



















 Download code from GitHub
Download code from GitHub
Chapter 1: Introduction to Performance and Concurrency
Motivation is a key ingredient of learning; thus, you must understand why, with all the advances in computing, a programmer still has to struggle to get adequate performance from their code and why success requires a deep understanding of computing hardware, programming language, and compiler capabilities. The aim of this chapter is to explain why this understanding is still necessary today.
This chapter talks about the reasons we care about the performance of programs, specifically about the reasons good performance doesn't just happen. We will learn why, in order to achieve the best performance, or sometimes even adequate performance, it is important to understand the different factors affecting performance, and the reasons for a particular behavior of the program, whether it is fast execution or slow.
In this chapter, we're going to cover the following main topics:
- Why performance matters
- Why performance requires the programmer's attention
- What do we mean by performance?
- How to evaluate the performance
- Learning about high performance
Why focus on performance?
In the early days of computing, programming was hard. The processors were slow, the memory was limited, the compilers were primitive, and nothing could be achieved without a major effort. The programmer had to know the architecture of the CPU, the layout of the memory, and when the compiler did not cut it, the critical code had to be written in assembler.
Then things got better. The processors were getting faster every year, the number that used to be the capacity of a huge hard drive became the size of the main memory in an average PC, and the compiler writers learned a few tricks to make programs faster. The programmers could spend more time actually solving problems. This was reflected in the programming languages and design styles: between the higher-level languages and evolving design and programming practices, the programmers' focus shifted from what they wanted to say in code to how they wanted to say it.
Formerly common knowledge, such as exactly how many registers the CPU has and what their names are, became esoteric, arcane matter. A "large code base" used to be one that needed both hands to lift the card deck; now, it was one that taxed the capacity of the version control system. There was hardly ever a need to write code specialized for a particular processor or a memory system, and portable code became the norm.
As for assembler, it was actually difficult to outperform the compiler-generated code, a task well out of reach for most programmers. For many applications, and those writing them, there was "enough performance," and other aspects of the programmers' trade became more important (to be clear, the fact that the programmers could focus on the readability of their code without worrying whether adding a function with a meaningful name would make the program unacceptably slow was a good thing).
Then, and rather suddenly, the free lunch of "performance taking care of itself" was over. The seemingly unstoppable progress of the ever-growing computing power just … stopped.
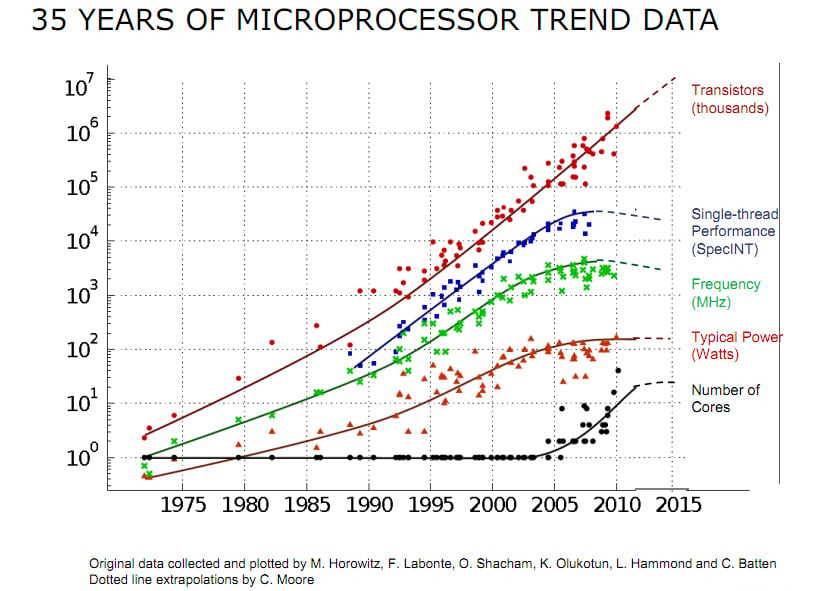
Figure 1.1 – Charting 35 years of microprocessor evolution (Refer to https://github.com/karlrupp/microprocessor-trend-data and https://github.com/karlrupp/microprocessor-trend-data/blob/master/LICENSE.txt)
Around the year 2005, the computing power of a single CPU reached saturation. To a large extent, this was directly related to the CPU frequency, which also stopped growing. The frequency, in turn, was limited by several factors, one of which was power consumption (if the frequency trend continued unchanged, today's CPUs would pack more power per square millimeter than the great jet engines that lift rockets into space).
