


















In this chapter, we will cover:
Understanding about SAP HANA Studio
Switching between different views – perspectives
Navigating SAP HANA Studio – the Navigator Pane
Administering SAP HANA Studio – the Administration Console perspective
Modeling SAP HANA Studio – the Modeler perspective
This recipe introduces you to why and where SAP HANA Studio is used. We will also look at how SAP HANA Studio has been developed and the technologies used behind its development.
SAP HANA Studio runs on the Eclipse platform and is both the central development environment and the main administration tool for SAP HANA. SAP HANA Studio is used by administrators to administer activities, such as to start and stop services, monitor the system, configure system settings, and manage users and authorizations. SAP HANA Studio interacts with the servers of the SAP HANA database by using SQL. Developers use SAP HANA Studio for content creation such as information views and stored procedures. These development objects are stored in the SAP HANA repository. SAP HANA Studio is developed in the Java language and is based on the Eclipse platform.
SAP HANA Studio is the interface between the HANA database and the reporting layer or the HANA database and the presentation layer. It is the area where we design our models (for example, data models—3NF, 5NF, dimension models—based on star schema where we have facts, dimensions, and so on). SAP HANA Studio is a collection of applications for the SAP HANA appliance software. It enables developers, modelers, or technical users to work on development activities of the SAP HANA database. These activities include creating/managing user authorizations and building models, which can be creating new or editing existing models of data in the SAP HANA database. SAP HANA Studio is a client environment which can be used to access the SAP HANA database. The database can be located in the same environment or at a remote location.
SAP HANA Studio runs on the Eclipse platform Version 3.6. SAP HANA Studio can be used on the following platforms:
Microsoft Windows x32 and x64 versions of XP, Vista, and Windows 7
64-bit versions of the Linux platform such as SUSE and Ubuntu
For Mac OS X, SAP HANA Studio (Version 1.00.60) is available for download
Java JRE 1.6 or 1.7 must be installed to run SAP HANA Studio. The path variable parameters have to be set for JRE. The correct Java variant installation has to be selected accordingly, 32 bit or 64 bit.
An installation path has to be defined while installing, otherwise default values will be applied, as shown:
Microsoft Windows 32 bit (x86):
C:\Program Files (x86)\sap\hdbstudioLinux 64 bit (x86):
/usr/sap/hdbstudioMicrosoft Windows 32 bit:
C:\Program Files\sap\hdbstudioMicrosoft Windows 64 bit:
C:\Program Files\sap\hdbstudio
Eclipse IDE at http://en.wikipedia.org/wiki/Eclipse_(software)
We use the same IDE, SAP HANA Studio, for different activities, such as modeling, administration, and transports. The corresponding perspective has to be set to perform these respective activities. This recipe explains in detail about the perspectives available.
SAP HANA Studio presents its various tools in the form of perspectives.
A perspective contains specific task- or resource-related functions. It determines which views and editors are available and controls what appears in certain menus and toolbars for the developers, modelers, or technical users to leverage based on the requirements.
Database administration and monitoring features are contained primarily within the Administration Console perspective. There are other perspectives as well, which include Modeler, SAP HANA Development, Debug, and Lifecycle Management, as shown in the following screenshot:

There are several key Eclipse perspectives that you will use while developing; however, these are the major ones that are used predominantly:
Modeler: The Modeler perspective is used to define information models and to create various types of views and analytical privileges to create models. It allows users to create new or modify existing models of data. Modelers can create different types of models (for example, attribute views, analytic views, and calculation views) depending on the data, which can be transaction data, master data, or any dimensional or other data. All databases are listed in the Navigator Pane of the studio.
SAP HANA Development: This perspective consists of new tools specifically created for SAP HANA XS (Extended Application Services). These tools help in writing the server-side JavaScript code. This perspective is used to create development objects that access or update models. There are native and non-native applications that are supported, such as JScript, HTML5, Java, and .Net.
Debug: This perspective is used for debugging purposes, such as server-side JavaScript or SQLScript.
Administration Console: This perspective is used to monitor the system and change settings. This perspective allows administrators to administer and monitor the SAP HANA database instances. It also includes the database status information. Administrators can check the overview of the system, servers, running services, diagnose logfiles, monitor log size, volume size, system performance, multiple alerts, and so on. They can also create users and roles and can assign privileges to roles.
Lifecycle Management: This perspective is used for future releases and upgrades. It helps in providing automated updates for SAP HANA using SAP Software Update Manager.
From the Window menu, select Open Perspective and change the perspective accordingly. At the bottom of the menu, we can see the Other option, from where we can access other perspectives as well, as shown in the following screenshot:

In the top-right corner of SAP HANA Studio, we have an option to open the available perspectives and change them.
By clicking on the  icon, we can navigate between perspectives.
icon, we can navigate between perspectives.
When we log on to SAP HANA Studio, this is the place through which we can access all the objects—schemas, tables, procedures, information views, and so on. We can see this pane on the left side of the studio. This recipe discusses the different actions that can be performed from the Navigator Pane.
SAP HANA Studio is client software deployed on local machines which is used to connect to the SAP HANA server (database). For this, we have to add the system with all the details in the Navigator Pane. It is this pane that we will be navigating to access objects in the database and achieve tasks, as shown in the following screenshot:

At first look, the pane looks empty as we don't have any systems added. Once we add systems, we can browse through all the content. We can connect to multiple HANA databases from a single studio. Let us say that, a company has multiple HANA servers across the landscape—Development, Quality, and Production. Individual entries have to be added for each system and connected to the same.
The options in the Navigator Pane depend on the opened perspective. When we are in the Modeler perspective, we will see only the available systems and the objects. The content differs with the SAP HANA Development perspective or Debug perspective. This can be seen in the following screenshot:

There are other options in the top portion of the Navigator Pane to monitor system health, administration, the SQL console, and so on. We will look at all the available options in detail.
We can monitor the system using the  option. When we click on this button, details of all the available systems will be displayed. By default, information available in the memory, used memory, and so on will be displayed system wise. These results can be configured with what data needs to be displayed on the monitor screen. We can further drill down to the administration mode from this menu. Just a double-click on the system will take us to the administration section of that system, as shown in the following screenshot:
option. When we click on this button, details of all the available systems will be displayed. By default, information available in the memory, used memory, and so on will be displayed system wise. These results can be configured with what data needs to be displayed on the monitor screen. We can further drill down to the administration mode from this menu. Just a double-click on the system will take us to the administration section of that system, as shown in the following screenshot:

The  option helps us with the administration of a particular system. More details on this option will be covered in the Administering SAP HANA – the Administration Console perspective recipe of this chapter.
option helps us with the administration of a particular system. More details on this option will be covered in the Administering SAP HANA – the Administration Console perspective recipe of this chapter.
As we deal with the administration of the system, this completely depends on the roles and authorizations we possess in the system.
The  option opens up an SQL console, where we can write the SQL code for different purposes. We usually write the SQL code for DDL/DML/TCL operations, such as creating/altering a table, inserting/updating/previewing/deleting data contents of a table, or committing updates. The code written in this is reusable. We can save the code as a file on our local PC and use the same code in the future.
option opens up an SQL console, where we can write the SQL code for different purposes. We usually write the SQL code for DDL/DML/TCL operations, such as creating/altering a table, inserting/updating/previewing/deleting data contents of a table, or committing updates. The code written in this is reusable. We can save the code as a file on our local PC and use the same code in the future.
The SQL code will be executed based on the roles/authorizations we have on a system. We should have authorization to execute SQL on a schema; otherwise, the execution fails with an invalid authorization issue. The SQL Console window is as shown in the following screenshot:

The level we select while opening the SQL console is very important. As shown in the preceding screenshot, we can see the name of the schema for which the SQL console has been opened. Text in the header section of the SQL console will be in the following format:
SYSTEM_NAME (USER_NAME) HOST_NAME (Current Schema: SCHEMA_NAME)
Let's have a look at each of the fields:
SYSTEM_NAME: This represents the system which has been selected for opening SQL Console. The length of the system name will be three characters.USER_NAME: This tells us the username with which we have logged in to the system and are working with in SQL Console.HOST_NAME: This shows the details of the host to which we are connected. The same host details can be seen from the properties of the system.SCHEMA_NAME: This gives us the name of the schema which has been selected while opening the SQL Console window. If SQL Console has been opened while selecting the system, we don't see this in the header section. From the preceding screenshot, we can see that when SQL Console is opened from the system level, no schema details are displayed. The same happens when we select a schema and open SQL Console; we can see the schema on which SQL Console is working.
The important thing here is that when we execute any SQL command without giving a schema name, it works on the schema which we have selected. When tables/views are created without giving the schema name, these will go and sit in the schema. There is no restriction on fetching data from any schema; we can run SQL on any schema to retrieve data.
The  option helps us in searching for a table in the system. This icon will be active only when we select a catalog folder in the system, as tables will be located in the catalog section. Even though a schema is selected to find a table, the search will be executed on the entire system. All the tables with the given search string will be returned. We can also select to include column names in the search. In this case, results will consist of the column names as well. The minimum length of the search string is two characters.
option helps us in searching for a table in the system. This icon will be active only when we select a catalog folder in the system, as tables will be located in the catalog section. Even though a schema is selected to find a table, the search will be executed on the entire system. All the tables with the given search string will be returned. We can also select to include column names in the search. In this case, results will consist of the column names as well. The minimum length of the search string is two characters.
The  option can be used to search systems. The name of the system will be stored in the following format:
option can be used to search systems. The name of the system will be stored in the following format:
SYSTEM_NAME HOST_NAME (USER_NAME)
A search will be executed soon after giving a single character. A search string can be a part of the system name, host name, or a username. All values that match will be displayed. There are two more options, Open Administration and Open SQL Console, at the bottom of the search window, as shown in the following screenshot. If these are checked, it automatically opens the corresponding windows—Administration/SQL Console.

