only a URL or an IP address or a partial network diagram.
We all have to agree that although we take all the precautions when conducting the tests, at times it can go wrong because it involves making computers do nasty stuffs. Having the right contact information on the client-side really helps. A penetration test turning into a DoS attack is often seen and the technical team on the client side should be available 24/7 in case a computer goes down and a hard reset is needed to bring it back online.
Penetration tests are also used as a means to check the readiness of the support staff in responding to incidents and intrusion attempts. Discuss this with the client if it is an announced or unannounced test. If it's an announced test, make sure you have the time and date informed to the client in order to avoid any real intrusion attempts to be missed by their IT security team. If it's an unannounced test, discuss with the client on what happens if the test is blocked by an automated system or network administrator. Does the test end there, or do you continue testing? It all depends on the aim of the test, whether it's been conducted to test the security of the infrastructure or to check the response of the network security and incident handling team. Even if you are conducting an unannounced test, make sure someone in the escalation matrix knows about the time and day of the test.
Once the security of a target is breached and the penetration tester has complete access to the system, they should avoid viewing the data on the target. In a web application, if important user data is stored on a SQL database and if the server is vulnerable to a SQL injection attack, should the tester try to extract all the information using the attack? There might be sensitive client data on it. Sensitive data handling need special attention in the rules of engagement. If your client is covered under the various regulatory laws such as the Health Insurance Portability and Accountability Act (HIPAA), the Gramm-Leach-Bliley Act (GLBA), or the European Data privacy laws, only authorized personnel should be able to view personal user data.
Communication is key for a successful penetration test. Regular meetings should be scheduled between the testing team and personals from the client organization. The testing team should present how far have they reached and what vulnerabilities have been found until now. The client organization can also confirm whether their automated detection systems have triggered any alerts by the penetration attempt. If a web server is being tested and a web application firewall (WAF) was deployed, it should have logged and blocked any XSS attempts. As a good practice, the testing team should also document the time when the test was conducted, which will help the security team to correlate the logs with the penetration tests.
Although penetration tests are recommended and should be conducted on a regular basis, there are certain limitations to it. The quality of the test and its results will directly depend on the skills of the testing team. Penetration tests cannot find all the vulnerabilities due to limitation of scope, limitation on access of penetration testers to the testing environment, and limitations of tools used by the tester. Following are some of the limitations of a penetration test:
Limitation of skills: As mentioned earlier, the success and quality of the test will directly depend on the skills and experience of the penetration testing team. Penetration tests can be classified into three broad categories: network, system, and web application penetration testing. You would not get the right results if you make a person skilled on network penetration testing work on a project that involves testing a web application. With the huge number of technologies deployed today on the Internet, it is hard to find a person skillful in all three. A tester may have in-depth knowledge of Apache Web servers but might encounter an IIS server for the first time. Past experience also play a significant role in the success of the test; mapping a low risk vulnerability to a system that has a high level of threat is a skill that is only acquired with experience.
Limitation of time: Often, penetration testing is a short-term project that has to be completed in a predefined time period. The testing team is required to produce results and identity vulnerabilities within that period. Attackers on the other hand, have much more time to work on their attacks and can plan them carefully over a longer period. Penetration testers also have to produce a report at the end of the test, describing the methodology, vulnerabilities identified, and an executive summary. Screenshots have to be taken at regular intervals, which are then added to the report. An attacker would not be writing any reports and can therefore dedicate more time to the actual attack.
Limitation of custom exploits: In some highly secure environments, normal pentesting frameworks and tools are of little use and it requires the team to think out of the box, such as creating a custom exploit and manually writing scripts to reach the target. Creating exploits is extremely time consuming and is also not part of the skillset of most penetration testers. Writing custom exploit code would affect the overall budget and time of the test.
Avoiding DoS attack: Hacking and penetration testing is an art of making a computer do things that it was not designed to do, so at times a test may lead to a DoS attack rather than gaining access to the system. Many testers do not run such tests in order to avoid inadvertently causing downtime of the system. Since systems are not tested for the DoS attacks, they are more prone to attacks by scripts kiddies who are out there waiting for such Internet-accessible systems to claim fame by taking them offline. Script kiddies are unskilled individual who exploit easy to find and well-known weaknesses in computer systems to gain fame without understanding the potential harmful consequences. Educating the client about the pros and cons of a DoS attack should be done which will help them to take the right decision.