It is evident from the preceding figure that not every measure of progress stalled in 2005: the number of transistors packed into a single chip kept growing. So, what were they doing if not making chips faster? The answer is two-fold, and part of it is revealed by the bottom curve: instead of making the single processor larger, the designers had to settle for putting several processor cores on the same die. The computing power of all these cores together, of course, increased with the number of cores, but only if the programmer knew how to use them. The second part of the "great transistor mystery" (where do all the transistors go?) is that they went into various very advanced enhancements to the processor capabilities, enhancements that can be used to improve performance, but again, only if the programmer makes an effort to use them.
The change in the progress of processors that we have just seen is often held as the reason that concurrent programming has entered the mainstream. But the change was even more profound than that. You will learn throughout this book how, in order to obtain the best performance, the programmer once again needs to understand the intricacies of the processor and memory architecture and their interactions. Great performance doesn't "just happen" anymore. At the same time, the progress we have made in writing code that clearly expresses what needs to be done, rather than how it's done, is not to be rolled back. We still want to write readable and maintainable code, and (and not but) we want it to be efficient as well.
To be sure, for many applications there is still enough performance in modern CPUs, but performance is getting more attention than it used to, in large part because of the change in CPU development we just discussed and because we want to do more computing in more applications that do not necessarily have access to the best computing resources (for example, a portable medical device today may have a full neural network in it).
Fortunately, we do not have to rediscover some lost art of performance by digging through piles of decaying punch cards in a dark storage room. At any time, there were still hard problems, and the phrase there is never enough computing power was true for many programmers. As computing power grew exponentially, so did the demands on it. The art of extreme performance was kept alive in those few domains that needed it. An example of one such domain may be instructive and inspiring at this point.
Why performance matters
To find such an example of an area where the focus on performance never really waned, let us examine the evolution of the computing that goes into making computing itself possible, which is the electronic design automation (EDA) tools that are used to design computers themselves.
If we took the computations that went into designing, simulating, or verifying a particular microchip in 2010 and ran the same workload every year since, we would see something like this:
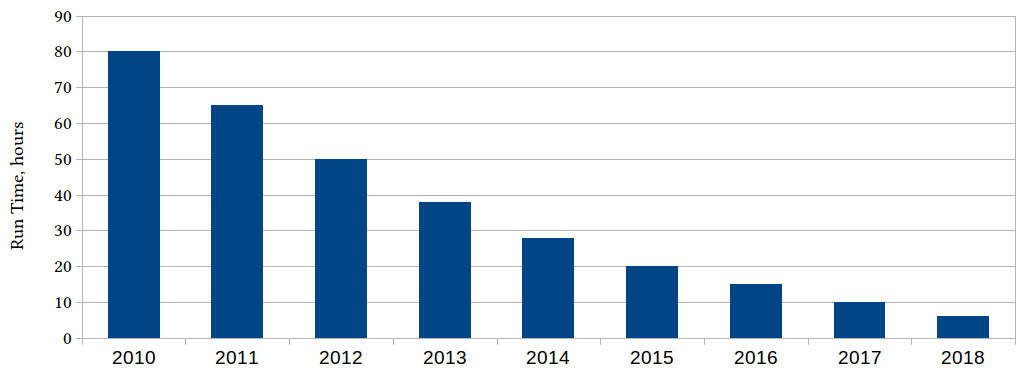
Figure 1.2 – Processing time, in hours, for a particular EDA computation, over the years
What took 80 hours to compute in 2010 took less than 10 hours in 2018 (and even less today). Where does the improvement come from? Several sources at once: in part, computers become faster, but also software becomes more efficient, better algorithms are invented, the optimizing compilers become more effective.