The  option links the objects opened with the navigation pane. When this option is enabled and an object is selected, the corresponding object in the navigation pane will be highlighted automatically. For example, let us assume that we are working on a few tables, views, and procedures opened in SQL Console, which are present in different schemas. When we change from one object to another in the main window, the same object in the respective schema will be highlighted in the navigation pane. This allows us to search where the objects are located exactly when required.
option links the objects opened with the navigation pane. When this option is enabled and an object is selected, the corresponding object in the navigation pane will be highlighted automatically. For example, let us assume that we are working on a few tables, views, and procedures opened in SQL Console, which are present in different schemas. When we change from one object to another in the main window, the same object in the respective schema will be highlighted in the navigation pane. This allows us to search where the objects are located exactly when required.
Cheat sheets can be opened in SAP HANA Studio. Select the Window menu, expand Show View and select Other. Now expand the Help folder. We can see Cheat Sheets. Select it, now we can see the Cheat Sheets pane on the right-hand side of SAP HANA Studio
Views in SAP HANA Studio
SAP HANA Database – Studio Installation and Update Guide at http://help.sap.com/hana/SAP_HANA_Studio_Installation_Update_Guide_en.pdf
This recipe introduces another perspective. This perspective is more helpful for administrative purposes.
The Administration Console perspective helps with the administration aspects of SAP HANA. This perspective is helpful for SAP HANA technology users (database administrators) who work on regular administrative tasks which involve maintaining and monitoring system status, monitoring disk volume usage, configuring alerts, and so on.
Let us go through the different options in this perspective. The following screenshot illustrates the Administration Console perspective:
We need to configure a system in SAP HANA Studio before starting to work on it. There could be different systems available in the landscape—Development, Quality, and Production. The following is the process of adding a system.
In order to connect to a SAP HANA instance, we need to know the server credentials and details (user ID, server, password, and instance number). The left-hand side of the studio Navigator Pane shows the available HANA instances in SAP HANA Studio. Following are the steps to add a new system:
Right-click in the Navigator space and click on Add System, as shown in the following screenshot:

Enter the values for SAP HANA Hostname and Instance Number and then click on Next, as shown in the following screenshot:

Enter the database credentials—User Name and Password—to connect to the SAP HANA database. After the successful connection to SAP HANA, click on Next and then click on Finish, as shown in the following screenshot:

The SAP HANA system now appears in the Navigator Pane, as shown in the following screenshot:

Apart from adding a system, there are other activities as well that can be done in the Administration Console perspective.
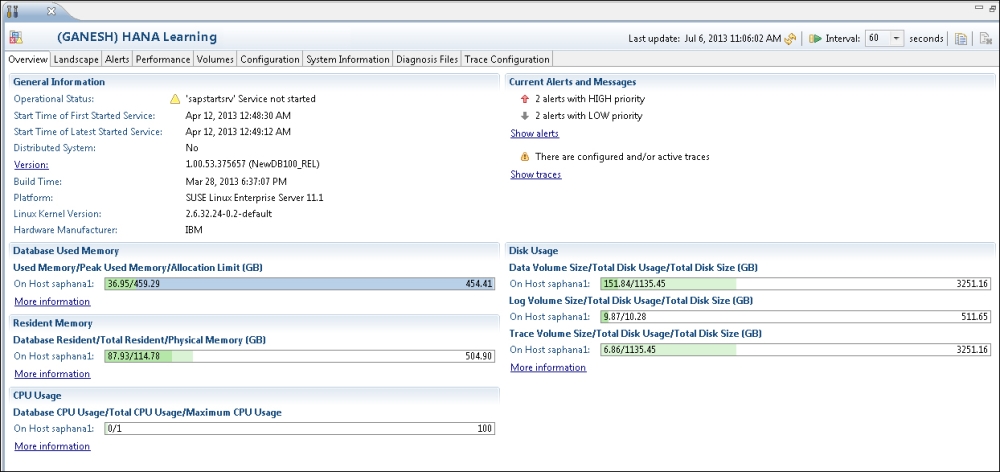
In this tab, we can have a snapshot of the overall status of the system. As shown in the screenshot in the Getting ready section of this recipe, it includes the system status, build version, hardware and software details, disk memory utilization, CPU utilization, and so on. We can dive into each category to get in-depth details.
In the Landscape menu, we can have a glance at different services running and their administration, configuring hosts, redistribution operation on tables, and so on.
Under this category, activities related to services are handled. All the services running across every host will be available here. We can start, stop, or kill the services. Memory usage and allocation details across different servers can be monitored, and the result set can be customized by fields to be displayed.
Hosts can be configured using Configuration. Assignment details of master/slaves for all servers can be monitored from this screen.
Tables have to be redistributed among index servers for effective utilization of resources and optimal performance. Performance will be optimal when frequently joined tables are located in the same index server compared to those that are spread into different index servers. Therefore, it is highly recommended to distribute the tables among index servers. This can be performed soon after adding the hosts or later as well based on the models we build on the tables, for which we have separate options available.
The same operation has to be applied for partitioned tables as well. Partitioned tables will be distributed across different index servers. This location can be specified manually or determined by the database when it has been partitioned initially. The size of these partitions will be growing in time, which may not give us optimal results. Therefore, it is required to redistribute the partition tables as well.
For an administrator, system status, services, and resources have to be monitored continuously. Configuring alerts will help in making timely decisions. In the generation of alerts, the statistics server plays a major role. When the SAP HANA system is started, the statistics server is automatically activated on the host of the active master name server. The statistics server runs SQL commands internally and collects all the information from all index servers. From this data, important alerts information will be displayed in the Overview tab and the Alerts tab will hold detailed level data.
E-mail notifications can be configured for these alerts and thereby all stakeholders will be updated on alerts. The sender's e-mail address, recipient's e-mail address, and SMTP port details are required for this setting. The recipients listed will be notified by e-mail upon generation of alerts by the statistics server.
All performance-related processes can be monitored from this tab. This includes threads, sessions, SQL cache, expensive statements, progress in jobs, load details, and so on.
Whenever there is an I/O operation in the SAP HANA system, it starts threads on the corresponding server. The detailed level of data on these threads can be monitored and can be cancelled if required. Similarly, details related to open sessions, SQL plan cache, expensive statements executed, and jobs which are progressing can be monitored.
Apart from these, the load impact on the SAP HANA system can be monitored. Flexible options are provided to change the filters dynamically so that we can drill down or drill up on the data of any server in the host. This really helps in understanding where the server is being impacted with peak loads on which server.
It makes no sense if system resources are not effectively utilized after taking on a powerful, in-memory database such as SAP HANA.
The Volumes tab gives us complete detail on the memory statistics of all servers (name server, index server, statistics server, and XS Engine) on the host. This includes total disk size, used disk size, remaining disk size, and volume size. Details about data volumes, log volumes along with the page size, and block size are also available.
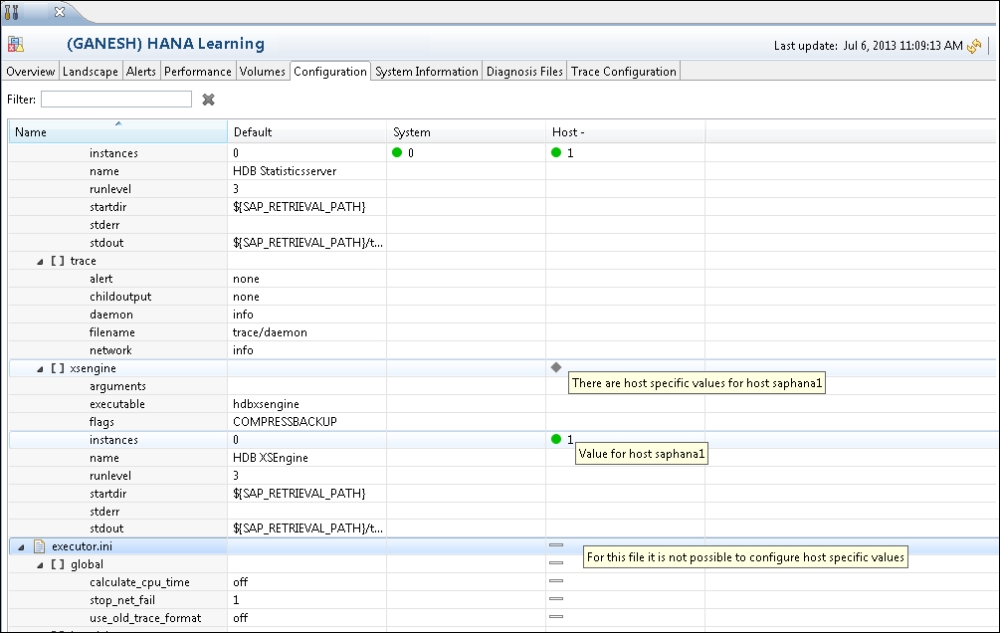