Limitation of access: Networks are divided into different segments and the testing team would often have access and rights to test only those segments that have servers and are accessible from the internet to simulate a real world attack. However, such a test won't detect configuration issues and vulnerabilities on the internal network where the clients are located.
Limitations of tools used: At times, the penetration testing team is only allowed to use a client approved list of tools and exploitation frameworks. No tool is complete, be it the free version or the commercial ones. The testing team needs to have the knowledge of those tools and will have to find alternatives to the features missing from it.
In order to overcome these limitations, large organizations have a dedicated penetration testing team that researches new vulnerabilities and performs tests regularly. Other organizations perform regular configuration reviews in addition to penetration tests.
Career as a penetration tester is not a sprint, it is a marathon.
With the large number of Internet-facing websites and the increase in the number of organizations doing business online, web applications and web servers make an attractive option for attackers. Web applications are everywhere across public and private networks, so attackers don't need to worry about lack of targets. It requires only a web browser to interact with a web application. Some of the flaws in web applications, such as logic flaws, can be exploited even by a layman. For example, if you have an e-commerce website that allows the user to add items into the e-cart after the checkout process due to bad implementation of logic and a malicious user finds this out through trial and error, then they would be able to exploit this easily without the need of any special tools.
Comparing it to the skills required to attack OS-based vulnerabilities, such as buffer overflows, defeating ASLR, and other mitigation techniques, hacking web applications is easy to start with. Over the years, web applications have been storing critical data such as personal information and financial records. The goal of more sophisticated attacks, known as APT, is to gain access to such critical data that is now available on an Internet-facing website.
Note
Advance persistent threats or APTs are stealth attacks where your adversary remains hidden in your network for a long period with the intention of stealing as much data as possible. The attacker exploits vulnerabilities in your network and deploys malware that communicates with an external command and control system sending across data.
Vulnerabilities in web applications also provide a means for spreading malware and viruses, and it could spread across the globe in matter of minutes. Cyber criminals make considerable financial gains by exploiting web applications and installing malware, the most recent one known as the Zeus malware.
Firewalls at the edge are more permissive for inbound HTTP traffic towards the web server, so the attacker does not require any special ports to be open. The HTTP protocol, which was designed many years ago, does not provide any inbuilt security features; it's a clear text protocol and would require an additional layering using the HTTPS protocol in order to secure communication. It also does not provide individual session identification and leaves it to the developer to design it. Many developers are hired directly from college, and they have only theoretical knowledge of programming languages and no prior experience with the security aspects of web application programming. Even when the vulnerability is reported to the developers, they take a long time to fix it as they are busier with the feature creation and enhancement part of the web application.
Note
Secure coding starts with the architecture and designing part of the web applications, so it needs to be integrated early into the development phase. Integrating it later proves to be difficult and requires a lot of rework. Identifying risk and threats early in the development phase using threat modeling would really help in minimizing vulnerabilities in production ready code of the web application.
Investing resources in writing secure code is an effective method for minimizing web application vulnerabilities, but writing secure code is easier to say but difficult to implement.
Some of the most compelling reasons to guard against attacks on web application are as follows:
Protecting customer data
Compliance with law and regulation
Loss of reputation
Revenue loss
Protection against business disruption.
If the web application interacts and stores credit card information, then it needs to in compliance with the rules and regulations laid out by Payment Card Industry (PCI). PCI has specific guidelines, such as reviewing all code for vulnerabilities in the web application or installing a web application firewall in order to mitigate the risk.
When the web application is not tested for vulnerabilities and an attacker gains access to customer data, it can severely affect the brand value of the company if a customer files a case against the company for not doing enough to protect their data. It may also lead to revenue losses, since many customers will move to your competitors who would assure better security.
Attacks on web applications may also result in severe disruption of service if it's a DoS attack or if the server is taken offline to clean up the exposed data or for forensics investigation. This might reflect in the financial losses.
These reasons should be enough to convince the senior management of your organization to invest resources in terms of money, manpower, and skills to improve the security of your web applications.