Unfortunately, we are not building 2010 version microchips in 2021: it stands to reason that as computers become more powerful, building newer and better ones becomes harder. The more interesting question, then, is how long does it take to do the same work every year for the new microchip we're building that year:
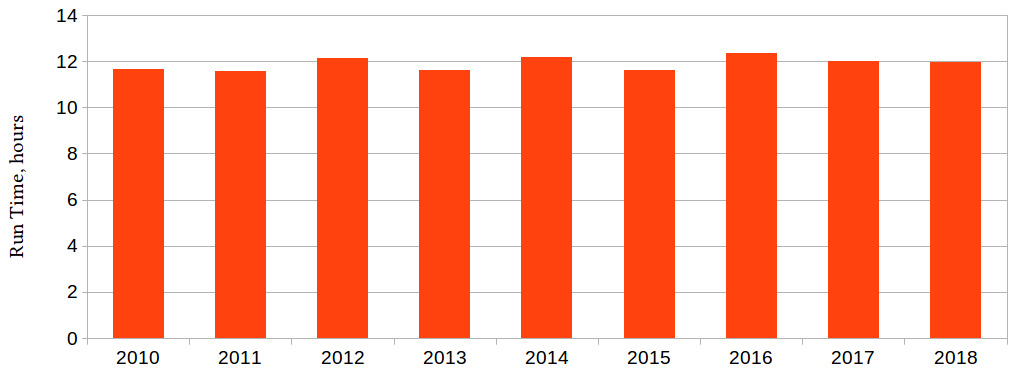
Figure 1.3 – Run time, in hours, for a particular design step for the latest microchip every year
The actual computations done each year are not the same, but they serve the same purpose, for example, verify that the chip performs as intended, for the latest and greatest chip we built every year. We can see from this chart that the most powerful processors of the current generation, running the best tools available, take roughly the same time to design and model the processor of the next generation every year. We are holding our own, but we are not making any headway.
But the truth is even worse than that, and the chart above does not show everything. It is true that from 2010 to 2018, the largest processor to be made that year could be verified overnight (some 12 hours) using the computer equipped with the largest processors made last year. But we forgot to ask how many of these processors? Well, here is the full truth now:
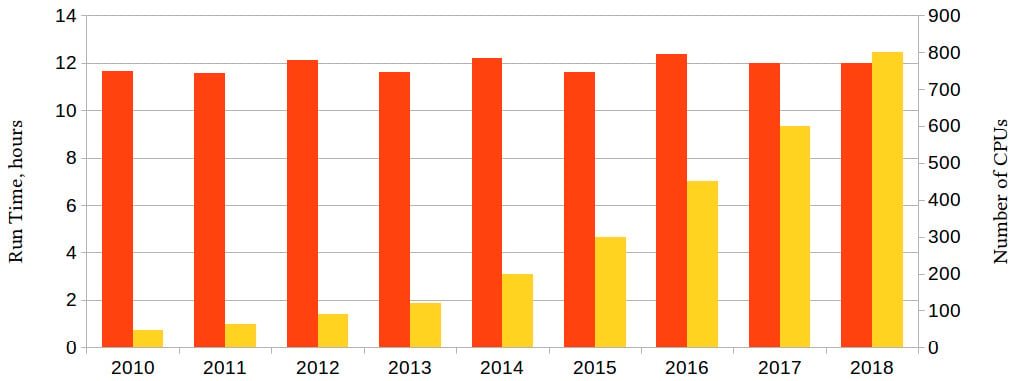
Figure 1.4 – The preceding figure, annotated with the CPU count for each computation
Every year, the most powerful computers, equipped with the ever-growing number of the latest, most powerful processors, running the latest software versions (optimized to leverage increasingly more processors and to use each one more efficiently), do the work needed to build the next year's most powerful computers, and every year, this task is balanced on the edge of what is barely possible. That we do not fall off this edge is largely the achievement of the hardware and the software engineers, as the former supply the growing compute power, and the latter use it with maximum efficiency. This book will help you to learn the skills for the latter.