The Configuration tab has highly sensitive data as all the system configurations are maintained in this section. For the SAP HANA system, configurations are stored in the form of configuration files—the .ini files. We will have several values, and these settings can be changed for the host or the entire system. When the value is changed, a green mark will be shown indicating changed values. Against a few values, a minus sign will be displayed. We cannot change these values and they are set by the system itself, as shown in the following screenshot:
The System Information tab holds the system information table, which has data related to the SAP HANA system. Data in each table can be viewed and a detailed analysis can be performed to take decisions for system maintenance. This includes tables on memory consumption, work load statistics, transactions in use, and many more.
Trace and logfiles of the system can be browsed from this menu (all the trace and logfiles right from the starting date of the system setup). These files can be viewed or downloaded to a local PC.
Detailed information about the actions of the HANA database can be obtained using different traces. We can activate these traces and configure them as per our requirements.
We can configure the following traces:
|
S No |
Trace |
Default Configuration |
|---|---|---|
|
1 |
SQL trace |
Inactive |
|
2 |
Performance trace |
Inactive |
|
3 |
Kernel profiler trace |
Inactive |
|
4 |
Global database trace |
Active with default trace level ERROR |
|
5 |
Database trace |
Active with default trace level ERROR |
|
6 |
User-specific trace |
Not specified |
|
7 |
End-to-end trace |
Active with default trace level ERROR |
|
8 |
Expensive statements trace |
Inactive |
SAP HANA Administration Guide at http://help.sap.com/hana/SAP_HANA_Administration_Guide_en.pdf
In this recipe, we will see how a modeler starts working in SAP HANA Studio to accomplish modeling activities. To perform any modeling activity, we have to switch to the Modeler perspective.
All the modeling activities will be done from this perspective. We will be creating tables, information views, SQL procedures, and so on. Let us talk in brief about this perspective.
SAP HANA Modeler is a graphical data modeling tool used to design analytical models and analytical privileges. Analytical models are used to load data and report on top of them, whereas analytical privileges are used to restrict access to those models. SAP HANA Modeler is intended for users with extensive technical knowledge and can therefore be regarded as the more powerful tool. The Modeler perspective supports functions as shown:
Creating information views (attribute/analytic/calculation) and analytic privileges
Processing models
Administration tasks such as managing modeling content
Importing table definitions/schemas
Loading data
The Modeler perspective is as shown in the following screenshot:

In the modeling section of SAP HANA, there are several things to know. A few of them are explained in this recipe.
Information views are of different types— Attribute View, Analytic View, and Calculation View. When we use an information composer, a calculation view is created. Calculation views are basically a query which is built on top of analytic views and other calculation views to meet a complex business requirement.
Some of the features are as follows:
Attribute views
Analytic views
Calculation views
Transportable design time objects are stored in the repository
Database objects (column store views) are generated from these development artifacts
SQLScript provides a flexible programming language environment as a combination of imperative and functional expressions of SQL. The significant part is that it allows developers to easily express data and control flow logic by using DDL, DML, and SQL query statements as well as imperative language constructs, such as loops and conditionals. On the other hand, functional expressions are used to express declarative logic for the efficient execution of data-intensive computations. This logic is internally represented as data flow, which can be executed in parallel as SAP HANA supports massive parallel processing.
Some of the features are as follows:
Push data-intensive operations into the SAP HANA database
Used in calculation views and procedures
Read-only procedures
Read/Write procedures
SAP HANA Modeling Guide at http://help.sap.com/hana/SAP_HANA_Modeling_Guide_en.pdf