The efforts that you put in to securing your computer devices using network firewalls, IPS, and web application firewalls are of little use if your employees easily fall prey to a social engineering attack. Security in computer systems is as strong as the weakest link and it only takes one successful social engineering attack on employees to bring an entire business down. Social engineering attacks can be accomplished using various means such as:
E-mail spoofing: Employees need to be educated to differentiate between legitimate e-mails and spoofed e-mails. Before clicking on any external links on e-mails, the links should be verified. Links in the e-mail have been favorite method to execute a cross-site scripting attack. When you click on the Reply button, the e-mail address in the To field should be the one that the mail came from and should be from a domain that looks exactly the same as the one that you were expecting the mail from. For example,
xyz@microsoft.comandxyz@micro-soft.comare entirely different e-mail accounts.Telephone attacks: Never reveal any personal details on telephone. Credit card companies and banks regularly advice their customers the same and emphasize that none of their employees have been authorized to collect personal information such as username and password from customers.
Dumpster diving: Looking for information in the form of documents or flash drives left by users is known as dumpster diving. A logical design document that a user failed to collect from the printer, which contains detailed design of a web application, including the database server, IP addresses, and firewall rules, would be of great use to an attacker. The attacker now has access to the entire architecture of the web application and would be able to directly move to the exploitation phase of the attack. Clean desk policy should be implemented organization wide.
Malicious USB drives: Unclaimed USB drives left at a desk can increase the curiosity of the user who would waste no time in checking out the contents of the USB drive by plugging it into his computer. A USB drive sent as a gift would also trick the user. These USB drives can be loaded with malicious backdoors that connect back to the attackers machine.
Employees at every level in the organization, from a help desk representative to the CEO of the company, are prone to social engineering attacks. Each employee should be held accountable to maintain the integrity of the information that they are responsible for.
An attack on a big fish in an organization such as a CEO, CFO, or CISO is known as whaling. A successful attack on people holding these positions bring in great value, as they have access to the most sensitive data in the organization.
Regular training and employee awareness programs are the most efficient way to thwart social engineering attacks. Employees at every level need a separate level of training, which would depend on what data they deal with and the type of interaction they have with the end clients. IT helpdesk personnel who have direct interaction with end users need specific training on ways to respond to queries on the telephone. Marketing and sales representatives, who interact with people outside the organization, receive a large number of e-mails daily, and spend a good amount of time on the Internet, need special instructions and guidelines to avoid falling in the trap of spoofed e-mails. Employees should also be advised against sharing corporate information on social networks and only those approved by the senior management should do it. Using official e-mail addresses when creating accounts on online forums should be strongly discouraged, as it becomes one of the biggest sources of spam e-mails.
If you are not a programmer who is actively involved in the development of web applications, then chances of you knowing the inner workings of the HTTP protocol, the different ways web applications interact with the database, and what exactly happens when a user clicks a links or types in the URL of a website in the web browser are very low.
If you have no prior programming skills and you are not actively involved in the development of web application, you won't be able to effectively perform the penetration test. Some initial knowledge of web applications and HTTP protocol is needed.
As a penetration tester, understanding how the information flows from the client to the server and back to the client is very important. For example, a technician who comes to your house to repair your television needs to have an understanding of the inner working of the television set before touching any part of it. This section will include enough information that would help a penetration tester who has no prior knowledge of web application penetration testing to make use of tools provided in Kali Linux and conduct an end-to-end web penetration test. We will get a broad overview of the following:
HTTP protocol
Headers in HTTP
Session tracking using cookies
HTML
Architecture of web applications
The underlying protocol that carries web application traffic between the web server and the client is known as the hypertext transport protocol. HTTP/1.1 the most common implementation of the protocol is defined in the RFCs 7230-7237, which replaced the older version defined in RFC 2616. The latest version, known as HTTP/2, was published in May 2015 and defined in RFC 7540. The first release, HTTP/1.0, is now considered obsolete and is not recommended. As the Internet evolved, new features were added in the subsequent release of the HTTP protocol. In HTTP/1.1, features such as persistent connections, OPTION method, and several improvements in way HTTP supported caching were added.
HTTP is basically a client-server protocol, wherein the client (web browser) makes a request to the server and in return the server responds to the request. The response by the server is mostly in the form of HTML formatted pages. HTTP protocol by default uses port 80, but the web server and the client can be configured to use a different port.
The HTTP request made by the client and the HTTP response sent by the server have some overhead data that provides administrative information to the client and the server. The header data is followed by the actual data that is shared between the two endpoints. The header contains some critical information which an attacker can use against the web application. There are several different ways to capture the header. A web application proxy is the most common way to capture and analyze the header. A detailed section on configuring the proxy to capture the communication between the server and client is included in Chapter 2, Setting up Your Lab with Kali Linux. In this section, we will discuss the various header fields.