We now understand the importance of the subject of the book. Before we can delve into the details, it would help to do a high-level overview; a review of the map of the territory where the exploration campaign will unfold, so to speak.
What is performance?
We have talked about the performance of programs; we mentioned high-performance software. But what do we mean when we say that? Intuitively, we understand that a high-performance program is faster than a program with poor performance, but it doesn't mean that a faster program always has good performance (both programs may have poor performance).
We have also mentioned efficient programs, but is efficiency the same as high performance? While efficiency is related to performance, it is not exactly the same. Efficiency deals with using resources optimally and not wasting them. An efficient program makes good use of the computational hardware.
On the one hand, an efficient program does not leave available resources idle: if you have a computation that needs to be done and a processor that is not doing anything, that processor should be executing the code that is waiting to be executed. The idea goes deeper: processors have many computing resources in them, and an efficient program tries to make use of as many of these resources as possible at the same time. On the other hand, an efficient program does not waste resources doing unnecessary work: it does not perform computations that do not need to be done, does not waste memory to store data that is never going to be used, does not send data over the network if it's not needed, and so on. In short, an efficient program does not leave the available hardware idle and does not do any work that doesn't have to be done.
Performance, on the other hand, always relates to some metrics. The most common one is "speed," or how fast the program is. The more rigorous way to define this metric is the throughput, which is the amount of computations the program does in a given time. The inverse metric that is often used for the same purpose is the turnaround time or how much time is needed to compute a particular result. However, this is not the only possible definition of performance.
Performance as throughput
Let's consider four programs that use different implementations to compute the same end result. Here are the run times of all four programs (units are relative; the actual numbers don't matter as we're interested in relative performance):

Figure 1.5 – Run times of four different implementations of the same algorithm (relative units)
It seems obvious that Program B has the highest performance: it finished before the other three programs, in half the time it took the slowest program to compute the same result. In many situations, this would be all the data we need to choose the best implementation.
But the context of the problem matters, and we neglected to mention that the program is running on a battery-powered device, such as a cell phone, and the power consumption matters as well.
Performance as power consumption
Here is the power consumed by all four programs during the course of the computation:

Figure 1.6 – Power consumption of four different implementations of the same algorithm (relative units)
Despite taking longer to get the result, Program C used less power overall. So, which program has the best performance?
Again, this is a trick question without knowing the full context. The program not only runs on a mobile device but performs a real-time computation: it is used in audio processing. This should put a premium on getting the results back faster in real time, right? Not exactly.
Performance for real-time applications
A real-time program must keep up with the events it is processing at all times. An audio processor must keep up with speech, in particular. If the program can process audio ten times faster than a person can speak, it does us no good, and we may as well turn our attention to power consumption.
On the other hand, if the program occasionally falls behind, some sounds or even words will be dropped. This suggests that the real time, or speed, matters up to a point, but it must be delivered in a predictable manner.
There is, of course, a performance metric for that as well: the latency tail. The latency is the delay, in our case, between the time the data is ready (voice recorded) and the time when the processing is completed. The throughput metric we saw earlier reflects the average time to process the sound: if we speak for one hour into the phone, how long will it take for the audio processor to do all the computations it needs to do? But what really matters in this context is that each little computation for every sound is done on time.
At a low level, the computation speed fluctuates: sometimes, the computation finishes faster, and sometimes it takes longer. As long as the average speed is acceptable, what matters are the rare long delays.
The latency tail metric is computed as a particular percentile of the delay, for example, at the 95th percentile: if t is the 95th percentile latency, then 95% of all computations take less time than t. The metric itself is the ratio of the 95th percentile time t to the average compute time t0 (it is often expressed as a percentage as well, so a 30% latency at the 95th percentile means that t is 30% greater than t0):

Figure 1.7 – 95% latency of four different implementations of the same algorithm (percents)
We now see that Program B, which computes the results faster than any other implementation, on average, also delivers the most unpredictable run time results, while Program D, which never stood out before, computes like clockwork and takes practically the same time to do a given computation, every time. As we have already observed, program D also has the worst power consumption. This is, unfortunately, not uncommon because the techniques that make the program more power-efficient, on average, are probabilistic in nature: they speed up the computations most of the time, but not every time.
