


















 Download code from GitHub
Download code from GitHub
Within the working world of technology, there are hundreds of thousands of different applications, all (usually) logging in different formats. As Splunk experts, our job is make all those logs speak human, which is often an impossible task. With third-party applications that provide support, sometimes log formatting is out of our control. Take for instance, Cisco or Juniper, or any other leading application manufacturer. We won't be discussing these kinds of logs in this chapter, but we'll discuss the logs that we do have some control over.
The logs I am referencing belong to proprietary in-house (also known as "home grown") applications that are often part of middleware, and usually they control some of the most mission-critical services an organization can provide.
Proprietary applications can be written in any language. However, logging is usually left up to the developers for troubleshooting and up until now the process of manually scraping log files to troubleshoot quality assurance issues and system outages has been very specific. I mean that usually, the developer(s) are the only people that truly understand what those log messages mean.
That being said, oftentimes developers write their logs in a way that they can understand them, because ultimately it will be them doing the troubleshooting/code fixing when something breaks severely.
As an IT community, we haven't really started looking at the way we log things, but instead we have tried to limit the confusion to developers, and then have them help other SME's that provide operational support to understand what is actually happening.
This method is successful, however, it is slow, and the true value of any SME is reducing any system's MTTR, and increasing uptime.
With any system, the more transactions processed means the larger the scale of the system, which means that, after about 20 machines, troubleshooting begins to get more complex and time consuming with a manual process.
This is where something like Splunk can be extremely valuable. However, Splunk is only as good as the information that comes into it.
I will say this phrase for the people who haven't heard it yet; "garbage in... garbage out"
There are some ways to turn proprietary logging into a powerful tool, and I have personally seen the value of these kinds of logs. After formatting them for Splunk, they turn into a huge asset in an organization's software life cycle.
I'm not here to tell you this is easy, but I am here to give you some good practices about how to format proprietary logs.
To do that I'll start by helping you appreciate a very silent and critical piece of the application stack.
Note
To developers, a logging mechanism is a very important part of the stack, and the log itself is mission critical. What we haven't spent much time thinking about before log analyzers, is how to make log events/messages/exceptions more machine friendly so that we can socialize the information in a system like Splunk, and start to bridge the knowledge gap between development and operations.
The nicer we format the logs, the faster Splunk can reveal the information about our systems, saving everyone time and headaches.
In this chapter we are briefly going to look at the following topics:
Log messengers
Logging formats
Correlation IDs and why they help
When to place correlation ID in a log
Here I will give some very high level information on loggers. My intention is not to recommend logging tools, but simply to raise awareness of their existence for those that are not in development, and allow for independent research into what they do. With the right developer, and the right Splunker, the logger turns into something immensely valuable to an organization.
There is an array of different loggers in the IT universe, and I'm only going to touch on a couple of them here. Keep in mind that I only reference these due to the ease of development I've seen from personal experience, and experiences do vary.
I'm only going to touch on three loggers and then move on to formatting, as there are tons of logging mechanisms and the preference truly depends on the developer.
I'm going to be taking some very broad strokes with the following explanations in order to familiarize you, the Splunk administrator, with the development version of 'the logger'. Each language has its own versions of 'the logger' which is really only a function written in that software language that writes application relevant messages to a log file. If you would like to learn more information, please either seek out a developer to help you understand the logic better or acquire some education on how to develop and log in independent study.
There are some pretty basic components to logging that we need to understand to learn which type of data we are looking at. I'll start with the four most common ones:
Log events: This is the entirety of the message we see within a log, often starting with a timestamp. The event itself contains all other aspects of application behavior such as fields, exceptions, messages, and so on... think of this as the "container" if you will, for information.
Messages: These are often made by the developer of the application and provide some human insight into what's actually happening within an application. The most common messages we see are things like unauthorized login attempt <user> or Connection Timed out to <ip address>.
Message Fields: These are the pieces of information that give us the who, where, and when types of information for the application's actions. They are handed to the logger by the application itself as it either attempts or completes an activity. For instance, in the log event below, the highlighted pieces are what would be fields, and often those that people look for when troubleshooting:
"2/19/2011 6:17:46 AM Using 'xplog70.dll' version
'2009.100.1600' to execute extended store procedure
'xp_common_1' operation failed to connect to 'DB_XCUTE_STOR'"
Exceptions: These are the uncommon but very important pieces of the log. They are usually only written when something goes wrong, and offer developer insight into the root cause at the application layer. They are usually only printed when an error occurs, and are used for debugging.
These exceptions can print a huge amount of information into the log depending on the developer and the framework. The format itself is not easy and in some cases is not even possible for a developer to manage.
This is a logger popularly used for Linux, and popular for its performance and multi-threaded handling of logging. Commonly, Pantheios is used for C/C++ applications, but it works with a multitude of frameworks.
This is a logger specifically for Python, and since Python is becoming more and more popular, this is a very common package used to log Python scripts and applications.
Each one of these loggers has their own way of logging, and the value is determined by the application developer. If there is no standardized logging, then one can imagine the confusion this can bring to troubleshooting.
This is an example of a Java exception in a structured log format:

Log format - null pointer exception
When Java prints an exception, it will be displayed in the format as shown in the preceding screenshot, and a developer doesn't control what that format is. They can control some aspects about what is included within an exception, though the arrangement of the characters and how it's written is done by the Java framework itself.
I mention this last part in order to help operational people understand where the control of a developer sometimes ends. My own personal experience has taught me that attempting to change a format that is handled within the framework itself is an attempt at futility. Pick your battles, right? As a Splunker, you can save yourself headaches on this kind of thing.
There are generally two formats that Splunkers will need to categorize to weigh the amount of effort that goes into bringing the data to a dashboard:
Structured data: These are usually logs for Apache, IIS, Windows events, Cisco, and some other manufacturers.
Unstructured data: This type of logging usually comes from a proprietary application where each message can be printed differently in different operations and the event itself can span multiple lines with no definitive event start, or event end, or both. Often, this is the bulk of our data.
In the land of unicorn tears, money trees, and elven magic, IT logs come in the same format, no matter what the platform, and every engineer lives happily ever after.
In our earthly reality, IT logs come in millions of proprietary formats, some structured and others unstructured, waiting to blind the IT engineer with confusion and bewilderment at a moment's notice and suck the very will to continue on their path to problem resolution out of them every day.
As Splunk experts, there are some ways that we can work with our developers in order to ease the process of bringing value to people through machine logs, one of which is to standardize on a log format across platforms. This in effect is creating a structured logging format.
Now when I say "cross-platform" and "standardize", I'm focusing on the in-house platform logs that are within your Splunk indexes and controlled by your in-house development staff right now. We can't affect the way a framework like Java, .NET, Windows, or Cisco log their information, so let's focus on what we can potentially improve. For the rest, we will have to create some Splunk logic to do what's called data normalization. Data normalization is the process of making the field user equal user across your entire first, second, and third-party systems. For instance, in Cisco log files there is a src_ip field. However, in the Juniper world, there is the source_address field. Data normalization is the act of making it so that you can reference a source IP address with a single field name across multiple data sets. In our example lets say source_ip represents both the src_ip field from Cisco, and the source_address from Juniper.
There are a few ways we can standardize on log event formats, and some systems already have these kinds of logging in place. The most Splunk-friendly ways are going to be either key=value pairs, or delimited values, JSON, or XML. I can tell you, through experience, that the easiest way to get Splunk to auto recognize the fields in a log is to use key=value pairs when writing to a log.
Let me give a couple examples of the structured data formats so you at least know what the data looks like:

JSON Logging format (this is how Splunk parses JSON logs)
You can find some information about Common Log Format at: https://en.wikipedia.org/wiki/Common_Log_Format .
The following dataset is very easy to parse within Splunk.
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
In this next example, we will learn how:
This is a delimited value format, and for ease we will be looking at web logs.
In the following image, we see that each log event is structured with <value1>, <value2>, and so on. This is a comma delimited log format that Splunk is quite happy with receiving, and pulling information out of:

Innately, Splunk will understand the structure of an IIS type of log event. However, in some cases it's up to the Splunk engineer to tell Splunk the field names, and the order of each of these events. This is basically event and field extraction, and it's also how we start organizing and managing the value of a dataset.
In this example there are a couple of ways of extracting knowledge from these events, and I will give both the automatic way and the manual way.
This type of value extraction is performed automatically by the back end Splunk programming. It looks for specific sourcetypes and data structures and extracts fields from them as long as you send data from each forwarder appropriately. For instance, IIS or apache logs.
In order to forward data appropriately, you'll need to:
Tell each forwarder on your IIS/Apache Machines to send data to the following source types (your choice of index):
access_combined - Apache
IIS - IIS
Make sure your Apache/IIS logs have the fields enabled for logging that Splunk is expecting (for more insight on this please see the Splunk documentation https://docs.splunk.com/Documentation .
After that, just run a search for index=<my_index> sourcetype=iis and if your forwarders/indexers are sending and receiving data properly, you should see data and the fields will be extracted in the Interesting Fields panel in Splunk. Voila, you're done!
This IIS/Apache automatic field extraction is available by default in Splunk which makes it nice for these data sets. If your source types are not named in this fashion, the extractions will not work for you out of the box as field extraction happens primarily at the source type level. If you would like to see all of the configuration for the IIS dataset, go to the following locations and look at the stanza:
$PLUNK_HOME/etc/system/default/props.conf-[iis], then take a look at the documentation if you want to learn more about the settings.
IIS data in Splunk should look something like this:
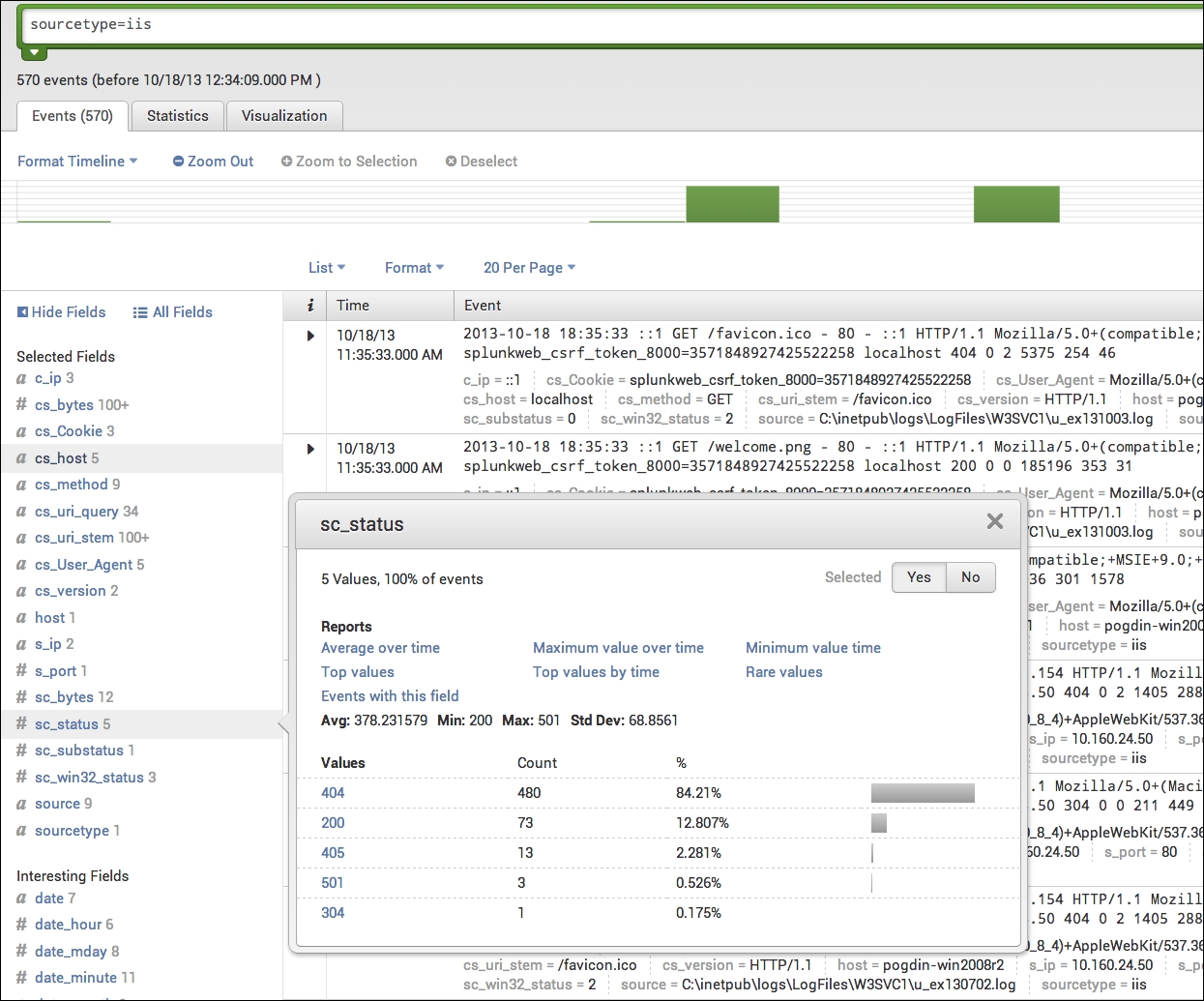
IIS data in Splunk with sc_status
Notice all of the fields that are being extracted under Interesting Fields.
Note
Splunk has only extracted a handful of log types, such as IIS/Apache logs, by default and cannot be leveraged on other datasets. Many of the other datasets are extracted using either an app from Splunkbase or the manual method. For a full list of datasets Splunk has programmed for automatic field extraction, please visit http://www.splunk.com/ . The whole goal of this chapter is to achieve this type of knowledge extraction most efficiently, as all of this is very helpful once we start building searches in Splunk. The most effective way to do this is by literally starting at the log format itself.
I will not be getting into how to work with REGEX in this book at all. I can only suggest that if you're a Splunk admin and you're not fluent with it... learn it quickly. RegExr ( http://regexr.com/) is a fantastic tool for learning this language or you can also visit https://regex101.com/ . Below is an image of regexr.com/v1 (the old version of the tool):
This technique can be used on any structured log data that is delimited, that Splunk itself doesn't have knowledge extraction of by default.
For this we are going to use the same type of structured data, but let's say that Splunk isn't extracting the data fields, though the data is already being input into Splunk. The data's source is a bash script that was created by a Linux system admin that required specifics on their set of machines.
This is as easy as speaking to the expert whose system the data belongs to.
In this example, the bash scripts output that is coming into Splunk is in a structured but unlabeled format:

If a general Splunk admin was to look at this data, it would appear to mean something, but it wouldn't be clear as to what. The person who does have clarity is the person who wrote the script. Our job as Splunk experts is often to go find out what this information means. I call this the process of discovery.
We can see a timestamp here, but after that, it's a series of information that makes no sense. The only thing we know for sure is that something is being printed at 2 second intervals and there are multiple values.
When we go to our SME, we need to ask him how he structured the data output that is being printed. Writing that information down will give us the field mappings we are looking for so we can structure this.
When we ask our SME, they will give us an answer that looks like this:

This is our field map, so now all we need to do is tell Splunk how to extract these characters being delimited by a space.
This is a quick and easy prop/transforms.conf setting.
For this example, we will just be using the standard search app, so we are going to adjust the settings there. We will be using REGEX to extract the fields and then standard bash variables to map each REGEX group to its field.
I'm going to add the following stanza to the transforms.conf in $SPLUNK_HOME/etc/apps/search/local/transforms.conf:
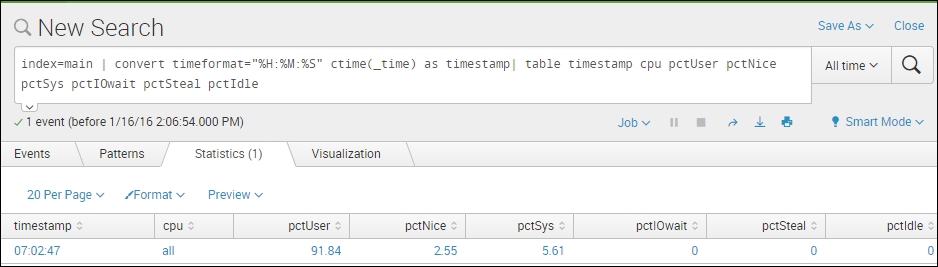
[myLinuxScript_fields] REGEX = [^ ]+\s\w+\s+(all)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+) FORMAT = cpu::$1 pctUser::$2 pctNice::$3 pctSys::$4 pctIOwait::$5 pctSteal::$6 pctIdle::$7
This REGEX gives Splunk the appropriate capture groups you want to label. These capture groups are signified by the parenthesis in the REGEX above.
I'm also going to call that transform in $SPLUNK_HOME/etc/apps/search/local/props.conf for my source type. We need this reference in order to extract our fields:
[mySourcetype] REPORT-fields = myLinuxScript_fields
Then we restart the Splunk service on the search head and we should see our new fields.
In the above transform, each REGEX capture group, represented by (), and anything in between them is mapped to a numerical variable. However, the capture groups must be contiguous and sequential. You can't have 10 capture groups and expect $1 to be the 5th group captured. $1 maps to capture group 1, $2 to capture group 2, and so on.
This is the data input from line 1 of the preceding image, with the method explained:
If you're developing an application in the world of structured data and mature logging, there are all kinds of lovely fields that can be used to bring value to our data with Splunk. One of the most valuable fields I've found in the development world that helps Splunk track a transaction end-to-end through a system is a correlation ID.
This is a field that is attached to the initial action of a user on a frontend, and that field value is passed down through the stack from frontend to middleware, to database call and back again during each action or transaction that is committed. This field is usually a uniquely generated GUID that, to Splunk, has huge potential.
Without something like a correlation ID, it's much more difficult to track activities from end-to-end, because many transactions within an application are looked at based on timestamp when troubleshooting. This little field will make your life profoundly easier if used properly with Splunk.
Some systems already have correlation IDs, such as SharePoint logging. However, many do not. If you're a developer of middleware and you're reading this, please use this field, as it makes mining for your data a lot easier.
This is an example of a SharePoint log with a correlation ID:
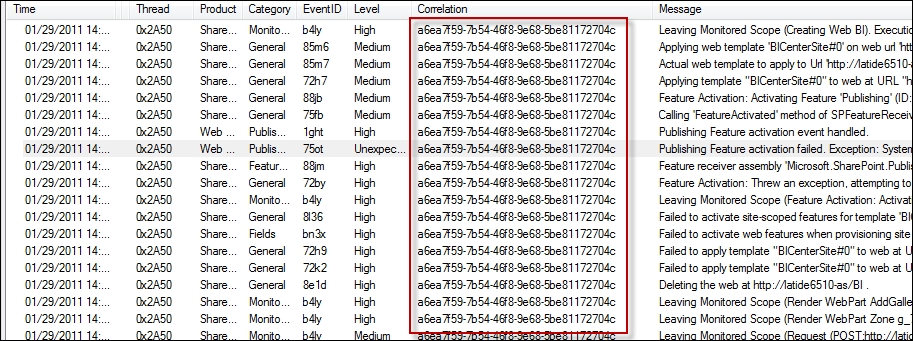
SharePoint log with a correlation ID
As you can see, this correlation ID is used throughout all log events made during this user's session. This allows great event correlation within a system.
For those who aren't familiar, there is a challenge within development with correlation IDs and specifically it's based on; when do we use them? Do we use them for everything? The answer to these questions usually boils down to the type of transaction being made within a system. I will share with you some techniques I've found to be useful, and have brought the most value to Splunk when working on development.