Another way to capture the header is using the Live HTTP Headers add-on in the Chrome browser, which can be downloaded from https://chrome.google.com/webstore/detail/live-http-headers/iaiioopjkcekapmldfgbebdclcnpgnlo?hl=en. The add-on will display all the headers in real time as you surf the website.
The following screenshot is captured using a web application proxy. As shown here, the request is from a client using the GET method to the www.bing.com website. The first line identifies the method used. In this example, we are using the GET method to access the root of the website denoted by "/". The HTTP version used is HTTP/1.1:
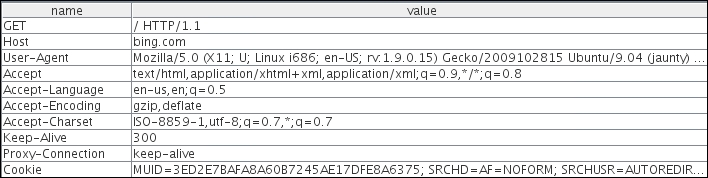
There are several fields in the header, but we will discuss the more important ones:
Host: This field is in the header and it is used to identify individual website by a hostname if they are sharing the same IP address. The client web browser also sets a user-agent string to identify the type and version of the browser.
User-Agent: This field is set correctly to its default values by the web browser, but it can be spoofed by the end user. This is usually done by malicious user to retrieve contents designed for other types of web browsers.
Cookie: This field stores a temporary value shared between the client and server for session management.
Referer: This is another important field that you would often see when you are redirected from one URL to another. This field contains the address of the previous web page from which a link to the current page was followed. Attackers manipulate the Referer field using an XSS attack and redirect the user to a malicious website.
Accept-Encoding: This field defines the compression scheme supported by the client; gzip and Deflate are the most common ones. There are other parameters too, but they are of little use to penetration testers.
The following screenshot displays the response header sent back by the server to the client:

The first field of the response header is the status code, which is a 3-digit code. This helps the browser to understand the status of operation. Following are the details of few important fields:
Status code: There is no field named as status code but the value is passed in the header. The status codes starting with 200 are used to communicate a successful operation back to the web browser. The 3xx series is used to indicate redirection when a server wants the client to connect to another URL when a web page is moved. The 4xx series is used to indicate an error in the client request and the user will have to modify the request before resending. The 5xx series indicate an error on the server side as, the server was unable to complete the operation. In the preceding image the status code is 200 which means the operation was successful. A full list of HTTP status codes can be found at https://developer.mozilla.org/en-US/docs/Web/HTTP/Response_codes.
Set-Cookie: This field, if defined, will contain a random value that can be used by the server to identify the client and store temporary data.
Server: This field is of interest to a penetration tester and will help in the recon phase of a test. It displays useful information about the web server hosting the website. As shown here, www.bing.com is hosted by Microsoft on IIS version 8.5. The content of the web page follows the response header in the body.
Content-Length: This field will contain a value indicating the number of bytes in the body of the response. It is used so that the other party can know when the current request/response has finished.
The exhaustive list of all the header fields and their usage can be found at the following URL:
http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
For a hacker, the more data in the header the more interesting is the packet.
When a client sends a request to the server, it should also inform the server what action is to be performed on the desired resource. For example, if a user wants to only view the contents of a web page, it will invoke the GET method that informs the servers to send the contents on the web page to the client web browser.
Several methods are described in this section and they are of interest to a penetration tester as they indicate what type of data exchange is happening between the two end points.
The GET method passes the parameters to the web application via the URL itself. It takes all the input in the form and appends them to the URL. This method has some limitations; you can only pass 255 characters in the URL via GET and if it is exceeding the count, most servers will truncate the character outside the limit without a warning or will return an HTTP 414 error. Another major drawback of using a GET method is that the input becomes a part of the URL and prone to sniffing. If you type in your username and password and these values are passed to the server via the GET method, anybody on the web server can retrieve the username and password from the Apache or IIS log files. If you bookmark the URL, the values passed also get stored along with the URL in clear text. As shown in the following screenshot, when you send a search query for Kali Linux in the Bing search engine, it is sent via the URL. The GET method was initially used only to retrieve data from the server (hence the name GET), but many developers use it send data to the server:

The POST method is similar to the GET method and is used to retrieve data from the server but it passes the content via the body of the request. Since the data is now passed in the body of the request, it becomes more difficult for an attacker to detect and attack the underlying operation. As shown in the following POST request, the username and password is not sent in the URL but in the body, which is separated from the header by a blank line:

The
HEAD method is used by attackers to identify the type of server as the server only responds with the HTTP header without sending any payload. It's a quick way to find out the server version and the date.