So, which program is the best? The answer, of course, depends on the application and even then may be non-obvious.
Performance as dependent on context
If this was simulation software that runs in a large data center and takes days to compute, the throughput would be the king. On a battery-powered device, power consumption is usually the most important. In a more complex environment, such as our real-time audio processor, it is the combination of multiple factors. The average run time matters, of course, but only until it becomes "fast enough." If the speaker cannot notice the delays, then making it even faster has no reward. Latency tail matters: users hate it when a word is dropped from the conversation every now and then. Once the latency is good enough that the call quality is limited by other factors, improving it further gives very little benefit; we would be better off conserving power at this point.
We now understand that, unlike efficiency, performance is always defined with respect to specific metrics, that these metrics depend on the application and the problem we're solving, and that for some metrics, there is such a thing as "good enough" when other metrics come to the foreground. The efficiency, which reflects the utilization of the computational resources, is one of the ways to achieve good performance, the most common way, perhaps, but not the only one.
Evaluating, estimating, and predicting performance
As we have just seen, the notion of metrics is fundamental to the concept of performance. With metrics, there is always the implied possibility and necessity of measurements: if we say "we have a metric," it implies that we have a way of quantifying and measuring something, and the only way to find out the value of the metric is to measure it.
The importance of measuring performance cannot be overstated. It is often said that the first law of performance is never to guess about performance. The very next chapter in this book is dedicated to performance measurements, measurement tools, how to use them, and how to interpret the results.
Guessing about performance is, unfortunately, all too widespread. So are overly general statements like "avoid using virtual functions in C++, they are slow." The problem with such statements is not that they are imprecise, that is, they do not reference a metric of how much slower a virtual function is, compared to a non-virtual one. As an exercise for the reader, here are several answers to choose from, all quantified:
- A virtual function is 100% slower
- A virtual function is about 15-20% slower
- A virtual function is negligibly slower
- A virtual function is 10-20% faster
- A virtual function is 100 times slower
Which is the right answer? If you selected any one of these answers, congratulations: you have chosen the correct answer. That is right, each of these answers is correct under certain circumstances and within a specific context (to learn why, you will have to wait until Chapter 9, High-Performance C++).
Unfortunately, by accepting the truth that it is almost impossible to intuit or guess about performance, we risk falling into another trap: using it as an excuse to write inefficient code "to be optimized later" because we don't guess about performance. While true, the latter maxim can be taken too far, just like the popular dictum do not optimize prematurely.
Performance cannot be added to the program later, so it should not be an afterthought during the initial design and development. Performance considerations and targets have their place at the design stage, just like other design goals. There is a definite tension between these early performance-related goals and the rule to never guess about performance. We have to find the right compromise, and a good way to describe what we really want to accomplish at the design stage with regard to performance is this: while it's almost impossible to predict the best optimizations in advance, it is possible to identify design decisions that would make subsequent optimizations very hard or even unfeasible.
The same holds later, during program development: it is foolish to spend long hours optimizing a function that ends up being called once a day and takes only a second. On the other hand, it is very wise to encapsulate this code into a function in the first place, so if the use patterns change as the program evolves, it can be optimized later without rewriting the rest of the program.
Another way to describe the limitations of the do not optimize prematurely rule is to qualify it by saying yes, but do not pessimize intentionally either. Recognizing the difference between the two requires knowledge of good design practices as well as an understanding of different aspects of programming for high performance.
So, what do you, as a developer/programmer, need to learn and understand in order to become proficient in developing high-performance applications? In the next section, we will start with an abbreviated list of these goals before diving into each of them in detail.