First we need to understand our three most popular actions within an application:
Publication: This is when an application answers a query and publishes data to a user one time. A user clicks a button, the application serves the user it's data for that request, and the transaction is complete.
Subscription: This is a transaction that begins with the click of a button, though the data streams to the user until something stops it. Think of this kind of transaction as a YouTube video that you click on. You click to start the video, and then it just streams to your device. The stream is a subscription type of transaction. While the application is serving up this data, it is also often writing to the application logs. This can get noisy as subscriptions can sometimes last hours or even days.
Database call: These are simply calls to a database to either retrieve or insert data to a database. These actions are usually pretty easy to capture. It's what people want to see from this data that becomes a challenge.
It's very simple. Add correlation IDs to all of your publication transactions, and save yourself and your ops team hundreds of hours of troubleshooting.
When writing to a log, if we can log a correlation ID for each publication transaction and insert that data into Splunk, then we can increase the view of what our application is doing tremendously. I will refer to SharePoint again as it is the easiest and most well-known to reference:
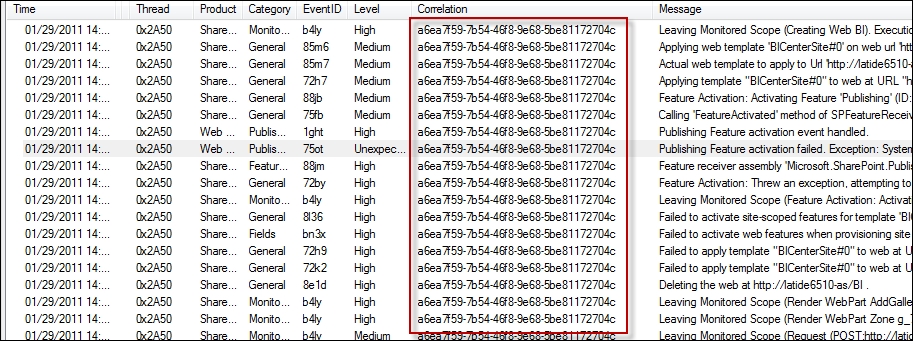
In the preceding image, all of these events are publications and you can see that it's even written into the log message itself in some events. What we are looking at above is a slice of time a user has been on our system, and their activity.
If we put this data into Splunk, and we extract the correlation ID field correctly, it's as easy as finding a single event with a username and then copying and pasting the correlation ID into our search query to find our user's entire behavior. Above, we are looking at a single instance of SharePoint.
In the real world we may have:
200 users
10 user-facing machines running an application that is load-balanced
30 middleware machines
4 databases
100+ tables.
Following a single user's activity through that system becomes time consuming, but if we use correlation IDs, mixed with Splunk, we will find ourselves saving days of time when looking for problems. We can also proactively alert on our system if we extract the knowledge in Splunk properly.
Developers actually love correlation IDs more than operations, because inserting their application data into Splunk and allowing them a single place to search the logs of their applications where all they have to do is find the correlation ID to look for a user's activity saves lots of time in QA.
The most common question for subscription transactions and correlation IDs is; How can we minimize the wasted space in the log that arises from subscription events, seeing as they are part of the same transaction and don't need to be written to every event within each subscription?
For subscription type events within a log, they are commonly very noisy and not needed until something breaks.
The compromise for writing correlation IDs to let Splunk continue to monitor user activity is to write a correlation ID in the event only at subscription start and subscription end.
If you want further detail on your subscriptions, and you want Splunk to be able to quickly retrieve these events, the developers I've known have used subscription IDs, which are printed to the log with every action within a subscription transaction. These are also usually GUIDs, but they target only a user's subscription within your system.
This often ends up being seen most in Splunk license utilization. However, if we plan accordingly, we can subvert this issue in the real world.
In this type of transaction we can write a correlation ID each time a transaction occurs, the same way we would do as a publication. As best practice, write this ID to the log event in the same manner one would on a publication transaction.
The larger the system, the more chaos we as Splunk experts must try to bring some order to. In many cases, companies have a specific use case for something like Splunk, though they often expect that Splunk is a turnkey solution.
The following screenshot is an example of what unstructured data looks like:

These kinds of logs are much more complicated to bring value to, as all of the knowledge must be manually extracted by a Splunk engineer or admin. Splunk will look at your data and attempt to extract things that it believes is fields. However, this often ends up being nothing of what you or your users are wanting to use to add value to their dashboards.
That being the case, this is where one would need to speak to the developer/vendor of that specific software, and start asking some pointed questions.
In these kinds of logs, before we can start adding the proper value, there are some foundational elements that need to be correct. I'm only going to focus on the first, as we will get to the other 2 later in this book.
Time stamping
Event breaking
Event definitions
Field definitions (field mapping)
With structured data, Splunk will usually see the events and not automatically break them as they are nice and orderly.
With unstructured data, in order to make sure we are getting the data in appropriately, the events need to be in some sort of organized chaos, and this usually begins with breaking an event at the appropriate line/character in the log. There's lots of ways to break an event in Splunk (see
http://docs.splunk.com/Documentation/Splunk/6.4.1/Admin/Propsconf
and search for break), but using the preceding data, we are going to be looking at the timestamp to reference where we should break these events, as using the first field, which is most often the timestamp, is the most effective way to break an event.
There are a few questions to ask yourself when breaking events, though one of the more important questions is; are these events all in one line, or are there multiple lines in each event? If you don't know the answer to this question, ask the SME (dev/vendor). Things can get messy once data is in, so save yourself a bit of time by asking this question before inputting data.
In the following example, we can see the timestamp is the event delimiter and that there can be multiple lines in an event. This means that we need to break events pre-indexing:

In order to do that, we need to adjust our props.conf on our indexer. Doing so will appropriately delineate log events as noted in the following image:

Note
Adding line breaking to the indexing tier in this way is a method for pre-index event breaking and data cannot be removed without cleaning an index.
In this example, we have five indexers in a cluster pool, so using the UI on each of those indexers is not recommended. "Why?" you ask. In short, once you cluster your indexers, most of the files that would end up in $SPLUNK_HOME/etc/ having become shared, and they must be pushed as a bundle by the cluster master. It is also not recommended by Splunk support. Try it if you like, but be prepared for some long nights.
Currently Splunk is set up to do this quite easily from an individual file via the UI, though when dealing with a larger infrastructure and multiple indexers, the UI feature often isn't the best way to admin. As a tip, if you're an admin and you don't have a personal instance of Splunk installed on your workstation for just this purpose, install one. Testing the features you will implement is often the best practice of any system.
Why should you install an instance of Splunk on your personal workstation you ask? Because if you bump into an issue where you need to index a dataset that you can't use the UI for, you can get a subset of the data in a file and attempt to ingest it into your personal instance while leveraging the UI and all its neat features. Then just copy all of the relevant settings to your indexers/cluster master. This is how you can do that:
Get a subset of the data, the SME can copy and paste it in an e-mail, or send it attached or by any other way, just get the subset so you can try to input it. Save it to the machine that is running your personal Splunk instance.
Login to your personal Splunk instance and attempt to input the data. In Splunk, go to Settings | Data Inputs | Files & Directories | New and select your file which should bring you to a screen that looks like this:

Attempt to break your events using the UI.
Now we are going to let Splunk do most of the configuring here. We have three ways to do this:
Auto: Let Splunk do the figuring.
Every Line: this is self-explanatory.
Regex...: use a REGEX to tell Splunk where each line starts.
For this example, I'm going to say we spoke to the developer and they actually did say that the timestamp was the event divider. It looks like Auto will do just fine, as Splunk naturally breaks events at timestamps:

Going down the rest of the option, we can leave the timestamp extraction to Auto as well, because it's easily readable in the log.
The Advanced tab is for adding settings manually, but for this example and the information we have, we won't need to worry about it.
When we click the Next button we can set our source type, and we want to pay attention to the App portion of this, for the future. That is where the configuration we are building will be saved:

Click Save and set all of the other values on the next couple of windows as well if you like. As this is your personal Splunk instance, it's not terribly important because you, the Splunk admin, are the only person who will see it.
When you're finished make sure your data looks like you expect it to in a search:

And if you're happy with it (and let's say we are) we can then look at moving this configuration to our cluster.
Remember when I mentioned we should pay attention to the App? That's where the configuration that we want was written. At this point, it's pretty much just copying and pasting.
All of that was only to get Splunk to auto-generate the configuration that you need to break your data, so the next step is just transferring that configuration to a cluster.
You'll need two files for this. The props.conf that we just edited on your personal instance, and the props.conf on your cluster master. (For those of you unfamiliar, $SPLUNK_HOME/etc/master_apps/ on your cluster master)
This was the config that Splunk just wrote in my personal instance of Splunk:

Follow these steps to transfer the configuration:
Go the destination app's
props.conf, copy the configuration and paste it to your cluster mastersprops.conf, then distribute the configuration to its peers ($SPLUNK_HOME/etc/master_apps/props.conf). In the case of our example:Copy source file = $SPLUNK_HOME/etc/apps/search/local/props.conf Copy dest file = $SPLUNK_HOME/etc/master_apps/props.confChange the stanza to your source type in the cluster:
When we pasted our configuration into our cluster master, it looked like this:
[myUnstructured] DATETIME_CONFIG = NO_BINARY_CHECK = true category = Custom pulldown_type = true
Yet there is no
myUnstructuredsource type in the production cluster. In order to make these changes take effect on your production source type, just adjust the name of the stanza. In our example we will say that the log snippet we received was from a web frontend, which is the name of our source type.The change would look like this:
[web_frontend] DATETIME_CONFIG = NO_BINARY_CHECK = true category = Custom pulldown_type = true
Push the cluster bundle via the UI on the cluster master:

Make sure your data looks the way you want it to:

Once we have it coming into our index in some sort of reasonable chaos, we can begin extracting knowledge from events.
In this chapter we discussed where the lion's share of application data comes from and how that data gets into Splunk and how Splunk reacts to it. We mentioned good ways and things to keep in mind when developing applications, or scripts, and also how to adjust Splunk to handle some non-standardized logging. Splunk is as turnkey as the data you put into it. Meaning, if you have a 20-year-old application that logs unstructured data in debug mode only, your Splunk instance will not be turnkey. With a system like Splunk, we can quote some data science experts in saying garbage in, garbage out.
While I say that, I will add an addendum by saying that Splunk, mixed with a Splunk expert and the right development resources, can also make the data I just mentioned extremely valuable. It will likely not happen as fast as they make it out to be at a presentation, and it will take more resources than you may have thought. However, at the end of your Splunk journey, you will be happy. This chapter was to help you understand the importance of logs formatting and how logs are written. We often don't think about our logs proactively and I encourage you to do so.
Now that we have this understanding about logging and the types of data that applications generally write, we can move on to understanding what kinds of data inputs Splunk uses in order to get data in.
Determining which data input suits your use case is often the first part of getting data into Splunk, and with a wide variety of ways to do this, Splunk enables us to use the methods that they have developed, as well as allowing room for us to develop our own if necessary.