When a TRACE method is used, the receiving server bounces back the TRACE response with the original request message in the body of the response. The TRACE method is used to identify any alterations to the request by intermediary devices such as proxy servers and firewalls. Some proxy servers edit the HTTP header when the packets pass though it and this can be identified using the TRACE method. It is used for testing purposes, as you can now track what has been received by the other side. Microsoft IIS server has a TRACK method which is same as the TRACE method. A more advance attack known as
cross-site tracing (XST) attack makes use of
cross-site scripting (XSS) and the TRACE method to steal user's cookies.
The
PUT and DELETE methods are part of WebDAV, which is an extension to HTTP protocol and allows management of documents and files on the web server. It is used by developers to upload production-ready web pages on to the web server. PUT is used to upload data to the server whereas DELETE is used to remove it.
It is used to query the server for the methods that it supports. An easy way to check the methods supported by the server is by using the Netcat (nc) utility that is built into all Linux distributions. Here, we are connecting to ebay.com on port 80 and then using the OPTIONS method to query the server for the supported methods. As shown in the following screenshot, we are sending the request to the server using HTTP/1.1. The response identifies the methods the server supports along with some additional information:

Understanding the layout in the HTTP packet is really important, as it contains useful information and several of those fields can be controlled from the user-end, giving the attacker a chance to inject malicious data.
HTTP is a stateless client-server protocol, where a client makes a request and the server responds with the data. The next request that comes is an entirely new request, unrelated to the previous request. The design of HTTP requests is such that they are all independent of each other. When you add an item in your shopping cart while doing online shopping, the application needs a mechanism to tie the items to your account. Each application may us a different way to identify each session.
The most widely used technique to track sessions is through a session ID set by the server. As soon as a user authenticates with a valid username and password a unique random session ID is assigned to that user. On every request sent by the client, it should include the unique session ID that would tie the request to the authenticated user. The ID could be shared using the GET method or the POST method. When using the GET method, the session ID would become a part of the URL; when using the POST method, the ID is shared in the body of the HTTP message. The server would maintain a table mapping usernames to the assigned session ID. The biggest advantage of assigning a session ID is that even though HTTP is stateless, the user is not required to authenticate every request; the browser would present the session ID and the server would accept it.
Session ID has a drawback too; anyone who gains access to the session ID could impersonate the user without requiring a username and password. Also, the strength of the session ID depends on the degree of randomness used to generate it, which would help defeat brute force attacks.
Cookie is the actual mechanism using which the session ID is passed back and forth between the client and the web server. When using cookies, the server assigns the client a unique ID by setting the Set-Cookie field in the HTTP response header. When the client receives the header, it will store the value of the cookie, that is, the session ID within the browser and associates it to the website URL that sent it. When a user revisits the original website, the browser will send the cookie value across identifying the user.
Besides saving critical authentication information, cookie can also be used to set preference information for the end client such as language. The cookie storing the language preference for the user is then used by the server to display the web page in the user preferred language.
As shown in the following figure, the cookie is always set and controlled by the server. The web browser is only responsible for sending it across to the server with every request. In the following image, we can see that a GET request is made to the server, and the web application on the server chooses to set some cookies to identify the user and the language selected by the user in previous requests. In subsequent requests made by the client, the cookie becomes the part of the request:

Cookies are divided into two main categories. Persistent cookies are the ones that are stored on the hard drive as text files. Since the cookie is stored on the hard drive it would survive a browser crash. A cookie, as mentioned previously, can be used to pass the sensitive authorization information in the form of session ID. If it's stored on the hard drive, you cannot protect it from modification by a malicious user. You can find the cookies stored on the hard drive when using Internet Explorer at the following location in Windows 7. The folder will contain many small text files that store the cookies:
C:\Users\username\AppData\Roaming\Microsoft\Windows\Cookies
Chrome does not store cookies in text files like Internet Explorer. It stores them in a single SQLlite3 database. The path to that file is C:\Users\Juned\AppData\Local\Google\Chrome\User Data\Default\cookies
The cookies stored in the Chrome browser can be viewed by typing in chrome://settings/cookies in the browser.