Learning about high performance
What makes a program high-performing? We could say "efficiency," but, first of all, this is not always true (although often it is), and second, it just begs the question, because the next obvious question becomes, OK, what makes the program efficient? And what do we need to learn in order to write efficient or high-performing programs? Let's make a general list of the required skills and knowledge:
- Choosing the right algorithm
- Using CPU resources effectively
- Using memory effectively
- Avoiding unnecessary computations
- Using concurrency and multi-threading effectively
- Using the programming language effectively, avoiding inefficiencies
- Measuring performance and interpreting results
The most important factor in achieving high performance is choosing a good algorithm. One cannot "fix" a bad algorithm by optimizing the implementation. However, this is also the one factor that is outside of the scope of this book. The algorithms are problem-specific, and this is not a book on algorithms. You will have to do your own research to find the best ones for the problem you are facing.
The methods and techniques to achieve high performance, on the other hand, are largely problem-agnostic. They do depend on the performance metrics, of course: for example, the optimization of real-time systems is a highly specific area with many idiosyncratic problems. In this book, we largely focus on the metrics of performance in the high-performance computing sense: doing a lot of computations as fast as possible.
In order to succeed in this quest, we have to learn to use as much of the available computing hardware as possible. This goal has a spatial and temporal component: in terms of space, we're talking about utilizing more of the transistors that the processor has in such huge numbers. The processors are becoming larger, if not faster. What is the added area used for? Presumably, it adds some new computing capabilities that we could use. In terms of time, we mean that we should be using as much hardware as possible at every time. Either way, computing resources are of no use to us if they are idle, so the goal is to avoid that. At the same time, busywork does not pay off, and we want to avoid doing anything we don't absolutely need to. This is not as obvious as it sounds; there are a lot of subtle ways your program could be doing computations you do not need.
In this book, we will start with a single processor and learn to use its computational resources efficiently. We will then expand our view to include not just the processor but also its memory. Then, naturally, we will look at using multiple processors at once.
But using the hardware efficiently is only one of the necessary qualities of a high-performing program: it does us no good to efficiently do the work that could have been avoided in the first place. The key to not creating unnecessary work is the effective use of the programming language, in our case, C++ (most of what we learn about the hardware can be applied to any language, but some of the language optimization techniques are very specific to C++). Furthermore, the compilers stand between the language that we write in and the hardware that we use, so we must learn how to use the compilers to produce the most efficient code.
Finally, the only way to quantify the degree of success for any of the goals we just listed is to measure it: how much of the CPU resources are we using? How much time do we spend waiting for memory? What is the performance gain achieved by adding another thread? And so on. Obtaining good quantitative performance data is not easy; it requires a thorough understanding of the measurement tools. Interpreting the results is often even harder.
You can expect to learn these skills from this book. We will learn about the hardware architecture, and what is hidden behind some programming language features, and how to see our code the way the compilers see it. These skills are important, but what is even more important is to understand why things work the way they do. The computing hardware changes fairly often, the languages evolve, and new optimization algorithms for the compilers are invented. Thus, the specific knowledge in any of these areas has a fairly short shelf life. However, if you understand not just the best ways to use a particular processor or compiler but also the ways in which we have arrived at this knowledge, you will be well prepared to repeat this process of discovery and, therefore, continue to learn.
Summary
In this introductory chapter, we have discussed why the interest in software performance and efficiency is on the rise despite the rapid advances in the raw computational power of modern computers. Specifically, we have learned why, in order to understand the factors limiting performance and how to overcome them, we need to return to the basic elements of computing and understand how computers and programs work at a low level: understanding the hardware and using it efficiently, understanding concurrency, understanding the C++ language features and the compiler optimizations, and their impact on performance.
This low-level knowledge is necessarily very detailed and specific, but we have a plan for dealing with that: as we learn specific facts about the processors or compilers, we will also learn the process by which we have arrived at these conclusions. Thus, at its deepest level, this book is about learning how to learn.
We have further understood that the notion of performance is meaningless without defining the metrics by which this performance is measured. The need to evaluate the performance against the specific metrics implies that any work on performance is driven by data and measurements. Indeed, the next chapter is dedicated to measuring performance.
Questions
- Why is program performance important despite advances in processing power?
- Why does understanding software performance require low-level knowledge of the computing hardware and programming languages?
- What is the difference between performance and efficiency?
- Why must performance be defined with respect to specific metrics?
- How can we judge whether the performance-related goals for specific metrics are accomplished?