To solve the security issues faced by persistent cookies, programmers came up with another kind of cookie that is more often used today known as non-persistent cookie, which is stored in the memory of the web browser, leaves no traces on the hard drive, and is passed between the web browser and server via the request and response header. A non-persistent cookie is only valid for a predefined time which is appended to the cookie as shown in the screenshot given in the following section.
In addition to name and the value of the cookie, there are several other parameters set by the web server that defines the reach and availability of the cookie as shown in the following screenshot:

Following are the details of some of the parameters:
Domain: This specifies the domain to which the cookie would be sent.
Path: To further lock down the cookie, the
Pathparameter can be specified. If the domain specified isemail.comand the path is set to/mail, the cookie would only be sent to the pages insideemail.com/mail.HttpOnly: This is a parameter that is set to mitigate the risk posed by cross-site scripting attacks, as JavaScript won't be able to access the cookie.
Secure: If this is set, the cookie is only sent over SSL.
Expires: The cookie will be stored until the time specified in this parameter.
Now that the header information has been shared between the client and the server, both the parties agree on it and move on to the transfer of actual data. The data in the body of the response is the information that is of use to the end user. It contains HTML formatted data. Information on the web was originally only plain text. This text-based data needs to be formatted so that it can be interpreted by the web browser in the correct way. HTML is similar to a word processor, wherein you can write out text and then format it with different fonts, sizes, and colors. As the name suggests, it's a markup language. Data is formatted using tags. It's only used for formatting data so that it could be displayed correctly in different browsers.
HTML is not a programming language.
If you need to make your web page interactive and perform some functions on the server, pull information from a database, and then display the results to the client, you will have to use a server side programming languages such as PHP, ASP.Net, and JSP, which produces an output that can then be formatted using HTML. When you see a URL ending with a .php extension, it indicates that the page may contain PHP code and it must run through the server's PHP engine which allows dynamic content to be generated when the web page is loaded.
HTML and HTTP are not the same thing: HTTP is the communication mechanism used to transfer HTML formatted pages.
As more complex web applications are being used today, the traditional way of deploying web application on a single system is a story of the past. All eggs in one basket is not a clever way to deploy a business-critical application, as it severely affects the performance, security, and availability of the application. The simple design of a single server hosting the application as well as data works well only for small web applications with not much traffic. The three-tier way of designing the application is the way forward.
In a three-tier web application, there is a physical separation between the presentation, application, and data layer described as follows:
Presentation layer: This is the server where the client connections hit and the exit point through which the response is sent back to the client. It is the frontend of the application. The presentation layer is critical to the web application, as it is the interface between the user and rest of the application. The data received at the presentation layer is passed to the components in the application layer for processing. The output received is formatted using HTML and displayed on the web client of the user. Apache and Nginx are open source software and Microsoft IIS is commercial software that is deployed in the presentation layer.
Application layer: The processor-intensive processing is taken care of in the application layer. Once the presentation layer collects the required data from the client and passes it to the application layer, the components working at this layer can apply business logic to the data. The output is then returned to the presentation layer to be sent back to the client. If the client requests some data, it is extracted from the data layer, processed into a form that can be of use to client, and passed to the presentation layer. PHP and ASP are programming languages that work at the application layer.
Data access layer: The actual storage and the data repository works at the data access layer. When a client requires data or sends data for storage, it is passed down by the application layer to the data access layer for persistent storage. The components working at this layer are responsible for the access control of the data. They are also responsible for managing concurrent connection from the application layer. MySQL and Microsoft SQL are two technologies that work at this layer. When you create a website that reads and writes data to a database it uses the structured query language (SQL) statements that query the database for the required information. SQL is a programming language that many database products support as a standard to retrieve and update data from it.
Following is a diagram showing the working of presentation, application, and the data access layers working together:

This chapter is an introduction to hacking and penetration testing of web application. We started by identifying different ways of testing the web applications. The important rules of engagements that are to be defined before starting a test were also discussed. The importance of testing web applications in today's world and the risk faced by not doing regular testing were also mentioned.
HTTP plays a major role in web application and a thorough understanding of the protocol is important to conduct a successful penetration test. We reviewed the basic building blocks of a web application and how different components interact with each other. Penetration testers can map input and exit points if they understand the different layers in the web application.


